
🐶 오늘의 학습 내용
-
스프링의 핵심🧐 의존성 주입(DI : Dependeny Injection)의 4가지 방법이란❓
-
들어가기에 앞서, 의존이란 A의 기능이 동작하려면 객체 B가 존재해야 함을 의미한다.

-
Controller는 웹화면을 구성하는 역할을 한다. 화면을 구성하려면 서비스에 맞는 데이터를 전달 받아야 하는데, 이때 Controller는 데이터를 서비스에 맞게 처리하는 로직을 가지고 있는 Service에 의존한다. 또한 Service는 데이터가 필요하므로 데이터를 가져오는 기능을 갖는 Repository에 의존한다.
-
이처럼, 객체지향구조는 서로 "의존" 하고 있는 구조이다. 그러나 의존을 주입하는 코드를 개발자가 직접 구현하면 객체를 직접 관리해야 하고 객체간 결합도가 증가한다.
-
하지만, 스프링에는 객체를 저장하는 컨테이너라는 공간이 있고, 컨테이너에 저장된 객체를 Bean 이라 부른다. 많은 객체가 의존하는 객체는 Bean으로 등록하고 필요할 때마다 컨테이너에서 빼오면 되고, 컨테이너에 등록하는 방법 또한 간단하다.
-
개발자는 Bean으로 만들고 싶은 객체를
@Component,@Bean어노테이션으로 표시한다. 그러한 어노테이션들을 스프링 프레임워크는 컴포넌트 스캔하여 Bean으로 등록하는 것이다. 이때 컨테이너에 Bean이 등록되면 Bean에 의존하는 객체에 의존성을 주입해야 하는데 이때 사용하는 방법들이 아래의 방법들이다.1) 수정자 주입(Setter 주입)
➡ 수정자 주입은 Setter라 불리는 필드의 값을 변경하는 수정자 메서드를
통해서 의존 관계를 주입하는 방법이다.2) 필드 주입
➡ 필드 주입은@Autowired를 붙여서 클래스 멤버 필드에 바로
주입하는 방법이다.3) 일반 메서드 주입
➡ 일반 메서드를 통해서 의존관계를 주입하는 방법이다.4) 생성자 주입
➡ 생성자를 통해서 의존 관계를 주입받는 방법으로, 4가지 방법 중 현재 가장
많이 쓰이고 있는 방법이다.
-
-
왜 생성자 주입을 많이 사용하는 걸까?
1) 불 변
의존 관계 주입은 처음 어플리케이션이 실행될 때 대부분 정해지고 종료 전까지 변경되지 않아야 한다. 만약, 변경 가능성이 있다면 개발자가 실수로 변경할 가능성이 있기 때문이다. 따라서 보통private final을 붙여서 변경할 수 없도록 만든다.2) 누 락
호출했을때 NullPointException 이 발생한다면, 의존 관계 주입이 누락되었기 때문이다. 생성자 주입을 사용하면 주입 데이터 누락 시 컴파일 오류가 발생한다. 따라서 누락이 발생하면 실행이 안되기 때문에 오류를 바로 수정할 수가 있다.3) 순환 참조 방지
개발을 하다 보면 여러 컴포넌트 간에 의존성이 생기게 되는데 필드 주입이나 수정자 주입은 빈이 생성된 후에 참조를 하기 때문에 어플리케이션이 어떠한 오류나 경고 없이 구동된다. 따라서 문제가 있을때 실제 코드가 호출될 때까지 문제를 알 수가 없다. 하지만 생성자를 사용하면 BeanCurrentlyInCreationException이 발생하게 되어 문제를 알 수 있다.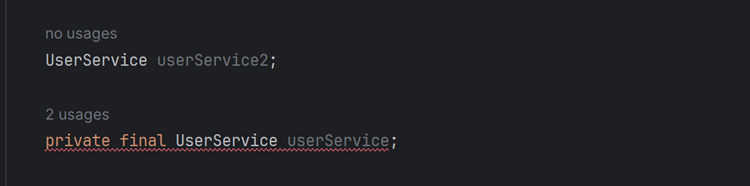
- 위의 그림은 아직 의존성 주입을 안한 코드이다. 1번째 줄의
private final을 안붙였을때는 오류가 안뜨고, 2번째 줄의 붙였을때는 오류가 뜨는 것을 볼 수 있다.
- 따라서
private final을 붙였을 때는 오류가 뜨면 내가 의존성 주입을 했는지부터 확인 하게 될 것이고, 아래처럼 생성자를 통해 의존성을 주입하여 오류를 해결할 수 있다.
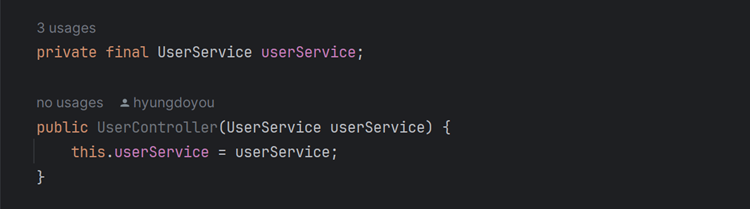
- 위의 그림은 아직 의존성 주입을 안한 코드이다. 1번째 줄의
-
계층형 아키텍처란❓
계층형 아키텍처는 가장 일반적인 소프트웨어 아키텍처 스타일 중 하나로, 기능이 유사한 모듈 또는 구성요소를 수평 계층으로 구성하여 각 계층이 애플리케이션 내에서 특정 역할을 수행하게 한다. 이는 유지 관리 및 확장이 필요한 소프트웨어에 적합하기 때문에 한 계층의 기능을 변경하는 경우 다른 계층에 영향을 주지 않고 해당 계층으로 분리할 수 있다는 장점이 있다.
그러나, 이 아키텍처는 Layer의 구조가 유연성하지 않다는 단점이 있다. Layer 4는 Layer 3의 행위/기능이 있어야 통신을 한다. 이는 Layer 4가 Layer 3의 행위/기능에 대해 의존적이며, Layer 3이 없어지면 Layer 4의 존재도 없어지므로 Layer 3이 Layer 4의 존재의 전제조건이 된다.
-
🦁 계층형 아키텍처 구조
1) Presentation Layer : View + Controller
사용자와의 최종 접점, 사용자로부터 데이터를 입력받거나 데이터를 출력해서 보이는 레이어이다. 외부로부터 어플리케이션에 대한 요구를 받아들이는 부분이자 처리결과를 사용자에게 보여주는 부분이다.
사용자가 선택할 수 있는 기능 표시, 요청에 필요한 부가적인 정보 전달을 위한 입력 양식, 전달된 자료를 효과적으로 보여주기 위한 프리젠테이션 로직 구현.2) Service Layer = Application layer = Business Layer
핵심 업무 로직 구현, 그에 관련된 데이터의 적합성 검증, 트랜잭션 처리, 다른 레이어들과 통신하기 위한 인터페이스 제공, 해당 레이어의 객체들 사이의 관계 관리
프리젠테이션 레이어와 퍼시스턴스 레이어 사이의 다리 역할.3) Persistence Layer : DAO ( Repository )
영속 계층, 데이터 계층이라고 불리며 어떤 방식으로 데이터를 보관 혹은 사용하는가에 대한 설계가 들어가는 계층이다.영구 데이터를 빼내어 객체화 시키며, 영구 저장소에 데이터를 저장, 수정, 삭제하는 계층이다. 데이터베이스나 파일에 접근하여 데이터를 CRUD하는 계층이며, 이처럼 일반적으로 데이터베이스를 많이 이용하지만 경우에 따라 네트워크 호출이나 원격 호출 등의 기술이 접목될 수 있다.
4) Database Layer : VO
관계형 데이터베이스의 엔티티와 비슷한 개념을 가지는 것으로 데이터 객체를 말한다.
✅ 계층화 아키텍처의 처리과정
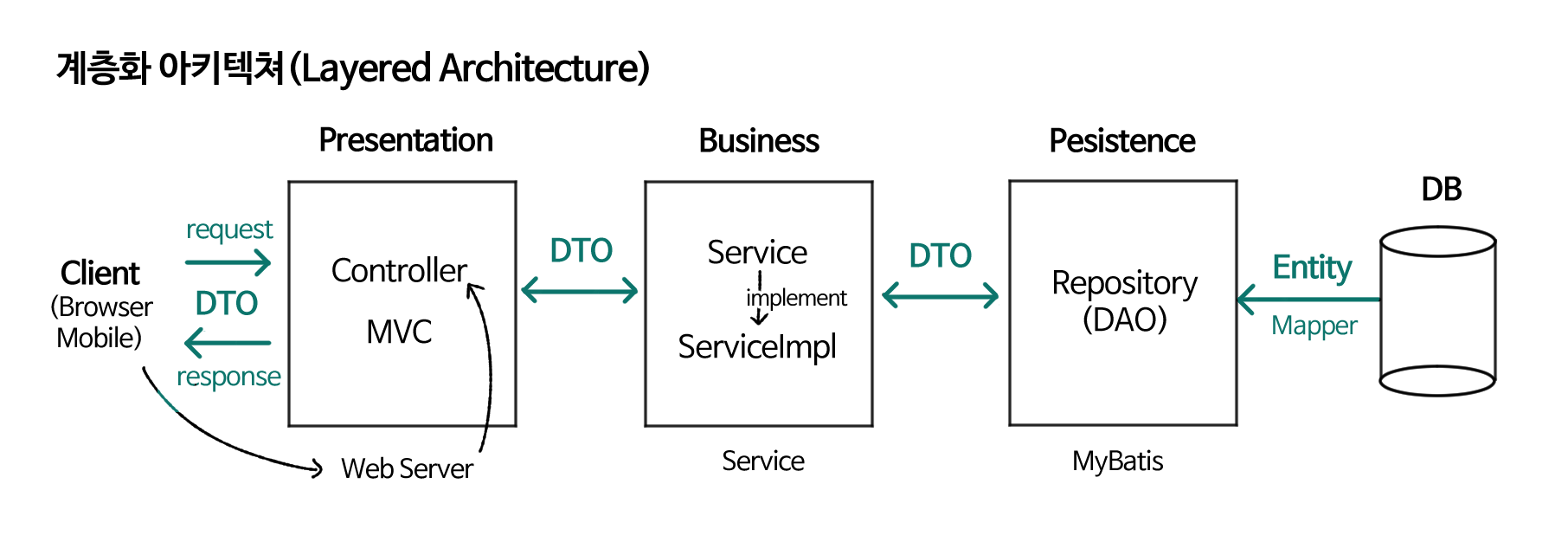
☑ Controller : 어플리케이션의 가장 바깥 부분, 요청/응답을 처리한다.
클라이언트의 요청을 처리 한 후 서버에서 처리된 결과를 반환해주는
역할을 한다.☑ Service : 어플리케이션의 중간 부분, 실제 중요한 작동이 많이 일어나는 부분으로,
아키텍처의 가장 핵심적인 비즈니스 로직이 수행되는 부분이다.☑ Repository : 어플리케이션의 가장 안쪽 부분으로 DB와 맞닿아 있다.
실제 데이터베이스의 데이터를 사용하는 계층이다.1) 클라이언트(Client)가 요청(Request)을 보낸다.
2) 요청(Request)을 URL에 알맞은 컨트롤러(Controller)가 수신받는다.
3) 컨트롤러(Controller)는 넘어온 요청을 처리하기 위해 서비스(Service)를 호출한다.
4) 서비스(Service)는 필요한 데이터를 가져오기 위해 저장소(Repository)에게 데이터를
요청한다.5) 서비스(Service)는 저장소(Repository)에서 가져온 데이터를 가공하여 컨트롤러
(Controller)에게 데이터를 넘긴다.6) 컨트롤러(Controller)는 서비스(Service)의 결과물(Response)을 클라이언트(Client)
에게 전달해준다.
-
DAO ( Data Access Object ) 란❓
실제로 DB에 접근하는 객체다. 프로젝트의 서비스 모델과 실제 DB를 연결하는 역할을 하며, JPA 에서는 DB에 데이터를 CRUD 하는Repositotry객체들이 DAO 라고 할 수 있다. -
DTO ( Data Transfer Object ) 란❓
계층 간 데이터 교환 역할을 한다. DB에서 꺼낸 데이터를 저장하는 Entity를 가지고 만드는 일종의 Wrapper라고 볼 수 있는데, Entity를 Controller 같은 클라이언트단과 직접 마주하는 계층에 직접 전달하는 대신 DTO를 사용해 데이터를 교환한다. -
Entity 란❓
Entity 클래스는 실제 DataBase의 테이블과 1 : 1로 매핑 되는 클래스로, DB의 테이블내에 존재하는 컬럼만을 속성(필드)으로 가져야 한다.
Entity 클래스는 상속을 받거나 구현체여서는 안되며, 테이블내에 존재하지 않는 컬럼을 가져서도 안된다. -
Entity와 DTO를 분리하는 이유❓
View Layer와 DB Layer의 역할을 철저하게 분리하기 위해서이며, 도메인 설계가 아무리 잘 되었다 해도 Getter만을 이용해서 원하는 데이터를 표시하기 어려운 경우가 발생할 수 있는데, 이 경우에 Entity와 DTO가 분리되어 있지 않다면 Entity 안에 Presentation을 위한 필드나 로직이 추가되게 되어 객체 설계를 망가뜨리게 된다.
때문에 이런 경우에는 분리한 DTO에 Presentation 로직 정도를 추가해서 사용하고, Entity에는 추가하지 않아서 도메인 모델링을 깨뜨리지 않는다.
-
Lombok(롬복) 이란❓
롬복은 Java 라이브러리로 반복되는Getter,Setter,toString등의 메서드 작성 코드를 줄여주는 코드 다이어트 라이브러리이다.
보통 Model 클래스나 Entity 같은 도메인 클래스 등에는 수많은 멤버변수가 있고 이에 대응되는Getter와Setter그리고toString()메서드 그리고 때에 따라서는 멤버변수에 따른 여러개의 생성자를 만들어주게 되는데, 거의 대부분 이클립스같은 IDE의 힘만으로 생성한다고 하지만 이 역시도 번거로운 작업이 될 수 있다. 뿐만 아니라 코드 자체가 반복되는 메서드로 인해 매우 복잡해지게 된다. -
롬복은 여러가지 어노테이션을 제공하고 이를 기반으로 코드를 컴파일과정에서 생성해 주는 방식이다. 즉, 코딩 과정에서는 롬복과 관련된 어노테이션만 보이고 getter와 setter 메서드 등은 보이지 않지만 실제로 컴파일된 결과물
(.class)에는 코드가 생성되어 있다는 뜻이다.✅ 롬복 사용방법
@Getter : 변수에 값을 받아갈 수 있는 메소드 생성
@Setter : 변수에 값을 설정할 수 있는 메소드 생성
@ToString : 변수의 값을 출력하는 메소드 생성
@NoArgsConstructor : 매개변수가 없는 생성자 생성
@AllArgsConstructor : 매개변수로 모든 변수의 값을 설정하는 생성자 생성
@Data : 위의 모든 어노테이션을 한번에 적용할 수 있는 어노테이션
실습은 다음글에서 계속... 👉
[참고 자료] : https://lordofkangs.tistory.com/406
