
MSA(MicroService Architecture) 란 ❓
-
MSA는 작고, 독립적으로 배포가 가능한 각각의 기능을 수행하는 서비스로 구성된 프레임워크를 말하는 것으로 애플리케이션을 "느슨하게 결합" 된 서비스의 모임으로 구조화하는 서비스 지향 아키텍처(SOA) 스타일의 일종인 소프트웨어 개발 기법이다.
-
MSA의 등장배경 🧐
MSA는 기존의 모놀리식 아키텍처의 한계를 개선하기 위해 등장하게 되었다. 모놀리식 아키텍처는 모든 구성요소가 한 프로젝트에 통합되어 있는 서비스를 말한다.
웹 개발을 예로 들어보면 지난 글에서도 실습하였듯, 웹 서비스를 배포하기 위해 하나의 스프링 부트 프로젝트를
jar파일로 패키징하여 배포하는 것을 생각해보면 된다.소규모의 프로젝트에서는 모놀리식 형태가 간단하고, 유지보수가 편하여 선호되고 있지만, 일정 규모 이상을 넘어가면 한계점을 맞닥드리게 된다.
-
모놀리식 아키텍처의 한계 🤔
1) 부분 장애가 전체 서비스의 장애로 확대될 수 있다.
➡ ex) 회원의 리뷰기능에 문제가 생겼을때, 서비스 전체가 정지되게 된다.2) 부분적인 "Scale-out(여러 서버로 나눠 일을 처리하는 방식)" 이 어렵다.
3) 서비스의 변경이 어렵고, 수정 시 장애의 영향도 파악이 힘들다.
4) 빌드 시간 및 테스트, 배포하는데 걸리는 시간이 오래 걸린다.
5) 하나의 프레임워크와 언어에 종속적이다.
➡ ex) 스프링 프레임워크를 사용할 경우 특정 기능에 한해서 다른 언어를 사용하면
기능을 보다 더 쉽게 개발할 수 있는 방법이 있지만, 자바를 사용할 수 밖에
없다.
-
🐼 MSA의 특징
이러한 모놀리식 한계점을 개선하여 MSA는 API를 통해서만 모든 구성요소들이 상호작용한다는 특징을 가지고 있다. 제대로 설계 된 MSA는 하나의 비즈니스 범위에 맞춰서 만들어지므로 하나의 기능한 수행하게 된다.✅ 장 점
1) 서비스별 개별 배포가 가능하며 (배포시 전체 서비스의 중단이 없음), 특정 서비스의
요구사항만을 반영하여, 빠르게 배포도 가능하다.2) 특정 서비스에 대한 확장성(scale-out)이 유리하여, 클라우드 기반 서비스 사용에
적합하다.3) 일부 기능에서 발생한 장애가 전체 서비스로 확장될 가능성이 적어 부분적으로
발생하는 장애에 대한 처리가 수월하다.4) 새로운 기술을 적용하는 것에 유연하다. (특정 서비스만 별도의 기술 또는 언어로 구현
가능)
✅ 단 점
1) MSA는 모놀리식 아키텍처에 비해 상대적으로 많이 복잡하다. 서비스가 모두 분산되어
있기 때문에 개발자는 내부 시스템의 통신을 어떻게 가져가야 할지 정해야하며,
통신의 장애와 서버의 부하 등이 있을 경우 어떻게 transaction을 유지할지 결정하고
구현해야한다.MSA에서는 비즈니스에 대한 DB를 가지고 있는 서비스도 각기 다르고, 서비스의
연결을 위해서는 통신이 포함되기 때문에 트랜잭션을 유지하는게 어렵다.2) 통합 테스트가 어렵다. 개발 환경과 실제 운영환경을 동일하게 가져가는 것이 쉽지
않다.3) 실제 운영환경에 대해서 배포하는 것이 쉽지 않다. MSA의 경우 서비스 1개를 재배포
한다고 하면, 다른 서비스들과의 연계가 정상적으로 이루어지고 있는지도
확인해야한다.4) 데이터가 여러 서비스에 분산되어 있어 관리하기 어렵다.
헥사고날 아키텍처(Hexagonal Architecture) 란 ❓
-
레이어드 아키텍처(Layered Architecture) 🧐
지금까지 실습해오면서 작성한 방식은 레이어드 아키텍처를 사용한 방식이었다. 레이어드 아키텍처는 모듈화와 계층화를 통해 시스템을 구성하는 것을 주요 목표로 한다.
따라서, 각 계층은 특정 역할을 수행하며, 계층 간의 의존성은 일반적으로 하위계층에서 상위 계층으로 향한다. 또한, 단일 책임 원칙을 중시하며, 각 계층은 특정 책임에 집중한다는 특징을 가지고 있다.
➡ 장점 : 모듈화 및 유지보수가 용이하고, 각 계층이 명확하게 정의되어 있어, 개발자 간
협업이 편리하다.➡ 단점 : 새로운 요구사항이나 변경이 발생할 경우 전체 계층을 수정해야 할 수 있어서
유연성이 부족하다.
-
헥사고날 아키텍처(Hexagonal Architecture) ✍
-
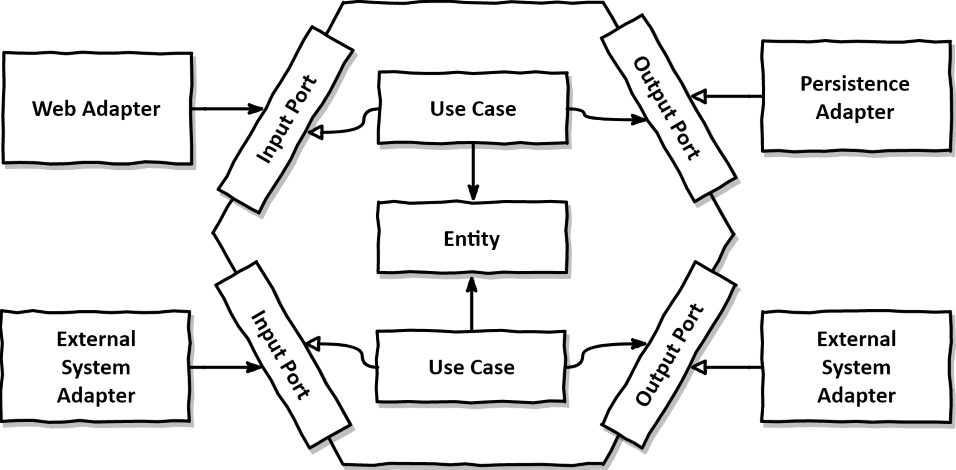
헥사고날 아키텍처, 또는 포트와 어댑터 아키텍처(Ports and Adapters Architecture)는 소프트웨어 아키텍처 중 하나로 주요 목표는 응용 프로그램의 비즈니스 로직을 외부 세계로부터 격리시켜, 유연하고 테스트하기 쉬운 구조를 만드는 것이다.
이를 위해 핵심 비즈니스 로직은 중앙의 도메인 영역에 위치하며, 입력과 출력을 처리하는 포트와 어댑터를 통해 외부와 소통하는 구조이다.
-
헥사고날 아키텍처는 내부 구현의 변경이 외부에 미치는 영향을 최소화하여 유연성을 높이고, 책임이 분리되어 있어 코드의 이해와 수정이 용이하여 유지보수성이 좋다.
또한 각 컴포넌트를 독립적으로 테스트할 수 있고, 외부 의존성 없이 테스트를 할 수 있어서 서비스 품질 향상과 개발 속도 향상에 도움이 된다. -
하지만 그만큼 구현하는 것이 복잡하다는 단점을 가지고 있다.
-
그렇기 때문에 헥사고날 아키텍처가 좋다, 레이어드 아키텍처가 좋다는 것은 없으며 각각의 서비스 특성에 따라 어떠한 아키텍처로 구성하는 것이 효율적인지 생각해 봐야 한다. 따라서, 프로젝트의 규모, 복잡성, 요구사항 등을 분석하여 적절한 아키텍처를 선택하는 것이 중요할 것이다.
🦁 헥사고날 아키텍처 구성해보기
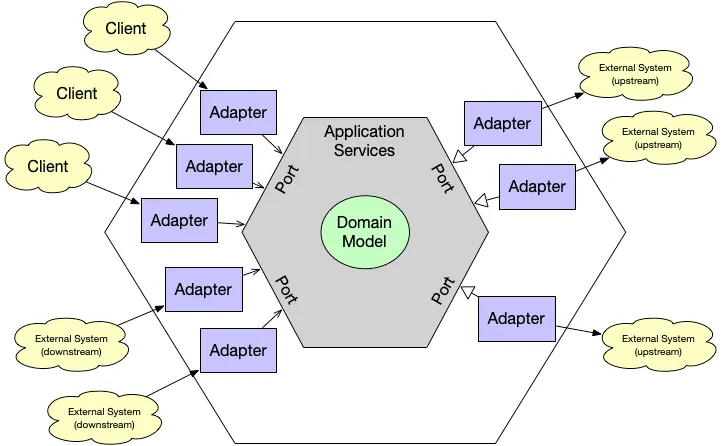
-
요청이 들어왔을 때 동작 순서
1) Web Adapter 로 클라이언트의 요청이 들어온다.
2) Web Adapter는 Input Port(UseCase)를 구현한 Application Service를 호출한다.
3) Application Service로 들어온 요청은 Domain Model로 전달한다.
4) Domain Model은 비즈니스 로직을 처리하고 Output Port를 구현한 외부
시스템과 연결된 Adapter를 호출하여 처리된 데이터를 외부로 저장하거나
외부의 데이터를 가져온다.5) 필요 시 Application Service는 Domain의 처리 결과를 받아서 클라이언트에게
반환한다.
-
패키지 구성도 ( 회원 등록과 수정 기능 )
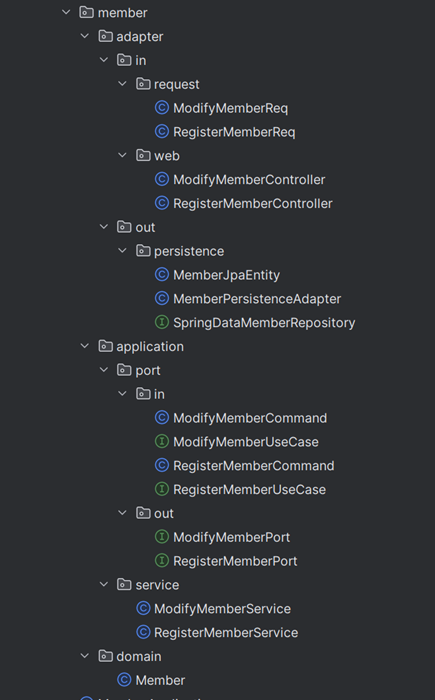
-
이해가 안되어 정리하는 부분 ( 도메인과 엔티티의 차이 )
✍ 도메인(Domain)
도메인은 소프트웨어 시스템이 다루는 실제 문제 영역이나 비즈니스 도메인을 나타낸다. 비즈니스 규칙, 프로세스, 용어 등을 포함하며, 소프트웨어가 해결해야 하는 실제 문제들을 반영한다.
➡ ex) 은행 서비스의 도메인 : 고객, 계좌, 거래와 같은 은행 업무와 관련된 모든 영역✍ 엔티티(Entity)
엔티티는 도메인에서 특정한 객체를 나타내는 개념입니다. 고유한 식별자를 가지며, 상태와 행동을 가진 객체로 구현된다.
➡ ex) 은행 도메인에서의 "계좌"는 엔티티이다. 각 계좌는 고유한 계좌 번호로 식별되며,
잔액과 같은 상태를 가지고 입금, 출금과 같은 행동을 수행한다.
💻 도메인
@Getter
@Setter
@AllArgsConstructor
@Builder
public class Member {
private final Long id;
private final String email;
private final String password;
private final String nickname;
private final Boolean status;
}💻 Web Adapter 클래스 ( Primary Adapter )
@RestController
@RequiredArgsConstructor
@WebAdapter // 단순 WebAdapter라는 이름을 보여주는 커스텀 어노테이션 (기능은 없다)
public class RegisterMemberController {
private final RegisterMemberUseCase registerMemberUseCase;
@RequestMapping(method = RequestMethod.POST, value = "/member/register")
Member registerMember(@RequestBody RegisterMemberReq registerMemberReq) {
RegisterMemberCommand registerMemberCommand = RegisterMemberCommand.builder()
.email(registerMemberReq.getEmail())
.password(registerMemberReq.getPassword())
.nickname(registerMemberReq.getNickname())
.status(true)
.build();
Member result = registerMemberUseCase.registerMember(registerMemberCommand);
return result;
}
}💻 RegisterMemberReq DTO
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
public class RegisterMemberReq {
private String email;
private String password;
private String nickname;
}
💻 @WebAdapter (커스텀 어노테이션)
@Target({ElementType.TYPE}) // 클래스나 인터페이스 등에 적용한다
@Component
@Retention(RetentionPolicy.RUNTIME) // 런타임까지 어노테이션이 유지된다
@Documented // 어노테이션을 사용한 곳의 문서에 이 어노테이션 정보가 나타난다.
public @interface WebAdapter { // 어노테이션의 이름을 설정한다
// Component 어노테이션의 Value 속성과 동일하게 적용시키겠다 (@어노테이션이름("test") == @Component("test")
@AliasFor(annotation = Component.class)
String value() default "";
}💻 Input Port ( UseCase )
// Application Service에 의해 구현되는 인터페이스
public interface RegisterMemberUseCase {
Member registerMember(RegisterMemberCommand registerMemberCommand);
}💻 Application Service 클래스
@Service
@RequiredArgsConstructor
public class RegisterMemberService implements RegisterMemberUseCase {
private final RegisterMemberPort registerMemberPort;
@Override
public Member registerMember(RegisterMemberCommand registerMemberCommand) {
Member member = Member.builder()
.email(registerMemberCommand.getEmail())
.password(registerMemberCommand.getPassword())
.nickname(registerMemberCommand.getNickname())
.status(registerMemberCommand.getStatus())
.build();
MemberJpaEntity memberJpaEntity = registerMemberPort.createMember(member);
return Member.builder()
.id(memberJpaEntity.getId())
.email(memberJpaEntity.getEmail())
.password(memberJpaEntity.getPassword())
.nickname(memberJpaEntity.getNickname())
.status(memberJpaEntity.getStatus())
.build();
}
}💻 검증용 DTO
@Getter
@Setter
@Builder
public class RegisterMemberCommand {
@NonNull
private final String email;
@NonNull
private final String password;
@NonNull
private final String nickname;
private final Boolean status;
public RegisterMemberCommand(String email, String password, String nickname, Boolean status) {
this.email = email;
this.password = password;
this.nickname = nickname;
this.status = status;
// TODO : 검증하는 코드 추가 예정
}
}💻 Output Port
// Persistence Adapter에 의해 구현되는 인터페이스
public interface RegisterMemberPort {
MemberJpaEntity createMember(Member member);
}💻 Persistence Adapter
@Component
@RequiredArgsConstructor
@PersistenceAdapter
public class MemberPersistenceAdapter implements RegisterMemberPort {
private final SpringDataMemberRepository springDataMemberRepository;
@Override
public MemberJpaEntity createMember(Member member) {
MemberJpaEntity memberJpaEntity = MemberJpaEntity.builder()
.email(member.getEmail())
.nickname(member.getNickname())
.password(member.getPassword())
.status(member.getStatus())
.build();
springDataMemberRepository.save(memberJpaEntity);
System.out.println(memberJpaEntity);
return memberJpaEntity;
}
} 💻 엔티티 객체
@Entity
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Getter
@Setter
public class MemberJpaEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String email;
private String password;
private String nickname;
private Boolean status;
}
💻 Secondary Adapter ( 외부와 통신이 필요한 도메인 모델을 연결 )
@Repository
public interface MemberJpaRepository extends JpaRepository<MemberJpaEntity, Long> {
public Optional<MemberJpaEntity> findByEmail(String email);
}Api GateWay 란 ❓
-
MSA를 사용하면 애플리케이션의 다양한 기능을 개발, 배포 및 유지 관리하기에 좋지만, 고객이 애플리케이션에 빠르고 안전하게 액세스하기가 더 어려워질 수도 있다. 이러한 문제를 해결해주는 것이 API 게이트웨이다.
고객이 각 MSA에 대한 액세스를 개별적으로 요청하는 대신, 게이트웨이가 모든 요청에 대한 단일 진입 점의 역할을 하여, 각각의 요청을 적절한 서비스에 전달하고 그 결과를 클라이언트에게 다시 전달한다.
따라서 API Gateway를 이용하면 통합적으로 엔드포인트와 REST API를 관리할 수 있다.
API 게이트웨이를 등록해주면, 모든 클라이언트는 각 서비스의 엔드포인트 대신 API Gateway로 요청을 전달하여 관리가 용이해 진다. 사용자가 설정한 라우팅 설정에 따라 각 엔드포인트로 클라이언트를 대리하여 요청하고 응답을 받으면 다시 클라이언트에게 전달하는 프록시(proxy) 역할을 하기 때문이다.API Gateway 서비스는 단순히 api 경유지 역할 뿐만 아니라, 엔드포인트 서버에서 공통으로 필요한 인증/인가, 사용량 제어, 요청/응답 변조 등의 다양한 기능을 플러그인 형태로 제공하고 있다.
이러한 플러그인을 API 게이트웨이에서 사용하면, 각 엔드포인트의 서버마다 위의 기능들을 구현하지 않아도 되기 때문에 개발자 입장에서는 개발 비용을 줄일 수 있다는 효과도 있다.
-
🐻 Api GateWay 설정하기
1)
pom.xml파일에 라이브러리 추가<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> <version>3.1.3</version> </dependency>2)
application.yml파일에 설정 추가server: port: 9999 # SCG(스프링 클라우드 게이트웨이) # route : 어떤 URL로 오면 어떤 서버를 실행시켜 주겠다. predicates와 filter로 구성되어 있고, predicates에 일치하는 요청을 URI로 전달 # predicates : SCG로 들어온 요청에서 확인할 조건 # filter : SCG로 들어오는 요청에 대해 선처리 및 후처리할 때 사용하는 기능 spring: application: name: gateway cloud: gateway: routes: - id: member-service uri: http://localhost:8080 predicates: - Path=/member/** -
이렇게 설정을 하면 클라이언트가
http://localhost:9999로 회원 서비스와 관련된
요청을 보내면,http://localhost:8080을 호출하여 요청을 처리한다. -
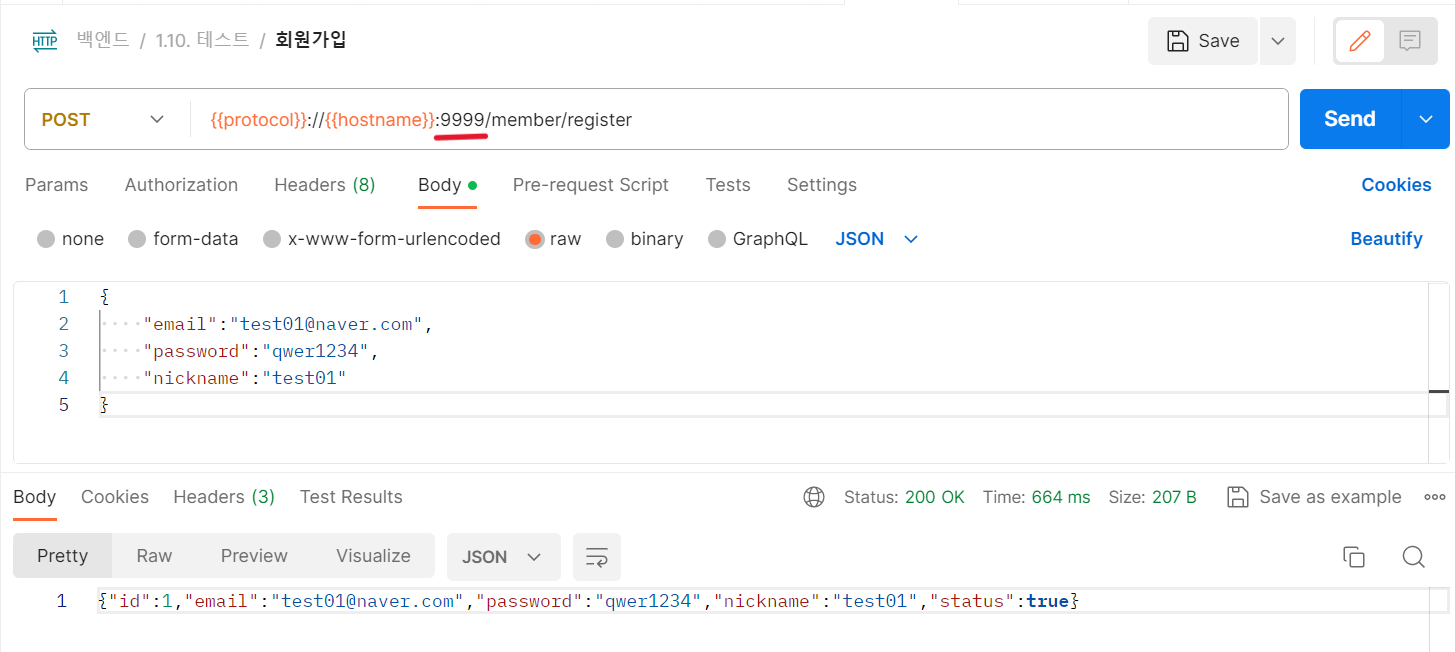
아래는 포스트맨으로 API 요청을 보낸 결과이다.
Apache Kafka 란 ❓
-
카프카(Kafka)는 높은 확장성과 내결함성, 대용량 데이터 처리, 실시간 데이터 처리에 특화되어 있는 오픈소스 메시징 시스템이다. Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산환경에 특화되어 있다.
-
메시지 큐(Message Queue, MQ) 란 ❓
메시지 큐는 메시지 지향 미들웨어(MOM : Message Oriented Middleware)를 구현한 시스템으로 프로그램(프로세스) 간의 데이터를 교환할 때 사용하는 기술이다.
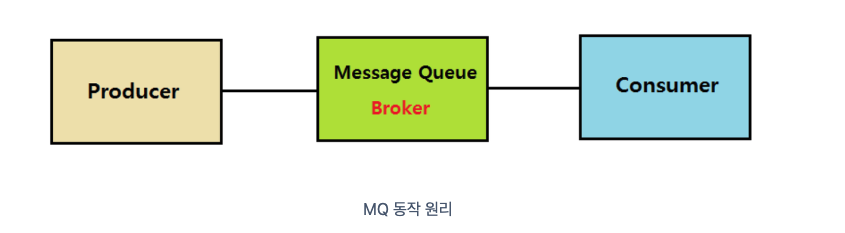
➡ Producer : 정보를 제공하는 자
➡ Consumer : 정보를 제공받아서 사용하려는 자
➡ Queue : Producer의 데이터를 임시 저장 및 Consumer에 제공하는 곳➡ Broker : 실행된 카프카 서버를 말한다.
프로듀서와 컨슈머는 별도의 애플리케이션으로 구성되는 반면, 브로커는
카프카 자체이다.
Broker(각 서버)는 Kafka Cluster 내부에 존재하며, 서버 내부에 메시지를
저장하고 관리하는 역할을 수행한다.➡ Zookeeper : 분산 애플리케이션 관리를 위한 코디네이션 시스템으로, 분산
메시지큐의 메타 정보를 중앙에서 관리하는 역할을 수행한다. -
이러한 카프카를 MSA에서 사용하는 가장 큰 이유는 비동기로 데이터를 처리하기 위함으로, 이벤트/데이터가 발생했다면 발생 주체가 카프카로 해당 이벤트/데이터를 전달한다. 그리고 해당 이벤트/데이터가 필요한 곳에서 직접 가져다 사용한다.
-
예를 들어 회원 서비스에서 새로운 회원이 가입되었다는 메시지를 카프카로 전달한다. 이 메시지를 멤버십 서비스가 컨슘하여 새로운 회원에게 가입 축하 멤버십 포인트를 생성해 부여한다. 동시에 하둡은 이 메시지를 컨슘하여 해당 유저에 대한 데이터를 빅데이터에 저장해 분석한다. 또한 동시에 로그 스태시(로그 수집 시스템)는 이 메시지를 컨슘하여 개발자가 디버깅할 때 사용할 수 있도록 로그를 생성한다.
카프카가 없었다면 회원 서비스가 멤버십 서비스, 하둡, 로그 스태시로 각각 다른 데이터 파이프라인을 통해 데이터를 전송해야 했을 것이다. 이에 반해 카프카를 사용하여 데이터 흐름을 중앙화한다면, 복잡도가 드라마틱하게 낮아지는 것을 확인할 수 있다.
🐷 Kafka 설치 및 브로커 서버 작동 테스트하기
-
준비사항 : 리눅스 가상머신 3대 ( 1대 : 주키퍼/브로커 서버, 2대 : 프로듀서, 컨슈머 서버)
-
✅ Kafka 설치방법
1) 리눅스 서버 3대 모두 IP 설정 및 방화벽을 꺼준다.
2) 공식홈페이지에서 Kafka 파일을 다운받는다.
(https://www.apache.org/dyn/closer.cgi?path=/kafka/3.2.1/kafka_2.13-3.2.1.tgz)3) 리눅스 서버 3대에 다운로드한 파일을 옮긴다. ( 다음 순서들도 3대 전부 동일 )
➡ 윈도우 CMD 창 :scp [파일명] [리눅스계정명]@[IP주소]:[경로]4) 옮긴
tar파일의 압축을 해제한다 :tar -xvzf [파일명]5) 압축해제된 폴더로 이동한다 :
cd [파일명]6) open jdk 11 설치 :
yum install java-11-openjdk-devel.x86_64
➡ 환경변수 설정 :vi /etc/profile
➡ 제일 밑에 JAVA_HOME 설정 추가 :
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.18.0.9-0.3.ea.el8.x86_64
➡ 설정 후 변경사항 적용 :source /etc/profile7) 주키퍼/브로커 서버에서 주키퍼 실행
➡./bin/zookeeper-server-start.sh ./config/zookeeper.properties8) 주키퍼/브로커 서버의 PUTTY 창을 1개 더 띄워서 브로커 서버 설정
➡vi config/server.properties
➡ 38번째 수정 :advertised.listeners=PLAINTEXT://[브로커 서버 IP로 수정]:9092
➡ 브로커 서버 실행 :./bin/kafka-server-start.sh ./config/server.properties9) 프로듀서 서버 실행
➡./bin/kafka-console-producer.sh --topic test --bootstrap-server [브로커서버ip:9092]10) 컨슈머 서버 실행
➡./bin/kafka-console-consumer.sh --topic test --bootstrap-server [브로커 서버ip:9092]11) 프로듀서 서버에서 텍스트를 입력했을때, 컨슈머 서버에 입력한 테스트가 출력되면
정상적으로 브로커 서버가 동작하고 있는 것이다.
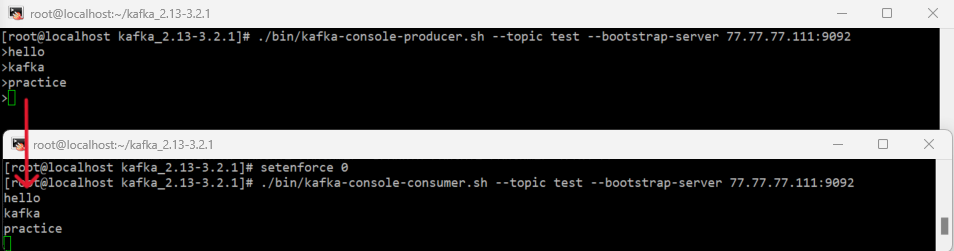
-
프로듀서 서버와 컨슈머 서버는 브로커 서버의 동작을 테스트해보기 위해 설치 후 실행해본 것이고, 실제로는 브로커 서버 1대만 있으면 된다.
