🐹 실습 전 사전 준비 사항
-
도커 허브에 이미지를 3개 만들어서 버전을 다르게 하여 올려 놓는다.
-
나는 스프링 부트에서 컨트롤러만 생성하여
/test/version으로 요청을 보내면, 응답으로 "V1 / V2 / V3 출력하는 이미지" 라는 내용을 반환토록 작성하여 이미지를 푸쉬해놨다.
🐶 무중단 배포 방법 실습
-
지난 글에서 Deployment를 생성할때 Recreate 방식을 사용하였는데, Recreate 방식은 버전 업데이트 시 실행중인 모든 파드를 한번에 삭제시키고 새로운 버전의 파드를 생성하기 때문에, 잠시동안 서버에 다운타임이 발생하게 되는 문제가 있다.
-
Recreate 방식 테스트 하기 💻
1. Recreate 방식으로 Deployment 생성하기
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
spec:
replicas: 2
strategy:
type: Recreate
minReadySeconds: 10
selector:
matchLabels:
type: backend
template:
metadata:
labels:
type: backend
spec:
containers:
- name: backend
image: [버전1 의 이미지 이름]
terminationGracePeriodSeconds: 5 2. LoadBalancer 로 서비스 생성하기
apiVersion: v1
kind: Service
metadata:
name: backend-svc
spec:
selector:
type: backend
ports:
- port: 8080
targetPort: 8080
type: LoadBalancer3. 테스트 명령어 입력 : 1초에 한번씩 생성한 컨트롤러로 요청 보내보기
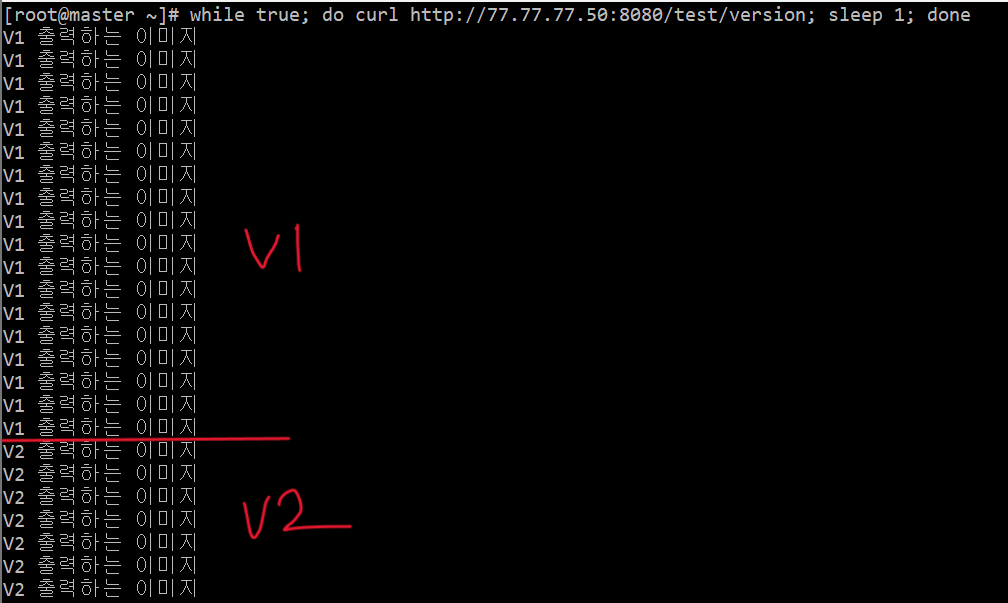
➡ while true; do curl http://[서비스 IP]:8080/test/version; sleep 1; done
4. 생성한 Deployment의 리소스 편집에서 이미지의 버전을 1.0 ➡ 2.0 으로 수정
-
이렇게 하면 처음에는 V1 이 출력되다가, 버전을 수정한 순간 아래처럼 잠시동안 다운타임이 생겼다가 V2가 출력되는 것을 볼 수 있다.
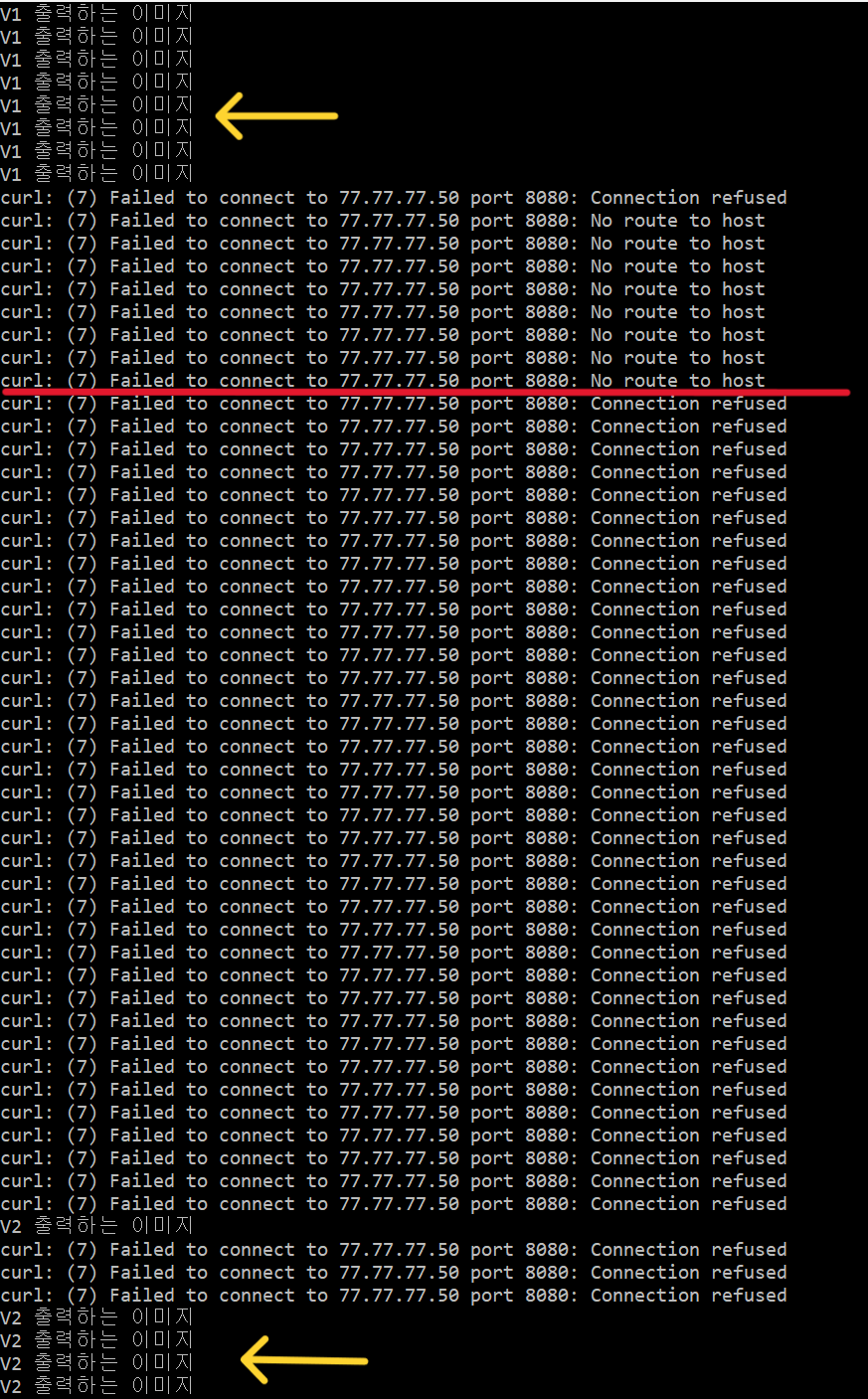
-
위의 사진을 보면 총 2가지의 실패 문장이 있다.
1)
No route to host: 이것은 파드가 삭제되고 생성되는 동안 찾아갈 주소가 없어서
발생되는 것이다.2)
Connection refused: 이것은 스프링 부트 서버가 실행되는 동안 발생되는 것이다.
-
이제 이러한 다운타임을 해결하기 위한 방법으로 Deployment의 또다른 방식인
RollingUpdate방식으로 생성을 해보겠다.➡ RollingUpdate 방식은 버전 업데이트 시 새로운 버전의 파드 1개를 먼저 생성하고,
생성되면 기존 파드 1개를 삭제하는 방식으로 진행된다.
( 인줄 알았으나, 설정할 수 있는 내용이 있어, 밑에서 추가 설명 예정)
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
spec:
replicas: 2
strategy:
type: RollingUpdate
minReadySeconds: 10
selector:
matchLabels:
type: backend
template:
metadata:
labels:
type: backend
spec:
containers:
- name: backend
image: [이미지 이름]
terminationGracePeriodSeconds: 5➡ 생성하는 방법은 위처럼 아예 새로 생성해도 되고, 위에서 생성했던 Deployment의 리소스
편집에서 type을 Recreate에서 RollingUpdate로 바꿔줘도 된다.
➡ 그런다음 위에서 실시한 것처럼 똑같이 테스트를 해보면 아래와 같이 결과가 나타날
것이다.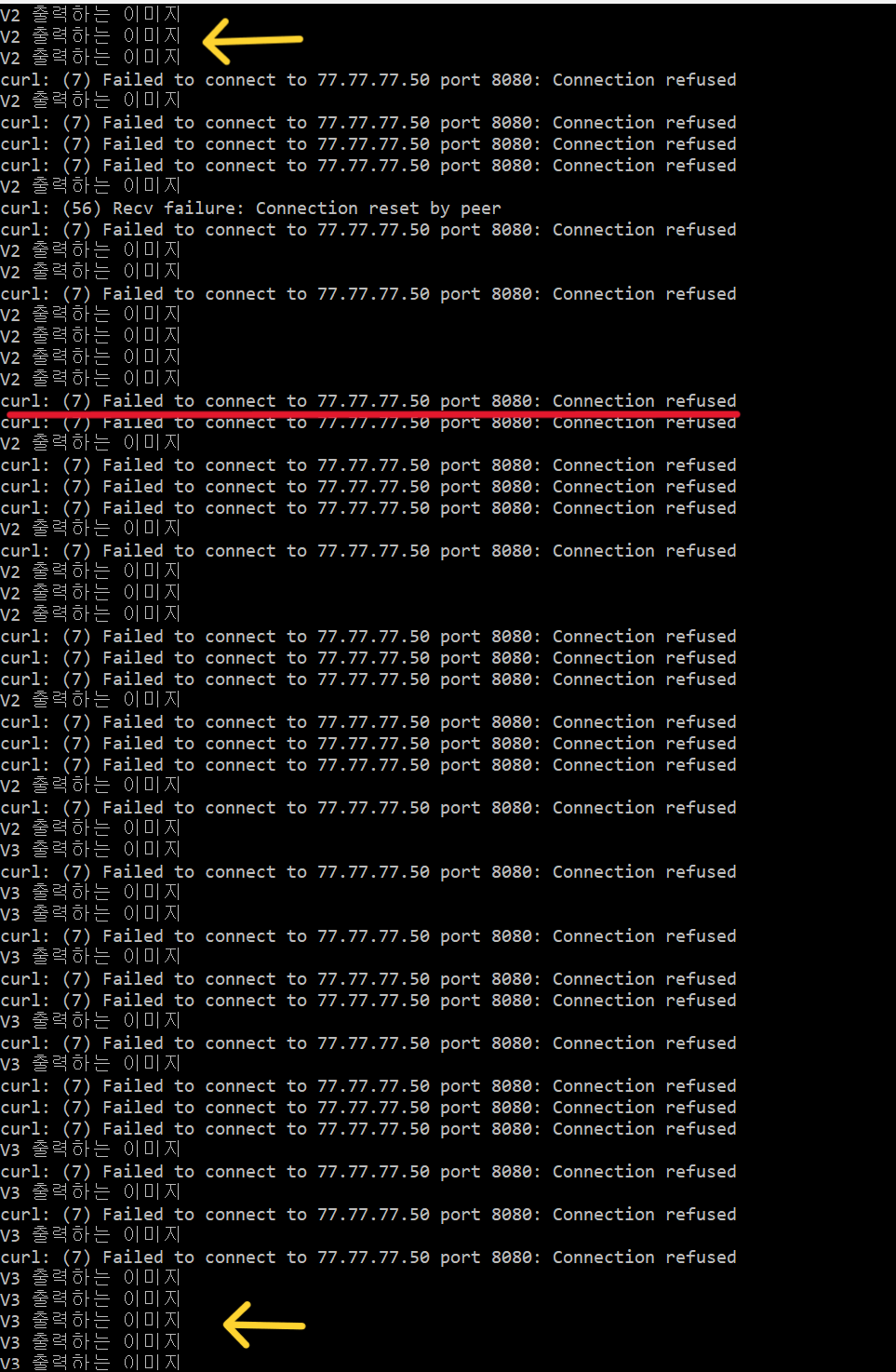
- 위의 사진을 보면 버전 2에서 버전 3으로 바뀔 동안, Recreate 방식에서 나타났던
No route to host실패 문장은 사라졌지만,Connection refused는 여전히 발생하는 것을 확인할 수 있다.
-
따라서, 이부분까지 해결해주기 위해서는 Probe 를 적용할 수 있다.
-
여러 종류가 있겠지만, 나는 readinessProbe를 적용해보겠다. readinessProbe를 적용하여 아래와 같이 Deployment를 생성한다.
apiVersion: apps/v1 kind: Deployment metadata: name: backend-deployment spec: replicas: 2 strategy: type: RollingUpdate minReadySeconds: 10 selector: matchLabels: type: backend template: metadata: labels: type: backend spec: containers: - name: backend image: [이미지 이름] readinessProbe: // 여기부터 추가 된 내용 httpGet: path: /test/version // 요청을 보내는 경로 ( 작동하는지 확인 ) port: 8080 initialDelaySeconds: 5 // 파드가 시작되고 readinessProbe를 시작하기 전 대기 시간 ( 5초 ) periodSeconds: 2 // readinessProbe를 수행하는 주기 ( 2초마다 실행 ) successThreshold: 3 // 성공으로 간주하는 연속 성공 횟수 ( 연속 3번 성공해야 성공 ) terminationGracePeriodSeconds: 5 -
readinessProbe는 Pod가 서비스 요청을 수신할 준비가 되었는지 확인하여, 준비가 되면 요청을 보내는 방식이다.
-
위 처럼 설정하면,
/test/version으로 요청을 보냈을때 연속해서 3번 성공해야 성공한것으로 간주하고 그때부터 본격적으로 요청을 보내게 된다. -
그럼 이제, 기존처럼 똑같이 테스트를 해보면 아래와 같이 서버의 다운타임 없이 완전한 무중단 배포 ( 버전 업데이트 ) 가 되는 것을 볼 수 있다.
➡ 정상적이라면 아래처럼 출력될 것이다. 하지만, 컴퓨터 사양에 따라 1 ~ 2초 정도
Connection refused가 출력될 수 있는데, 이 부분은 생성할때 조건을 조절하면
될 것이다. ( 내가 실제로 테스트 진행 간 그랬다... )

🔥 RollngUpdate 설정 알게된 내용 정리 (24. 2.17. 추가)
-
인프런 일프로님의 강의를 들으면서 알게된 내용이 있어, 다시 정리 한다.
-
위에서, RollingUpdate로 Deployment를 생성하면, 파드가 1개씩 생성되고 삭제된다고 적었는데 알고보니 이것은 RollingUpdate에서 Pod를 생성하고 삭제하는 설정 내용이 기본값으로 설정이 되있어서 그랬던 것이었다.
-
아래는 설정 내용을 적용한 Deployment 생성 야멜 파일이다.
apiVersion: apps/v1 kind: Deployment metadata: name: backend-deployment spec: replicas: 2 strategy: type: RollingUpdate rollingUpdate: <-- 새로 추가한 설정 🔥🔥 maxUnavailable: 25% <-- 기본값으로, 별도로 설정해주지 않으면 적용되는 값 maxSurge: 25% <-- 기본값으로, 별도로 설정해주지 않으면 적용되는 값 minReadySeconds: 10 selector: matchLabels: type: backend template: metadata: labels: type: backend spec: containers: - name: backend image: [이미지 이름] terminationGracePeriodSeconds: 5 -
maxUnavailable : 롤링 업데이트 중에 허용되는 동시에 사용할 수 없는 파드의 최대 비율을 나타낸다. 즉, 업데이트 동안 최대 몇개의 파드를 서비스 중지시킬 것인지 설정하는 것이다.
-
maxSurge : 롤링 업데이트 시 최대 몇개까지 파드를 동시에 만들 것인지 설정하는 것이다.
-
만약, maxUnavailable: 100%, maxSurge: 100% 로 설정한다면, 버전 업데이트 시 전체 파드를 서비스 중지로 만들고, 새로 생성하는 것 또한 전체 파드 개수만큼 한번에 생성하게 된다.
Deployment의 기능을 알고 있다면, 이러한 작동 방식이 Deployment의 Recreate 방식과 동일하다는 것을 알 것이다. 이처럼 직접 설정해 줄 수 있기 때문에
따라서, maxUnavailable: 0%, maxSurge: 100% 로 설정을 한다면, 2개의 파드를 기준으로 했을 때 버전 업데이트 시 새로운 버전의 파드가 2개가 한번에 생성되고, 생성이 완료되면 기존 파드 2개가 1개씩 순차적으로 삭제되는 형태가 된다.
-
아래는 실습해본 영상이다. ( 실습 코드는 아래와 같음 )
apiVersion: apps/v1 kind: Deployment metadata: name: backend-deployment spec: replicas: 2 strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 0% maxSurge: 100% minReadySeconds: 10 selector: matchLabels: type: backend template: metadata: labels: type: backend spec: containers: - name: backend image: [이미지 이름] terminationGracePeriodSeconds: 5
-
지금까지는 Deployment의 2가지 방식인 Recreate 와 RollingUpdate에 대해서 실습해봤는데, 이번에는 쿠버네티스의 기능을 이용한 무중단 배포 방식인
Blue/Green방식을 실습해보겠다. -
Blue/Green방식은 Deployment를 생성할 때 버전을 명시해주고, 서비스를 생성할때도 버전을 명시해서 나중에 버전 업그레이드 시 업그레이 된 버전의 새로운 Deployment를 생성하고 그 버전으로 서비스도 변경해주는 방식이다.➡ 버전은 원하는대로 지어준 뒤 서비스와 Deployment 간 매칭만 잘 해주면 된다.
1) Deployment를 생성한다. ( 버전 명시 )
apiVersion: apps/v1 kind: Deployment metadata: name: backend-deployment-1 spec: replicas: 2 strategy: type: Recreate revisionHistoryLimit: 1 selector: matchLabels: type: backend version: v1 // 버전 명시 ( 임의 지정 ) template: metadata: labels: type: backend version: v1 // 버전 명시 ( 임의 지정 ) spec: containers: - name: backend image: [이미지 이름]
2) 서비스를 생성한다. ( 버전 명시 )
apiVersion: v1 kind: Service metadata: name: backend-svc spec: selector: type: backend version: v1 // 버전 명시 ( 위에서 설정한 이름 ) ports: - port: 8080 targetPort: 8080 type: LoadBalancer
3) 업그레이드 버전의 새로운 Deployment를 생성한다. ( 바뀐 버전 명시 )
apiVersion: apps/v1 kind: Deployment metadata: name: backend-deployment-2 spec: replicas: 2 strategy: type: Recreate revisionHistoryLimit: 1 selector: matchLabels: type: backend version: v2 // 바뀐 버전 명시 ( 임의 지정 ) template: metadata: labels: type: backend version: v2 // 바뀐 버전 명시 ( 임의 지정 ) spec: containers: - name: backend image: [이미지 이름]
4) 서비스의 리소스 편집에서 버전을 v1에서 v2로 바꿔준다.
-
위의 절차대로 테스트를 하면 아래와 같이 버전이 업데이트 될 때 다운타임 없이 업데이트가 성공적으로 이뤄지는 것을 확인할 수 있다.
-
실무에서는 이처럼 Deployment를 2개 생성해 놓고, 운영을 안하는 Deployment는 Pod를 0으로 설정해놨다가, 버전 업데이트 시 해당 Deployment의 Pod를 늘리고, 업데이트 된 버전으로 적용한 다음,
서비스의 버전을 바꾸고, 기존 Deployment의 Pod 개수를 다시 0으로 바꾸는 식으로 계속 Deployment 2개를 바꿔가며 사용하기도 한다고 한다.
🧐 알고 있으면 유용한 옵션 : revisionHistoryLimit
-
revisionHistoryLimit 옵션은 버전 업데이트 시 지정한 개수만큼 레플리카 셋을 남겨놓도록 하는 설정이다.
-
주로, 업데이트를 잘못했을 때 되돌아가기 위해 사용한다고 한다.
-
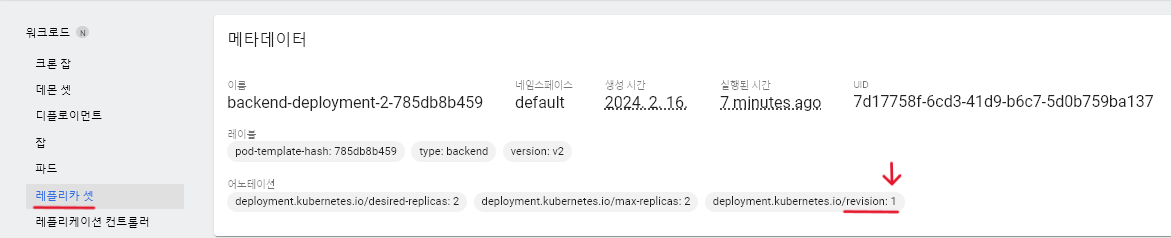
버전 히스토리 출력 :
kubectl rollout history deployment [디플로이언트 이름]

-
버전 롤백 : 버전 숫자는 히스토리 출력 또는 레플리카 셋을 클릭해보면 볼 수 있다.
kubectl rollout undo deployment [디플로이언트 이름] --to-revision=[버전숫자]
🦁 Istio 설치하기
-
쿠버네티스에서 모니터링 시스템을 구축하는 방법으로는
1) 도커 허브에 올려져 있는 이미지 활용
2) Helm 차트 활용
3) MSA와 같은 서비스 매쉬에서 사용되는 Istio 활용이렇게 총 3가지가 있는데, 나는 3번째 방식을 실습하였다.
-
Istio 란 ❓
쿠버네티스는 도커를 편리하게 컨트롤할 수 있으며, 다양한 이점을 제공한다. 하지만 다수의 컨테이너가 동작할 때 컨테이너의 트래픽을 관찰하고 정상 동작하는지 모니터링하는 것은 그만큼 매우 어렵다.
따라서, 이를 해결해주는 것이 서비스 매쉬란 개념이고, 이에 대한 구현체 중 하나가 Istio이다.
✅ Istio의 장점
➡ 쿠버네티스의 복잡성을 감소시킬 수 있다.
➡ 트러블 슈팅과 디버깅이 매우 쉬워져서 운영하는데 큰 도움을 준다.✅ Istio의 단점
➡ 각 Pod당 Sidecar 형태로 컨테이너가 1개씩 더 붙기 때문에 성능이 떨어진다.
-
Service Mesh 란❓
Mesh란 그물, 망사라는 뜻을 가지고 있으며, Service Mesh는 Serivce들이 그물처럼 엮여있는것을 뜻한다.
MSA를 적용한 시스템의 내부 통신이 그물(Mesh) 네트워크의 형태를 띄는 것에 빗대어 Service Mesh로 불리게 되었다.
애플리케이션 계층이 아닌 인프라 플랫폼 계층에 특정 모듈을 삽입하여 애플리케이션에 대한 라우팅, 보안 및 안정성 기능을 추가하는 도구로, 쿠버네티스와 같은 컨테이너 오케스트레이션 환경에서 일반적으로 애플리케이션 코드(사이드 카 라고 불리는 패턴)와 함께 배치된 확장 가능한 네트워크 프록시 모듈로 구현된다.
Service Mesh를 사용하는 이유는❓서비스 메시 없이 동작하는 마이크로 서비스는 서비스 간 커뮤니케이션을 통제하는 로직으로 코딩해야 하기 때문에 개발자들이 비즈니스 로직에 집중하지 못하게 된다.
또한, 서비스 간 커뮤니케이션을 통제하는 로직이 각 서비스 내부에 숨겨져 있기 때문에 커뮤니케이션 장애를 진단하기 더 어려워진다.
수십 개의 마이크로 서비스가 분리되어 있고, 서비스 간의 통신도 매우 복잡하여 새로운 장애 지점이 계속 나타나게 된다면 서비스 메시 없이는 문제가 발생한 지점을 찾아내기가 어려울 것이다.
✅ Service Mesh의 장점1) 서비스 간 커뮤니케이션의 모든 부분을 성능 메트릭으로 캡처할 수 있다.
2) 개발자 들은 비즈니스 로직에 집중할 수 있다.
3) 문제를 손쉽게 인식하고 진단할 수 있다.
4) 장애가 발생한 서비스로부터 요청을 재 라우팅 할 수 있기 때문에 애플리케이션 복구 능력이
향상된다.
5) 성능 메트릭을 통해 런타임 환경에서 커뮤니케이션을 최적화하는 방법을 제안할 수 있다.
-
Side Car 패턴이란❓
애플리케이션 컨테이너와 독립적으로 동작하는 별도의 컨테이너를 붙이는 패턴으로, 오토바이에 연결된 사이트와 유사하기 때문에 사이드 카 패턴이라고 불린다.
애플리케이션 컨테이너와 독립적으로 동작하기 때문에, 사이드카 장애 시 애플리케이션이 영향을 받지 않고, 사이드카 적용/변경/제거 등의 경우에 애플리케이션은 수정이 필요가 없다.
-
설치 방법 💻 설치 문서 바로가기
1) Calico 설정 변경
kubectl patch FelixConfiguration default --type=merge --patch \ '{"spec": {"policySyncPathPrefix": "/var/run/nodeagent"}}'
kubectl patch installation default --type=merge -p '{"spec": {"flexVolumePath": "None"}}'➡ 이때 아래처럼 error 라고 출력되는데 이것은 신경쓰지 않아도 된다.

2) Calico CSI (Container Storage Interface) 드라이버 설치 : 모든 노드에서 정책 동기화 API 설정
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/csi-driver.yaml
3) 명령어(프로그램) 설치
curl -L https://git.io/getLatestIstio | ISTIO_VERSION=1.15.2 sh -
echo "export PATH=$HOME/istio-1.15.2/bin:$PATH" >> ~/.bashrc
source .bashrc
4) Istio 컨트롤 플레인 설치
➡
istioctl install --set components.cni.enabled=true -y➡ 정상적으로 설치된다면, 아래 사진처럼 출력된다.

➡ 만약 설치가 제대로 안되면, 아래 명령어로 삭제한 뒤 다시해봐야된다.
➡istioctl x uninstall --purge이때, 완전히 삭제되는지 확인을 해야되고, 가상 컴퓨터 재부팅도 방법이 될 수
있을 것이다.
5) namespace 변경
kubectl create -f - <<EOF apiVersion: security.istio.io/v1beta1 kind: PeerAuthentication metadata: name: default-strict-mode namespace: istio-system spec: mtls: mode: STRICT EOF
6) Istio 사이드 카 중 Dikastes 설치
curl https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/alp/istio-inject-configmap-1.15.yaml -o istio-inject-configmap.yaml
kubectl patch configmap -n istio-system istio-sidecar-injector --patch "$(cat istio-inject-configmap.yaml)"
7) addon 설치 ( Istio의 기본 기능 외 추가적인 기능 사용 목적 )
➡ Prometheus : 클러스터 내의 모니터링 및 지표 수집을 위한 기능
설치 명령어 :kubectl apply -f istio-1.15.2/samples/addons/prometheus.yaml➡ Grafana : 프로메테우스로부터 수집한 지표를 시각화하고, 대시보드로 표시하기 위한 기능
설치 명령어 :kubectl apply -f istio-1.15.2/samples/addons/grafana.yaml➡ Jaeger : 분산 추적을 지원하기 위한 기능 ( 각 서비스 간의 통신 추적 및 디버깅 )
설치 명령어 :kubectl apply -f istio-1.15.2/samples/addons/jaeger.yaml➡ Kiali : 서비스 맵, 트래픽 흐름 및 메트릭을 시각화하여 모니터링하는 기능
설치 명령어 :kubectl apply -f istio-1.15.2/samples/addons/kiali.yaml
8) Istio를 적용할 라벨 지정
➡kubectl label ns default istio-injection=enabled
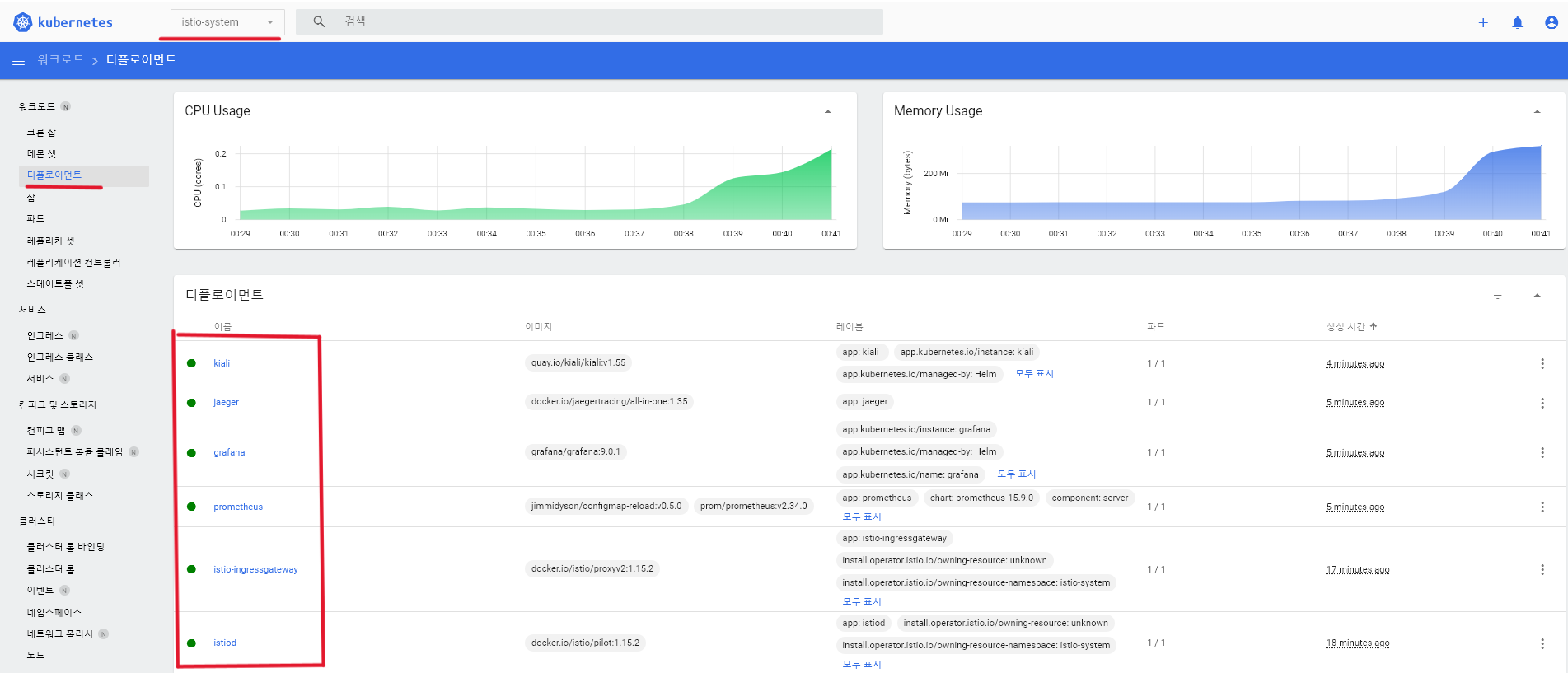
- 여기까지 진행하면 설치가 끝나고, 대쉬보드의 네임스페이스에서
istio-system으로 들어갔을때, 모든 디플로이먼트가 아래처럼 정상적으로 동작중인 것을 확인하면 된다.
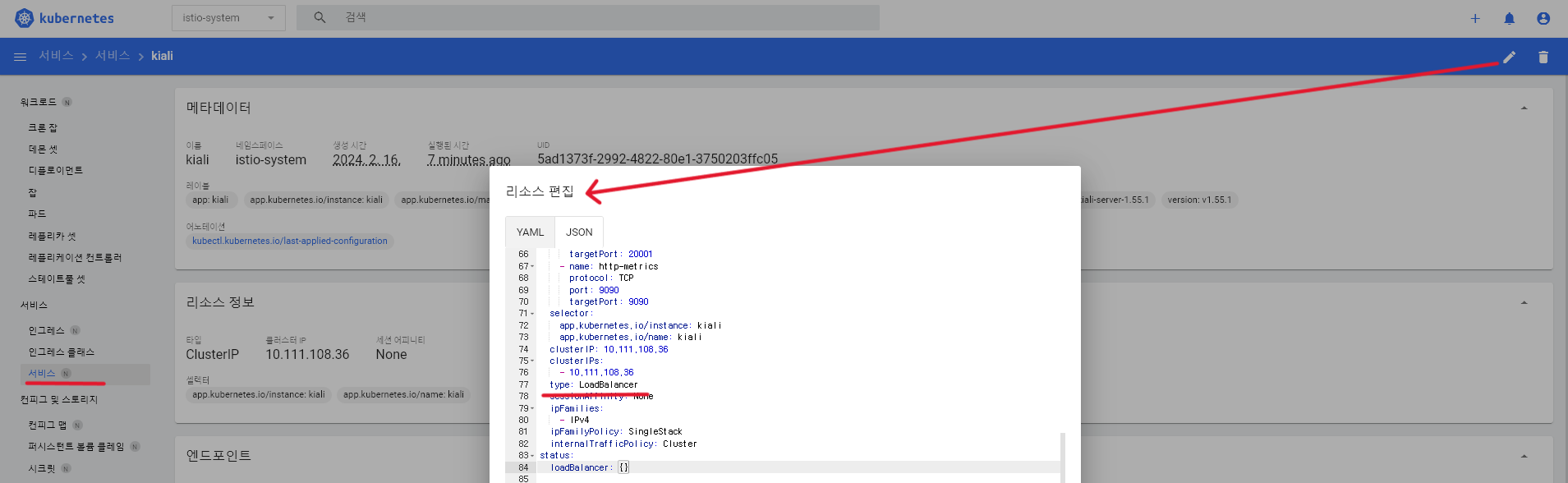
- 위처럼 잘 동작중이라면, 서비스로 이동하여
grafana와kiali의 리소스 편집에서 type을 Cluster IP 에서 LoadBalancer 로 변경해준다.
-
그다음 각각의 외부 엔드포인트로 접속해보면 아래처럼 접속이 정상적으로 된다.
➡kiali는 20001 번 포트로 접속
✅ grafana 화면
-
그라파나의 대쉬보드는 대쉬보드 사이트 바로가기 여기서 마음에 드는 것을 찾아서 Import 시키면 된다.
✅ kiali 화면
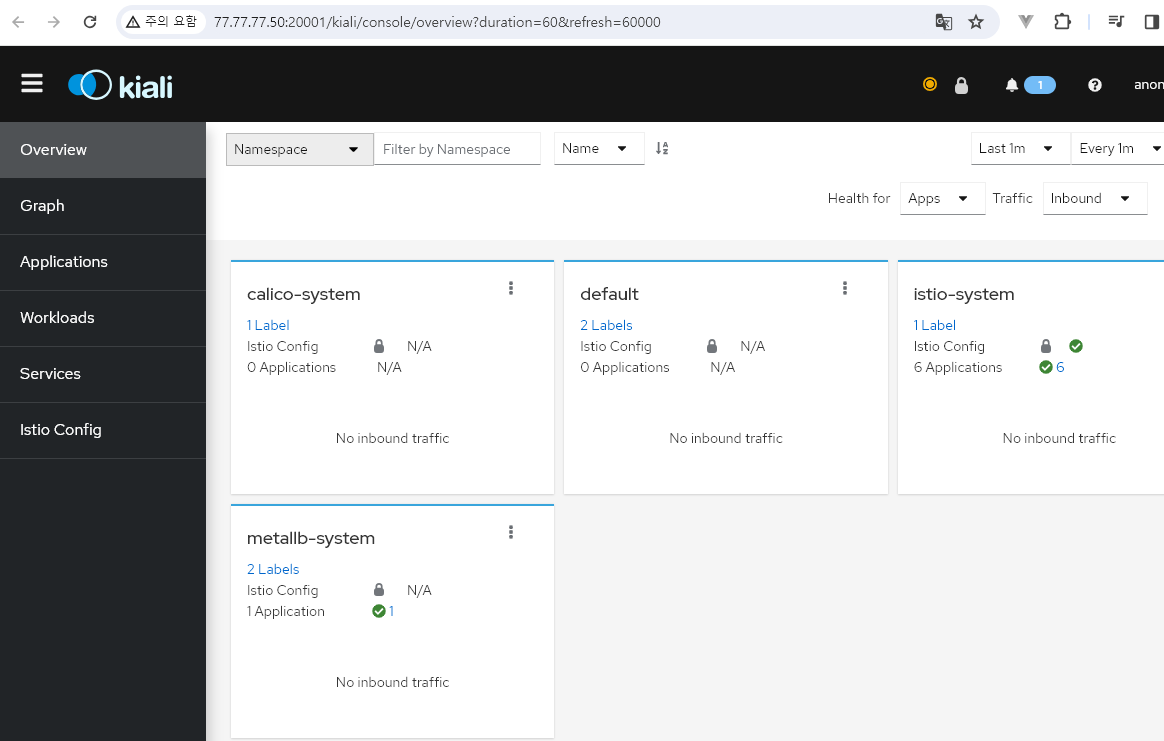
- 이제
default namespace로 다시 이동하여, Deployment 새로 생성해본다.
➡ 이때 Probe 설정은 하지 않는다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: backend-deployment
spec:
replicas: 2
strategy:
type: RollingUpdate
minReadySeconds: 10
selector:
matchLabels:
type: backend
template:
metadata:
labels:
type: backend
spec:
containers:
- name: backend
image: [이미지 이름]
terminationGracePeriodSeconds: 5
➡ Pod의 로그 확인 창으로 가보면 기존에는 backend 라는 컨테이너 1개만 있었는데,
Istio를 설치함으로써 자동으로 istio-proxy 와 dikastes 컨테이너까지
총 3개의 컨테이너가 생성되는 것을 아래처럼 확인할 수 있을 것이다.
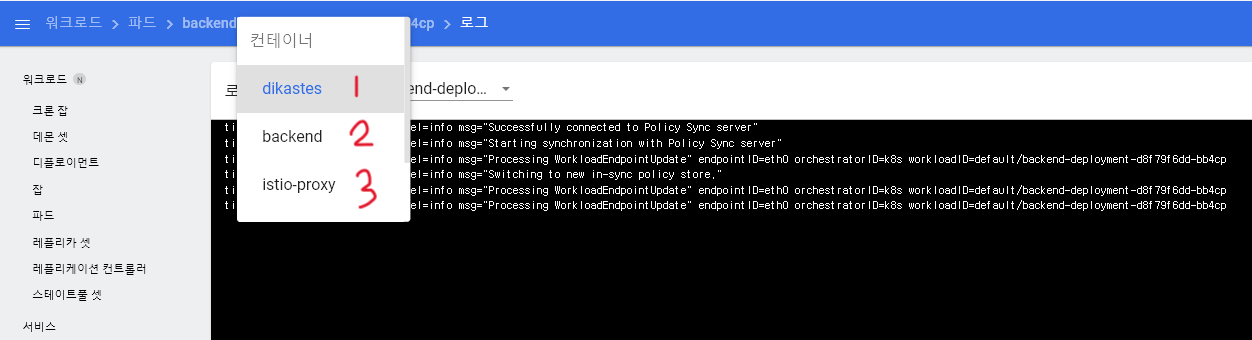
- 다음으로 서비스도 생성해본다.
apiVersion: v1
kind: Service
metadata:
name: backend-svc
spec:
selector:
type: backend
ports:
- port: 8080
targetPort: 8080
type: LoadBalancer
- 그런 다음, 웹브라우저로 요청을 보냈을때 정상적으로 요청이 보내지면 구축이 끝난다.
- 강의실 노트북으로 했을때는, 정상 동작했는데, 집에서 다시 해보니 동작을 안해서 확인이 필요하다.
- 정상적으로 되면 아래처럼 요청을 수행할 것이다.

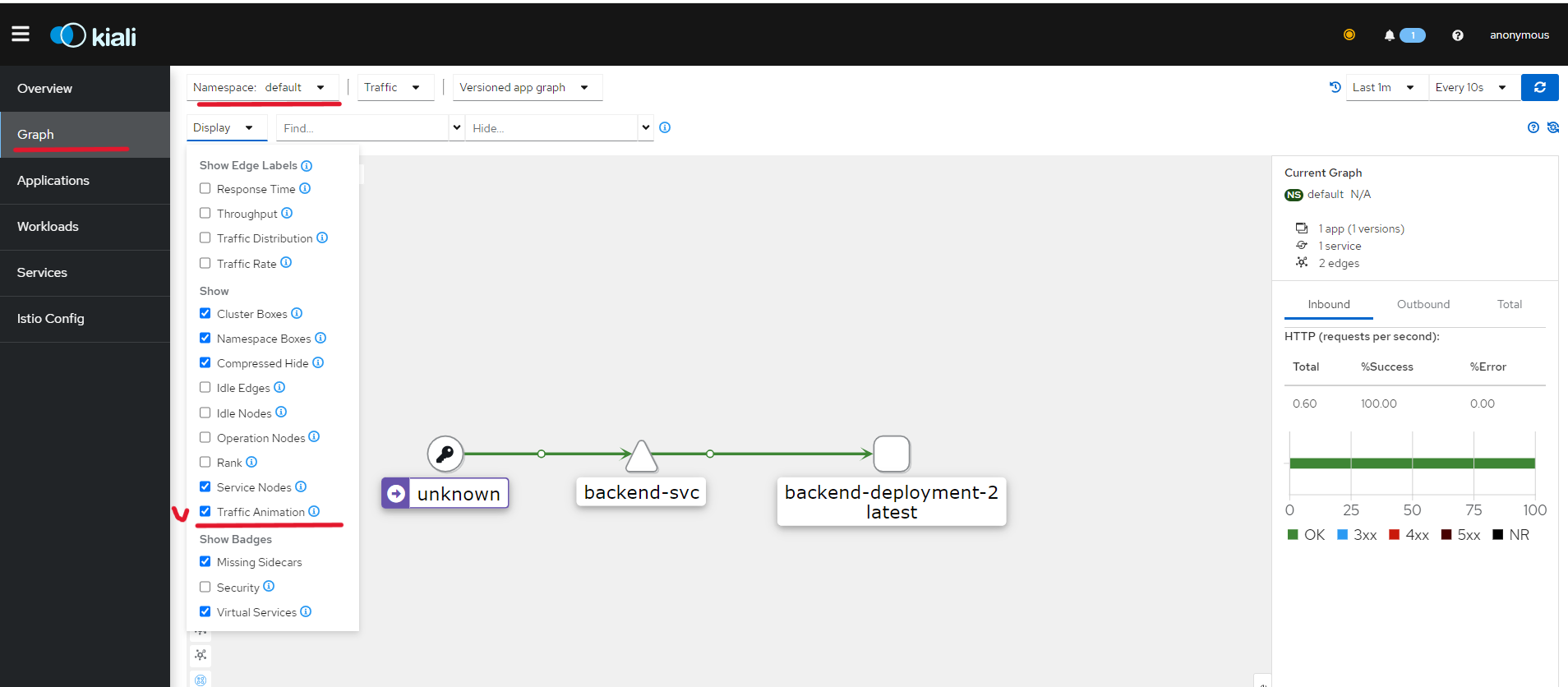
- 그랬을때, master 컴퓨터에서 테스트로 위의 URL 과 동일하게 아래처럼 실행시키고,
kiali에서 확인해보면 요청을 보내는 것이 애니메이션화 되어 표시된다.
➡while true; do curl http://77.77.77.53:8080/test/version; sleep 1; done