메모리 계층 구조와 메모리 관리 핵심
메모리 계층 구조
- 메모리는 컴퓨터 시스템 여러 곳에 계층적으로 존재
- CPU 레지스터 - CPU 캐시 - 메인 메모리 - 보조기억장치
- CPU 레지스터에서 보조기억장치로 갈수록
1) 용량 증가
2) 가격 저렴
3) 속도 저하
- 메모리 계층 구조의 중심 - 메인 메모리
- 메모리 계층화의 목적
- 빠른 프로그램 실행을 위해 CPU의 메모리 엑세스 시간을 줄이기 위함

메모리 계층구조의 특성
| CPU 레지스터 | L1/L2 캐시 | L3 캐시 | 메인 메모리 | 보조기억장치 | |
|---|---|---|---|---|---|
| 용도 | 몇 개의 명령과 데이터 저장 | 한 코어에서 실행되는 명령과 데이터 저장 | 멀티 코어들에 의해 공유. 명령과 데이터 저장 | 실행 중인 전체 프로세스들의 코드와 데이터, 입출력 중인 파일 블록들 저장 | 파일이나 데이터베이스, 그리고 메모리에 적재된 프로세스의 코드와 데이터의 일시저장 |
| 용량 | 바이트 단위. 8~30개 정도. 1KB 미만 | KB 단위 (Core i7의 경우 32KB/256KB) | MB 단위(Core i7의 경우 8MB) | GB 단위 (최근 PC의 경우 최소 8GB 이상) | TB 단위 |
| 타입 | SRAM (static RAM) | SRAM (static RAM) | DRAM (Dynamic RAM) | 마그네틱 필드나 플래시 메모리 | |
| 속도 | <1ns | <5ns | <5ns | <50ns | <20ms |
| 가격 | 고가 | 고가 | 보통 | 저가 | |
| 휘발성 | 휘발성 | 휘발성 | 휘발성 | 휘발성 | 비휘발성 |
메모리 계층화 - 성능과 비용의 절충
1) 계층화
- 계층화 과정
- CPU 성능 향상 -> 더 빠른 메모리 요구 -> 작지만 빠른 off-chip 캐시 등장 -> 더 빠른 액세스를 위해 on-chip 캐시 -> 멀티 코어의 성능에 적합한 L1, L2, L3 캐시
- 컴퓨터의 성능 향상 -> 처리할 데이터도 대형화 -> 저장 장치(하드 디스크)의 대형화 -> 빠른 저장 장치 요구 -> SSD의 등장 - 성능과 비용의 절충
- 빠른 메모리일수록 고가이므로 작은 용량 사용
2) 계층화 성공 이유
- 참조의 지역성 때문
- 코드나 데이터, 자원 등이 아주 짧은 시간 내에 다시 사용되는 프로그램의 특성
- CPU는 작은 캐시 메모리에 로딩된 코드와 데이터로 한동안 실행
- 캐시를 채우는 시간의 손해보다 빠른 캐시를 이용하는 이득이 큼
3) 계층화의 미래
- 현재, 메모리와 하드디스크 사이에 또 다른 형태의 메모리가 구현되고 있음
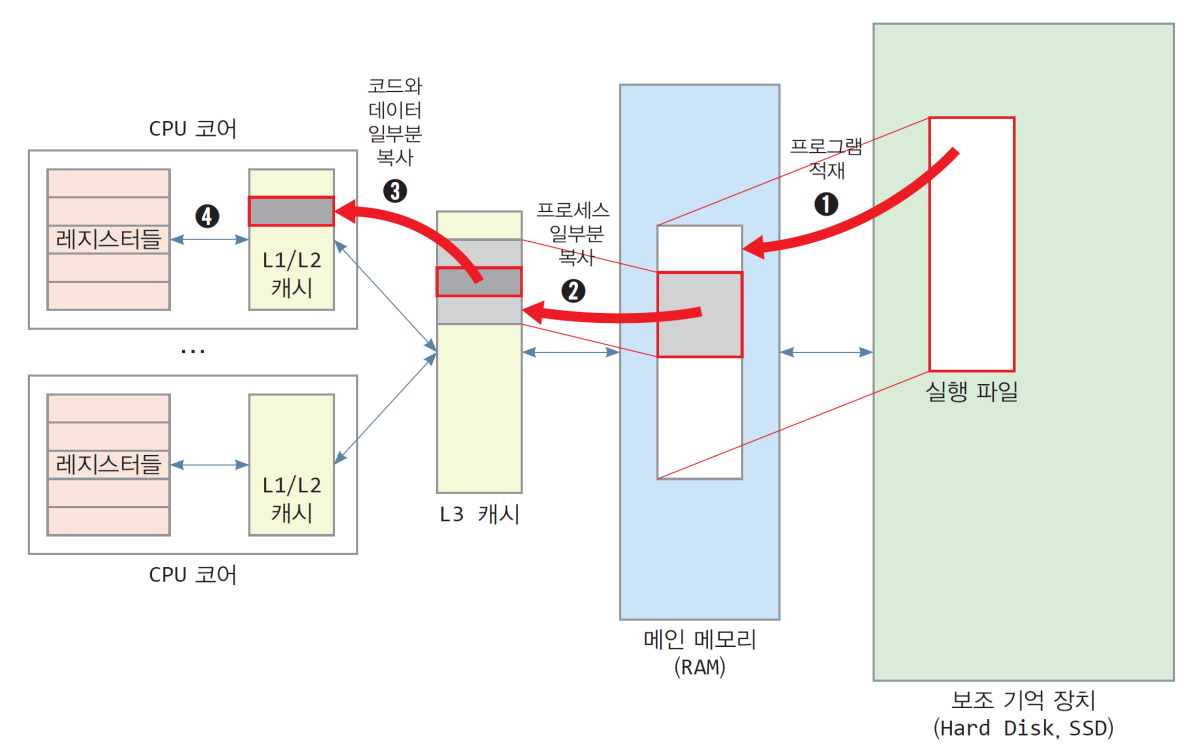
메모리 관리
1) 메모리의 역할
- 메모리는 실행하고자 하는 프로그램의 코드와 데이터 적재
- CPU는 메모리에 적재된 코드와 데이터만 처리
2) 운영체제에 의해 메모리 관리가 필요한 이유
- 메모리는 공유 자원
- 여러 프로세스 사이에 메모리 공유
- 각 프로세스에게 물리 메모리 할당 - 메모리 보호
- 프로세스의 독립된 메모리 공간 보장
- 사용자 코드로부터 커널 공간 보호 - 메모리 용량 한계 극복
- 설치된 물리 메모리보다 큰 프로세스 지원 필요
- 여러 프로세스의 메모리 합이 설치된 물리 메모리보다 큰 경우 필요 - 메모리 효율성 증대
- 가능하면 많은 개수의 프로세스를 실행시키기 위해- 프로세스 당 최소한의 메모리 할당
메모리 주소
물리 주소와 논리 주소
1) 메모리는 오직 주소로만 접근
2) 주소의 종류
- 물리 주소
- 물리 메모리(RAM)에 매겨진 주소. 하드웨어에 의해 고정된 메모리 주소
- 0에서 시작하여 연속되는 주소 체계
- 메모리는 시스템 주소 버스를 통해 물리 주소의 신호 받음 - 논리/가상 주소
- 개발자나 프로세스가, 프로세스 내에서 사용하는 주소, 코드나 변수 등에 대한 주소
- 0에서 시작하여 연속되는 주소 체계
- CPU가 프로세스를 실행하는 동안 다루는 모든 주소는 논리 주소
- 프로세스 내에서 매겨진 상대주소 (프로그램에서 변수 n의 주소가 100번지라면, 논리 주소가 100이고, 물리 주소를 알 수 없음)
- 컴파일러와 링커에 의해 매겨진 주소 (실행 파일 내에 만들어진 이진 프로그램의 주소들은 논리 주소로 되어 있음)
- 사용자나 프로세스는 결코 물리 주소를 알 수 없음
3) MMU (Memory Management Unit) - 논리 주소를 물리 주소로 바꾸는 하드웨어 장치
- CPU가 발생시킨 논리 주소는 MMU에 의해 물리 주소로 바뀌어 메모리에 도달 - 오늘날 MMU는 CPU 안에 내장
- 인텔이나 AMD의 x86 CPU는 80286부터 MMU를 내장
- MMU 덕분에 여러 프로세스가 하나의 메모리에서 실행되도록 됨
C 프로그램에서의 주소는 논리 주소인가 물리 주소인가?

[참고]
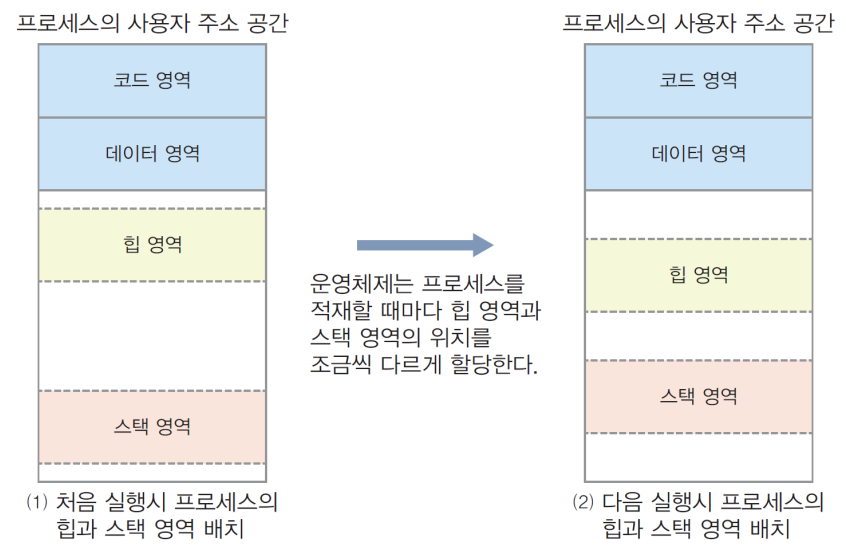
- ASLR (Address Space Layout Randomization)
- 해커들의 메모리 공격에 대한 대비책
- 주소 공간의 랜덤 배치
- 프로세스의 주소 공간 내에서 스택이나 힙, 라이브러리 영역의 랜덤 배치
- 실행할 때마다 이들의 논리 주소가 바뀌게 하는 기법 -> 실행할 때마다 함수의 지역 변수와 동적 할당 받는 메모리의 논리 주소가 바뀜
- 하지만, 코드나 전역 변수가 적재되는 데이터 영역의 논리 주소는 바뀌지 않음
물리 메모리 관리
메모리 할당
- 운영체제가 새 프로세스를 실행 시키거나 실행 중인 프로세스가 메모리를 필요로 할 때, 물리 메모리 할당
- 프로세스의 실행은 할당된 물리 메모리에서 이루어짐
- 프로세스의 코드, 변수, 스택, 동적 할당 공간 액세스 등
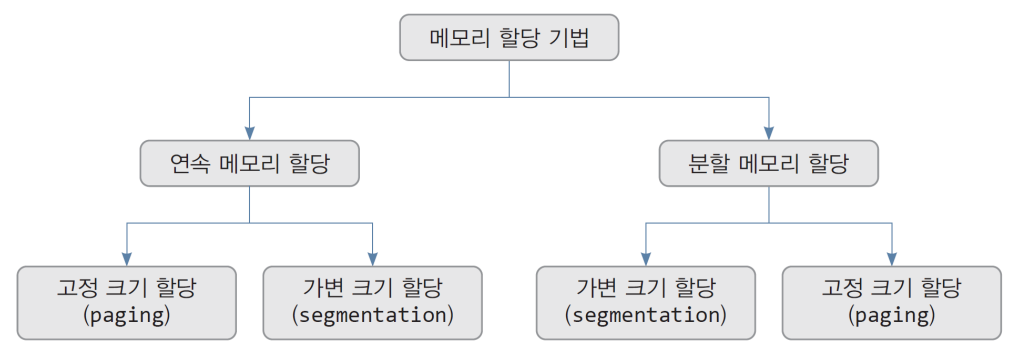
메모리 할당 기법
1) 연속 메모리 할당
- 프로세스별로 연속된 한 덩어리의 메모리 할당
- 고정 크기 할당
- 메모리를 고정 크기의 파티션으로 나누고 프로세스 당 하나의 파티션 할당 - 가변 크기 할당
- 메모리를 가변 크기의 파티션으로 나누고 프로세스 당 하나의 파티션 할당
2) 분할 메모리 할당
- 프로세스에게 여러 덩어리로 나누어 메모리 할당
- 고정 크기 할당
- 고정 크기의 동일한 덩어리 메모리의 분산 할당. 대표 방법 - Segmentation 기법 - 가변 크기 할당
- 가변 크기의 덩어리 메모리를 분산 할당. 대표 방법 - 페이징 기법
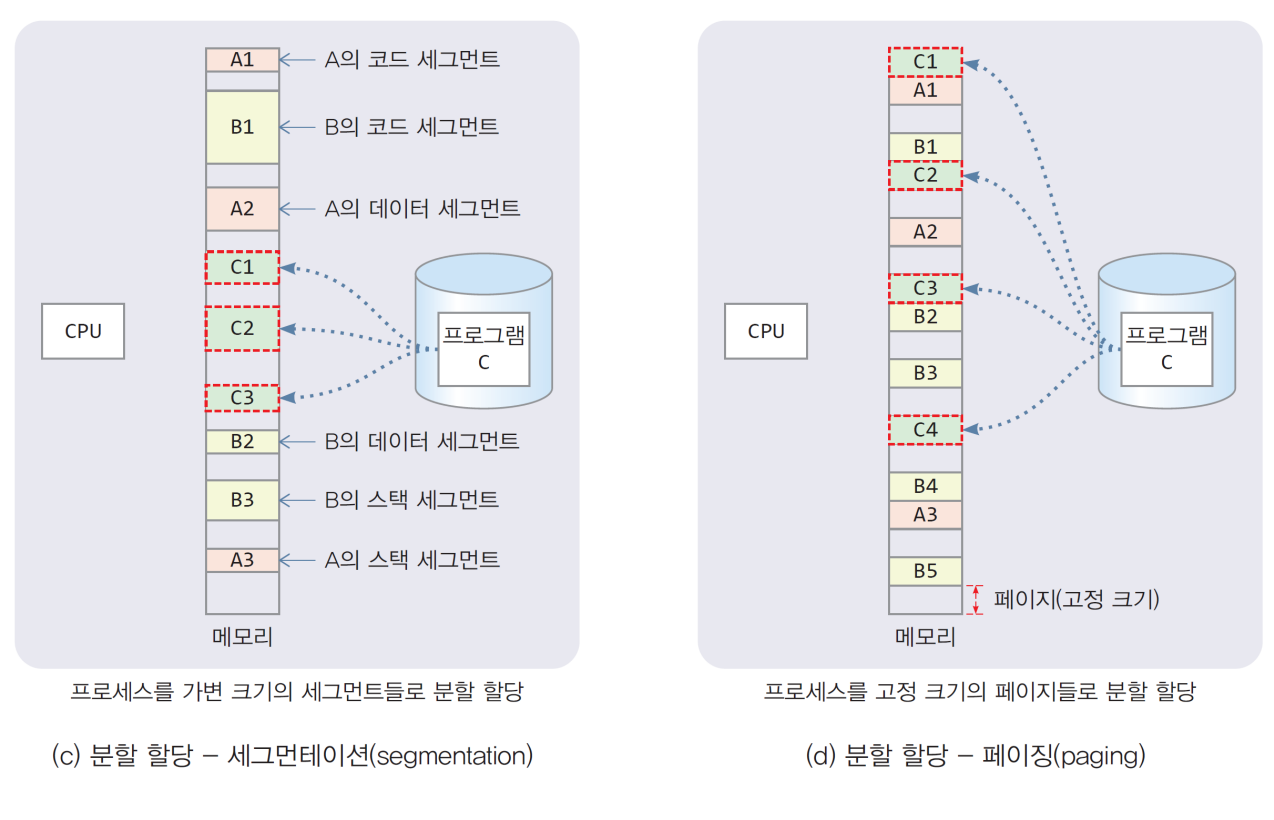
※ 왼쪽 오른쪽 그림 위치가 바뀜
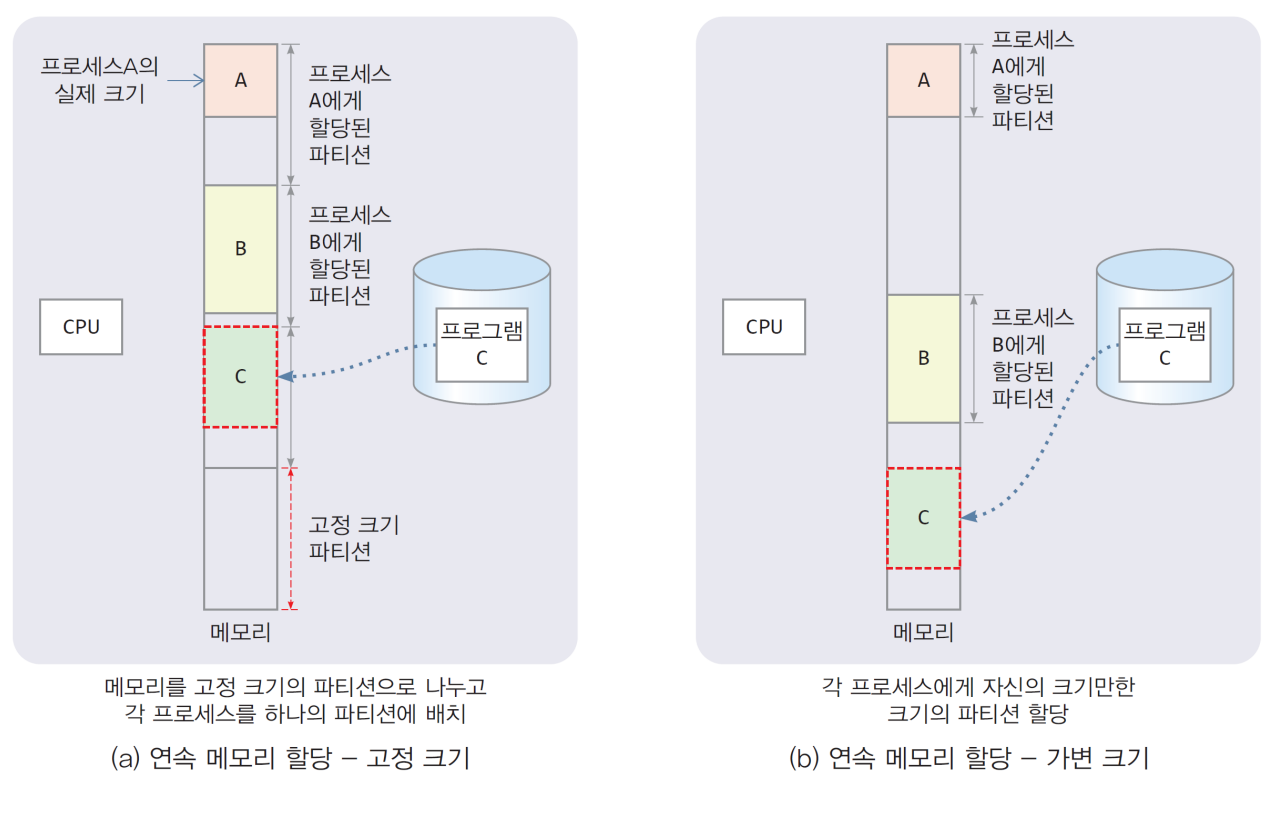
연속 메모리 할당
연속 메모리 할당
1) 각 프로세스 영역(코드와 데이터)을 연속된 메모리 공간에 배치
- 메모리를 한 개 이상의 파티션으로 분할하고 파티션을 할당하는 기법
- 한 프로세스는 한 파티션으로 할당
2) 연속 메모리 할당은 초기 운영체제에서 사용
- MS-DOS 와 같은 과거 운영체제
- MS-DOS는 단일 사용자 단일 프로세스 시스템, 한 프로세스가 전체 메모리 독점 - 고정 크기 할당
- IBM OS/360 MFT
- 메모리 전체를 고정 크기의 n개로 분할. 프로세스마다 하나씩 할당. 수용가능 프로세스의 수 n 고정
- 메모리가 없을 때, 프로세스는 큐에서 대기
- 가변 크기 할당
- IBM OS/360 MVT
- 프로세스마다 가변 크기로 연속된 메모리 할당. 수용가능 프로세스 수 가변
- 메모리가 부족할 때, 프로세스는 큐에서 대기 - 가상 메모리 지원 X

단편화
1) 단편화
- 프로세스에게 할당할 수 없는 조각 메모리들이 생기는 현상, 조각 메모리를 홀(hole)이라고 부름
2) 내부 단편화
- 할당된 메모리 내부에 사용할 수 없는 홀이 생기는 현상
- 파티션보다 작은 프로세스를 할당하는 경우 발생
- IBM OS/360 MFT 사례
3) 외부 단편화
- 할당된 메모리들 사이에 사용할 수 없는 홀이 생기는 현상
- 가변 크기의 파티션이 생기고 반환되면서 여러 개의 작은 홀 생성
- 홀이 프로세스의 크기보다 작으면 할당할 수 없음
- IBM OS/360 MVT 사례

연속 메모리 할당 구현
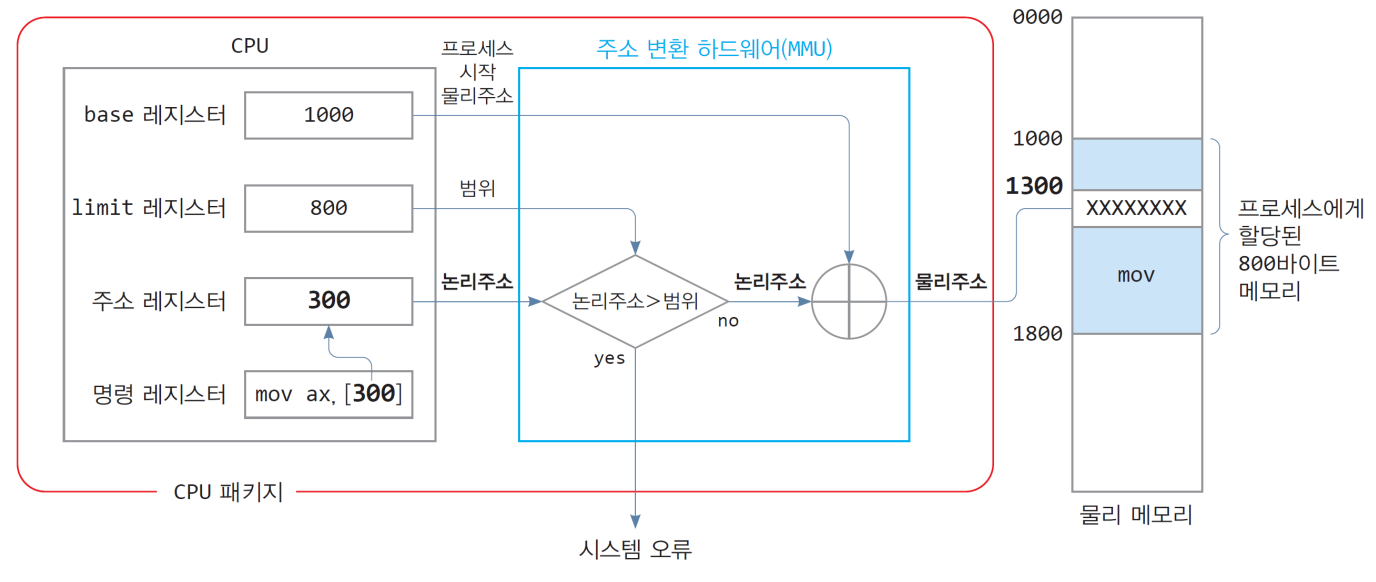
1) 하드웨어 지원
- CPU 레지스터 필요
- base 레지스터 : 현재 CPU가 실행 중인 프로세스에게 할당된 물리 메모리의 시작 주소
- limit 레지스터 : 현재 CPU가 실행 중인 프로세스에게 할당된 메모리 크기
- 주소 레지스터 : 현재 액세스하는 메모리의 논리 주소 - 주소 변환 하드웨어(MMU) 필요 - 논리 주소를 물리 주소로 변환하는 장치
2) 운영체제 지원
- 모든 프로세스에 대해 프로세스별로 할당된 '물리메모리 시작 주소와 크기 정보 저장' 관리
- 비어있는 메모리 영역 관리
- 새 프로세스를 스케줄링하여 실행시킬 때마다, '물리 메모리의 시작 주소와 크기 정보'를 CPU 내부의 base 레지스터와 limit 레지스터에 적재
3) 연속 메모리 할당의 장단점
- 장점
1) 논리 주소를 물리 주소로 바꾸는 과정이 단순. CPU의 메모리 액세스 속도 빠름
2) 운영체제가 관리할 정보량이 적어서 부담이 덜함 - 단점
1) 메모리 할당의 유연성이 떨어짐. 작은 홀들을 합쳐 충분한 크기의 메모리가 있음에도, 연속된 메모리를 할당할 수 없는 경우 발생 (-> 메모리 압축 기법으로 해결)
홀 선택 알고리즘 / 동적 메모리 할당
- 운영체제는 할당 리스트 유지
- 할당된 파티션에 관한 정보를 리스트로 유지 관리
- 할당된 위치, 크기, 비어 있는지 유무
- 할당 요청이 발생하였을 때 운영체제의 홀 선택 전략 3가지
1) first-fit(최초 적합) - 비어있는 파티션 중 맨 앞에 요청 크기보다 큰 파티션 선택
- 할당 속도 빠름/단편화 발생 가능성
2) best-fit(최적 적합)
- 비어 있는 파티션 중 요청을 수용하는 가장 작은 파티션 선택
- 크기 별로 파티션이 정렬되어 있지 않으면 전부 검색
- 가장 작은 홀 생성됨
3) worst-fit(최악 적합)
- 비어 있는 파티션 중 요청을 수용하는 가장 큰 파티션 선택
- 크기 별로 파티션이 정렬되어 있지 않으면 전부 검색
- 가장 큰 홀 생성됨

세그먼테이션 메모리 관리
세그먼테이션 개요
1) 세그먼트
- 세그먼트는 논리적 단위 - 개발자의 관점에서 보는 프로그램의 논리적 구성 단위
- 세그먼트마다 크기 다름
2) 프로그램을 구성하는 일반적인 세그먼트 종류
- 코드 세그먼트
- 데이터 세그먼트
- 스택 세그먼트
- 힙 세그먼트
3) 세그먼테이션 기법
- 프로세스를 논리 세그먼트 크기로 나누고, 각 논리 세그먼트를 한 덩어리의 물리 메모리에 할당하고 관리하는 메모리 관리 기법]
- 프로세스의 주소 공간
- 프로세스의 주소 공간을 여러 개의 논리 세그먼트들로 나누고
- 각 논리 세그먼트를 물리 세그먼트에 매핑
- 프로세스를 논리 세그먼트로 나누는 과정은 컴파일러, 링커, 로더, 운영체제에 의해 이루어짐
4) 논리 세그먼트와 물리 세그먼트의 매핑
- 시스템 전체 세그먼트 매핑 테이블을 두고 논리 주소를 물리 주소로 변환
5) 외부 단편화 발생

세그먼테이션의 구현
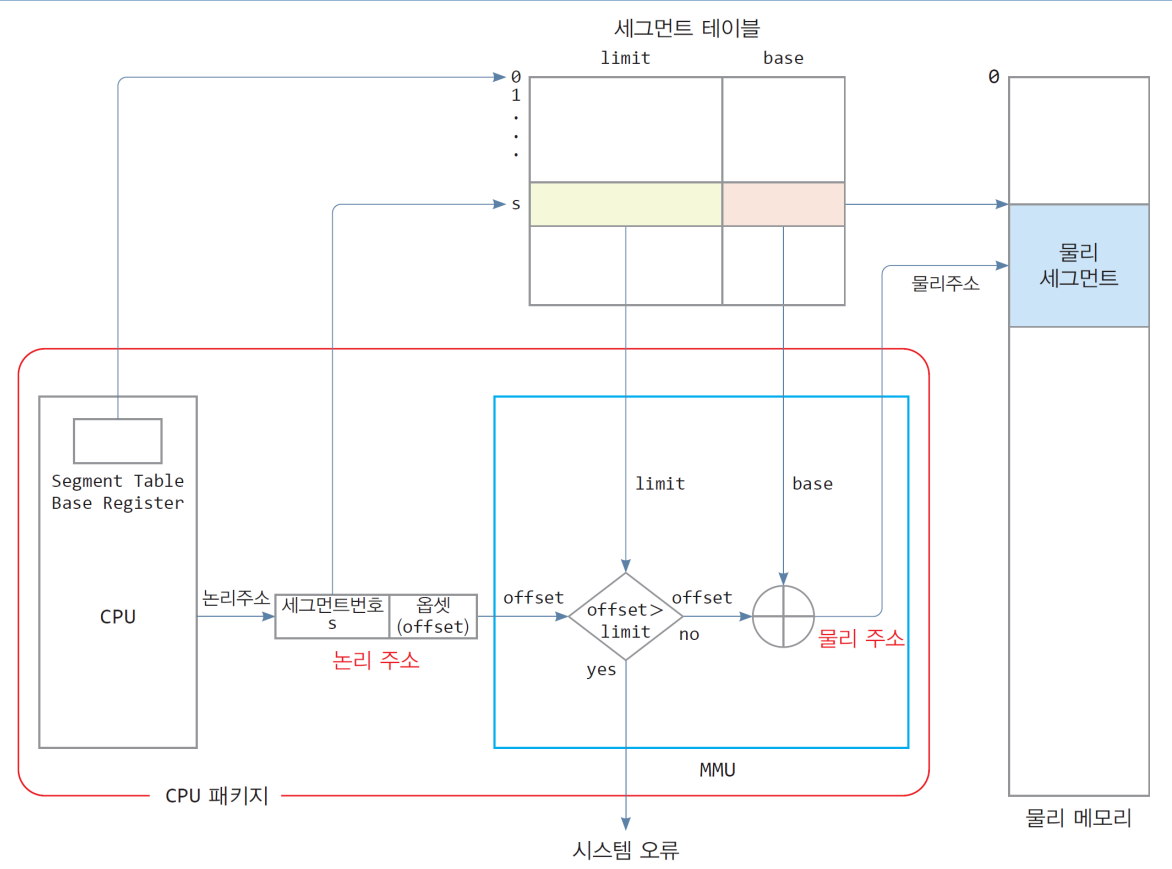
1) 하드웨어 지원
- 논리 주소 구성 : [세그먼트 번호, 옵셋]
- 옵셋 : 세그먼트 내 상대 주소 - CPU
- 세그먼트 테이블의 시작 주소를 가리키는 레지스터 필요 - MMU 장치
- 논리 주소를 물리 주소로 변환하는 장치
- 논리 주소가 세그먼트 범위를 넘는지 판별(메모리 보호)
- 논리 주소의 물리 주소 변환(메모리 할당) - 세그먼트 테이블
- 메모리에 저장
- 세그먼트별로 시작 물리 주소와 세그먼트 크기 정보
2) 운영체제 지원
- 세그먼트의 동적 할당/반환 및 세그먼트 테이블 관리 기능 구현
- 프로세스의 생성/소멸에 따라 동적으로 세그먼트 할당/반환
- 물리 메모리에 할당된 세그먼트 테이블과 자유 공간에 대한 자료 유지
- 컨텍스트 스위칭 때 CPU의 레지스터에 적절한 값 로딩
3) 컴파일러, 링커, 로더 지원 - 사용자 프로그램을 세그먼트 기반으로 컴파일, 링킹, 로딩
단편화
-
외부 단편화 발생
- 세그먼트들의 크기가 같지 않기 때문에 세그먼트와 세그먼트 사이에 발생하는 작은 크기의 홀 -
내부 단편화 발생 없음

데이터사이언스와 자연어처리를 공부하고 있습니다.