들어가기에 앞서
안녕하세요! 처음 월간 슈도렉 컨텐츠을 고민하다가 최근 하고 있는 공모전과 시너지를 위해 LLM for rec, 다시 말해 추천을 위한 대형언어모델 연구를 전체적으로 리뷰해보려는 대형?! 프로젝트를 시작하려고 합니다. 메인 소스는 위에 언급한 서베이 논문을 두고, 핵심이 될 수 있는 논문를 추가적으로 리뷰하며 전체적인 연구 흐름을 이해해보려 합니다. 이번달에는 우선 서베이 논문에 대해서 개략적으로 살펴본 후 (개인적으로 논문 컨텐츠는 좋은데 논문 흐름이 매끄럽지 않은 느낌이 있어서 의역과 흐름을 제 나름대로 재구성했습니다!) 그리고 최근에 각광받고 있는 Generative LLM(GPT 계열)을 활용한 추천시스템 중 튜닝을 활용하지 않는 방법론에 대해 좀 더 이야기해보고자 합니다!
- 참고로 서베이 논문과 관련한 깃허브는 https://github.com/WLiK/LLM4Rec-Awesome-Papers 다음과 같습니다.
초록 및 서론
LLM은 추천 분야에 있어서도 주목을 받고 있습니다.
- (추천) 유저와 아이템과의 관계를 설정함에 있어 (LLM) 텍스트 피처에 대한 높은 품질의 표현과 광범위한 외부지식을 활용하는 것이 중요 포인트입니다.
기존 추천시스템과는 다르게, LLM 기반 모델은 유저 쿼리나 아이템 설명, 다른 텍스트 데이터를 효과적으로 통합할 수 있으며, LLM의 사전지식통해 추천과 관련된 사전정보가 없어도 특정 유저나 아이템에 추천할 수 있는 제로/퓨샷 추천 능력(가능성)을 갖추고 있습니다.
- 특히 GPT 계열의 generative 언어모델이 두드러지며, 언어 생성 능력을 기반으로 설명력 제공 가능성도 보였습니다.
LLM 기반의 추천시스템 연구에 대한 이해를 돕기 위해, 이 논문에서는 분류체계를 소개합니다. 통합방법과 모델사용 관점에서 연구를 구분해볼 수 있습니다.
-
(통합방법 관점) 언어모델을 추천에 통합하는 방식은 3가지 카테고리로 분류될 수 있습니다.
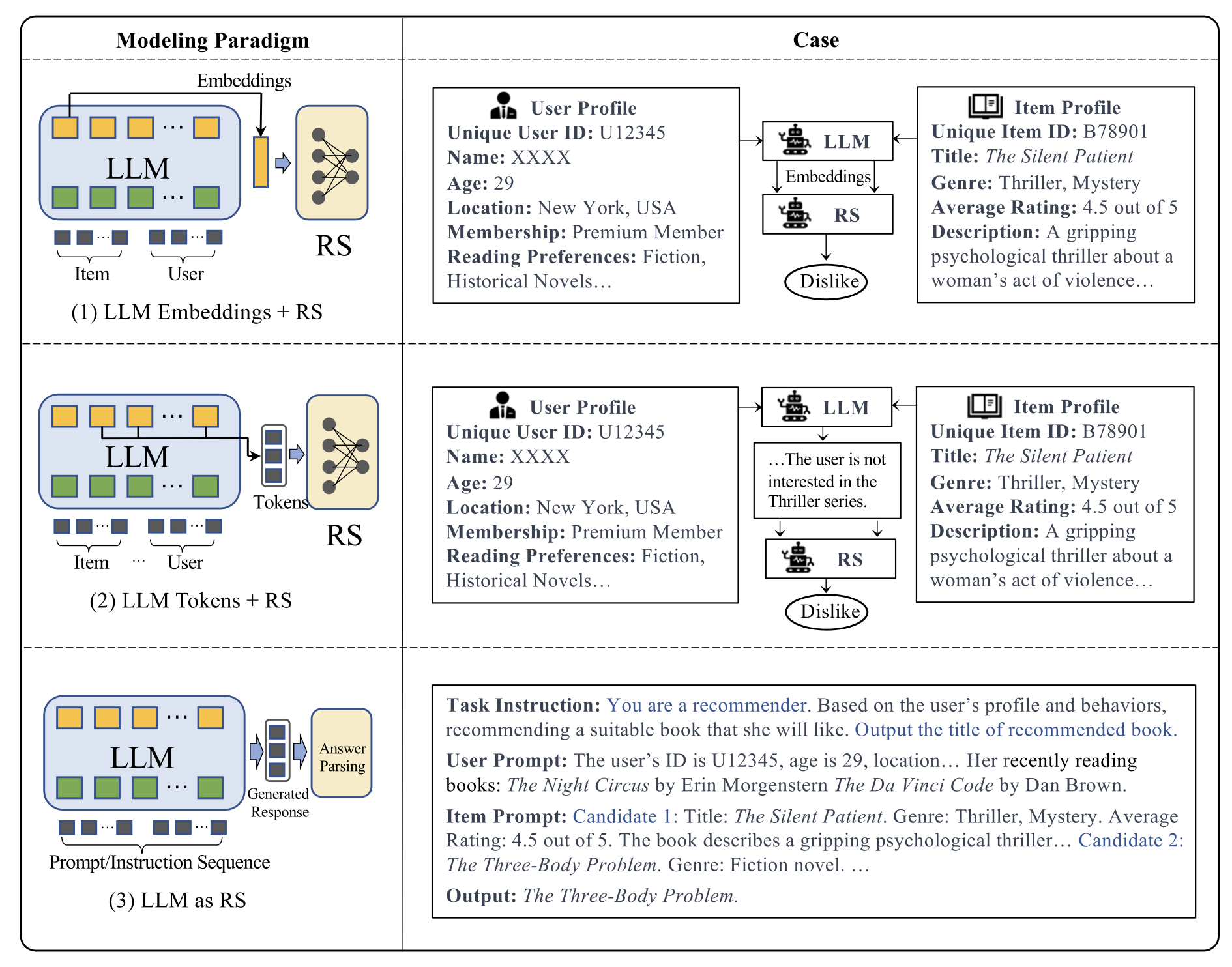
a. LLMEmbeddings+RS : 언어모델을 피처추출 인코더로 활용합니다. 기본적으로 트랜스포머 인코더를 사용하는 BERT 계열의 Discriminative LM이 임베딩 학습에 강점이 있기 때문에, 해당 언어모델이 주로 쓰입니다.
b. LLMTokens+RS : 1번 방법론과 유사하나, (텍스트로 변환된) 토큰을 사용합니다.
c. LLM as RS : 사전학습된 LLM을 바로 추천시스템으로 변환합니다. 2번 및 3번 방법론은 텍스트 생성에 강점이 있는 GPT계열의 generative LM이 활용됩니다.
-
(모델선택 관점)
a. Discriminative large language models (BERT 계열) : 주로 파인튜닝 또는 프롬프트 튜닝을 수행하여 LLM의 표현을 재정렬합니다.
b. Generative LLMs for recommendation(GPT 계열) : 추천을 자연어생성으로 치환하고, 튜닝하지 않는 방법과 튜닝하는 방법으로 구분될 수 있습니다.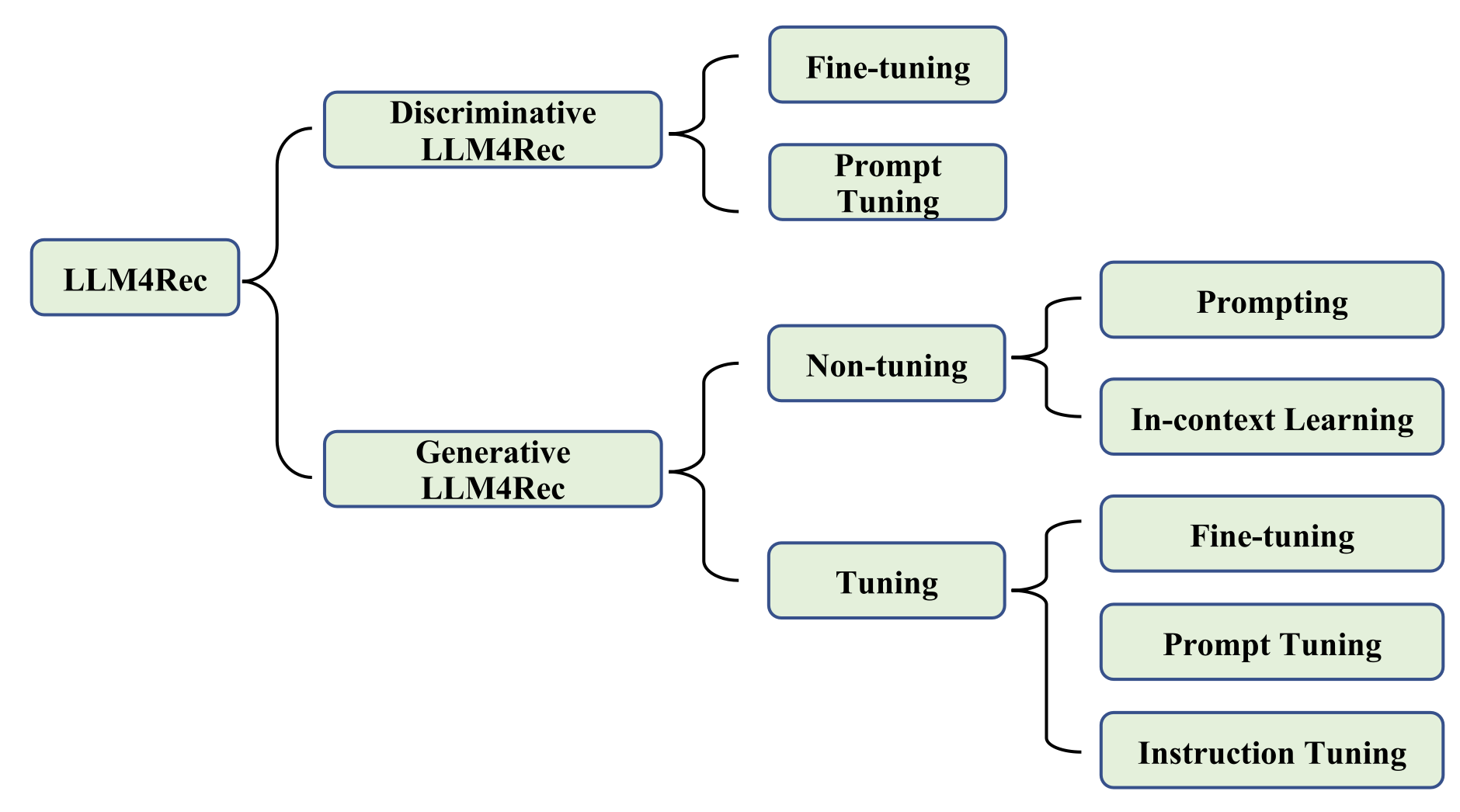
서베이 논문에 대한 추가적인 설명은 다음 슈도렉 컨텐츠로 미루고, 논문에서 소개된 Generative LLM(GPT 계열)을 활용한 추천시스템 중 튜닝을 활용하지 않는 연구 두개를 간략하게 살펴보도록 합시다.
(1) Is ChatGPT a Good Recommender? A Preliminary Study

알리바바에서 발표한 논문(CIKM, 2023)입니다. 이 논문의 접근방법은 아래 그림을 보면 바로 이해가 되실겁니다.
- 평점예측을 예로 들면, 제로샷 또는 퓨샷 프롬프트를 구성해서 ChatGPT에 그대로 입력하는 방식입니다.
(이게 끝이냐구요?, 사실입니다)

이 논문에서 주장하는 컨트리뷰션은 추천 Task에서 ChatGPT를 평가하는 벤치마크를 구축한 것과 ChapGPT를 추천에 활용했을때의 장점과 단점에 대해 논의했다는 것입니다. 그래서 방법론 자체는 새로울 것이 없긴 합니다. (논문은 타이밍)
-
5개 추천 Task(rating prediction, sequential recommendation, direct recommendation, explanation generation, and review summarization)에서 성능을 평가하기 위해 제로샷 및 퓨샷 프롬프트(task description, behavior injection, and format indicator)를 디자인하고 성능을 평가했습니다.
-
정확성 관점에서 ChatGPT는 평점 예측에서는 좋은 성능을 보였으나(아마존 beauty 데이터셋에서 MF, MLP보다 성능이 좋았습니다.)
-
시퀀셜 추천 및 다이렉트 추천에서는 성능이 매우 나빴습니다.
- 저자들은 성능이 나쁜 나름의 이유를 찾고자했고, 시퀀셜 추천 예를 들면, 성능이 나쁜 이유로는 ChatGPT는 아이템간의 시퀀셜한 관계를 본 것이 아니라, 단순히 의미적 유사성에 집중했을 가능성을 언급하며 또한 프롬프트의 길이 문제로 모든 아이템을 입력할 수 없었다고 합니다.
-
하지만 설명력에 있어서는 사람이 평가한(human evaluation) 관점으로 최신 추천모델을 능가했다고 합니다.
(2) Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System

두번째는 2023년에 arXiv에 올라온 논문으로, 기존 추천시스템을 프롬프트를 활용한 LLM과 연계하여 대화형 추천패러다임을 제안합니다. LLM은 별도로 추가 학습하지 않으며, In-context learning 만을 활용합니다.
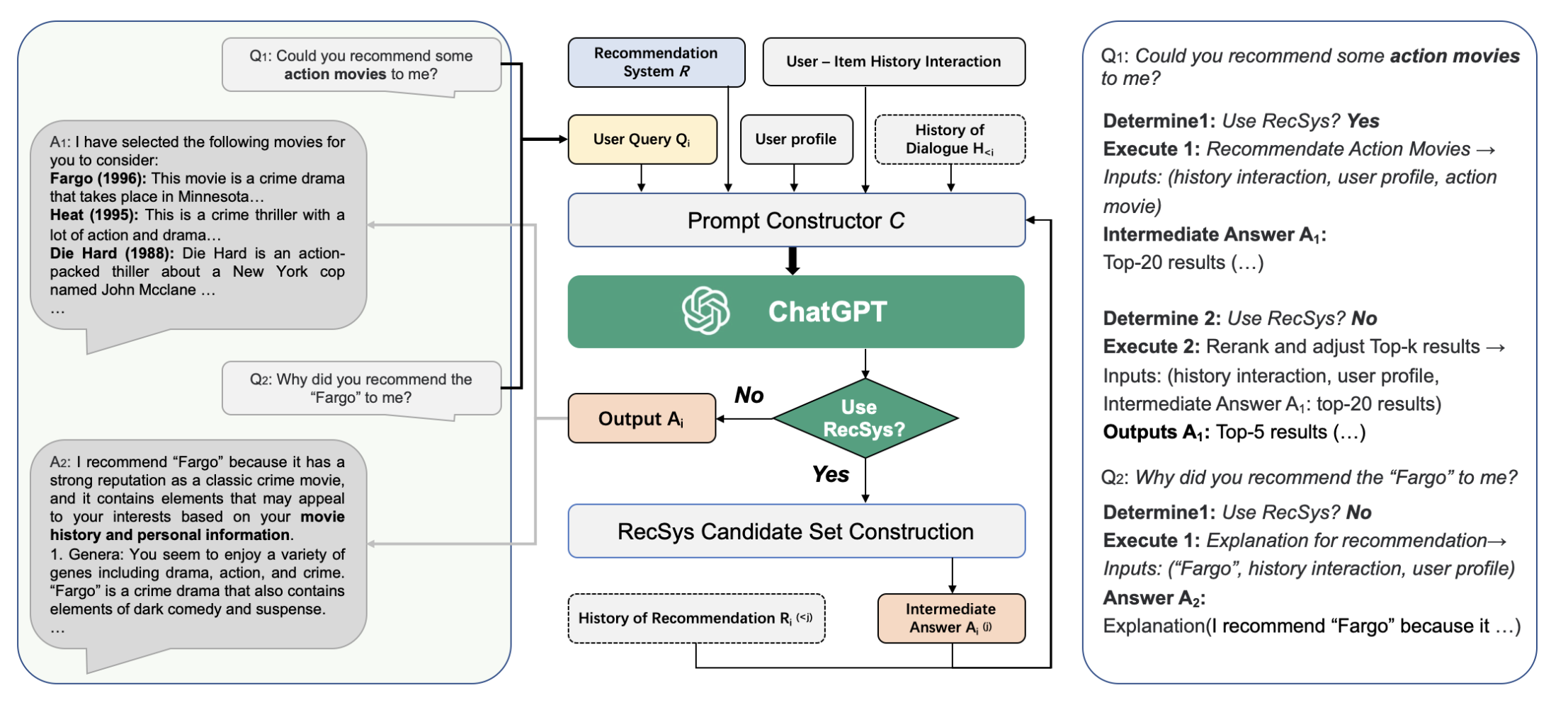
- 제안 프레임워크는 프롬프트 생성기()에서 나온 프롬프트가 ChatGPT에 입력되는 방식이며, 프롬프트 생성기에는 추천시스템()과 유저 쿼리, 유저 정보 등이 연계되어 있습니다.
- 프롬프트 생성기는 유저 쿼리와 추천 관련 정보를 잘 요약하는 텍스트 문장을 만듭니다.
- 만약, 유저의 쿼리가 추천 질문으로 판단되면, 추천시스템()에서 후보 아이템들을 생성하고 이후 해당 아이템을 다시 랭킹(rerank)을 매기는 작업을 거칩니다.
- 추천시스템 모듈은 정확하게는 후보 아이템군을 줄여서 프롬프트에 넣기 위한 모듈로 사용됩니다.
논문에서 제시한 케이스 스터디를 보겠습니다.
- 아래 그림은 두 다른 유저의 추천 관련 대화입니다. 유저의 프로필 정보 히스토리는 (보이지 않지만) 프롬프트로 변환되어 입력되었습니다. (왼쪽에서 볼 수 있는 것처럼) 추천에 대한 설명이라던지, (오른쪽에서 처럼) 멀티턴, 영화 관련 정보 등을 LLM은 답변하고 있습니다.

또한, 논문에서는 외부 데이터베이스 기반 RAG를 연계한 LLM을 활용해서 콜드스타트 문제를 개선할 수 있다는 주장과
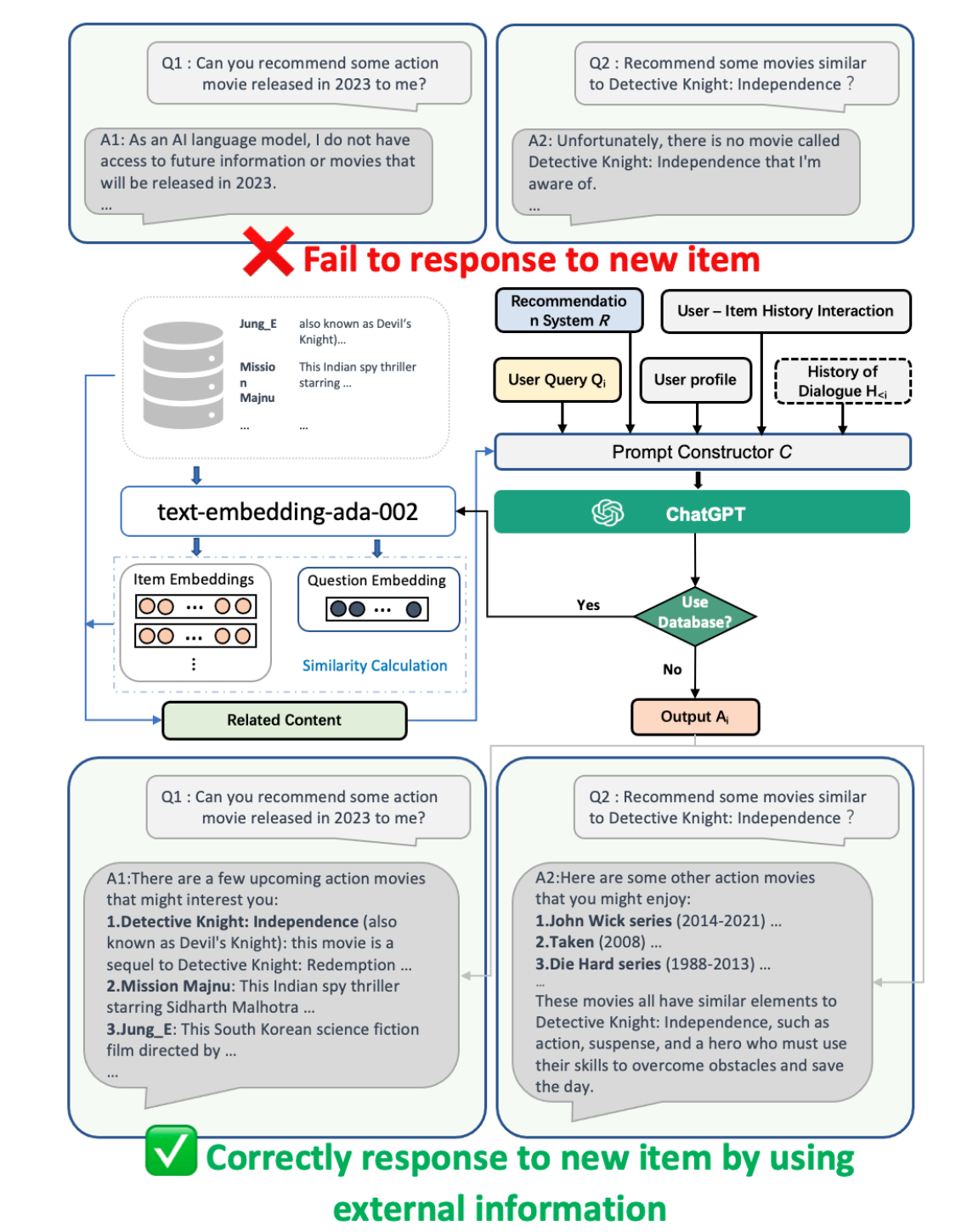
크로스도메인 문제도 해결가능함을 주장합니다.
- 크로스도메인의 경우 LLM은 기존에 유저가 보유한 영화 히스토리를 기반으로 다른 도메인인 책, TV 프로그램, 팟캐스트, 비디오게임을 추천합니다. LLM이 이미 인터넷의 다양한 정보으로 학습되었기 때문에 이를 가능하게 하는 지식을 보유할 수 있습니다.
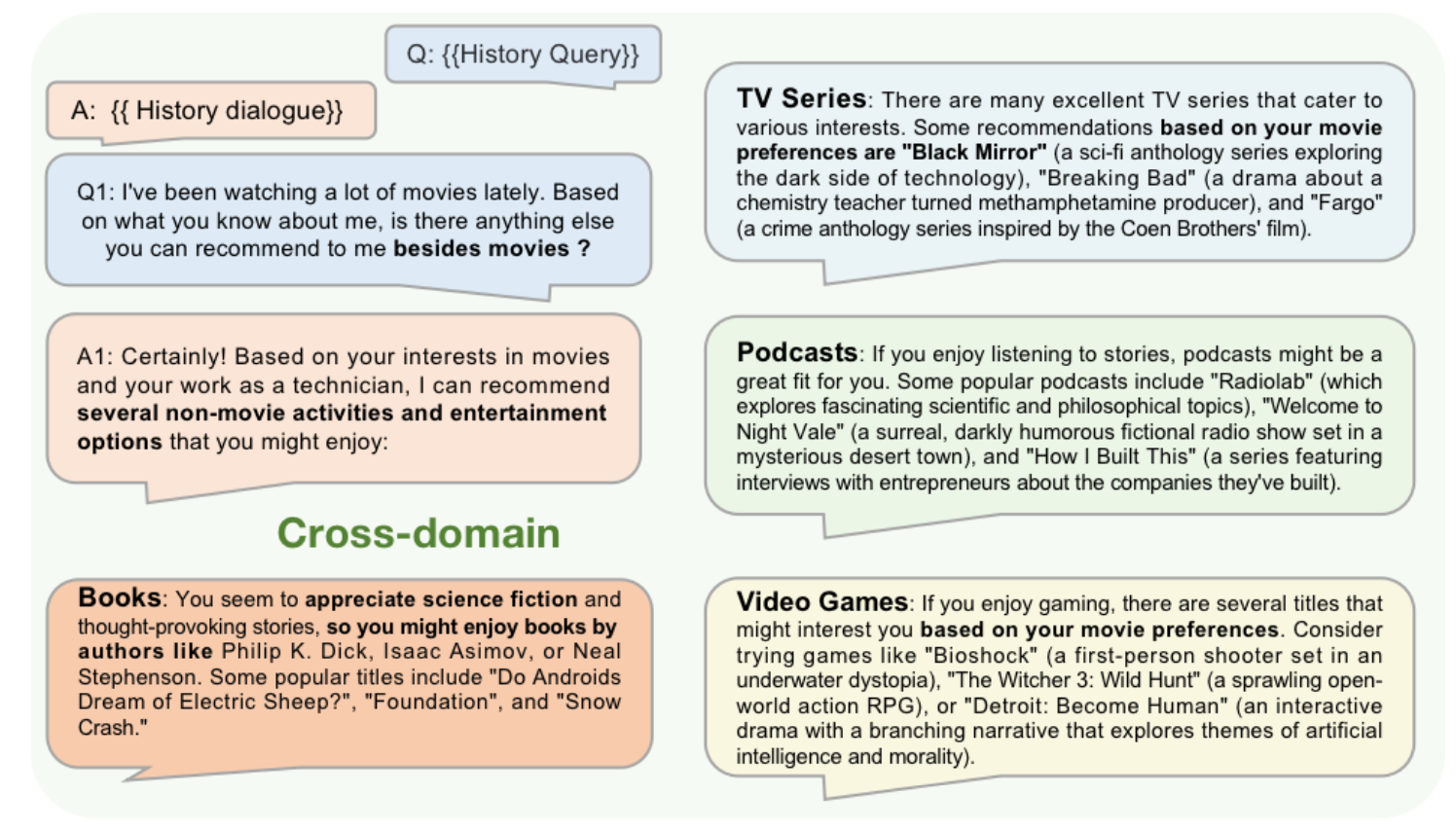
실험은 간략하게 설명드리면, 논문은 평점예측과 Top-5 예측 성능을 FM, GCN, MF, KNN 모델과 비교를 해서 성능 개선을 보여줍니다. (다만, 아쉬운 점은 구체적으로 연계한 추천모듈이 무엇인지, 앞서 주장했던 콜드스타트나 크로스도메인과 같은 task에서의 성능을 보여주지 않은 점입니다.)
위 두번째 논문은 LLM과 추천시스템을 연계하는 패러다임을 제안했습니다. 이를 기반으로 다양한 후속 연구, 최신 딥러닝 기반 추천시스템이나 크로스도메인 영역에서 LLM의 성능을 높이고 이를 검증하는 연구들이 기대되고 저도 한번 해보고 싶다는 생각이 듭니다. 끝까지 읽어주셔서 감사합니다.
