실수 표현 정확도 한계 0.3 + 0.6=0.899..
a = 0.3 + 0.6 ## a결과 0.8999 if a == 0.9: print(True) else: print(False) # 결과 : False
해결 방법 : round(수, 표시 소수 자리 수) 반올림 권장
함수(변수) 형태는-> 변수 = 함수(변수) 형태로 할당해야 변수값 변경됨
a = round(0.3 + 0.6, 1) # 0.9
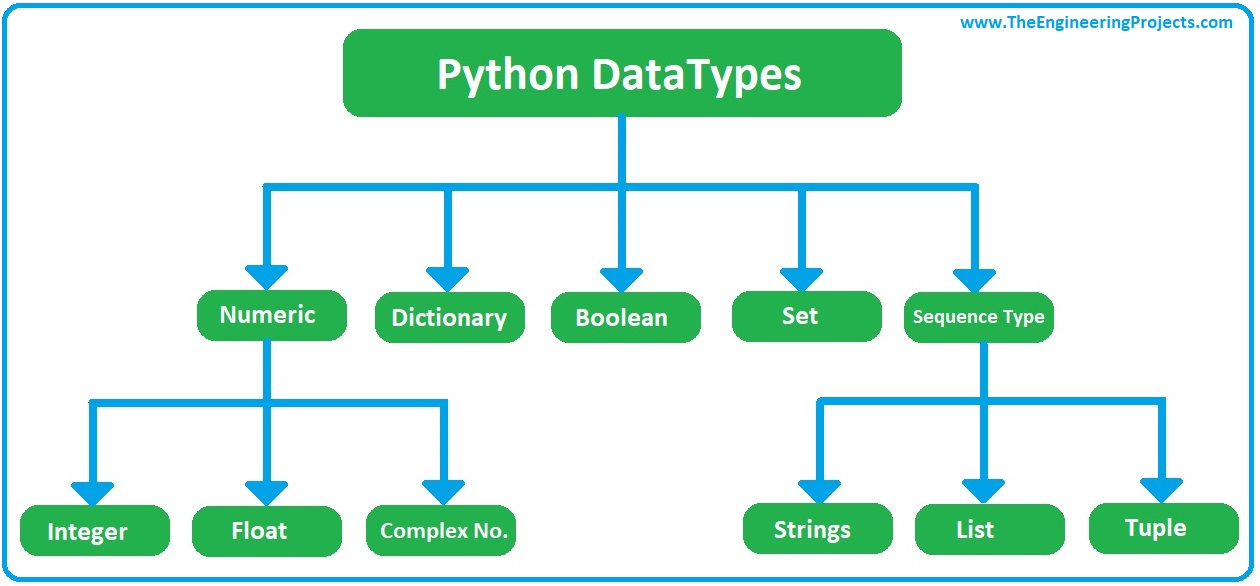
str, list, tuple, dict, set
--- str ---
생성 = "Hello" - or - 'world' - or - str(123)
인덱싱, 슬라이싱 가능
특정 인덱스 값 변경 불가 (immutable)
변환
문자열을 리스트로 변환
list_from_str = list("Hello")문자열을 튜플로 변환
tuple_from_str = tuple("Hello")문자열을 집합으로 변환 (중복 제거)
set_from_str = set("Hello")
--- list ---
생성 = [1, 2, 3] - or - list( [1, 2, 3] )
- 인덱싱, 슬라이싱 가능 (순서가 있음)
- 원소 중복 가능
- 특정 인덱스 값 변경 가능 (mutable)
- 원소 추가(append, insert) 제거(remove) 가능
변환
리스트를 문자열로 변환
str_from_list = ''.join(['a', 'b', 'c'])리스트를 튜플로 변환
tuple_from_list = tuple([1, 2, 3])리스트를 집합으로 변환
set_from_list = set([1, 2, 2, 3])리스트를 dict로 변환
dict_from_list = {i: list_data[i] for i in range(len(list_data))} # {0: 'a', 1: 'b', 2: 'c'}
--- tuple ---
생성 = (1, 2, 3) - or - tuple((1, 2, 3))
- 인덱싱, 슬라이싱 가능 (순서가 있음)
- 원소 중복 가능
- 특정 인덱스 값(=한번 선언된 값) 변경 불가 (immutable)
- 원소 추가(append, insert) 제거(remove) 불가
변환
튜플을 문자열로 변환
str_from_tuple = ''.join( ('a', 'b', 'c') )튜플을 리스트로 변환
list_from_tuple = list( (1, 2, 3) )튜플을 집합으로 변환
set_from_tuple = set( (1, 2, 2, 3) )튜플을 dict로 변환
dict_from_tuple = {i: tuple_data[i] for i in range(len(tuple_data))} # {0: 'a', 1: 'b', 2: 'c'}
--- dict ---
생성 = {'name': 'Min', 'age': 12} - or - dict({'name': 'Min', 'age': 12}) - or - dict(a=1, b=2, c=3) - or - dict( [ ('a', 1), ('b', 2), ('c', 3) ] )
- 'key' : 'value'의 쌍을 데이터로 갖는 자료형
- 인덱싱 불가 (순서가 없음)
- 'key'는 중복 불가. 중복 시 뒤에 선언된 값 사용
- dict 원소 추가, 삭제 가능
- 'key'값으로 'value'값 조회, 수정 O(1) → 리스트보다 성능이 좋음
- 키와 값의 자료형 모두 통일하지 않아도 되고 섞어서 사용 가능
--- set ---
생성 = set([1, 2, 2, 3]) - or - {1, 2, 3} - or - s = set() → 빈 중괄호 {}는 dict 클래스가 생성되므로 주의
- 인덱싱 불가 (순서가 없음) → for i in s 로 출력해보면 어떤 값이 먼저 나올지 모름
- 원소 중복 불가 (key 값)
- 원소 추가, 제거, 조회 가능
- 원소로 조회 O(1)
- default가 오름차순 정렬
변환
집합을 문자열로 변환
str_from_set = ''.join(set(['a', 'b', 'c']))집합을 리스트로 변환
list_from_set = list({1, 2, 3})집합을 튜플로 변환
tuple_from_set = tuple({1, 2, 3})
--- list 2개를 key, value로 하여 dictionary 생성 ---
key = ['Alex', 'Jess', 'Dilan', 'Mei', 'Teddy'] value = [80, 90, 95, 67, 88] key_val = [key, value] ##2중 어레이[['Alex', 'Jess', 'Dilan', 'Mei', 'Teddy'], [80, 90, 95, 67, 88]] ##zip(*변수)로 unzip을 하여 dict로 변환 landmark_dict = dict(zip(*key_val))출력 결과
{'Alex': 80, 'Jess': 90, 'Dilan': 95, 'Mei': 67, 'Teddy': 88}
--- dictionary를 list 2개 key, value로 생성 ---
my_dict = {'a': 1, 'b': 2, 'c': 3} keys = list(my_dict.keys()) values = list(my_dict.values())출력 결과
print(keys) # ['a', 'b', 'c'] print(values) # [1, 2, 3]
--- dictionary를 zip(*)을 활용하여 list 2개 key, value로 생성 ---
keys, values = zip(*my_dict.items()) # zip으로 생성된 결과는 튜플이므로 list로 변환 keys = list(keys) values = list(values) print(keys) #['a', 'b', 'c'] print(values) #[1, 2, 3]
--- 리스트 컴프리핸션을 이용하여 변환 ---
my_dict = {'a': 1, 'b': 2, 'c': 3} keys = [k for k in my_dict.keys()] values = [v for v in my_dict.values()] print(keys) # ['a', 'b', 'c'] print(values) # [1, 2, 3]
문자열 (str)
문자열 내장함수
▶ lower ▶ upper
s = "HapPineSS" #소문자 casting된 문자열 반환 s=s.lower() # happiness s=s.upper() # HAPPINESS
▶ find ▶ count
# "s"가 위치한 index 찾기 # 여러 개일 경우 가장 앞쪽 index print(s.find("s")) # 7 # 문자열 내의 "s"의 개수 print(s.count("s")) # 2
▶ replace ▶ split
#문자 변환 s = "Hello, World!" s_new = s.replace("World", "Python") # "Hello, Python!" #주어진 문자열을 쉼표로 분할하여 리스트로 변환 s = "apple,orange,banana" words = s.split('orange') ##['apple', 'orange', 'banana']
문자열 2개 연결하기
a = "ABC" + "DEF" b = "Hello" c = "World" print(a) # ABCDEF print(b + " " + c) # Hello World
리스트(list)
▶ 빈 리스트 생성 ▶ 리스트 2개 연결
arr1 = [] arr2 = list() #2가지 모두 빈 리스트가 생성된다. arr1 = [1, 2] arr2 = [3, 4, 5] arr = arr1 + arr2 # [1, 2, 3, 4, 5]
▶ 리스트 생성과 동시에 초기화 ▶ append
arr = [] for i in range(1,11): arr.append(i) print(arr) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 생성 arr2 = list(range(1, 11)) print(arr2) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 생성
▶ insert
# arr.insert(i, v) : i번 인덱스에 v 추가 arr.insert(3, 7) # [1, 2, 3, 7, 4, 5, 6, 7, 8, 9, 10]
▶ pop ▶ remove ▶ del
##### arr1.pop() : 마지막 원소 꺼내기 (꺼낸 값 반환) ##### arr1.pop(i) : i번 인덱스 값 꺼내기 (꺼낸 값 반환) ##### arr.pop() : 마지막 원소 꺼내기 (꺼낸 값 반환) ##### arr.pop(i) : i번 인덱스 값 꺼내기 (꺼낸 값 반환) print(arr.pop()) # 10 print(arr) # [1, 2, 3, 7, 4, 5, 6, 7, 8, 9] print(arr.pop(3)) # 7 print(arr) # [1, 2, 3, 4, 5, 6, 7, 8, 9] ##### arr1.remove(v) : v 값을 찾아서 제거 ##### 없는 값을 제거할 경우 ValueError: list.remove(x): x not in list 에러 발생 arr.remove(5) # [1, 2, 3, 4, 6, 7, 8, 9] print(arr) del arr[6] # 6번 (7번째) index 원소 삭제 print(arr) # [1, 2, 3, 4, 6, 7, 9]
▶ index ▶ min, max, sum
print(arr.index(7)) # 5 7이라는 값의 인덱스 순서 print(sum(arr)) # a의 모든 원소의 합 32 print(max(arr)) # a의 원소 중 최대 값 9 print(min(arr)) # a의 원소 중 최소 값 1
▶ sort ▶ reverse
a = [1, 3, 2, 7, 5] # 원본 리스트 정렬 (리스트 a 자체 정렬) a.sort() # 오름차순 [1, 2, 3, 5, 7] a.sort(reverse=True) # 내림차순 [7, 5, 3, 2, 1] ##### 정렬된 새로운 리스트 반환 (리스트 a는 원본 유지, 정렬된 리스트 b로 반환) a = [1, 3, 2, 7, 5] b = sorted(a) c = sorted(a, reverse=True) # 내림차순 print(a) # [1, 3, 2, 7, 5] print(b) # [1, 2, 3, 5, 7] print(c) # [7, 5, 3, 2, 1] a = [1, 3, 2, 7, 5] #### 리스트 원소 순서 뒤집기 a.reverse() # [5, 7, 2, 3, 1]
▶ clear
a.clear() # 빈 리스트로 만들기
리스트 활용하기
▶ len
a = [1, 2, 3, 4] len(a) # 리스트 원소의 개수 출력. 4 for i in range(len(a)): print(a[i]) for x in a: print(x)
▶ enumerate
a = [12, 19, 34, 21, 50] for x in enumerate(a): print(x) # (0, 12)\n (1, 19)\n ... (4, 50)\n 튜플로 출력 for x in enumerate(a): print(x[0], x[1]) # 0 12\n 1 19\n ... 4 50\n for i, val in enumerate(a): print(i, val) # 0 12\n 1 19\n ... 4 50\n
▶ all, any
a = [11, 12, 42, 38, 7] ## all(iterable 리스트, 튜플, 딕셔너리 등) ## 모든 요소가 참이면 True, 하나라도 거짓이면 False a = [11, 12, 42, 38, 7] if all(60 > x for x in a): print("모든 원소가 60 미만입니다.") ## all(iterable 리스트, 튜플, 딕셔너리 등) ## 요소가 하나라도 참이면 True, 전부 거짓이면 False if any(10 > x for x in a): print("20미만인 원소가 존재합니다.")
2차원 리스트
▶2차원 리스트 초기화
# N*M 2차원 리스트 초기화 할 때 (세로 N & 가로 M) n = 5 # 세로 크기 m = 4 # 가로 크기 default_value = 0 # N*M 2차원 리스트 초기화 (세로 N & 가로 M) array = [[default_value] * m for _ in range(n)] # 결과 확인을 위한 출력 for row in array: print(row) ## [0, 0, 0, 0] ## [0, 0, 0, 0] ## [0, 0, 0, 0] ## [0, 0, 0, 0] ## [0, 0, 0, 0]
▶특정 영역의 값 계산 ▶각 행의 합
n = 4 m = 4 array = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16] ] ### (1, 1)에서 (2, 2)까지의 합 (인덱스는 0부터 시작) sum_value = 0 for i in range(1, 3): for j in range(1, 3): sum_value += array[i][j] print("Sum of submatrix:", sum_value) ##34 [6,7] [10,11]의 합 #### #### 각 행의 합 for row in array: row_sum = sum(row) print("Row sum:", row_sum) ##Row sum: 10 ##Row sum: 26 ##Row sum: 42 ##Row sum: 58
튜플 (tuple)
▶튜플 생성 및 초기화 ▶튜플에 원소 추가
t = (1, 2, 3, 4, 5) ##생성 t1 = (1, 2, 3) t2 = (4, 5) t3 = t1 + t2
▶튜플 인덱스로 값 조회 ▶튜플 값 존재 여부 확인
print(t[3]) # 4 print(t[1:4]) # (2, 3, 4) t[3] = 2 # Error. 변경 불가, 불가능한 문법 print(1 in t) # True print(9 in t) # False
▶ count ▶ index
t = (1, 2, 2, 3, 3, 4) print(t.count(2)) ## "2"의 갯수 반환 print(t.index(4)) ## 특정 값의 인덱스 반환. # 여러 개면 가장 앞쪽 인덱스, 없으면 에러 print(t.index(2)) # 1
딕셔너리 (dict)
▶‘key’로 문자열, 정수형, 실수형, 불린형 모두 사용 가능
▶‘value’로는 추가로 리스트, 딕셔너리까지도 사용 가능
▶딕셔너리 초기화
### dict 초기화 data = dict() data['사과'] = 'Apple' data['바나나'] = 'Banana' data['코코넛'] = 'Coconut' #### 딕셔너리 key만, value만 리스트로 data.keys() # key만 ##출력 : dict_keys(['사과', '바나나', '코코넛']) data.values() # value만 ##출력: dict_values(['Apple', 'Banana', 'Coconut'])
집합(set)
▶ add ▶ update ▶ remove
s = {1, 2, 3} # set.add(v) 새로운 원소 추가 s.add(4) # {1, 2, 3, 4} ##### # set.update(v) 새로운 원소 여러 개 추가 (수정 보다는 여러 개 추가 개념) s.update([5,7]) # {1, 2, 3, 4, 5, 7} ##### a = {1, 2, 3} # set.remove(v) 원소 삭제 s.remove(4) # {1, 2, 3, 5, 7}
Python 코테 cheat sheet
한 줄에 여러 개의 숫자 입력 받기
~~~~~~~[입력 예시]~~~~~~~ 1 2 3 4 a, b, c, d = map(int, input().split()) print(a, b, c, d) # 1, 2, 3, 4 ~~~~~~~[입력 예시]~~~~~~~ 1 3 5 7 9 10 a = list(map(int, input().split())) print(a) # [1, 3, 5, 7, 9, 10] ~~~~~~~[입력 예시]~~~~~~~ A B C D E a = list(input().split()) print(a) # ['A', 'B', 'C', 'D', 'E']
리스트 중복 제거 & 정렬
a = [3, 1, 5, 8, 5, 10, 7, 1] print(a) b = list(set(a)) # [1, 3, 5, 7, 8, 10] c = sorted(list(set(a))) # [1, 3, 5, 7, 8, 10] d = sorted(list(set(a)), reverse=True) # [10, 8, 7, 5, 3, 1]
리스트 전체 합과 평균 구하기
N = int(input()) # 개수 a = list(map(int, input().split())) # 점수 리스트 입력 total = sum(a) avg = int(round(total/N, 0)) # 평균을 첫째 자리에서 반올림
리스트 반복문에서 리스트의 원소 여러 번 사용할 때
score = [80, 83, 95, 87, 93, 71] for i, val in range(N): if val < 90: # "score[i] < 90" 대신 짧고 편하게 사용 가능 print("B") elif val < 80: print("C") elif val < 70: print("D")
리스트 원소 개수 세기 (딕셔너리 활용)
s = [1, 3, 4, 2, 3, 4, 1, 3] cnt = {} # dictionary 생성 for x in s: if x in cnt: cnt[x] += 1 else: cnt[x] = 1
딕셔너리 value로 key값 찾기
for key, value in cnt.items(): if value == "찾을 value 값": print(key, end=' ') # value에 해당하는 key 값 출력
두 변수 값 바꾸기 (swap) + 딕셔너리 ‘key’ 또는 ‘value’로 존재 여부 확인
##swap a,b = b,a # 키 존재 여부 확인 if '사과' in data: print("키 '사과'가 존재합니다.") # 값 존재 여부 확인 if 3 in data.values(): print("값 3이 존재합니다.")
딕셔너리를 key 또는 value 기준으로 정렬
a = {'Tom': 90, 'Liz': 75, 'John': 67, 'Mia': 92} print(a.keys()) # dict_keys(['Tom', 'Liz', 'John', 'Mia']) print(list(a.keys())) # ['Tom', 'Liz', 'John', 'Mia'] print(sorted(a.keys())) # ['John', 'Liz', 'Mia', 'Tom'] print(sorted(a.keys(), reverse=True)) # ['Tom', 'Mia', 'Liz', 'John'] # 튜플 자료형으로 리턴 print(sorted(a.items())) # 결과 : [('John', 67), ('Liz', 75), ('Mia', 92), ('Tom', 90)] print(sorted(a.items(), reverse=True)) # 결과 : [('Tom', 90), ('Mia', 92), ('Liz', 75), ('John', 67)] # 람다식 key값 기준 정렬 print(sorted(a.items(), key=lambda x: x[0])) # 결과 : [('John', 67), ('Liz', 75), ('Mia', 92), ('Tom', 90)] print(sorted(a.items(), key=lambda x: x[0], reverse=True)) # 결과 : [('Tom', 90), ('Mia', 92), ('Liz', 75), ('John', 67)] # 람다식 value값 기준 정렬 print(sorted(a.items(), key=lambda x: x[1])) # 결과 : [('John', 67), ('Liz', 75), ('Tom', 90), ('Mia', 92)] print(sorted(a.items(), key=lambda x: x[1], reverse=True)) # 결과 : [('Mia', 92), ('Tom', 90), ('Liz', 75), ('John', 67)]
2차원 리스트 입력 받기
''' [입력 예시] 5 0 2 1 1 0 1 1 1 1 2 0 2 1 2 1 0 2 1 1 0 0 1 1 1 2 ''' n = int(input()) arr = list(list(map(int, input().split())) for _ in range(n))
이분 탐색
중앙값을 찾아서 비교해서 중앙값 전/후로 나누어서 다시 탐색을 반복
a.sort() # 먼저 정렬 lt = 0 # 시작 값 rt = n-1 # 끝 값 ##와일문 제한 while lt <= rt: mid = (lt + rt) // 2 if a[mid] < m: lt = mid + 1 elif m < a[mid]: rt = mid - 1 elif m == a[mid]: print(mid+1) break
python list 2개로 dictionary를 생성하기
key = ['Alex', 'Jess', 'Dilan', 'Mei', 'Teddy'] value = [80, 90, 95, 67, 88] key_val = [key, value] landmark_dict = dict(zip(*key_val)) ### 결과 : {'Alex': 80, 'Jess': 90, 'Dilan': 95, 'Mei': 67, 'Teddy': 88}
python list가 비어있는지 확인
arr = [] if not arr: print("empty") ## if arr: print("not empty")
python list의 마지막 요소 가져오기/제거하기
arr = [1, 3, 5, 2, 4] print(arr[-1]) # 4 arr.pop() print(arr) ##[1, 3, 5, 2]
str -> 중복제거 set -> String으로 변환
my_string = "aavvccccddddeee" # converting the string to a set temp_set = set(my_string) # stitching set into a string using join new_string = ''.join(temp_set) print(new_string) ## 결과 :vcdae
열을 짧게 구성 + 빠르게 행렬 구성
n = 3 my_list = [0]*n # n denotes the length of the required list # [0, 0, 0, 0] print(my_list) print([my_list]*3)
도움될만한 링크 : https://velog.io/@jeong_yooony/Code-Up-%ED%8C%8C%EC%9D%B4%EC%8D%AC-100%EC%A0%9C
