Cues
-
유사도 라는 것에 의해 사물의 분류가 정해 진다면 이것은 search 의 일종이 아닌가?
단순히 미니멈을 찾는 것으로는 변수를 수정할 수가 없고 만약 직접 변수를 할당하면 i 가 날아감
-
크기와 붉은 정도와 같은 특징 추출에 있어 서의 "특징"은 어떠한 데이터에 의해 저장이 되는 가?
-
그렇다면 사실 차선책을 따라가는 탐욕 알고리즘의 일종이 아닌가?
-
만약 X - Y 축 그래프를 그려야 한다면 맥시멈 기준으로 사용할 특징은 고작 2가지 인가?
-
좋은 특징이란?
Notes
-
KNN 에서 무언가를 분류할 때 그래프 상에서 가까운 노드 들이 얼마나 많은 가에 의해 결정.
-
넷플릭스 등에서의 추천 시스템은 대상 유저와 취향이 가장 비슷한 5 명의 고객이 좋아하는 영화를 추천해주는 방식이다.
-
유사도를 특정하려면 아래의 이미지처럼 size, color saturation 같은 특징을 추출해야한다.
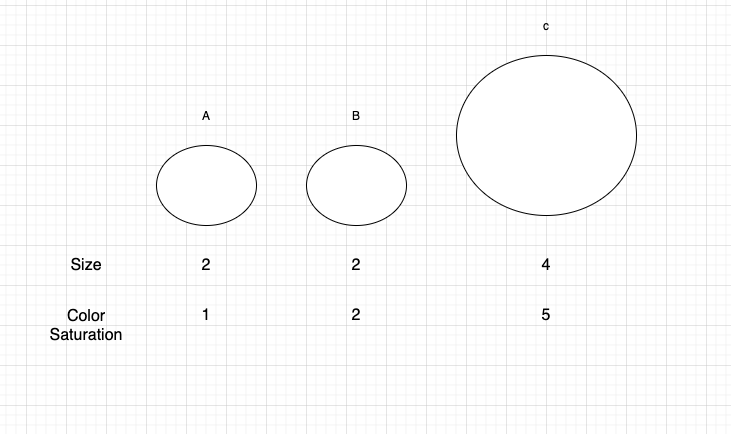
-
아래와 같이 그래프를 만든다 (X, Y 축은 위의 각 특징들에 따라)
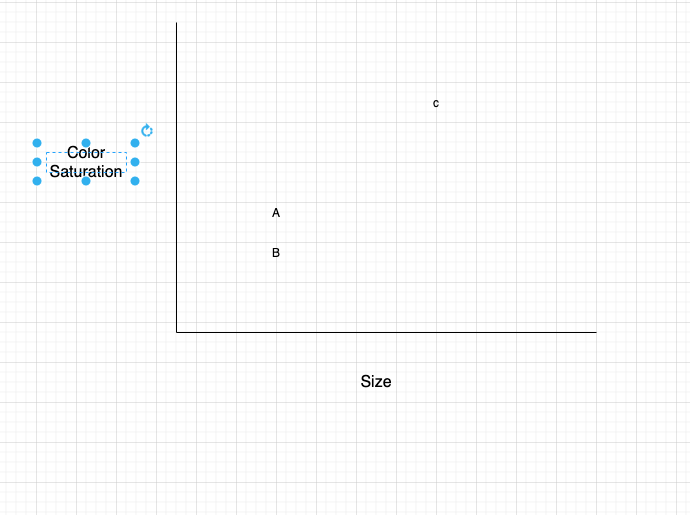
-
이 들간의 거리는 피타고라스의 정리를 사용한다.
-
위의 예시에 대한 수식은 다음과 같다.
- √[(2-2)²+(2-1)²]
- √0+1
- √1
- 1
- √1
- √0+1
- √[(2-2)²+(2-1)²]
-
그래프 뿐만 아니라 집합으로 나타내는 방법도 있다.
-
회귀 분석 (regression analysis) 는 위의 예시에서 평점을 예측할 때도 쓰인다.
-
KNN (분류: 그룹으로 나누기) / 회귀 (숫자로 된) 반응을 예측하기
-
가령 빵집을 운영할 때 오늘 몇개의 빵을 만들어야 할지 예측하고 싶다면...
- 특징정보를 파악해야한다. 예를 들면 이렇다.
- 1점부터 5점까지 숫자로 표현한 날씨 (1,2,3,4,5)
- 주말 또는 휴일인지 (1, 0) Boolean?
- 스포츠 경기가 있는지? (1, 0)
- 분류 데이터를 모은다.
- A(5,1,0) = 300
- B(3,1,1) = 225
- C(1,1,0) = 75
- D(4,0,1) = 200
- E(4,0,0) = 150
- F(2, 0, 0) = 50
- 그렇다면 G(4,1,0) 의 경우에는?
- 피타고라스 정리를 이용해서 거리를 구했을 때 ABDE 와 가장 가깝다
- ABDE 의 평균을 구하면 218.75 다.
- 특징정보를 파악해야한다. 예를 들면 이렇다.
-
코사인 유사도(Cosine similiary) 가 실무에서 더 많이 이용된다.
- 같은 취향을 같은 두 고객이 한명은 점수를 주는데 인색하다라면? 이웃이 되지 않을수도 있지 않나?
- 코사인 유사도는 두 벡터의 거리가 아닌 각도를 측정.
- 같은 취향을 같은 두 고객이 한명은 점수를 주는데 인색하다라면? 이웃이 되지 않을수도 있지 않나?
-
머신러닝 이란?
- OCR Optical Character Recognition 광학 문자 인식
- 책의 페이지를 사진으로 찍으면 컴퓨터가 자동으로 그 사진 속의 글자를 읽어주는 것.
- OCR 의 원리? 여러 가지 숫자 그림을 살펴보고 이 그림들의 특징을 뽑아냄.
- 새로운 그림이 주어지면 그림의 특징을 뽑아서 가장 가까운 것을 살펴봄.
- OCR 의 경우 문자의 직선, 점, 곡성들을 찾아냄.
- 스팸 필터는 Naive Bayes Classifier 라고 하는 간단한 알고리즘을 이용.
- 각 단어의 스팸 유사성을 찾아서 스팸으로 분류.
-
만약 특정 인물들의 평점에 가중치를 주고 싶다면 명수를 늘리듯 가중치를 할당.
Summary
- KNN 이란 k개의 가장 가까운 이웃 데이터를 이용하여 분류와 회귀 분석을 할 수 있음.
- 분류 = 그룹으로 나누는 작업
- 회귀 = 숫자로 된 반응을 예측
- 특징 추출은 항목을 비교 가능한 몇개의 숫자로 만듬.
- 좋은 특징을 고르는 것은 성공적인 알고리즘 모델을 위해 중요
