
사실 Redis를 많이 사용하는데 그냥
Inmemory기반이고key-value로 데이터를 저장하니까 속도가 빠르지 않을까? 그니까 많이 사용하는거지 않을까? 라고 무의적으로 사용했는데 왜 Redis를 사용하는지, 사용법, 그리고 어케 적용하는지 알아야할 것 같아서 글을 써볼려고 한다.
🤔 왜 사용할까?
사실 가장 큰 이유는 높은 성능과 확장성 때문이다.
인메모리(In-Memory) 기반이라는 말은 말 그대로 데이터를 메모리(RAM) 안에서 처리하거나 저장하는 방식을 의미한다. 그렇기 때문에 Redis는 읽기/쓰기 속도가 매우 빠르다.
하지만 Redis에도 단점은 분명히 존재한다.
첫째, 메모리 용량에 한계가 있다. 예를 들어, 내가 사용하는 맥북 M2의 RAM이 16GB라면, 이 16GB는 모든 데이터 저장과 처리를 위한 전체 용량이다. 서버에서도 비슷하게 RAM은 한정되어 있으므로, 대용량 데이터를 저장하기엔 부담이 될 수 있다.
둘째, Redis는 Key-Value 형태의 NoSQL이다.
처음에는 이게 편하게 느껴질 수 있지만, 실제로는 우리가 자주 사용하는 객체 지향 방식의 복잡한 구조를 표현하기에는 제약이 생긴다. 관계형 DB처럼 복잡한 조인이나 조건 검색을 하긴 어렵다는 특징이 존재한다.
이러한 단점을 보완하고, Redis의 빠른 속도를 최대한 활용하기 위해 캐시(Cache) 용도로 사용되기 시작했다.
❓ 캐시?
- 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소
- 캐시에 있는 데이터는 시간과 자원 면에서 최소한의 비용으로 반복적으로 접근 가능
🤔 그냥 DB를 사용하면 안돼?
DB는 데이터를 디스크에 직접 저장(write)하기 때문에 서버가 다운되도 크게 문제가 없긴하다.
하지만 매번 디스크에 접근해야하므로 사용자가 급증하면 속도가 느려질 가능성이 존재한다. 따라서 캐시를 도입하는것이 가장 좋은 방법이고 자주 사용하는 것이 Redis다.
Redis 구조
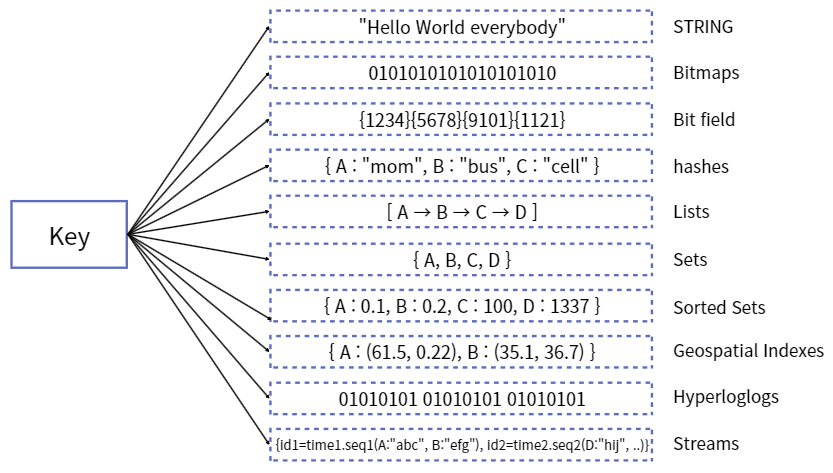
Redis는 다양한 자료구조가 존재한다. String,Bitmaps,Lists등등 다양한 형태를 key-value로 저장할 수있다. 어떠한 형태를 사용하더라도 반드시 Key는 사용되어야한다.
Redis Disk 저장 방식? AOF?
아까 위에서 말했듯이 Redis는 인메모리 방식이라 컴퓨터가 꺼지거나 재시작되면 데이터가 사라질 가능성이 존재한다. 따라서 메모리에 저장된 데이터를 디스크에 저장하는 방식도 존재한다고 한다. 크게 RDB(snapshotting) 방식과 AOF(Append only file) 방식이 존재한다.
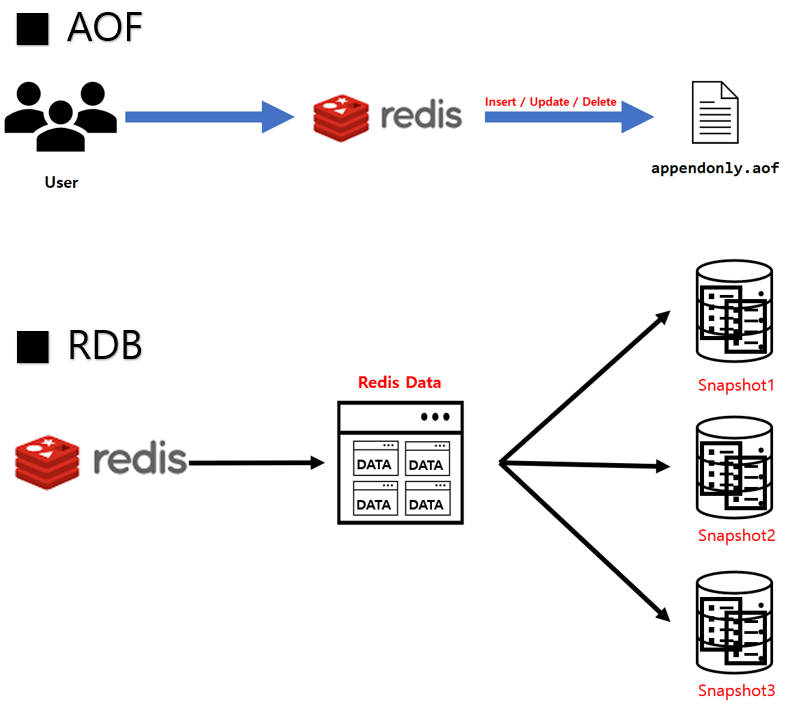
1) RDB (snapshotting) 방식
Redis는 인메모리 데이터베이스지만, 주기적으로 데이터를 디스크에 저장해 장애 상황에서도 복구가 가능하다. 기본 설정에서는 RDB 방식으로 일정 시간마다 메모리 상태를 스냅샷 파일로 저장한다. 따라서 Redis 프로세스가 예기치 않게 종료되더라도, 저장된 파일을 읽어 이전 상태로 복원할 수 있다.
특징으로는 .rdb 파일은 AOF 파일보다 사이즈가 작다.
RDB (snapshotting)는 우리가 알고있는 데이터베이스의 한 종류와 헷갈리는 경우가 많은데 다른 개념이다.
RDB (snapshotting)는 메모리의 스냅샷을 그대로 저장하기 때문에 서버를 재구동할 때 스냅샷을 다시 읽으면 속도가 빠르지만, 추출하는데 오래걸리고 서버가 도중에 꺼지면 데이터가 다 날라간다.
🤔 스냅샷?
특정 시점의 메모리에 있는 데이터를 바이너리 파일로 저장하는 뜻, 쉽게 말해 그 시점의 상태(정보)를 그대로 저장해두는 것을 의미한다.
Redis-cli 설정 방식
- RDB 관련 info 조회
> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1655100738
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:-1
rdb_current_bgsave_time_sec:-1
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok- 수동 SAVE 하기
> BGSAVE
Background saving started직접 터미널에서 명령으로도 RDB 파일을 수동 생성이 가능하다.
AOF (Append Only File)
Redis의 AOF(Append Only File)는 모든 write/update 연산을 로그 파일에 순차적으로 기록하는 방식이다.
기본적으로 appendonly.aof 파일에 기록되며, 조회(read)를 제외한 삽입, 수정, 삭제 명령이 실행될 때마다 로그가 저장된다.
서버가 재시작되면, 이 로그 파일을 순서대로 재실행함으로써 이전 상태를 복구한다.
-
클라이언트가 Redis에 업데이트 관련 명령(예: SET, DEL 등)을 요청한다.
-
Redis는 해당 명령을 AOF(Append Only File)에 기록한다.
-
파일 쓰기가 완료되면, Redis는 명령을 실행하여 메모리(RAM) 상의 데이터를 변경한다.
이처럼 현재 시점까지의 log를 기록 가능하며, 기본적으로 논블로킹으로 동작된다.
AOF는 로그 파일에 append(추가)만 하기 때문에 쓰기 속도가 빠르고,
어떤 시점에서 서버가 다운되더라도 데이터가 손실되지 않는 장점이 있다.
그러나, 모든 write/update 연산을 로그 파일에 기록하기 때문에 로그 데이터의 양이 매우 커지고,
복구 시 저장된 모든 write/update 연산을 재실행해야 하므로, 서버 재시작 속도가 느려지는 단점이 있다.
- 그렇기에 AOF 방식은 rewrite 기능을 제공하여 특정 시점에 데이터 전체를 다시 쓰는 기능이 존재한다. 이러면 최종 데이터만 기록된다는 특징이 존재한다.
Redis-cli 설정 방식
> BGREWRITEAOF
Background append only file rewriting startedAOF Rewrite는 BGREWRITEAOF 커멘드를 이용해 CLI 창에서 수동으로 AOF 파일 재작성 가능
AOF vs RDB
굳이 Redis를 캐시로만 사용하면, 굳이 백업 기능이 필요없으면 AOF 방식을 사용하고, 백업은 필요하지만 어느정도 데이터 손실이 발생해도 괜찮으면 RDB를 단독으로 사용하자!!
😻 스프링(Redis)에서의 Redis
Redis를 스프링부트에서 사용을 하고 있는데 그냥 Redis에 필요한 데이터를 넣고 꺼내기만 해봤지 어떻게 효율적으로 사용하는지에 잘 몰랐다. 따라서 이 참에 공부를 해볼려고 한다. 참고로 나는 Redis를 도커(Docker)에 띄워서 사용한다. 자세한 설명법은 다른 사람의 블로그를 참고해주길 바란다.
[리눅스] Docker로 redis설치하기
설정
build.gradle
// Redis
implementation 'org.springframework.boot:spring-boot-starter-data-redis'RedisConfig
@Configuration
public class RedisConfig {
@Value("${redis.host}")
private String redisHost;
@Value("${redis.port}")
private int redisPort;
@Bean
public LettuceConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration config = new RedisStandaloneConfiguration(redisHost,
redisPort);
return new LettuceConnectionFactory(config);
}
@Primary
@Bean
public RedisTemplate<String, String> redisStringTemplate(
RedisConnectionFactory connectionFactory) {
RedisTemplate<String, String> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new StringRedisSerializer());
return template;
}
@Bean
public RedisTemplate<String, Object> redisObjectTemplate(
RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
template.setKeySerializer(new StringRedisSerializer());
GenericJackson2JsonRedisSerializer serializer = new GenericJackson2JsonRedisSerializer();
template.setValueSerializer(serializer);
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}나는 코드 변경 없이 환경별 Redis 접속 정보를 유연하고 안전하게 관리하기 위해, 호스트와 포트를 application.yml 에서 주입받아 RedisStandaloneConfiguration에 설정했다.
redisStringTemplate, redisObjectTemplate를 두개 다 설정한 이유는 단순 문자열 데이터와 구조화된 객체 데이터를 각각 최적의 방식으로 직렬화·역직렬화하고, 운영 관점에서 성능·가독성·타입 안전성을 확보하기 위해 문자열 전용 템플릿과 JSON 객체 전용 템플릿을 분리하기 위해서 그렇게 설정하였다.
따라서 만약에 key-value 가 문자열 - 문자열인 경우 private final RedisTemplate<String, String> redisTemplate; 으로 , key-value 가 문자열 - 객체 인 경우에 private final RedisTemplate<String, String> redisTemplate; 를 사용하면 된다.
사진 출처
참고
