.png)
오버피팅
훈련셋을 이용하여 훈련을 지나치게 많이 하게 될 경우, 훈련셋에 대해서는 오차가 적게 훈련이 되지만 시험셋이나 다른 데이터셋에 대해서는 오차가 커지는 현상이다.
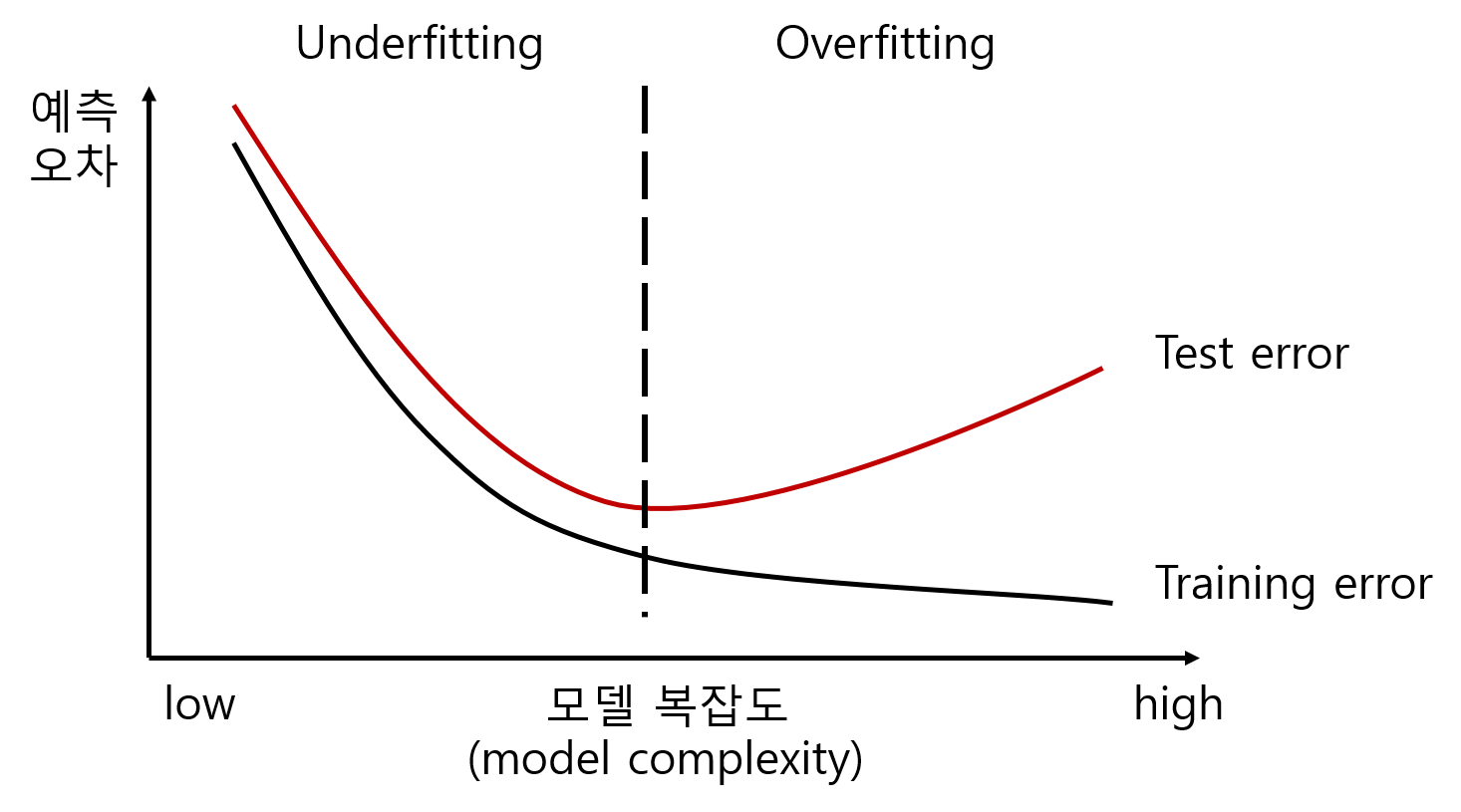
오버피팅 해결
검증셋이 있다면 스스로 평가하면서 적절한 학습방법을 찾아 볼 수 있다.
검증셋으로는 훈련을 하지 않고 스스로 검증을 한다.
가장 이상적인 학습량을 찾아야한다.
문제해결 방법
- 오버피팅이 되는 에포크를 확인하고, 오버피팅 전의 에포크 만큼 모델을 학습을 시킨다. → 단점)두번 학습
- 콜백함수를 이용하여, 오버피팅이 감지되면 조기 중단을 시킨다. → 단점) 더 좋은 가중치가 나올 수 있다.
- 콜백함수를 사용하여, 매 에포크마다 검증셋의 손실값을 확인한 후, 이전 손실값보다 낮은 경우 모델을 파일로 저장한다, 즉 학습이 종료가 되면 파일에 저장된 모델은 손실값이 가장 낮을 때의 가중치를 가지고 있다.
3번째 방법
→ save_best_only = True
손실값이 가장 적게 나온 모델을 저장하는 콜백함수를 지정해 준다.
checkpoint_callback = ModelCheckpoint("best_model.h5",
save_best_only=True,
monitor="val_loss") hist = model.fit(x_train, y_train,
validation_split=0.2,
batch_size=32,
epochs=100,
callbacks=[checkpoint_callback])
computer science student