Index
추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다
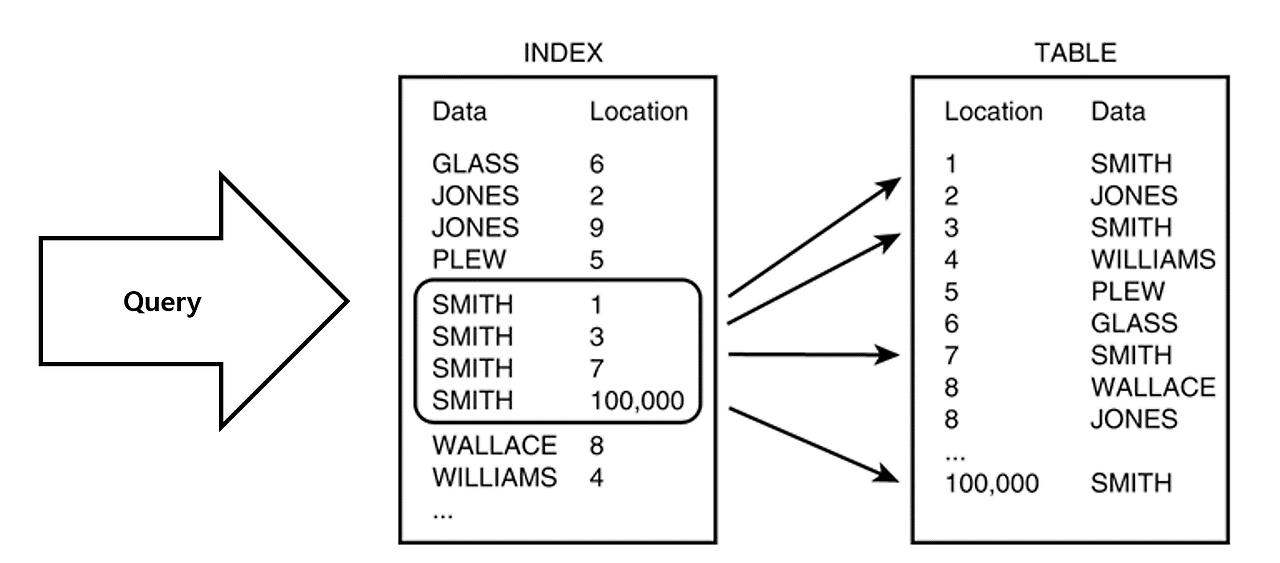
장점
- 테이블을 조회하는 속도와 그에 따른 성능을 향상시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
이러한 장점은 대부분 index는 정렬에 기인된 장점들이다.
조건 검색의 효율성
원래 테이블은 순서없이 데이터들이 뒤죽박죽 섞여있기 때문에 Full Table Scan을 통해 원하는 데이터를 검색하는데, 정렬이 되어있다면 조건에 맞는 데이터를 찾는데 효율적이다.
정렬의 효율성
정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생된다. 하지만 인덱스를 사용하면 이러한 전반적인 자원의 소모를 하지 않아도 된다.
최대, 최소 값의 효율성
마찬가지로 정렬되어있기 때문에 쉽게 찾을 수 있다.
단점
- 다른 메모리공간이 추가적으로 필요하다.
- 데이터를 삽입하거나 업데이트할때 항상 정렬 상태를 유지해야하기 때문에 수정해야한다.
- 실제 데이터의 10% ~ 15%이하의 데이터를 처리할 때만 큰 효과를 기대할 수 있다.
따라서 아래와 같은 상화에 사용하는 것이 유리하다.
- 규모가 작지 않은 테이블
- INSERT, UPDATE, DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
- etc
Index의 구현
Hash Table
자세한 내용은 [[Hash]]에 있다.
(Key, Value)의 쌍으로 이뤄져 있어, 선형시간에 검색을 할 수 있는 장점이 있다.
하지만 Hash Table은 등호연산에만 장점을 가지고 있어, Index가 가지는 장점을 100% 사용할 수 없다.
즉, 사전검색에서 a 라고치면 apple을 찾기위해선 Full Table Scan을 해야한다.
B Tree
자세한 내용은 [[B+ tree]]에 있다.
이는 트리형태의 데이터 구조로 각 노드에 데이터를 연속적으로 저장하고 있어, 검색에 큰 장점을 가진다.
하지만, 모든 Table의 데이터가 필요한 상황에는 많은 Pointer연산이 필요하고 이는 연산 overhead를 발생시킬 수 있다.
B+ Tree
자세한 내용은 [[B+ tree]]에 있다.
이는 B Tree의 개선 자료구조로 모든 데이터를 Lead node에 저장해 범위검색이나, Full Scan에 장점이 있는 자료구조이다. 또 각 노드에 데이터가 있는 구조가 아니라 Memory적으로 효율적이다.
하지만 모든 데이터를 찾기위해 leaf까지 내려가야하는 단점이 있다.
다양한 종류
Dense Index
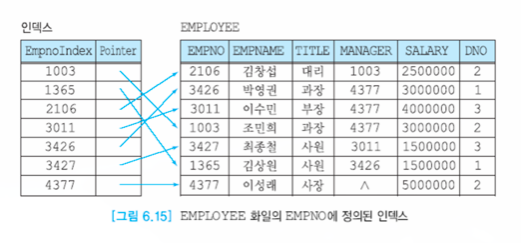
한 index에 원하는 record가 바로 매칭된다.
Sparse Index
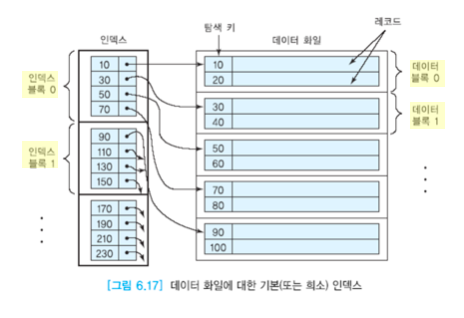
- 느슨한 인덱스
- block 속에서 진짜 자기가 원하는 값을 찾아야 한다.
- data를 fragnation이 일어나지 않고, 효율성을 높이기 위해서 블록 단위로 놓는 것이다.
Composite Index
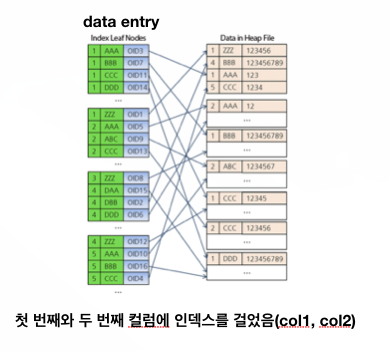
- single index가 한 cloumn에 indexing을 하는 것과 다르게 여러개의 column에 indexing을 한다.
빈도수가 적은 인덱스를 먼저 거는 것이 좋다.
ex) (a, b)를 가지는 데이터를 찾는다면, Composite index는 둘중에 더 적은 데이터수를 가진것을 찾는것이 효율성이 높다. (남자, 서)라고 대한민국 사람을 검색한다면, 서씨로 찾는게 더 이득!
Multi Level Index
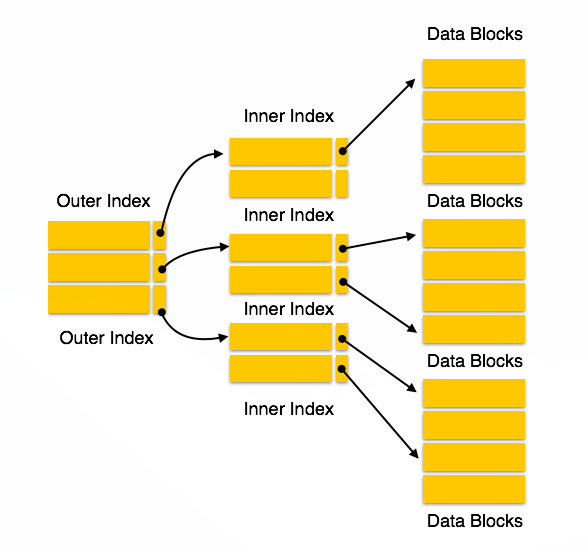
- 인덱스를 위한 인덱스를 위한 인덱스를 위한… 인덱스!
- 데이터가 커지면 index 크기 역시 커집니다.
- 그러므로 single level index를 사용할 수가 없어 multilevel index를 사용합니다.
- inner index(원래 인덱스)를 작은 색인으로 분할하여 outer index를 작게 만든다.
- 그로 인한 단점으로 I/O가 자주 일어난다.
- 실제 데이터베이스 파일과 함께 디스크에 저장됩니다.
Secondary Index
index들은 키의 순서와 record의 순서가 같은 Primary Index(Clustering Index)였다면,
키의 순소와 데이터의 순서가 상관이 없는 index를 의미한다.
