String
Brute Force
검색 대상이 되는 원본 문자열의 처음부터 끝까지 차례대로 순회하며 문자들을 일일이 비교하는 방식의 고지식한 알고리즘입니다.
특징
1. 시간복잡도 : O(nm), n = 총 문자열의 길이, m = 찾으려는 문자열 패턴의 길이
2. 장점 : 구현이 쉬운편이다.
3. 단점 : 비효율적이다.
구현
1. T, P 모두 첫 문자부터 비교를 시작하므로 검색 인덱스를 맨 처음 인덱스로 설정합니다.
2. 각각의 검색 인덱스부터 하나씩 문자를 비교합니다.
1. 비교 문자가 같으면 T, P의 인덱스 모두 뒤로 한 칸씩 이동합니다.
2. 비교 문자가 다르면 T의 인덱스는 한 칸 뒤로 이동하고, P의 인덱스는 맨 처음 인덱스로 돌아갑니다.
3. 다시 2번 과정부터 검색이 끝날 때까지 반복합니다.

KMP
접두사와 접미사의 개념을 활용하여 ‘반복되는 연산을 얼마나 줄일 수 있는지’를 판별하여 매칭할 분자열을 빠르게 점프하는 기법이다 .
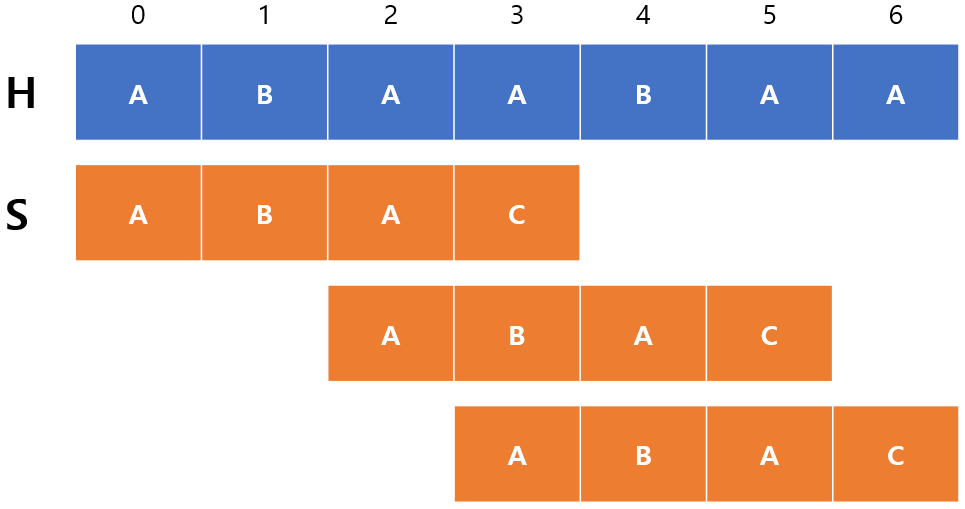
구현
pi[i]는 주어진 문자열의 0~i 까지의 부분 문자열 중에서 prefix == suffix가 될 수 있는 부분 문자열 중에서 가장 긴 것의 길이
이 배열을 통해 매칭을 해가면 불일치가 발생하면 위 배열을 이용해 추가 비교를 수행하지 않고 넘어갑니다.
**시간복잡도 : O(n+m), n = 문자열의 길이, m = 패턴의 길이
Boyer - Moore
부분에서 불일치가 일어날 확률이 높다는 성질을 활용합니다. 그래서 오른쪽 끝부터 비교하게 됩니다.

구현
p의 거리를 측정하는 배열을 만들어서 P에서 겹친다면 p를 저 위치로 스킵한다.
시간 복잡도 : O(mn), 평균 : O(n/m)
