ES를 적용하는 프로젝트의 상태
검색 기능
검색 관련 아키텍쳐
검색 기능 관련 기능
간단 정리
시도한 다른 방법
ES를 적용하는 프로젝트의 상태
서버 : Spring Boot (AWS EC2)
DB : MySQL (AWS RDS)
검색 기능
기능 1
MySQL에서 일대다로 매핑되어있는 두 개의 테이블(Stories:Episodes == 1:N)에서
장르, 검색 내용, 페이지네이션 이 세 개의 조건과 함께 동시에 검색되어야 한다.
검색 내용은 Stories테이블의 storyTitle, Episodes테이블의 episodeTitle, description 중 하나라도 포함되어있는 데이터를 찾아야 한다.
검색 내용이 episodes의 description에 포함되어있을 경우 해당 부분부터 일정 길이를 잘라서 리턴한다.
(description의 경우 최대 5만자 까지 저장되기 때문)
검색 내용이 episodes의 description 혹은 episodeTitle과 일치할 경우 해당 episode의 story 정보까지 같이 리턴 한다.
검색 내용이 stories의 storyTitle과 일치할 경우 해당 story의 episode를 일괄적으로 리턴한다.
기능 2
MySQL의 Users라는 테이블에서 검색 내용을 penName을 기준으로 찾게 된다.
검색 내용을 포함하고 있거나 일치하는 user의 데이터 일부분을 보낸다.
검색 관련 아키텍쳐
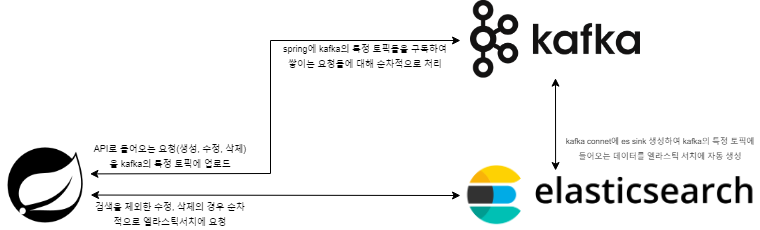
검색 기능 관련 기능
kafka, zookeeper, connect docker-compose
version: '3.3' # Docker Compose 파일 버전
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0 # Zookeeper 이미지 버전
hostname: zookeeper # 컨테이너 내 호스트 이름 설정
container_name: zookeeper # 컨테이너 이름 설정
ports:
- "2181:2181" # Zookeeper의 2181 포트를 호스트의 2181 포트와 연결
environment:
ZOOKEEPER_CLIENT_PORT: 2181 # Zookeeper 클라이언트 포트 설정
ZOOKEEPER_TICK_TIME: 2000 # Zookeeper의 tick time 설정 (밀리초 단위)
networks:
- kafka # kafka 네트워크에 연결
kafka:
image: confluentinc/cp-kafka:7.3.0 # Kafka 이미지 버전
hostname: kafka # 컨테이너 내 호스트 이름 설정
container_name: kafka # 컨테이너 이름 설정
depends_on:
- zookeeper # Zookeeper가 먼저 실행된 후 Kafka 실행
ports:
- "29092:29092" # Kafka 내부 포트 29092를 호스트의 29092 포트와 연결
- "9092:9092" # Kafka 내부 포트 9092를 호스트의 9092 포트와 연결
- "9101:9101" # JMX 모니터링용 포트
environment:
KAFKA_HEAP_OPTS: "-Xms512M -Xmx512M" # Kafka JVM 힙 메모리 설정 (512MB)
KAFKA_BROKER_ID: 1 # Kafka 브로커 ID (고유 식별자)
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181' # Zookeeper와 연결할 주소 설정
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT # 보안 프로토콜 맵핑
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://url # 외부에서 접근할 Kafka 리스너 설정
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1 # 오프셋 토픽의 복제 수
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1 # 최소 ISR (복제본 수) 설정
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1 # 트랜잭션 로그의 복제 수 설정
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0 # 그룹 리밸런스 지연 시간을 0으로 설정
KAFKA_JMX_PORT: 9101 # JMX 모니터링 포트 설정
KAFKA_JMX_HOSTNAME: localhost # JMX 모니터링용 호스트 설정
networks:
- kafka # kafka 네트워크에 연결
connect:
image: confluentinc/cp-kafka-connect:7.3.0 # Kafka Connect 이미지 버전
ports:
- 8083:8083 # Kafka Connect의 8083 포트를 호스트의 8083 포트와 연결
container_name: connect # 컨테이너 이름 설정
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:29092 # Kafka Connect가 연결할 Kafka 브로커 주소
CONNECT_REST_PORT: 8083 # Kafka Connect REST API 포트 설정
CONNECT_GROUP_ID: "quickstart-avro" # Kafka Connect 클러스터의 그룹 ID
CONNECT_CONFIG_STORAGE_TOPIC: "quickstart-avro-config" # Kafka Connect 설정을 저장할 토픽
CONNECT_OFFSET_STORAGE_TOPIC: "quickstart-avro-offsets" # 오프셋을 저장할 토픽
CONNECT_STATUS_STORAGE_TOPIC: "quickstart-avro-status" # 상태를 저장할 토픽
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1 # 설정 토픽의 복제 수
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1 # 오프셋 토픽의 복제 수
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1 # 상태 토픽의 복제 수
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" # 메시지 key를 변환할 JSON 컨버터 설정
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" # 메시지 value를 변환할 JSON 컨버터 설정
CONNECT_INTERNAL_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" # 내부 key 변환용 JSON 컨버터 설정
CONNECT_INTERNAL_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter" # 내부 value 변환용 JSON 컨버터 설정
CONNECT_PLUGIN_PATH: "/etc/kafka-connect/jars" # Kafka Connect 플러그인 경로 설정
CONNECT_REST_ADVERTISED_HOST_NAME: "localhost" # 외부에서 접근할 Kafka Connect REST API의 호스트 이름 설정
volumes:
- /home/ec2-user/kafka/component/confluentinc-kafka-connect-jdbc:/etc/kafka-connect/jars # 로컬 디렉터리를 컨테이너 내부의 플러그인 경로에 마운트
networks:
- kafka # kafka 네트워크에 연결
networks:
kafka:
external: true # 외부 네트워크 사용 (이미 생성된 네트워크)더 찾아본 결과 최근에는 zookeeper를 사용하지 않는다고 하나 zookeeper를 뺀 경우 어떻게 구성해야 하는지 찾지 못해서 zookeeper를 그대로 사용함
elasticSearch docker-compose
version: '3.2' # Docker Compose 파일 버전
services:
elasticsearch:
build:
context: elasticsearch/ # Elasticsearch를 빌드할 컨텍스트 디렉토리
args:
ELK_VERSION: $ELK_VERSION # ELK 스택의 버전 정보, 환경 변수로 설정 가능
volumes:
- type: bind
source: ./elasticsearch/config/elasticsearch.yml # 로컬 파일 시스템의 설정 파일을 컨테이너 내부로 마운트
target: /usr/share/elasticsearch/config/elasticsearch.yml # 컨테이너 내의 설정 파일 경로
read_only: true # 설정 파일을 읽기 전용으로 마운트
- type: volume
source: elasticsearch # Elasticsearch 데이터 저장을 위한 볼륨
target: /usr/share/elasticsearch/data # 컨테이너 내 데이터 저장 경로
ports:
- "9200:9200" # Elasticsearch HTTP 포트를 호스트와 매핑
- "9300:9300" # Elasticsearch TCP 포트를 호스트와 매핑 (클러스터 통신용)
environment:
ES_JAVA_OPTS: "-Xmx256m -Xms256m" # Elasticsearch JVM 메모리 옵션 설정 (최대 256MB, 최소 256MB)
ELASTIC_PASSWORD: changeme # 기본 Elasticsearch 비밀번호 설정
# 단일 노드 모드로 설정하여 프로덕션 모드 비활성화 및 부트스트랩 검사 비활성화
discovery.type: single-node # 단일 노드 클러스터로 설정
networks:
- elk # 네트워크 설정
networks:
elk:
driver: bridge # 네트워크 드라이버로 브리지 사용
volumes:
elasticsearch: # Elasticsearch 데이터를 저장할 볼륨
Spring의 kafkaProducer
Spring의 API를 통해 episodes, stories와 관련된 생성, 수정, 삭제가 일어날 경우
Spring의 KafkaProducer를 통해 kafka의 특정 토픽에 해당 내용을 json직렬화 시켜서 업로드한다.
kafka producer configuration 빈 등록
@Configuration
public class KafkaProducerConfig {
@Value("${kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${kafka.key-serializer}")
private String keySerializer;
@Value("${kafka.value-serializer}")
private String valueSerializer;
@Bean
public KafkaProducer<String, String> kafkaProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializer);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializer);
return new KafkaProducer<>(props);
}
}빈으로 등록시킨 kafkaProducer를 사용하여 kafka 사용
@Service
@RequiredArgsConstructor
public class KafkaEpisodesProducerService {
private final KafkaProducer<String, String> producer;
private final JsonObjectMapper objectMapper;
private final KafkaMapper kafkaMapper;
@Value("${kafka.episodes-topic}")
private String episodesTopic;
public void sendCreate(Episode episode) {
KafkaEpisodeDto episodeDto = kafkaMapper.episodeToKafkaDto(episode, episode.getStory(), "create");
String jsonMessage = objectMapper.writeValueAsString(episodeDto);
ProducerRecord<String, String> record = new ProducerRecord<>(episodesTopic, jsonMessage);
producer.send(record);
}
public void sendUpdate(Episode episode) {
KafkaEpisodeDto episodeDto = kafkaMapper.episodeToKafkaDto(episode, episode.getStory(),"update");
String jsonMessage = objectMapper.writeValueAsString(episodeDto);
ProducerRecord<String, String> record = new ProducerRecord<>(episodesTopic, jsonMessage);
producer.send(record);
}
public void sendDelete(Long episodeId) {
String jsonMessage = objectMapper.writeValueAsString(Map.of("operation", "delete", "episodeId", episodeId));
ProducerRecord<String, String> record = new ProducerRecord<>(episodesTopic, jsonMessage);
producer.send(record);
}
}json직렬화 시킬때 operation이라는 키로 각각 어떤 상태로 kafka에 업로드 되는지 명시
create : es에 생성
update : es에 수정
delete : es에 삭제
Spring의 kafkaConsume
kafka의 특정 토픽을 구독하여 해당 토픽의 변화를 실시간으로 감지하여 작동하는 Consume
@Component
@RequiredArgsConstructor
public class KafkaConsumer {
private final JsonObjectMapper objectMapper;
private final EpisodesElasticSearchRepository episodeElasticSearchRepository;
private final UserElasticSearchRepository userElasticSearchRepository;
@KafkaListener(topics = "${kafka.episodes-topic}", groupId = "${kafka.consumer-group-id}")
public void episodeConsume(String message) {
Map<String, Object> data = objectMapper.readValue(message);
String operation = (String) data.get("operation");
if (operation.equals("delete")) {
Long episodeId = Long.parseLong(data.get("episodeId").toString());
episodeElasticSearchRepository.delete(episodeId);
}
if (operation.equals("update")){
episodeElasticSearchRepository.update(data);
}
}
@KafkaListener(topics = "${kafka.user-topic}", groupId = "${kafka.consumer-group-id}")
public void userConsume(String message) {
Map<String, Object> data = objectMapper.readValue(message);
String operation = (String) data.get("operation");
if (operation.equals("delete")) {
Long episodeId = Long.parseLong(data.get("userId").toString());
userElasticSearchRepository.delete(episodeId);
}
if (operation.equals("update")){
userElasticSearchRepository.update(data);
}
}
}kafka에 구독한 topics의 변화를 감지하고 해당 데이터를 읽어와서 operation를 기준으로
create를 제외한 나머지를 수행한다.(update, delete)
create를 따로 읽지 않는 이유
kafka의 connect에 elasticSearch Sink connect를 사용하여 connect를 등록할 경우
kafka 토픽에 들어어는 내용을 connect가 자동으로 elasticSearch의 업로드한다.
따로설정을 통해 수정, 삭제 또한 자동적으로 수행되게 할 수 있는 것으로 보이나 설정 이슈로 원하는 대로 작동하지 않아 consume을 통해 수정, 삭제를 따로 처리함
설정{ "name": "싱크 이름 자유롭게 설정 가능", // 싱크 커넥터의 이름을 설정하는 부분 "config": { "connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", //kafka에서 사용가능한 jar클래스 "tasks.max": "1", // 병렬 작업을 실행할 최대 태스크 수를 설정 (여기서는 1개로 설정) "topics": "topics", //구독할 토픽이름 "connection.url": "http://url", //연결할 elasticSearch url "connection.username": "아이디", //elasticSearch에 로그인이 필요할 경우 "connection.password": "비밀번호", ////elasticSearch에 로그인이 필요할 경우 "type.name": "_doc", // ElasticSearch에서 사용할 문서 타입, 기본적으로 "_doc"으로 설정 "key.ignore": "true", // Kafka 메시지의 key를 무시할지 여부를 설정 (true는 무시) "schema.ignore": "true", // 스키마 정보를 무시할지 여부를 설정 (true는 무시) "key.converter": "org.apache.kafka.connect.json.JsonConverter", // 메시지 key를 JSON 포맷으로 변환하는 컨버터 설정 "key.converter.schemas.enable": "false", // key 변환시 스키마 정보를 포함할지 여부 (false는 포함 안 함) "value.converter": "org.apache.kafka.connect.json.JsonConverter", // 메시지 value를 JSON 포맷으로 변환하는 컨버터 설정 "value.converter.schemas.enable": "false", // value 변환시 스키마 정보를 포함할지 여부 (false는 포함 안 함) "transforms": "unwrap", // Kafka 메시지를 처리할 때 특정 변환을 적용, 여기서는 "unwrap" 변환을 사용 "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", // unwrap 변환의 구체적인 타입으로, Kafka 메시지에서 새로운 레코드 상태만 추출하는 변환 "behavior.on.null.values": "delete", // Kafka 메시지의 값이 null일 때의 동작을 설정, "delete"는 해당 레코드를 ElasticSearch에서 삭제 "delete.enabled": "true" // delete 기능을 활성화할지 여부 (true는 활성화) } }
delete.enabled설정을 통해 삭제를 시도해 봤지만 kafka에 정확하게 null로 올라오는 것을 확인했지만 elasticSearch에서 원하는 대로 작동하지 않았음
위 설정을 통해 elasticSearch에 자동적으로 데이터를 업로드 시킴
elasticSearch 템플릿
kafka의 connect를 통해 elasticSearch에 데이터가 업로드 될때 kafka의 topic과 동일한 이름으로 인덱스가 생성되고 그 인덱스에 데이터가 올라가기 때문에 해당 인덱스의 템플릿을 만들어
원하는 방식으로 역인덱싱을 걸 수 있다.
{
"index_patterns": ["topic*"], // topic으로 시작되는 인덱스에 적용되는 템플릿
"template": {
"settings": {
"number_of_shards": 1, // 인덱스를 구성하는 샤드(분할)의 개수 (1개로 설정)
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram", // n-gram 기반의 토크나이저 설정
"min_gram": 2, // 최소 2글자부터 역인덱싱
"max_gram": 10, // 최대 10글자까지 역인덱싱
"token_chars": ["letter", "digit"] // 분석 시 처리할 문자 유형 (문자와 숫자)
}
},
"analyzer": {
"ngram_analyzer": {
"type": "custom", // 사용자 정의 분석기 설정
"tokenizer": "ngram_tokenizer", // n-gram 토크나이저 사용
"filter": ["lowercase"] // 모든 문자를 소문자로 변환하는 필터 적용
}
}
},
"index": {
"max_ngram_diff": 8 // n-gram의 최소값과 최대값 간의 차이를 제한 (여기서는 8로 설정)
}
},
"mappings": {
"properties": {
"episodeId": { "type": "long" }, // 에피소드 ID, long 타입
"episodeChapter": { "type": "long" }, // 에피소드 챕터, long 타입
"episodeTitle": {
"type": "text", // 에피소드 제목, 텍스트로 저장
"analyzer": "ngram_analyzer" // n-gram 분석기 사용
},
"episodeDescription": {
"type": "text", // 에피소드 설명, 텍스트로 저장
"analyzer": "ngram_analyzer" // n-gram 분석기 사용
},
"episodePublicDate": { "type": "date" }, // 에피소드 공개 날짜, date 타입
"episodeOnDisplay": { "type": "boolean" }, // 에피소드 표시 여부, boolean 타입
"storyId": { "type": "long" }, // 스토리 ID, long 타입
"storyTitle": {
"type": "text", // 스토리 제목, 텍스트로 저장
"analyzer": "ngram_analyzer" // n-gram 분석기 사용
},
"storyGenre": { "type": "keyword" }, // 스토리 장르, keyword 타입 (정확한 값 매칭에 사용)
"storyOnDisplay": { "type": "boolean" }, // 스토리 표시 여부, boolean 타입
"userId": { "type": "long" }, // 사용자 ID, long 타입
"penName": { "type": "keyword" }, // 필명, keyword 타입 (정확한 값 매칭에 사용)
"fieldImage": { "type": "keyword" } // 이미지 필드, keyword 타입 (정확한 값 매칭에 사용)
}
}
},
"priority": 1 // 템플릿의 우선 순위 설정 (숫자가 높을수록 우선 적용)
}위 템플릿 처럼 User 템플릿도 생성함
{
"index_patterns": ["topic"], // 'topic'이라는 이름의 인덱스에 적용되는 템플릿
"template": {
"settings": {
"number_of_shards": 1, // 인덱스의 샤드 수를 1개로 설정 (데이터를 저장할 물리적 분할)
"analysis": {
"tokenizer": {
"ngram_tokenizer": {
"type": "ngram", // n-gram 기반의 토크나이저 설정
"min_gram": 1, // 최소 1글자부터 인덱싱
"max_gram": 12, // 최대 12글자까지 인덱싱
"token_chars": ["letter", "digit"] // 분석 시 처리할 문자 유형 (문자와 숫자)
}
},
"analyzer": {
"ngram_analyzer": {
"type": "custom", // 사용자 정의 분석기 설정
"tokenizer": "ngram_tokenizer", // n-gram 토크나이저를 사용
"filter": ["lowercase"] // 문자를 소문자로 변환하는 필터 적용
}
}
},
"index": {
"max_ngram_diff": 11 // n-gram의 최소값과 최대값의 차이를 11로 제한
}
},
"mappings": {
"properties": {
"userId": { "type": "long" }, // 사용자 ID, long 타입
"penName": {
"type": "text", // 필명, 텍스트로 저장
"analyzer": "ngram_analyzer" // n-gram 분석기 사용
}
}
}
},
"priority": 1 // 템플릿의 우선 순위 설정 (숫자가 클수록 우선 적용)
}elasticSearch config생성 및 검색, 수정, 삭제
elasticSearch configuration 생성
@Configuration
public class ElasticSearchConfig {
@Value("${spring.elasticsearch.rest.uris}")
private String elasticsearchUris;
@Value("${spring.elasticsearch.rest.username}")
private String username;
@Value("${spring.elasticsearch.rest.password}")
private String password;
@Bean
public ElasticsearchClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(HttpHost.create(elasticsearchUris))
.setDefaultHeaders(new BasicHeader[]{
new BasicHeader("Authorization",
"Basic " + Base64.getEncoder().encodeToString((username + ":" + password).getBytes()))
});
RestClient restClient = builder.build();
RestClientTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
return new ElasticsearchClient(transport);
}
}elasticSearch 검색 및 쿼리(NativeQuery) 사용
@Repository
@RequiredArgsConstructor
public class EpisodesElasticSearchRepository {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
private final ElasticSearchMapper elasticSearchMapper;
private final ElasticSearchQuery elasticSearchQuery;
public List<ElasticSearchEpisodeDocument> searchEpisodesWithQueryBuilders(String filter, StoryGenreEnum genre, Pageable pageable) {
Query query = elasticSearchQuery.EpisodesAndStoriesQuery(filter, genre);
HighlightField episodeDescriptionField = elasticSearchQuery.episodeHighLightField("episodeDescription");
Highlight highlight = elasticSearchQuery.episodeHighLight(episodeDescriptionField);
HighlightQuery highlightQuery = elasticSearchQuery.episodeHighLightQuery(highlight);
NativeQuery searchQuery = elasticSearchQuery.episodeNativeQuery(query, highlightQuery, pageable);
SearchHits<ElasticSearchEpisodeDocument> searchHits = elasticsearchTemplate.search(searchQuery, ElasticSearchEpisodeDocument.class);
return elasticSearchMapper.HitsToEpisodeDocument(searchHits);
}
public void delete(Long episodeId) {
Query query = elasticSearchQuery.episodeIdQuery(episodeId);
NativeQuery searchQuery = elasticSearchQuery.onlyNativeQuery(query);
SearchHits<ElasticSearchEpisodeDocument> searchHits = elasticsearchTemplate.search(searchQuery, ElasticSearchEpisodeDocument.class);
searchHits.forEach(hit -> {elasticsearchTemplate.delete(hit.getId(), ElasticSearchEpisodeDocument.class);});
}
public void update(Map<String, Object> data) {
Long episodeId = Long.parseLong(data.get("episodeId").toString());
Query query = elasticSearchQuery.episodeIdQuery(episodeId);
NativeQuery searchQuery = elasticSearchQuery.onlyNativeQuery(query);
SearchHits<ElasticSearchEpisodeDocument> searchHits = elasticsearchTemplate.search(searchQuery, ElasticSearchEpisodeDocument.class);
searchHits.forEach(hit -> {elasticsearchTemplate.delete(hit.getId(), ElasticSearchEpisodeDocument.class);});
}
public void updateOnlyStory(Map<String, Object> data) {
Long storyId = Long.parseLong(data.get("storyId").toString());
Query query = elasticSearchQuery.storyIdQuery(storyId);
NativeQuery searchQuery = elasticSearchQuery.onlyNativeQuery(query);
SearchHits<ElasticSearchEpisodeDocument> searchHits = elasticsearchTemplate.search(searchQuery, ElasticSearchEpisodeDocument.class);
searchHits.forEach(hit -> {elasticsearchTemplate.delete(hit.getId(), ElasticSearchEpisodeDocument.class);});
}
public List<Long> searchAllEpisodeIdList() {
Query query = elasticSearchQuery.matchAllQuery();
NativeQuery searchQuery = elasticSearchQuery.onlyNativeQuery(query);
SearchHits<ElasticSearchUserDocument> searchHits = elasticsearchTemplate.search(searchQuery, ElasticSearchUserDocument.class);
return elasticSearchMapper.UserDocumentListToLong(elasticSearchMapper.HitsToUserDocument(searchHits));
}
}구체적인 NativeQuery
@Service
public class ElasticSearchQuery {
public Query EpisodesAndStoriesQuery(String filter, StoryGenreEnum genre) {
return QueryBuilders.bool(bool -> {
bool.must(QueryBuilders.multiMatch(multi -> multi
.query(filter)
.fields("episodeTitle", "episodeDescription", "storyTitle")
));
if (genre != null) {
bool.must(QueryBuilders.match(match -> match
.field("storyGenre")
.query(genre.name())
));
}
bool.must(QueryBuilders.match(multi -> multi
.query("true")
.field("episodeOnDisplay")
));
bool.must(QueryBuilders.match(multi -> multi
.query("true")
.field("storyOnDisplay")
));
return bool;
});
}
public Query penNameQuery(String filter) {
return QueryBuilders.bool(bool ->
bool.must(QueryBuilders.match(multi -> multi
.query(filter)
.field("penName")
))
);
}
public Query episodeIdQuery(Long filter) {
return QueryBuilders.term(t -> t
.field("episodeId")
.value(filter)
);
}
public Query storyIdQuery(Long filter) {
return QueryBuilders.term(t -> t
.field("storyId")
.value(filter)
);
}
public Query userIdQuery(Long filter) {
return QueryBuilders.term(t -> t
.field("userId")
.value(filter)
);
}
public Query matchAllQuery() {
return QueryBuilders.matchAll().build()._toQuery();
}
public NativeQuery episodeNativeQuery(Query query, HighlightQuery highlightQuery, Pageable pageable) {
SourceFilter sourceFilter = new CustomSourceFilter(
new String[] {"episodeDescription"}
);
return NativeQuery.builder()
.withQuery(query)
.withHighlightQuery(highlightQuery) // 하이라이트 쿼리 추가
.withPageable(pageable)
.withSourceFilter(sourceFilter)
.build();
}
public NativeQuery penNameNativeQuery(Query query, Pageable pageable) {
return NativeQuery.builder()
.withQuery(query)
.withPageable(pageable)
.build();
}
public NativeQuery onlyNativeQuery(Query query) {
return NativeQuery.builder()
.withQuery(query)
.build();
}
public HighlightField episodeHighLightField(String descriptionField) {
return new HighlightField(descriptionField,
HighlightFieldParameters.builder()
.withFragmentSize(80)
.withNoMatchSize(80)
.withNumberOfFragments(1)
.build());
}
public Highlight episodeHighLight(HighlightField highlightField) {
return new Highlight(
HighlightParameters.builder().build(),
List.of(highlightField)
);
}
public HighlightQuery episodeHighLightQuery(Highlight highlight) {
return new HighlightQuery(highlight, ElasticSearchEpisodeDocument.class);
}
}간단 정리
1. kafka, zookeeper, elasticSearch가 docker-compose를 통해 실행
2. spring의 producer, consume을 통해 kafka의 특정 토픽에 업로드, 구독 및 작업
3. kafka connect에 sink connect를 등록하여 kafka의 업로드 되는 데이터를 es에 자동적으로 업로드
4. elasticSearch Repository 등록
시도한 다른 방법
시도했던 방법 1
MYSQL의 LOG_BIN 기능을 통해 episodes 테이블을 감지하여 변하는 모든 데이터를 kafka를 통해 es에 반영하는 방식으로 시도함
문제점
episodes 테이블외의 데이터(storyTitle, storyId, userId....)를 kafka에 넘길 수 없음
transaction을 통해 episodes에 없는 컬럼을 남기려 시도해봤지만 log_bin에서는 episodes테이블외의 데이터를 감지하지 못함
수정, 삭제의 경우 kafka에는 제대로 넘어가지만 엘라스틱서치에서는 수정,삭제를 감지하지 못하고 스프링에서 직접 수정, 삭제를 해야함
시도했던 방법 2
MYSQL의 LOG_BIN 기능을 통해 episodes, story테이블을 감지하여 변하는 모든 데이터를 kafka를 통해 es에 반영하는 방식으로 시도함
문제점
테이블의 변화를 감지하고 넘기는 형식이라 episodes, stories 테이블의 데이터가 kafka에 넘어갈때 형태를 직접 성형하지 못함
(stories테이블은 stories형태 그대로, episodes는 episodes 테이블 형태 그대로 넘어감)
다른 형태의 데이터라도 스프링에서 받아 직접 성형하려 해도 중복, 서로 다른 개수 등으로 페이지네이션 기능을 구현하기 힘들어짐
