
https://book.naver.com/bookdb/book_detail.nhn?bid=16268369
으뜸 파이썬과 함께 공부하는 포스트입니다.
리스트 자료형의 필요성
리스트는 이미 앞장에서 간단히 보았다. 이제 자세히 알아볼 차례이다. 리스트 변수는 여러개의 값 또는 변수를 한꺼번에 담을 수 있다.
예를 들어 학생이 7명 있다고 하면 a,b,c,d,e,f,g와 같이 7개의 개별적 변수를 선언하려면 귀찮기 때문에 리스트를 활용하여 하나로 묶는 것이다.
a = 1 , b = 2, c = 3, d = 4, e = 5, f= 6, g = 7. 그냥 보기만 해도 번거롭다. 또한 이와 같은 개별변수들은 여러곳의 메모리에 분산되어 저장되므로 연속적으로 읽을 수 없어서 비효율적이다.
이때 개별적인 값을 하나의 변수에 담아서 처리하게 되면 매번 변수의 이름을 작성하고 관리하는 것보다 편리하고 효율적일 것이다.
리스트를 사용하면 이 변수들을 한 번에 묶어서 선언하는 것이 가능해진다. 리스트 내에서 쉼표로 구분된 자료 값을 리스트의 항목 혹은 요소라고 하는데 학생들의 점수를 score_list 라는 리스트로 선언하고 이 리스트에 [87, 84, 95......90] 과 같은 형식으로 점수 값을 저장하면 된다.
그리고 이 리스트는 첫번째 원소와 네번째 원소는 score_list[0], score_list[3]와 같이 인덱스를 이용하여 참조하면 된다.

위 코드에서 연속적인 값들은 score_list라는 변수와 인덱스를 통해서 참조하는 것이 가능하다.
리스트는 "대괄호 []" 내에 쉼표를 이용하여 값을 구분할 수 있다. 또한 '세 번째 변수'와 같이 위치를 지정해서 원하는 값을 불러오는 것도 가능하다. 다음의 실습을 해보자.

보다시피 instrument라는 리스트에는 문자열 네개를 한꺼번에 저장하고 출력하였다. 그리고 mixed_list에는 숫자와 문자를 동시에 저장하고 출력하는것이 가능하다는 것을 알 수 있다.
파이썬은 이와 같이 각각의 큰 괄호 내에 원소를 쉼표로 구분하여 입력하는 방법으로 리스트를 만들 수도 있지만, 앞서 살펴본 range()나 문자열을 이용하여 리스트를 만들 수도 있다. 또 실습을 해보자.

위 코드를 보면 리스트는 list 함수로 만들 수 있지만 빈 리스트는 변수에 대괄호만 할당해주는 것만으로도 만들 수도 있다. list3은 튜플 (1,2,3)으로부터 list() 함수를 이용하여 얻을수 있다.
그리고 range(1,10)이라는 함수를 통해 1부터 9까지 숫자의 열을 얻은 후 이 열을 원소로 가지는 리스트를 list() 함수를 통해 생성할 수 있다.
마지막 리스트 list5는 'ABCDEF'라는 문자열을 리스트로 변환하여 하나하나씩 쪼개어 요소로 하는 리스트를 생성했다.
문제 하나를 풀어보자.
LAB 5-1 리스트의 생성
1. 1부터 10까지 숫자 중에서 짝수를 요소로 가지는 even_list라는 리스트를 생성하여라.(10 포함) print() 함수를 사용하여 이 리스트를 출력하여라.

실행 결과
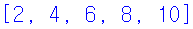
일단 even_list에 빈 리스트를 할당했다. 다음 for 문으로 1에서 10까지 반복하는 명령문을 적고, 내부에서 2로 나누었을 때 나머지가 없는, 즉, 짝수를 출력하는 명령을 하고나서, 그에 해당되는 수를 even_list에 append 메소드를 이용하여 집어 넣고, print() 함수로 출력하는 것으로 마무리 하였다.
리스트의 인덱스
리스트는 저장된 항목들 중 필요한 값을 추출하는 기능을 지원한다.
가장 일반적인 방법은 선언한 리스트 변수 이름 뒤에 대괄호 []를 사용하고 이 대괄호 사이에 숫자를 넣으면 해당하는 위치에 있는 항목 값을 가져올 수 있다.
이와 같이 리스트의 항목 값을 가리키는 숫자를 인덱스라 한다. 항목의 개수가 n개인 리스트의 인덱스는 0부터 n-1까지 증가한다.
그리고 이를 이용하여 자료값에 접근하는 것을 인덱싱이라 한다.
원소가 6개인 n_list라는 리스트를 통해 이를 알아보자.

len 함수로 크기를 반환할 수 있다. 차례대로 11, 22, 33, 44, 55, 66 값이 저장되어있으므로 len(n_list)는 6을 출력하게 된다.
리스트의 인덱스를 사용할 때 주의할 점은 인덱스 값을 최대 인덱스 값보다 더 큰 값을 넣으면 안된다는 것이다.
예를 들어 항목이 6개 들어있는 리스트 변수에 n_list[6]을 입력하면 n_list에 존재하지 않는 일곱번째 값에 접근하는 것이므로, 오류가 발생한다. 이에 대해 주의가 필요하다. 최대 인덱스는 len(n_list) - 1로 얻을 수 있다.

리스트 인덱싱의 큰 특징은 음수 인덱스를 사용할 수 있다는 점으로, C나 Java에서는 지원하지 않는다.

파이썬의 리스트는 음수 인덱스를 이용하여 원소들을 참조할 수 있는데 위와 같이 음수 인덱스 -1이 리스트의 제일 마지막 원소의 인덱스이며 -6은 리스트의 첫 원소의 인덱스이다.
즉, -1씩 감소하면서 앞 쪽 원소를 인덱싱하는 것을 알 수 있다. 리스트의 제일 마지막 원소의 항목은 [-1 + len(n_list)]와 같으며, 그 앞 항목은 [-2 + len(n_list)]과 같다. 그리고 첫 항목은 [-len(n_list) + len(n_list)]로 정수 인덱스 [0]과 같다.
LAB 5-2 리스트의 생성과 인덱싱
1. 2부터 10까지의 수중에서 소수를 원소로 가지는 prime_list라는 리스트를 생성해라. 그리고 이 리스트의 가정 첫 원소를 리스트 인덱싱을 이용하여 다음과 같이 출력하여라.
prime_list의 첫 원소 : 2

첫 원소는 그냥 출력하려면 0을 인덱싱, 음수로 인덱싱 하려면 -9를 입력해야 한다.
2. 'Korea', 'China', 'Russia', 'Malaysia' 를 원소로 가지는 nations라는 리스트를 생성하여라. 그리고 이 리스트의 가장 첫 원소를 print() 함수를 이용하여 출력하여라.

리스트 항목의 추가와 삭제
이미 생성된 리스트에 원하는 항목을 추가하는 것이 가능하며, 리스트내의 특정 항목을 지우는 것도 가능하다.
리스트 내에 원하는 항목을 추가하려면 append() 메소드를 사용한다. 이는 이미 존재하는 리스트의 끝에 새로운 항목을 삽입하는 기능을 한다. 실습을 해보자.

리스트 내의 항목을 지우는 방법은 3가지가 존재 하는데, 첫번째 방법은 파이썬의 키워드 del을 사용하는 것이다. del 뒤에 n_list[3]이라고 명시하면 리스트 내의 4번째 위치의 항목을 삭제할 수 있다.
두번째 방법은 리스트 클래스에 있는 remove() 라는 메소드를 사용하는 것이다. remove의 매개변수로 원하는 값을 넣어주면 매개변수와 같은 값을 가지는 항목이 지워진다.
세번째 방법은 pop() 메소드를 사용하는 방법인데 pop메소드는 리스트의 트정 위치에 있는 항목을 삭제함과 동시에 이 항목을 반환한다는 특징이 있다.

del을 이용한 인자 삭제 방법이다.
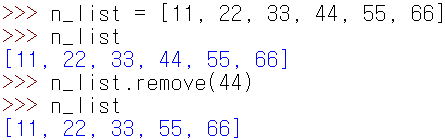
remove() 메소드를 이용한 인자 삭제 방법이다.
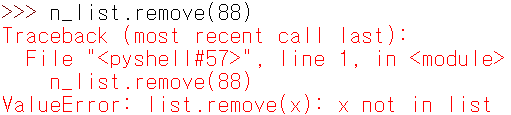
물론 없는 인자를 삭제하려고 입력하면 오류가 발생한다. 이러한 문제를 해결하기 위해 리스트의 멤버를 확인하는 등의 연산이 필요하다.
멤버 연산자 in, not in
파이썬은 리스트나 딕셔너리, 튜플, 집합, 문자열과 같이 여러개의 항목을 가지는 자료형을 제공하는데, 이 자료형 내에 특정 항목 값이 포함되어 있는가를 묻는 연산자를 멤버 연산자라고 한다. 이는 참이나 거짓을 반환하는 연산자이다. 실습을 해보자.

이렇게 존재 여부를 확인할 수 있다. 그렇다면 리스트가 존재하지 않는 원소를 삭제할 때 발생하는 오류를 막기 위해 이러한 멤버 연산자를 사용하는 방법을 알아보자.
우리는 어떤 리스트가 존재할 때 특정 원소가 그 리스트에 존재 존재하는지의 여부를 확인할 수 있는 방법을 알고 있다.

이제 이것을 이용하여 if 조건문과 함께 remove 메소드를 사용하면 보다 안전한 삭제가 가능하다.

프로그램을 보면 n_list 변수에 해당하는 값이 있는지 확인하기 위해 in 연산을 사용하고 반환하는 값을 if문의 조건식에 넣어서 True를 반환하면 삭제를 실행하고 아니면 실행하지 않도록 하였다.
이로써 해당 값이 존재하지 않아도 오류가 발생하지 않는 안전한 삭제 연산이 가능해졌다. 이렇게 코딩 시 발생 가능한 문제를 생각해보고 안전한 방식으로 코딩하는 습관을 들이도록 노력하자.
LAB 5-3 리스트의 삽입과 삭제, in 연산자
1. 1부터 10까지의 수 들 중에서 소수 원소를 가지는 prime_list라는 리스트를 생성하시오. 그리고 append() 메소드를 사용하여 11을 추가하시오. 이 때 추가 전과 추가 후의 결과를 출력하시오.

2. 'Korea', 'China', 'Russia', 'Malaysia' 라는 국가 이름을 원소로 가지는 nations라는 리스트에 append() 메소드를 사용하여 'Nepal'을 추가하시오. 이 때 추가 전과 추가 후의 결과를 출력하시오.

3. 앞 문제의 nations 라는 리스트에 'Japan'과 'Russia'가 있는지 없는지 검사하여 출력하시오. 존재 여부는 in 연산자, 출력시에는 if-else 조건문을 사용하시오.

실행 결과

리스트에 적용되는 내장함수
앞에서 min(), max(), sum() 같은 내장함수를 살펴보았는데, 이 함수들의 인자로 리스트를 넘겨주면 각각 리스트 안에서 최솟값, 최댓값, 합을 구할 수 있다.

이렇게 리스트의 원소가 숫자가 아닌 문자열이 들어있는 리스트 변수에도 min(), max() 함수는 잘 작동되며, min()은 영어의 경우 사전 순서로 가장 앞에 나오는 단어, max()는 사전 순서로 가장 뒤에 나타나는 단어나 문자를 구한다. sum() 함수는 문자열에 대해 작동하지 않는다.

영어 뿐만 아니라 한글 문자열을 요소로 가져도 잘 작동한다.

리스트의 메소드
리스트의 메소드에 대해 알아보자. 리스트 클래스는 다양하고 편리하게 이용 할 수 있는 메소드를 제공하고 있는데 그중에서 가장 많이 사용되는 것이 정렬 메소드인 sort()이다.
이 메소드는 리스트 변수 뒤에 마침표와 sort()를 적어주면 다음과 같이 항목들을 오름차순과 내림차순으로 정렬이 가능해진다. 이 때, 리스트 변수 list1의 메소드 sort()를 호출하면 변수 안의 항목들을 [10, 20, 30, 40, 50]과 같이 증가하게 된다.
이와 같이 값이 증가하는 정렬을 오름차순 정렬이라 하면 값이 감소하는 정렬을 내림차순 정렬이라 한다. sort() 메소드는 디폴트로 오름차순, 키워드 인자 reverse를 True로 설정하면 내림차순을 수행한다.

정렬뿐만 아니라 리스트는 다양한 메소드를 제공하여 개발시에 편리하게 이용 가능하다.

위 메소드를 하나씩 다 써보자.
index
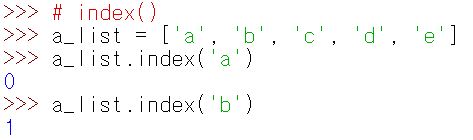
인자의 위치를 반환한다.
count
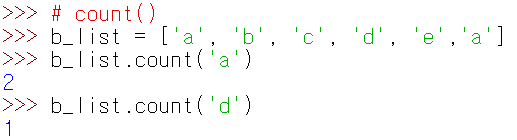
인자의 개수를 구할 수 있다.
extend

리스트 두개를 가지고 둘 중 하나의 리스트에 다 넣을 수도 있고, 따로 하나만 추가 할 수도 있다.
insert

넣을 인자의 위치를 정해주고, 넣을 인자를 입력하는 것으로 사용할 수 있다.
remove

앞에서 했듯이 인자를 삭제하는 함수이다.
pop

pop() 을 쓰고 괄호안에 아무것도 쓰지 않으면 맨 뒤의 인자가 삭제되어 반환되고, 아니면 삭제할 인자의 위치를 입력하는 것으로써 삭제할 수 있다. remove() 메소드와 비슷하지만 remove()는 삭제만 하고 반환은 하지 않는다.
reverse

순서만 재배열 할 뿐 내림차순 정렬을 하지는 않는다.
LAB 5-5 리스트 메소드의 활용
1. a 리스트의 원소 값이 [1,2,3]이고 b 리스트의 원소 값이 [10, 20, 30]이다. a 리스트에 append(b) 메소드와 extend(b) 메소드를 각각 호출할 때 어떤 결과가 나타날지 프로그램 해보시오.
(1)

(2)
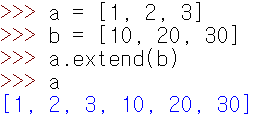
보다시피 append(b)를 하면 리스트가 통째로 a 리스트에 추가된다. 반면 extend(b)를 이용하면 인자만 옮겨지는 것을 볼 수 있다. 헷갈리지 않도록 유의하도록 하자.
2. insert() 메소드를 사용하여 nlist의 제일 앞에 0을 삽입하여 다음과 같이 출력하여라.
nlist = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
insert 함수는 앞에서 설명했듯이 인자를 넣을 위치를 설정하고 인자를 입력하는 것으로 사용한다.
리스트와 연산
두 리스트 사이에는 더하기 연산자를 사용할 수 있다. 그런 빼기 연산자나 곱하기, 나누기는 하지 못한다.
list1 리스트에 list2 리스트를 더하기 연산자를 사용해 더하면 두 리스트 list1의 항목에 list2 항목을 추가하게 된다.
그러나 이 결과를 다른 리스트에 할당을 하지 않으면 list1은 상태변화가 없다.

프로그램 수행 결과로 두 리스트가 하나로 되고, 할당연산자를 통하여 list3에 할당하였다. 다음은 곱셈 연산을 해보자.

곱하기 2를 하면 리스트의 인자가 두번씩 나오고 3을 곱하면 3번씩 반환한다. 그러나 다음 프로그램은 오류를 발생시킨다.

리스트 끼리는 곱셈을 하지 못한다는 뜻이다. 이제 비교 연산을 해보자.

비교 연산은 == 연산자로 할 수 있다. 인자도 같고 인자의 순서도 같은 list1과 list2를 비교하면 True라고 나오지만, list3은 다른 순서로 나열했기 때문에 False를 반환한다. 즉, 순서와 인자 모두 같아야 True를 반환한다는 것을 알 수 있다.
이 비교연산자로 크기 비교도 할 수 있다.

크기 비교 연산은 정수나 실수 값의 경우 나타나는 순서대로 하나하나 비교하여 먼저 큰 값이 나타나는 리스트가 더 큰 값이 되며, 문자열의 경우 사전적 순서를 비교한다.
위 프로그램은 1,2,3,4 와 2,3,3,4 이기 때문에, list1이 사전적 순서에 의해 먼저 나타난다. 따라서 list1 > list는 거짓, list1 < list2는 참이다.
리스트 내용 갱신을 위한 방법
3장에서 for문을 통해 리스트의 항목을 하나하나씩 나열, 혹은 연산하는 기능을 보았다. 이제 10, 20, 30, 40, 50의 원소를 가지는 리스트가 있을 때, 모든 원소에 10을 곱한 값인 100, 200, 300, 400, 500의 원소를 가지는 리스트를 만들어 보자.
파이썬의 장점 중 하나는 동일한 기능을 수행하는 코드를 매우 다양한 방법으로 만들 수 있다는 것이다.

실행 결과
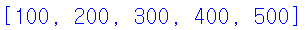
위 코드가 상대적으로 복잡하게 느껴졌다면 더 간단한 방법도 있다. 이 방법은 리스트의 축약 표현이라고 하는데, 대괄호 내에 있는 코드 for n in list1을 이용하여 list1의 모든 원소를 방문하여 n * 10 연산을 적용한 새로운 리스트를 얻을 수 있다.
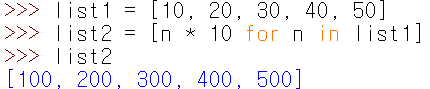
다음 방법은 map() 함수를 이용하여 리스트의 모든 원소에 대해 지정된 함수를 사상시키는 방법으로 이 예제에서는 lambda() 함수를 사용하였다.

리스트의 슬라이싱
리스트의 슬라이싱은 파이썬의 강력하고 편리한 기능 중 하나이다. 슬라이싱을 사용하면 리스트 내의 항목을 특정한 구간별로 선택하여 잘라낼 수 있다.
이를 사용하면 리스트 내의 항목을 특정한 구간별로 선택하여 잘라낼 수 있다. [1:5]와 같이 시작 인덱스와 끝 인덱스를 명시하여 새로운 리스트를 얻는 것이 바로 슬라이싱이다.
이 때 구간을 명시하기 위해 리스트 [start : end] 와 같은 문법을 사용하는데 end-1까지의 항목을 새 리스트에 삽입한다.

위에서부터 보자면 1은 시작 인덱스, 5는 끝 인덱스인데, 끝 인덱스에서 1을 뺀 인덱스까지만 포함하여 반환한다.
그리고 [1:]는 1에서부터 끝 인덱스까지, [:5]는 처음부터 5-1 = 4 까지의 인덱스만 반환한다는 뜻이다.
이 뿐만 아니라 [::2] 와 같은 문법도 있다. 이는 처음부터 끝까지 2씩 건너뛰어서 반환한다.
LAB 5-7 리스트의 슬라이싱
1. range(15) 함수를 사용하여 다음과 같은 리스트를 생성하여라.
n_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]

- 문제 1번을 슬라이싱 해보아라.


