react query와 react-infinite-scroller 라이브러리로 커서 페이지네이션 api 목록 무한 스크롤 조회를 구현하게 되었다.
목록을 스크롤로 내려 조회해오고 목록에 데이터를 추가한다던가 하는 것들은 잘 동작했는데
목록에서 데이터를 지울 때 문제가 발생했고 온갖 추측, 구글링, 소스코드 확인 등을 통해 해결했던 과정을 기록했다.
문제상황
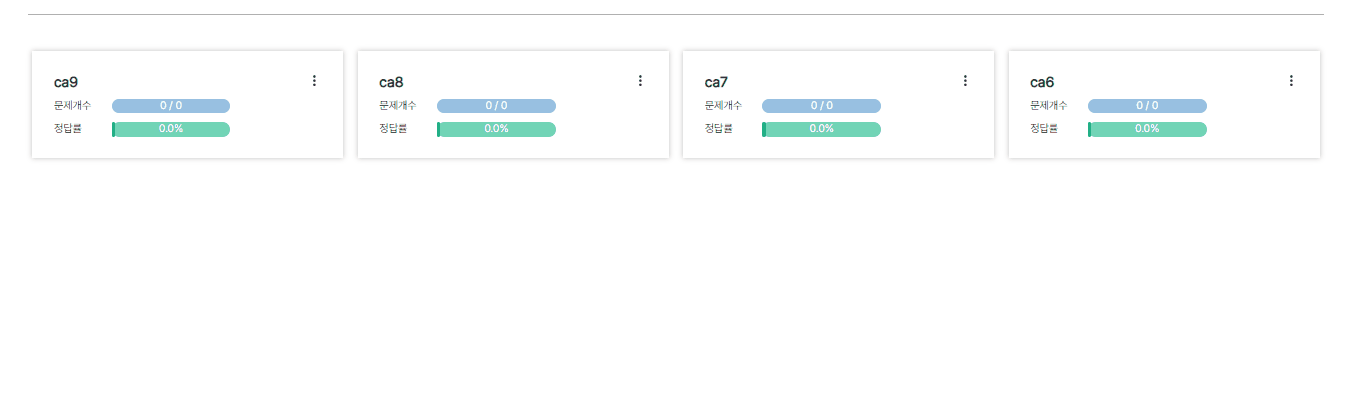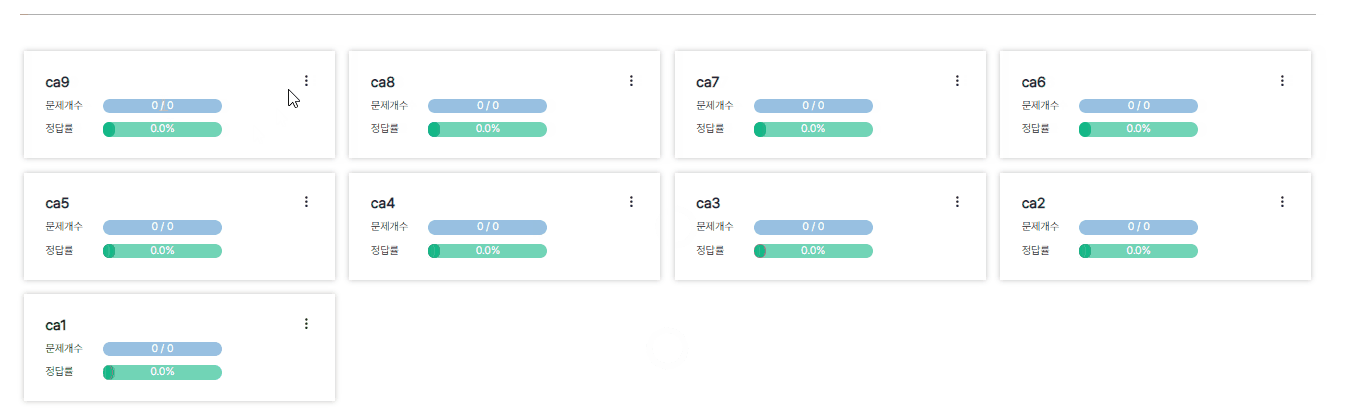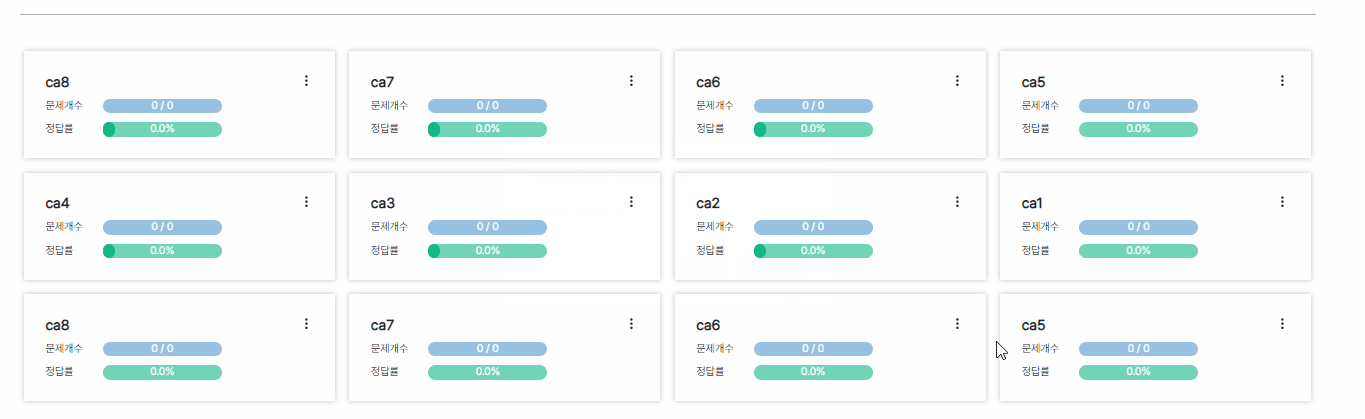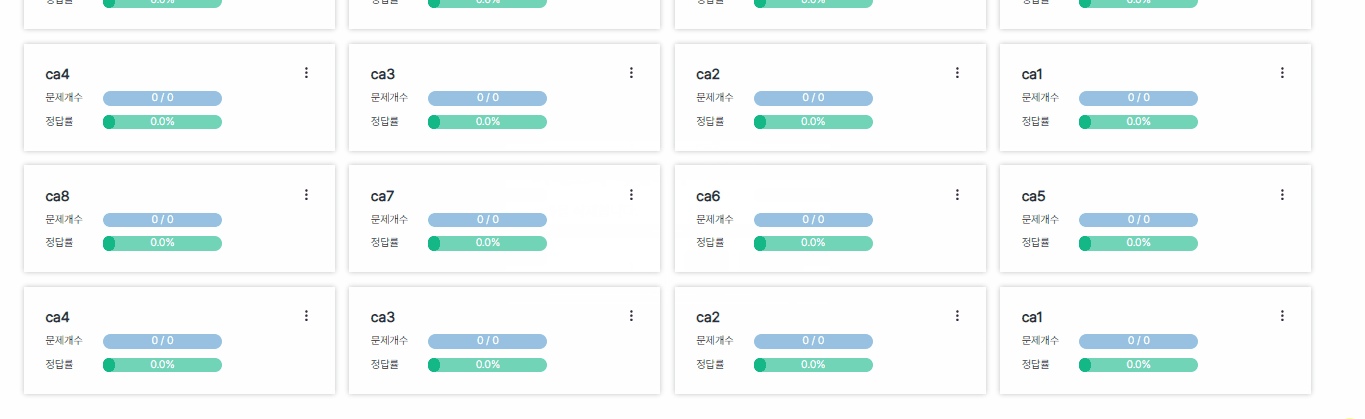
pageSize를 4로 두고 4개씩 데이터를 끊어서 가져오게끔 구현했는데 삭제했을 때 목록 개수가 pageSize로 딱 맞아떨어지면
기존 캐시된 데이터를 덮어씌워야하는데 그 밑에 새로운 데이터로 중복하여 목록을 구성하는 문제가 생겼다.
useMutation으로 요소 하나를 삭제했을 때 해당 쿼리를 무효화하게끔 해두었다.
const useCategoryDelete = () => {
const queryClient = useQueryClient();
const { mutate: deleteCategory } = useMutation(categoryApi.deleteCategory, {
onSuccess: () => {
queryClient.invalidateQueries([queryKey.categories, 'me']);
alertToast('삭제 완료', 'success');
},
});
return { deleteCategory };
};
export default useCategoryDelete;
이렇게 pageSize가 맞아 떨어지지 않을 때는 쿼리를 invalidate 해도 문제없이 동작하는데 말이다..
원인을 생각해보자
추측하기
확실한 것은 쿼리를 invalidate 해서 쿼리무효화를 통해 useInfiniteQuery를 사용해 다시 패치할 때 발생한 문제였다.
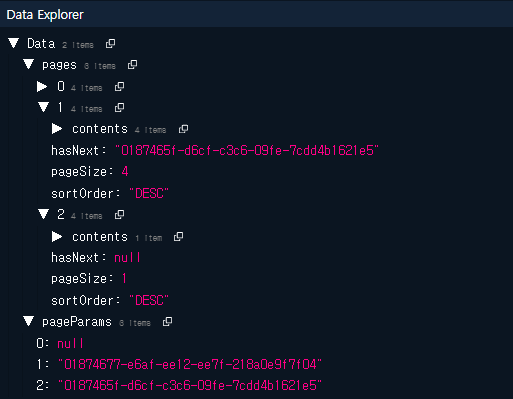
삭제 동작으로 pageSize에 맞아떨어지게 될 경우 pages와 pageParams배열의 길이자체가 달라지는데 이 때 발생한 문제일 것이다.
추측으로 데이터가 5개 존재할 경우 [hasNext: someId, hasNext: null] 이었던 것이 [hasNext: null] 로 변경되면서 발생한 문제가 아닐까 생각했다.
응아니였다
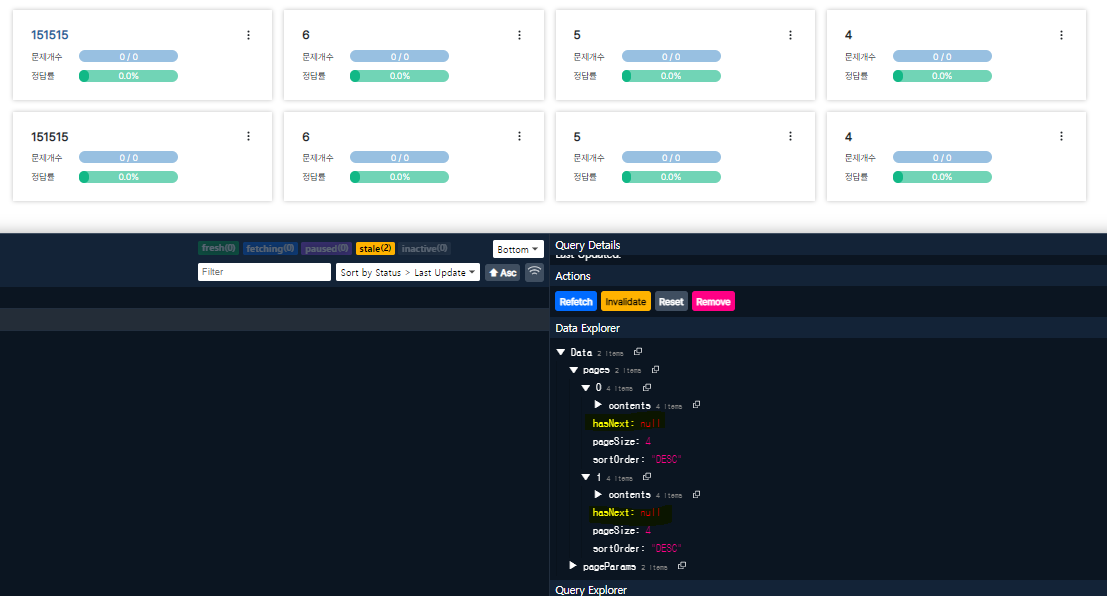
쿼리 무효로 다시 패치하고 기존 캐시된 데이터를 패치한 결과로 업데이트 해주었고
그 밑에 똑같은 데이터가 또 패치되어 목록을 구성하고 있었다..

기존 캐시된 쿼리와의 스냅샷과 뭔가 다른점이 있어 한 번더 패치를 해와 구성하는 것 같은데... 도저히 원인을 파악할 수 없었다..
쉽게 해결하는 방법: Optimistic Update
사실 리액트쿼리에서 추구하는 낙관적 업데이트를 말하기보다는 업데이트 된 척이라고 할 수 있는 해결방법이다.
const useCategoryDelete = () => {
const queryClient = useQueryClient();
const { mutate: deleteCategory } = useMutation(categoryApi.deleteCategory, {
onMutate: async (variables) => {
await queryClient.cancelQueries({ queryKey: [queryKey.categories, 'me'] });
const previousData: InfiniteData<CategoriesResponse> | undefined = queryClient.getQueryData([
queryKey.categories,
'me',
]);
// if(previousData) {
// queryClient.setQueryData(키, 삭제 된 후의 결과);
// }
return { previousData };
},
onError: (err, _, context) => {
queryClient.setQueryData([queryKey.categories, 'me'], context?.previousData);
},
onSettled: () => {
// 이걸 안해버린다면??
// queryClient.invalidateQueries([queryKey.categories, 'me']);
},
onSuccess: () => {
alertToast('삭제 완료', 'success');
},
});위의 코드는 공식문서에도 예시로 나와있는 낙관적 업데이트 코드와 별 다르지 않다. onSettled의 주석만 해제한다면..
이렇게 쿼리 무효화를 하지않고 직접 쿼리에서 삭제된 데이터를 제외시켜줄 수 있다. 그럼 사실 데이터 중복 문제는 발생하지 않을 것이라고 생각한다.
하지만 두가지 이유로 이 방법을 적용하지 않기로 하였다.
(1) react-query에서 optimistic update는 UX목적(업데이트 수행 중에도 사전에 결과를 보여주는)으로 사용될 뿐이며 업데이트 시 무효화가 권장된다.
그렇게 하기를 예전 버전 문서에서는 권장했었다.
업데이트 성공까지 기다리지 않고도 미리 성공 결과를 보여주고 실패했을 경우 롤백하는 방식으로 사용자의 기다림을 없애는 것이다.
현재버전(v4)의 경우 mutation시 setQueryData를 활용해 네트워크 호출을 줄이고 즉시 업데이트할 수 있다고 문서에 예제가 기재되어있어서 비권장되는지는 의문이지만 tanstack query이전 버전을 공부할 때는 그렇게 알고 있었고 유데미에서도 그렇게 배웠었다!
21년도 포스트지만 리액트 쿼리 개발자의 블로그에서 문서의 예제와 함께 본인의 의견을 확인할 수 있었다.
Direct updates
Sometimes, you don't want to refetch data, especially if the mutation already returns everything you need to know. If you have a mutation that updates the title of your blog post, and the backend returns the complete blog post as a response, you can update the query cache directly via setQueryData
I personally think that most of the time, invalidation should be preferred. Of course, it depends on the use-case, but for direct updates to work reliably, you need more code on the frontend, and to some extent duplicate logic from the backend. Sorted lists are for example pretty hard to update directly, as the position of my entry could've potentially changed because of the update. Invalidating the whole list is the "safer" approach.
때에 따라 다르나 안정성이나 구현 복잡도를 이유로 쿼리 무효화를 권장한다고 한다.
사실 위의 인용구와 어느정도 일치하는 내용이 두번째 이유다.
(2) 개발이 어렵다
쿼리 무효화 없이 명시적으로 업데이트 하는 로직이 매우 복잡하다.
사실 닉네임을 수정한다던가 그런 너무 결과가 명확하고 간단한 부분에 대해서는 명시적으로 업데이트해버리고 굳이 api를 재호출 하지 않아도 된다고 생각했었다. 유데미 선생님이 너무 강경 무효화파여서 배울 때 당시 혼란스러웠었지만 개발하신 분의 의견을 듣고 편안해졌다
하지만 이런 무한스크롤 데이터의 경우 리액트 쿼리로 구현을 해 적용하는 것 자체는 쉽지만 내부적으로 관리되는 데이터가 꽤 복잡하다.
상황에 맞춰 삭제를 예로 들면 삭제되는 아이디를 모든 page를 돌며 찾은다음 지워야 하며 그로인해 발생하는 사이드 이펙트도 모두 처리해야 한다.
pageSize에 맞게 데이터를 당겨오고 커서인 nextPage에 담길 정보를 바꾸고 pageParams를 수정하는 등등..
처리하는 구현 자체가 매우 복잡하고 다른 곳에서 해당 데이터 사용이 될 때 안정성도 보장할 수 없게 되며 유지보수도 안좋아지기 때문에 사용하고 싶지 않았다.
코드만 봐서는 찾을 수 없어서 서치하다보니 tanstack query 깃헙레포 이슈에 나와 같은 상황을 겪었던 사람이 있었다!
해결책은 쉽지만 이유를 찾기는 어려웠다!
getNextPageParam으로 얻는 다음 페이지 정보가 null이었던 것이 문제였다.
getNextPageParam의 결과는 다음페이지를 위한 pageParam으로 사용되며 해당 결과에 따라 hasNextPage 상태가 갱신된다.
백엔드에서 더 이상 데이터가 없을 경우 hasNext 데이터를 null로 보내주는데 이를 그대로 pageParam로 사용하여서 발생했던 문제였다.
const {
data: categoires,
isLoading,
isError,
hasNextPage,
fetchNextPage,
} = useInfiniteQuery(
[queryKey.categories, 'me'],
({ pageParam }) => {
const props = {
hasNext: pageParam,
};
!pageParam && delete props.hasNext;
return categoryApi.getMyCategoryList(props);
},
{
enabled: hasAuth,
getNextPageParam: (lastPage) => lastPage.hasNext, // 다음 데이터가 없을 경우 null
},
);이게 왜 문제?
null도 알아서 다음 페이지가 없다는 것으로 인식하지 않을까? 라고 생각했다.
Now I think we need to 1) make this maybe more prominent in the docs and 2) I think it's weird that the infinite query even stops fetching initially if we return null... also, hasNextPage returns false if we return null / undefined or false, which is definitely inconsistent
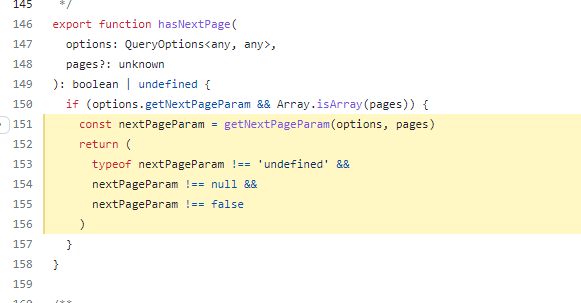
hasNextPage 상태의 경우 getNextPageParam의 결과가 null이어도 없음이 보장된다고 하며 실제 코드도 그렇고
삽질하며 확인했을 때도 그랬다. 그러니 null일 때도 조회할 때는 더 이상 다음데이터가 패치 되지 않았을 것이다.
해결책은 해당 이슈에 있었고 tanstack query 공식문서에서도 확인할 수 있었다.
getNextPageParam: (lastPage) => lastPage.nextPage ?? undefined
로 명확하게 체크하여 사용하라고 이슈 답변자(아까 그 블로그 주인)가 언급했다.
그런데 또 공식문서의 infiniteQuery 부분을 보면 다음과 같이 작성되어있었다.

실제로 hasNextPage는 null이어도 false로 동작했었는데 참 혼란스럽던 와중 깃허브 소스코드를 보다가 왜 undefined를 명시하라는지 절반정도 확신할 수 있었다.
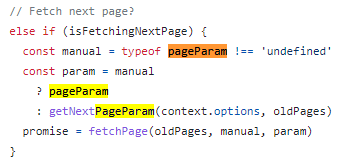
useInfiniteQuery실제 내부 구현부 코드인데 pageParam이 undefined일 경우만 체크하고 있었다.
내부적으로 무한스크롤 쿼리가 무효화 될 경우 fetchNextPage를 호출해 업데이트하게 된다.
어차피 실제로 서버 api를 호출할 때는 null또는 undefined일 경우 페이지정보를 보내지 않았었기에 티가 안났지만
내부적으로 쿼리 무효화로 인해 스크롤 데이터들을 패치해올 때 null이라는 새로운 페이지 파라미터를 사용해 새로운 무한스크롤 페이징 데이터로서 구성시켰을 것이다!
해결하기
getNextPageParam: (lastPage) => lastPage.hasNext ?? undefined,엄청 크나큰 문제마냥 몇 시간 삽질했지만 결국 10글자도 안되는 저게 해결책이었다.
결론
infiniteQuery 사용 시 다음 페이지가 없다면 명확하게 undefined 를 명시하자
