🙏내용에 대한 피드백은 언제나 환영입니다!!🙏
N+1 문제를 다시 공부하던 중, fetch join에 대한 페이징 처리에 대해 다시 알아보고자 하였다.
이 전에 연관관계(Mapping) - N+1문제라는 글을 정리하여 쓴 적이 있다.
여기에서 fetch join과 페이징을 함께 처리하는 경우, 어떻게 처리가 되는지 자세히 알아보려고 한다.
🧐 fetch join && 페이징 테스트 코드 쿼리
List<Post> posts = jpaQueryFactory
.select(post)
.from(post)
.join(post.writer, member).fetchJoin()
.leftJoin(post.likes).fetchJoin()
.where(category.name.eq(categoryName))
.orderBy(post.id.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();쿼리DSL을 통해서 위와 같이 fetchJoin()과 offset, limit를 처리해보았다.
실행한 결과, 쿼리는 아래와 같다.
Hibernate:
select
.
.
.
from
Post p1_0
join
Member w1_0
on w1_0.id=p1_0.writer_id
left join
Likes l1_0
on p1_0.id=l1_0.post_id
join
Category c1_0
on c1_0.id=p1_0.category_id
where
c1_0.name=?
order by
p1_0.id desc여기서 주목할 점은 limit표시가 없는 것이다.
즉, 페이징 처리가 적용이 되지 않고, Hibernate에 모든 데이터를 불러오는 것이다.
모두 불러온다❓
만약 하나의 Post(id = 1)에 3개의 Like(id = 1, 2, 3)가 있다면,
Post와 Like에 fetch join을 하게 된다면
1 1 (각각 Post, Like id)
1 2
1 3
이렇게 중복된 값을 들고온다. 또한 페이징처리가 되지 않았기에, 모든 데이터를 들고온다.
⚙️ 동작 방식
동작 방식을 확인하기 위해
package org.hibernate.sql.results.spi.ListResultsConsumer 코드를 찾아 보았다.
public List<R> consume(JdbcValues jdbcValues, SharedSessionContractImplementor session, JdbcValuesSourceProcessingOptions processingOptions, JdbcValuesSourceProcessingStateStandardImpl jdbcValuesSourceProcessingState, RowProcessingStateStandardImpl rowProcessingState, RowReader<R> rowReader) {
// 조회를 시작하기 전에 세션 초기화 및 준비 작업
.
.
.
try {
// 결과 데이터를 어떻게 저장하고 처리할지를 결정하는 로직
JavaType<R> domainResultJavaType = this.resolveDomainResultJavaType(rowReader.getDomainResultResultJavaType(), rowReader.getResultJavaTypes(), typeConfiguration);
boolean isEntityResultType = domainResultJavaType instanceof EntityJavaType;
Object results;
if (!isEntityResultType || this.uniqueSemantic != ListResultsConsumer.UniqueSemantic.ALLOW && this.uniqueSemantic != ListResultsConsumer.UniqueSemantic.FILTER) {
results = new Results(domainResultJavaType);
} else {
results = new EntityResult(domainResultJavaType);
}
// 조회한 결과를 순차적으로 읽고 처리하는 로직
// 이 구간이 중요한 구간.
(1)
int readRows = 0;
if (this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.FILTER || this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.ASSERT && rowProcessingState.hasCollectionInitializers() || this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.ALLOW && isEntityResultType) {
while(rowProcessingState.next()) {
((Results)results).addUnique(rowReader.readRow(rowProcessingState, processingOptions));
rowProcessingState.finishRowProcessing();
++readRows;
}
}
else if (this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.ASSERT) {
while(rowProcessingState.next()) {
if (!((Results)results).addUnique(rowReader.readRow(rowProcessingState, processingOptions))) {
throw new HibernateException(String.format(Locale.ROOT, "Duplicate row was found and `%s` was specified", ListResultsConsumer.UniqueSemantic.ASSERT));
}
rowProcessingState.finishRowProcessing();
++readRows;
}
} else {
while(rowProcessingState.next()) {
((Results)results).add(rowReader.readRow(rowProcessingState, processingOptions));
rowProcessingState.finishRowProcessing();
++readRows;
}
}
// 아래는 데이터베이스 조회 결과를 가져와 반환 가능한 형태로 가공하는 부분
.
.
.
}
/* 데이터의 고유성 확인을 위한 class. 데이터 중복을 처리 */
private static class EntityResult<R> extends Results<R> {
private static final Object DUMP_VALUE = new Object();
private final IdentityHashMap<R, Object> added = new IdentityHashMap();
public EntityResult(JavaType<R> resultJavaType) {
super(resultJavaType);
}
(2) 중복된 row를 처리하는 로직
public boolean addUnique(R result) {
if (this.added.put(result, DUMP_VALUE) == null) {
super.add(result);
return true;
} else {
return false;
}
}
}ListResultsConsumer에서 일부 로직을 들고왔다.
이 부분으로 fetch join이 어떻게 동작을 하는지 확인할 수 있다.
👉 조회 로직
먼저, 결과 데이터를 어떻게 저장하고 처리할지를 결정하는 로직한다.
그 다음으로, 위 코드에서 (1)표시를 해놓은 아래의 코드로 이동한다.
(1)
int readRows = 0;
if (this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.FILTER || this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.ASSERT && rowProcessingState.hasCollectionInitializers() || this.uniqueSemantic == ListResultsConsumer.UniqueSemantic.ALLOW && isEntityResultType) {
while(rowProcessingState.next()) {
((Results)results).addUnique(rowReader.readRow(rowProcessingState, processingOptions));
rowProcessingState.finishRowProcessing();
++readRows;
}
}이 로직을 실행하는 이유는 컬렉션 초기화가 필요한지 확인하는 rowProcessingState.hasCollectionInitializers()가 true이기 때문이다.
그 이유는, @OneToMany 관계에서 자식 클래스에 대한 컬렉션 필드가 있을 수 있다.
예시를 들자면 아래와 같은 코드이다.
@Entity
public class Post {
@Id
private Long id;
private String title;
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Like> likes = new ArrayList<>();
}
이런 상황에서 Post 엔티티는 likes라는 컬렉션을 포함하고 있다.
그래서 rowProcessingState.hasCollectionInitializers()가 true여서 (1)부분을 실행하게 되는 것이다.
👉 중복된 데이터 제거 로직 (distinct)
동작 로직에서
((Results)results).addUnique(rowReader.readRow(rowProcessingState, processingOptions));와 같은 로직이 있다.
이것이 바로 위에 적어둔 (2)부분이다.
private final IdentityHashMap<R, Object> added = new IdentityHashMap();
(2) 중복된 row를 처리하는 로직
public boolean addUnique(R result) {
if (this.added.put(result, DUMP_VALUE) == null) {
super.add(result);
return true;
} else {
return false;
}
}addUnique메서드를 통해서 added라는 HashMap에 중복된 값을 제외한 값들이 있는지 확인하고, 값을 처리한다.
이렇게, 전체 데이터를 불러왔을 때, 중복된 값이 있다면 그것을 distinct하는 역할을 하는 것이다.
👉 fetch join쿼리에서 limit은?
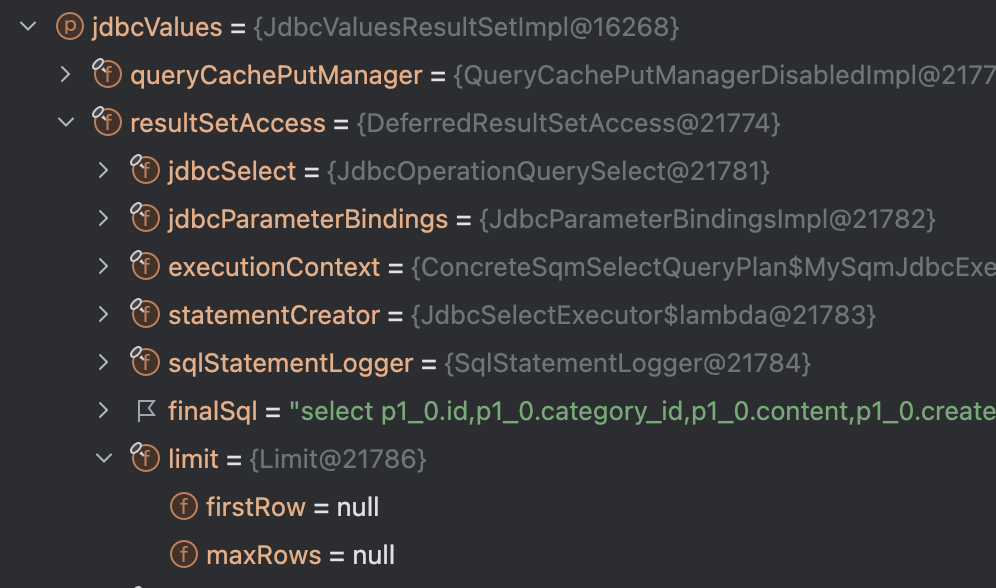
위 사진에서 limit 안에 보면 firstRow, maxRows가 모두 null이 되어 있는 것을 볼 수 있다.
즉, offset, limit가 처리되고 있지 않는 것이다.
그 이유는 아래와 같다.
-
JPA에서 @ToMany 관계에 대해 Paging + fetch join을 수행할 때,
-
One Entity 기준으로 Many Entity에 대한 데이터를 join하게 되어 데이터의 수가 변한다.
-
따라서 JPA는 어떤 데이터를 기준으로 Paging을 수행해야 하는 지 알 수 없게 된다.
또한, 공식 문서에 아래와 같이 적혀 있다.
Fetch should be used together with setMaxResults()or setFirstResult() , as these operations are based on the result rows which usually contain duplicates for eager collection fetching, hence, the number of rows is not what you would expect.
번역: Fetch는 일반적으로 setMaxResults()나 setFirstResult()와 함께 사용되어야 합니다. 왜냐하면 이러한 작업은 즉시 로딩(컬렉션 페치)을 사용할 때, 중복된 결과 행을 포함할 수 있기 때문입니다. 따라서 결과 행의 수가 예상과 다를 수 있습니다.
정확한 의미는, 페이징(setMaxResults()나 setFirstResult())이 적용된 Fetch Join은 중복된 결과를 가져올 수 있기 때문에 주의해야 한다. 인 것 같다. 처음에 무슨 말인지 몰랐다..
📄 내용 정리
그래서, 전하고 싶은게 무엇이냐?
-
fetch join 쿼리에 페이징 처리를 한다고 하더라도, limit를 포함하지 않아 DB에서 페이징 처리를 하지 않는다.
-
1과 같은 이유로, fetch join을 사용하면 하이버네이트에 모든 데이터를 load한다.
-
하이버네이트에서 중복된 데이터 (pk가 같은 값)을 제거한다.
-
남은 row를 통해 페이징을 진행한다.
결국에는 페이징 처리를 해주니깐 써도 될까?
정답은 아니다. (데이터의 양이 적다면 써도 괜찮다고 생각한다)
만약, fetch join + Paging를 사용한다면 아래와 같은 경고 문구가 뜬다.
WARN [org.hibernate.query.sqm.internal.QuerySqmImpl.executionContextForDoList:544] - HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
이것은 메모리에 모든 데이터를 올리기 때문에 발생하는 문제이다.
만약 대량의 데이터를 다루게 된다면, 서버에 부하가 많이 걸릴 것이다.
해결 방법은 연관관계(Mapping) - N+1문제을 참고해주길 바란다.
💡 느낀점
이번에 fetch join과 페이징 처리의 관계를 다시 깊이 있게 공부하면서, Hibernate의 내부 동작 방식에 대해 좀 더 이해하게 되었다. 특히 @OneToMany나 @ManyToMany와 같은 다대일 관계에서 fetch join을 사용할 때 페이징 처리가 어떻게 작동하는지를 분석할 수 있었다. 이를 통해 ORM 툴이 내부적으로 중복 데이터를 제거하고 메모리에서 페이징을 처리하는 방식을 알게 되었다.
또한, 단순히 동작 여부만 확인하는 것이 아니라, 라이브러리의 내부 구조와 동작 방식을 깊이 있게 이해하는 것이 얼마나 중요한지 다시 느꼈다.
