🙏내용에 대한 피드백은 언제나 환영입니다!!🙏
PC 성능
- Apple M2칩
- 코어 : 8 (4성능 4효율)
- 메모리 : 16GB
테스트 상황 (VisualVM 활용)
아래와 같은 크기로 서버에 요청
- 크기 : 3.2MB, 화소 : 5323x8000
- 위 크기 사진의 24장. 약 80MB (화소 동일)
🧐 문제 상황
현재 진행 중인 여행 기록 플랫폼을 개발하는 과정에서 이미지 데이터를 다뤄야하는 과정이 있다.
이미지를 처리하는 과정은 아래와 같다.
- 이미지의 메타데이터 추출
- 이미지를 리사이징 후 S3에 저장 (화질 최대한 유지)
위의 과정을 서버에서 직접 처리하는 로직을 작성하고자 하였다.
리사이징 코드는 아래와 같다.
// thumbnailator 라이브러리 사용
Thumbnails.of(original)
.scale(0.25)
.outputQuality(0.9f)
.toFile(outputFile);🚨 문제 발생
상단에 적어놨듯이 크기 : 3.2MB, 화소 : 5323x8000의 사진 24장을 처리하는 테스트를 수행하였다.
1️⃣ 단순 비동기 처리
VisualVM을 사용하여 테스트한 결과는 아래와 같다.
 |  |
|---|---|
| CPU 사용량 | 힙 사용량 |
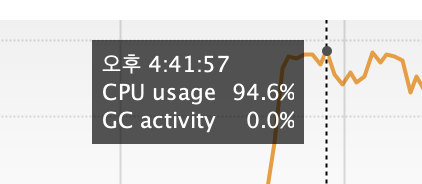
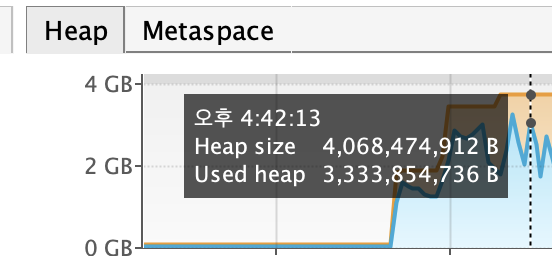
위 사진에서 볼 수 있듯이
- CPU 사용량 약 95% 도달했고,
- Heap Size 약 4GB 상승하고, 사용량은 약 3.3GB로 상승했다.
(기존 Heap 크기는 0.14GB)
CPU 사용량이 95% 라는 것은
- 서버의 연산 자원이 거의 소진된 상태이고,
- 다른 요청을 처리할 CPU 여유가 부족해지고,
- 결과적으로 응답 지연이 발생하거나, 심할 경우 애플리케이션 자체가 멈추는 현상이 나타난다.
또한 Heap 사이즈가 커졌다는 것은
- GC처리 빈도가 증가하여 (객체 정리를 위해서)
- GC 과정 중, 모든 스레드가 멈추기에 응답이 느려지고,
- 최악으로는 더 이상 객체를 저장할 수 없는 Out Of Memory(OOM)가 발생한다.
2️⃣ RabbitMQ를 통한 서버 분산 도입
그래서 위의 문제를 해결하기 위해, RabbitMQ 메시지 브로커를 통해 부하를 분산시키는 방법을 고려해봤다.
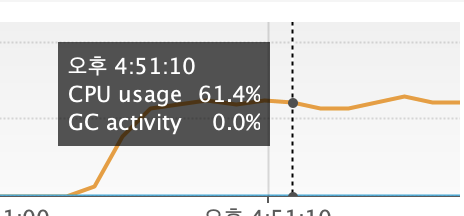
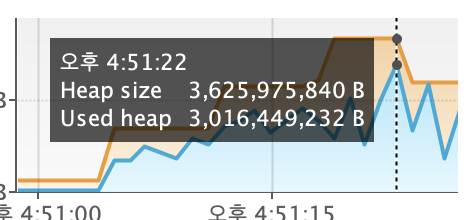
하지만 아래와 같은 결과가 나왔다.
 |  |
|---|---|
| CPU 사용량 | 힙 사용량 |
요청 부하를 분산시켜 해결하고자 하였지만, 서버 부하 문제는 해결되지 않았다.
문제가 해결되지 않을 뿐만 아니라, 컨슈머 서버로 인한 비용 증가의 단점도 생긴다.
🔥 해결 방법
위 처럼 문제가 발생한 이유를 확인하기 위해서는 어떤 작업을 수행 헀는가를 알아야 했다.
위에서 언급했듯이, 사진을 리사이징한다.
파일의 크기가 3.2MB이지 5323x8000와 같이 고해상도 이미지의 경우 메모리 상에서 수십 MB를 차지한다.
이러한 이미지를 디코딩하고, 리사이징과 같은 무거운 작업을 수행하는 과정은 서버에 무리를 준다. 그래서 위와 같은 문제가 발생한 것이다.
그래서, 서버에서 리사이징을 하지 말자라는 결론을 내렸다.
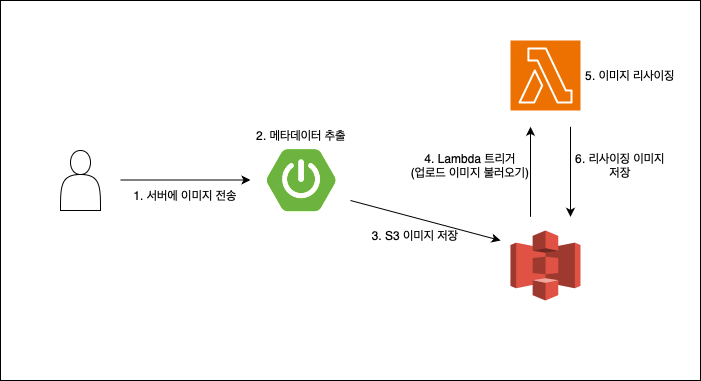
🛰️ Serverless (AWS Lambda) 도입
AWS Lambda를 도입함으로써, 이미지 저장 로직은 아래와 같다.
- 서버에 이미지 전송
웹/앱 클라이언트 -> 서버 - 이미지의 메타데이터 추출
서버 - 이미지를 S3에 전송
서버 -> AWS S3 - S3 업로드 이벤트를 트리거로 Lambda 함수 실행
Serverless - Lambda가 이미지를 리사이징 후 다시 S3에 저장
Lambda -> S3
이런 과정을 도입하여 서버는 더 이상 이미지를 리사이징하거나, 다운로드하거나, 변환하거나 하는 무거운 작업을 전혀 하지 않는다.
그래서, 서버는 가볍게, 서버리스는 무겁게.의 흐름을 명확히 가져가기로 했다.
👉 적용 결과
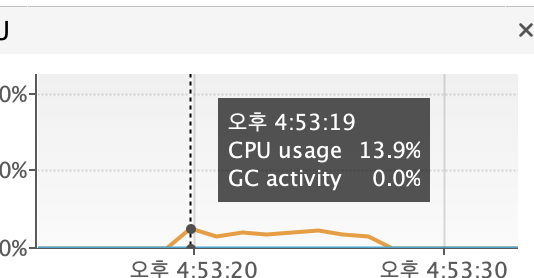 | 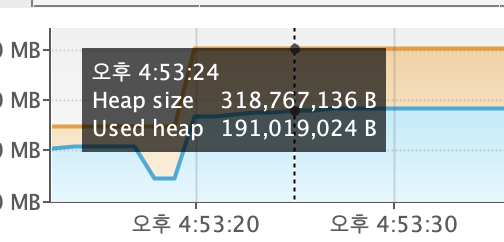 |
|---|---|
| CPU 사용량 | 힙 사용량 |
CPU 사용량 95% -> 14%
힙 3GB/4GB -> 0.2GB/0.3GB
위 크기는 이미지 처리과정 (메타데이터 추출) & S3 전송 과정에서 발생하는 부하로,
CPU 사용량은 약 7배, 힙 사이즈는 약 13배 감소하였다.
Lambda에서 이미지 리사이징은 파이썬 코드를 이용했다.
콜드 스타트 관점에서 봤을 때, 자바의 경우 JVM을 로딩하기 때문에 느리고, 파이썬은 빠르다.
그렇기 떄문에, 파이썬 코드를 이용하였다.
⚙️ Serverless 아키텍처
📌 향후 개선 방향
현재는,
- 서버에 원본 이미지를 보내고
- 메타데이터를 추출하여
- S3에 전송하는 로직이다.
하지만, 서버로 보내는 원본 이미지 I/O 처리 + 메타 데이터 추출 + S3로 전송의 부하가 여전히 나타난다.
테스트 하였던 상황보다 더 대규모의 트래픽이 발생하게 된다면, 똑같이 서버에 부하를 주게 될 것이다.
개선 방향은 아래와 같다.
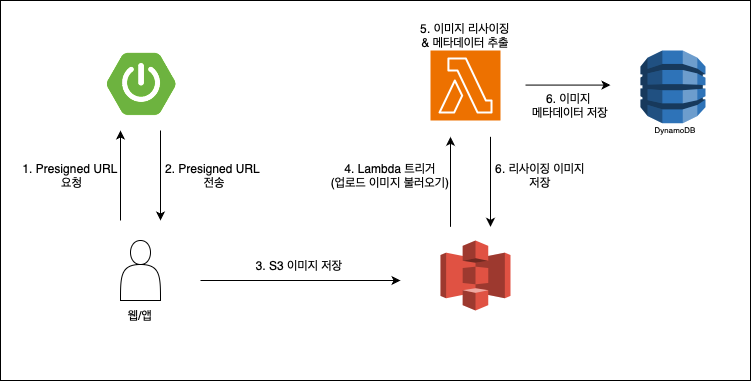
1️⃣ Presigned URL을 이용
요청을 하면 서버가 미리 S3 업로드 URL을 생성하여 클라이언트에 전달한다.
그러면, Presigned URL을 통해서 클라이언트가 직접 S3에 이미지 업로드한다.
=> 서버는 아예 이미지 파일을 받지 않는다
Presigned ULR?
S3 객체에 제한된 시간 동안 직접 접근할 수 있도록 만들어주는 임시 URL.
이를 통해 AWS 키 값을 사용하지 않고, URL만을 통해 안전하게 클라이언트가 S3에 직접 파일을 업로드하거나 다운로드 할 수 있다.
2️⃣ Lambda에서 메타데이터 추출
Lambda가 리사이징뿐 아니라 메타데이터 추출까지 진행한다.
그리고, Lambda는 AWS NoSQL DB인 DynamoDB에 바로 업로드를 한다.
서버 API를 호출하여 메데이터를 전달해도 되지만, 이미지 요청 수가 많아지게 된다면, 서버가 요청에 대해 처리하는 속도가 지연이 되고, 지연으로 인해서 전달 과정에서 타임아웃과 같은 에러가 발생할 수 있다.
Lambda가 재시도 처리 또한 모두 실패했을 때, 해당 데이터는 사라지기에 저장소에 저장하는 것을 고려했다.
=> 서버 부하는 0에 가까워 짐.
⚙️ 개선된 Serverless 아키텍처
💡 느낀점
이번 과정을 통해 다시 한번 느낀 것은서버가 모든 걸 처리하려고 하지 말자.이다.
서버에서 적절히 부하를 분산시켜 작업을 수행하는 것에만 집중했었지만, 이번 트러블 슈팅으로 서버에서만의 처리로는 트래픽 처리의 모든 것을 해결하지 않는다는 것을 알게되었다.
상황에 맞는 도구와 전략을 선택하는 게 가장 중요하다는 걸 몸으로 느낀 경험이었다.
