
이 포스트는 Causal Inference and Discovery in Python의 Chapter7의 내용을 바탕으로 작성되었습니다.
DoWhy란?
DoWhy는 인과추론의 대표적인 라이브러리 중 하나로, 다음과 같은 장점이 있습니다.
- 잘 설게되었고, 일관적이고, 실용적이다.
- 명확하고 쉽고 재현 가능한 4가지 단계를 통해 전체 인과추론 과정을 실행할 수 있다.
- 다른 많은 라이브러리와 통합할 수 있다 (such as EconML, scikit-learn, CausalML).
- 숙련된 연구원과 개발자 팀이 유지관리한다.
- Microsoft&AWS 같은 기업이 지원하고 있어, 장기적으로 안정적인 개발을 할 가능성이 높다.
- 로드맵을 자주 업데이트 하며 미래를 바라본다.
공식 문서에서는 DoWhy를 end-to-end causal inferencel ibrary로 소개할 만큼, 라이브러리를 넘어 프레임워크 같은 역할을 합니다.
(참고: DoWhy 공식 페이지: https://www.pywhy.org/dowhy/v0.8/)
DoWhy의 주요 클래스는 ‘CausalModel’로, 가장 상위 클래스이며 Pandas 데이터 프레임을 처리합니다.
DoWhy를 이용한 인과추론 예시
그럼 실제로 DoWhy로 인과효과를 추정해보겠습니다.
Step0. Generate the dataset
이 예시에선 GPS 사용이 공간 기억에 주는 영향에 대한 데이터를 생성해 사용했습니다.
이 데이터는 treatment인 GPS 변수(X), outcome인 공간 기억 변수(Y), 그 외에 해마 부피 변수(Z)를 가지고 있습니다.
CausalModel은 dataset을 Pandas dataframe으로 받기 때문에 해당 형식으로 만들어 주어야 합니다.
# First, we'll build a structural causal model (SCM)
class GPSMemorySCM:
def __init__(self, random_seed=None):
self.random_seed = random_seed
self.u_x = stats.truncnorm(0, np.infty, scale=5)
self.u_y = stats.norm(scale=2)
self.u_z = stats.norm(scale=2)
self.u = stats.truncnorm(0, np.infty, scale=4)
def sample(self, sample_size=100, treatment_value=None):
"""Samples from the SCM"""
if self.random_seed:
np.random.seed(self.random_seed)
u_x = self.u_x.rvs(sample_size)
u_y = self.u_y.rvs(sample_size)
u_z = self.u_z.rvs(sample_size)
u = self.u.rvs(sample_size)
if treatment_value:
gps = np.array([treatment_value]*sample_size)
else:
gps = u_x + 0.7*u
hippocampus = -0.6*gps + 0.25*u_z
memory = 0.7*hippocampus + 0.25*u
return gps, hippocampus, memory
def intervene(self, treatment_value, sample_size=100):
"""Intervenes on the SCM"""
return self.sample(treatment_value=treatment_value, sample_size=sample_size)
Step1. modeling the problem
다음으로, causal graph를 정의하고, 이를 GML 그래프 형식으로 작성해줍니다.
Step1.1 Define the graph structure
여기에선, 각 변수들이 다음과 같은 그래프 구조를 갖는다고 가정해보겠습니다.
Motivation 변수는 데이터에 없는 관측되지 않은 변수이지만, 그래프에 포함해주어야 모델이 이를 인지하고 정확한 인과효과를 추정할 수 있습니다.
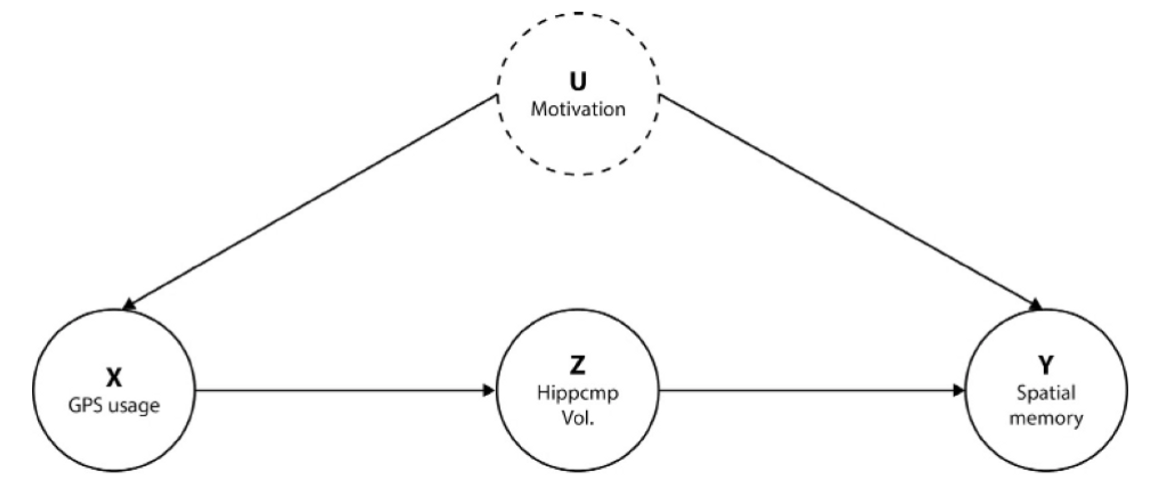
Step 1.2 Define the GML Graph
정의한 그래프를 바탕으로 GML 그래프를 작성합니다.
GML 그래프는 문자열 형식으로 크게 3가지를 정의해주어야 합니다.
- 그래프 종류 정의 (directed/undirected)
- 맨 앞 부분에 그래프 종류를 정의해줍니다. 단방향 그래프라면 directed, 양방향 그래프라면 undirected로 작성하면 됩니다.
- Node 정의
- 그 다음으로, node를 정의해줍니다. 노드는 유니크한 ID와 label을 갖습니다.
- Edge 정의
- 마지막으로, node 간 엣지를 정의합니다. 각 엣지는 source와 target 파라미터를 갖는데, 어떤 노드(source)로부터 어떤 노드(target)로 향할지 기입하면 됩니다.
# Create the graph describing the causal structure
gml_graph = f"""
graph [
directed 1
node [id "gps" label "gps"]
node [id "hippocampus" label "hippocampus"]
node [id "memory" label "memory"]
node [id "motivation" label "motivation"]
edge [source "gps" target "hippocampus"]
edge [source "hippocampus" target "memory"]
edge [source "motivation" target "gps"]
edge [source "motivation" target "gps"]
]
"""참고로, 각 문자열은 반드시 “”(쌍따움표)로 감싸줘야 합니다. ‘’를 사용 시 에러가 발생합니다.
Step 1.3 Define the Dowhy model
이제 CausalModel 클래스에 필요한 모든 input이 만들어졌으니, 모델 객체를 생성해보겠습니다.
CausalModel에는 4가지 정보를 넣어주어야 합니다.
1) Pandas DataFrame 2) Treatment column name 3) Outcome column name 4) GML graph
# With graph
model = CausalModel (
data=df,
treatment='gps',
outcome='memory',
graph=gml_graph
)모델에 넣어준 causal graph도 그릴 수 있습니다.
model.view_model()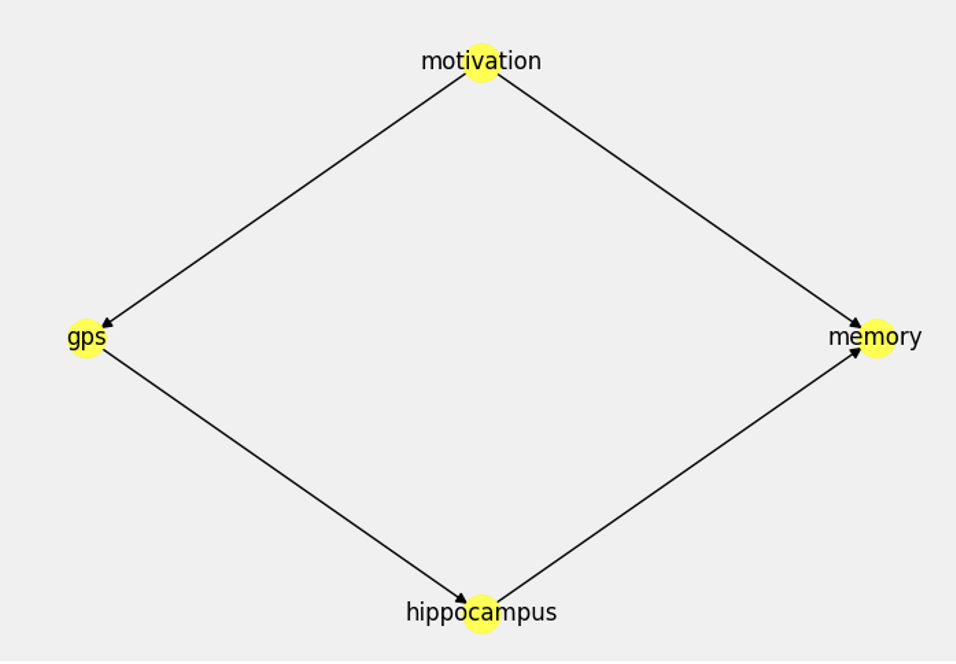
Step2. Identifying the estimand(s)
인과효과를 추정하기 전, 어떤 인과추론 방법을 사용해야 할지 DoWhy로 찾을 수 있습니다.
DoWhy는 세가지 추정방법 후보를 제공합니다. 1) Back-door 2) Front-door 3) Instrumental variable
각 추정방법에 대해 매우 간단히 설명드리면, back-door은 control variable을 통제하여 인과효과를 추정하고, front-door은 chain variabel을 이용, instrumental variable은 말그대로 instrumental variable을 이용하여 인과효과를 추정합니다.
그럼, 이 문제에서는 어떤 방법을 사용할 수 있는지 확인해보겠습니다.
estimand = model.identify_effect
결과에서 볼 수 있다시피, 3가지 방법을 모두 실행하고 만약 인과 구조상 실행할 수 없는 방법이라면, ‘No such variable(s) found!’ 를 출력합니다.
여기선 instrumental variable과 control variable이 없기 때문에, backdoor과 iv 방법은 사용할 수 없다고 출력되었네요.
이 문제에서는 frontdoor만 사용 가능하니, 해당 방법을 추정기로 사용하겠습니다.
Step3. Obtaining estimates
그럼 실제로 추정을 해볼까요?
인과효과를 추정하는 함수는 estimate_effect 이고, 이 함수는 두 개의 인자를 받습니다.
-
estimand
-
사용할 모델 이름
앞서, 추정기는 frontdoor로 정했으니 사용할 모델만 정하면 되는데요,
DoWhy에선 frontdoor estimator로 two linear regression model만 지원하기 때문에 이 모델을 사용하도록 하겠습니다.
estimate = model.estimate_effect(
identified_estimand=estimand,
method_name='frontdoor.two_stage_regression')print(f'Estimate of causal effect (linear regression): {estimate.value}')
이 모델이 추정한 결과는 -0.421로, 실제 인과효과인 -0.42에 거의 근접합니다.
Step4. Refutation tests
이 예시에선 실제 인과효과 값을 알기 때문에 추정값이 정확하다는걸 알 수 있지만, 실제 인과추론을 할 땐 추정값을 검증해볼 필요가 있습니다.
인과추론에선 검증에 refutation test를 많이 사용합니다.
refutation test는 모델 혹은 데이터 구조를 바꾸면서 결과가 어떻게 달라지는지 테스트하는 방법으로, unobserved data 우려가 있을 때 CV(Cross-Validation) 대신 사용하기 좋습니다.
(CV는 observed data에 대한 검증만 가능하기 때문)
DoWhy는 refutation test를 위한 2가지 변환을 제공합니다.
- Invariant transformations
- 인과관계가 변하지 않도록 데이터 변경을 함
- 만약, 인과효과가 달라졌을 경우 모델을 신뢰할 수 없음
- 예시) 약물이 혈압에 미치는 효과를 추정한 모델에서, 혈압의 단위를 다르게 변환
- Nullifying transformations
- 인과관계가 변하도록 데이터 변경을 함
- 만약, 인과효과가 같을 경우 모델을 신뢰할 수 없음
- 예시) 일부 treatment variable을 control variable로 바꿈
여기서는 invariant transformations의 일환으로, 데이터의 일부분을 없앤 후 인과효과를 다시 추정해보겠습니다.
refute_subset = model.refute_estimate(
estimand=estimand,
estimate=estimate,
method_name="data_subset_refuter",
subset_fraction=0.4)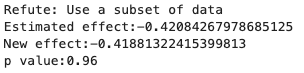
변환 후 계산된 인과효과는 -0.42로 기존 인과효과 값과 매우 유사한 값 입니다.
두 값이 같다는 가설에 대한 지표인 p-value도 0.96으로 통계적으로 유의합니다.
Key Ideas
인과추론의 대표적인 라이브러리 중 하나인 DoWhy의 사용법에 대해 알아보았습니다.
DoWhy는 코드 몇 줄 만으로 인과효과를 간단하게 추정할 수 있어 매우 편리합니다.
또한, 이 예시에서는 사용하지 않았지만 sklearn이나 EconML의 모델을 추정 모델로 사용할 수 있습니다.
