데이콘 해커톤 - bert vs gpt
이 포스트는 9월22일에서 9월 25일까지 있었던 데이콘의 뉴스 기사 레이블 복구 해커톤 회고록 겸 sbert 공부이다. 해커톤을 하며 생각했던 사고과정과 알게된 개념에 대해 정리하고자 한다.
Dataset Info.
news.csv [파일]
id : 샘플 고유 id
title : 뉴스 기사 제목
content : 뉴스 기사 전문sample_submission.csv [파일] - 제출 양식
id : 샘플 고유 id
category : 뉴스 카테고리
처음에 데이터와 baseline을 보니 데이터가 정말 간단하여 전처리는 크게 건들게 없고 모델과 군집화 방법만 바꾸면 될것이라 생각했다. transformer에서 발전된 형태가 더 개선된 모델이 무엇인지 모르겠어서bert와 gpt가 있다는것을 알고 둘의 차이를 알아야겠다고 생각했다.
~~bert 모델에서 입력값을 바꿔본다던가 학습방식을 바꿔본다던가 하는 형태로 rbert roberta 등 파생품 등이 나오고 있다
seq2seq
encoder모델:output이 컴퓨터가 이해할 수 있는 숫자로 떨어짐
context벡터(의미를 가진 벡터값)을 활용해서 생성하는 태스크
~~
bert 계열과 gpt계열의 차이점
사람처럼 자연어로 소통가능한 존재를 만들고 싶어한다.
'자연어 빅데이터에 담긴 지식을 언어 모델이 최대한 많이 배우도록 하자!'
ex)가짜뉴스 판별
input: 뉴스기사가 통째로 모델의 인풋으로 들어간다
output: 뉴스기사가 가짜다 or 가짜가 아니다
레이블이 각각이 뭔지는 사람이 보고 판단하는게 가장정확하다
하지만 정답이 태깅된 데이터셋이 그렇게 많지 않고 태깅하는데 시간과 돈이 많이 든다.
=> 따라서 정답이 annotation된 데이터셋이 한정되어있다.
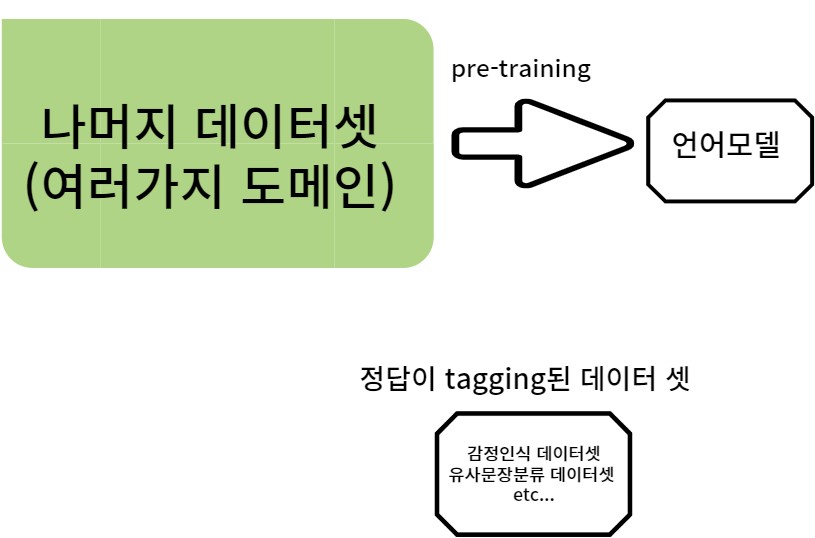
pre-train과 train의 차이
언어모델을 만들때 정답이 태킹된 데이터셋을 많이 만들어서 학습시키는것도 가능하다. 하지만 나머지 데이터셋(대부분의 데이터셋)을 활용하면 그 안에 있는 막대한 양의 데이터로 pre-training한걸로 끝난게 아니라 이 언어모델을 가짜뉴스판별서비스에 적용해서 좀 더 잘 분류할 수 있게 만들수 있다. 이를 각각의 도메인이나 테스크마다 적용시켜야한다.
이를 각 도메인이나 테스크마다 적용시키는 것을 또다른 training으로 볼수 있다는 것을 염두해두고 데이터셋으로부터 최초 언어모델을 학습시키는것을 pre-training이라고 부른다
엄청난 양의 데이터셋이 스케이트타는법에 대하 내용을 다룬다고 가정하자.
이 데이터로 학습을 잘시킨 모델은 빙상에서 스케이트타는 기술이나 기법에 대한 많은 지식을 습득한 상태이다. 근데 이를 잘 갖춘 모델이라고해도 (스피드스케이드,피겨스케이트)같은 다른 테스크에서는 또 따로 배워야 할 것들이 존재한다. 따라서 언어모델이 특정 테스크나 모델에 적용될 때는 training의 과정이 한번 더 필요하다. 그래서 대량의 데이터셋에서 언어모델이 학습하는 과정은 각각의 테스크에 적용되기 이전의 과정이다. 그래서 pre-training이라고 불린다. 이를 통해서 언어모델은 어마어마한 양의 지식을 습득했다.
그냥 아무것도 없는 상태에서 스케이트 타는법에 대해 학습시키는거보다 대규모의 데이터로부터 빙상에서 스케이트를 타는 법에 대한 지식을 습득한 모델이 스케이트 더 잘타게 될것이다. 이처럼 LLM에서 각 task에 맞춤으로 train하는걸 train이라고 한다
bert vs gpt
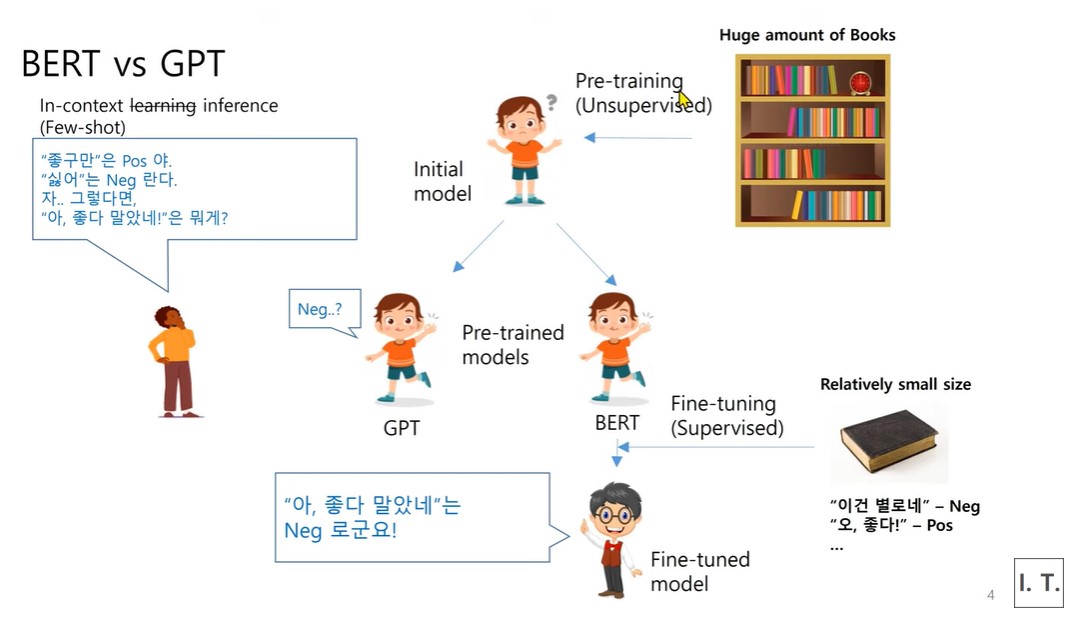
Bert와 gpt 모두 pre-training과정에서 많은 지식을 배운다는 공통점을 지닌다.
이후의 Fine-tuning 과정에서 GPT와 BERT는 차이를 보인다.
BERT
이렇게 pre training된 모델을 bert계열에서는 풀고자하는 task가 있다는 가정하에 Fine- tuning이 진행된다.
정답 label이 매겨진 tagging이 된 혹은 annotation된 데이터셋이 있다고 가정하자. 이런 데이터셋은 도서관(위의 사진 참고)에 있는 책보다 양이 훨씬적다(small size data set). 이걸로 fine-tuning해서 완성된다.
ex)아이가 도서관에서 무작정 1년간 책을 읽는다(pre-training)
그 아이가 도서관에서 나왔을때 책을 하나 던져준다. (감성인식이 tagging된 책) 이 책이 도서관안에 없었다고 할지라도 그 정보가 이미 도서관 책들에 담겨있을 것이다. 그래서 아이는 한권의 책을 통해서 훨씬 효과적으로 학습할 수 있을 것이다. 이를 전이학습(transfor learn)이라고 한다
결론: bert 모델은 supervise 방식에 의해 전이학습이 이뤄진다. 이처럼 특성 task나 도메인이 adaptatoin된 언어모델의 파라미터를 재설정하는걸 fine-tuning이라고 한다. 이는 fine-tuning되지 않은 모델에 비해 해당 task에서 훨씬 잘 맞출 수 있다.
GPT
gpt계열은 하나의 pre-train을 잘 시킨 슈퍼모델에 계속된 질문의 문맥을 바탕으로 정보를 학습하고 그 문맥에 적합한 출력을 생성하는 학습 방식을 말한다.
GPT 계열은 BERT처럼 1년동안 책을 읽은 아이에게 또 책을 읽으라고 시키지 않는다. 다만 이 아이에게 내가 원하는 답을 얻기위해 아이에게 곧바로 퀴즈를 내듯이 질문을 하게된다. 이를 맞출 수 있게 시도 하는것이다. 이를통해 아이는 퀴즈의 주어진 문맥을 바탕으로 정보를 학습하고 그 문맥에 적합한 출력을 생성하는 학습을 한다.
이를 gpt 계열 논문에서는 in-context learning이라고 지칭한다.
in-context learning은 bert에서 추구하는 학습이란 개념과 많이 다르다
bert에서 얘기하는 fine-tuning은 어린아이가 배웠던 지식에 더해서 추가로 준 책으로부터 새로운 지식을 조금이라도 배우게 된다. 따라서 추가적인 지식이 반영이 된다.
결국 bert는 pre-training과정에서 파라미터가 업데이트 되었다.
하지만 gpt 계열의 in- context learning은 파라미터 업데이트가 더이상 일어나지 않는다. 학습이 일어나지 않는 것이다.이처럼 파라미터 업데이트가 일어나지 않아서 in context inference 라고 불리기도 한다.
pos , neg 같은 경우는 두개의 예시가 있다. 이 예시가 몇개냐에 따라 few-shot이 two-shot이라고 됨 이게 몇개가 되느냐에 따라 숫자가 바뀐다. 예시를 주지 않으면 zero- shot이다.
gpt는 pre-train을 잘 시킨 하나의 슈퍼모델을 만들어서 모든 task에 적용시킬 수 있게 하는것이다
이런 gpt모델에서도 해당 분야의 퀴즈를 계속 냄으로써 fine tuning을 시도했다.
하지만 한개의 슈퍼모델을 만들어서 모든 영역에 적용하고자하는 gpt 계열이더라도 fine -tuning을 거치면 더좋은 성능을 낼수 있을 것이라고 여겨져 이에 대한 시도가 이어지고 있다
컴달인 유튜브를 토대로 작성했습니다
