push_swap은 난수를 효과적으로 정렬하는 과제이다. 정렬을 위해서 먼저 어떤 구조로 난수를 받아 저장해 둘 지 선택해야 하는데, 여기서 자료구조에 대한 정리가 필요하다고 느껴졌다.
👀 자료구조
자료구조란 데이터를 구조적으로 표현하는 방식으로, 여러 종류가 있다. 효율적인 자료구조에 따라 효율적인 알고리즘을 사용할 수 있게 한다. 과제에는 스택 a, 스택 b라고 되었는데, 스택은 자료구조의 선형구조 중 하나이다. 선형구조에는 배열, 리스트 외에 stack, queue, deque가 있다.
어떤 정렬 알고리즘을 사용하는 지에 따라 사용하는 자료구조도 다르다. 일단 자료구조를 알아야 할 것 같아 대표적인 선형 자료 구조 stack, queue, deque을 알아보도록 했다.
✅ stack
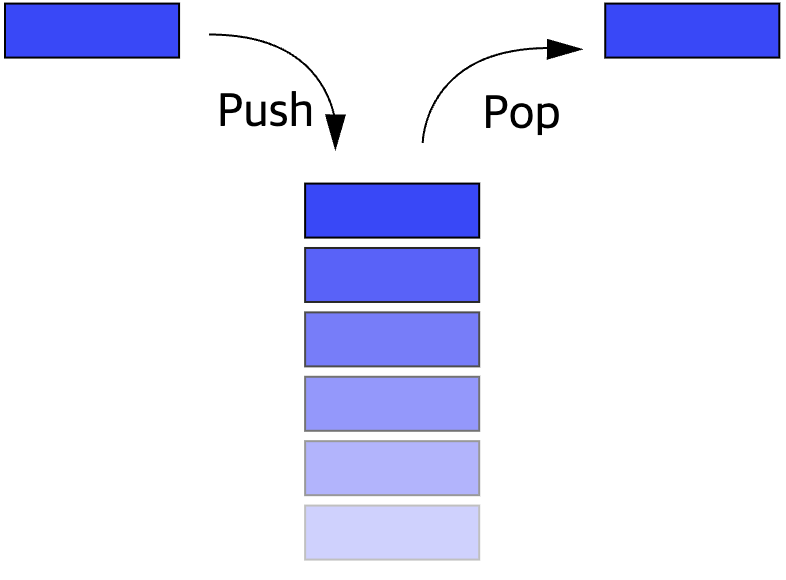
스택은 메모리 구조에서 보았듯 후입선출(LIFO, Last-In First-Out) 방식으로, 가장 늦게 저장된 데이터가 가장 먼저 인출된다. 스택의 맨 위의 데이터(top)에만 접근이 가능하기 때문에 그 아래 위치한 데이터를 바로 삭제할 수 없다.
🤔 피신 때 재귀함수에서 atoi를 구현했던 것을 생각해보면, 일의 자리 끝부터 write();로 출력하는데 왜 순서대로 출력이 될까? 궁금했었는데 바로 후입선출방식으로 쌓였다 출력되기 때문이다.
장단점
구조가 단순하기 때문에 구현이 쉽고, ⚡️ 데이터를 저장하거나 읽는 속도가 빠른 장점이 있다. 하지만 데이터 크기를 미리 정하고 사용해야 하므로 저장 공간 낭비가 일어날 수 있고, 고정된 크기에서 넘쳐나면 다른 메모리 영역을 침범하는 ☄️StackOverFlow가 일어날 수 있다. 또 가장 top에 있는 데이터 외의 데이터를 삭제하려면 그 위의 데이터를 모두 꺼낸 후 해당 데이터에 접근해 삭제할 수 있다.
사용
가장 최신 데이터를 먼저 처리해야 될 때 사용하므로, 재귀 알고리즘을 비롯해서 실행 취소 및 뒤로가기에 사용한다.
✅ queue
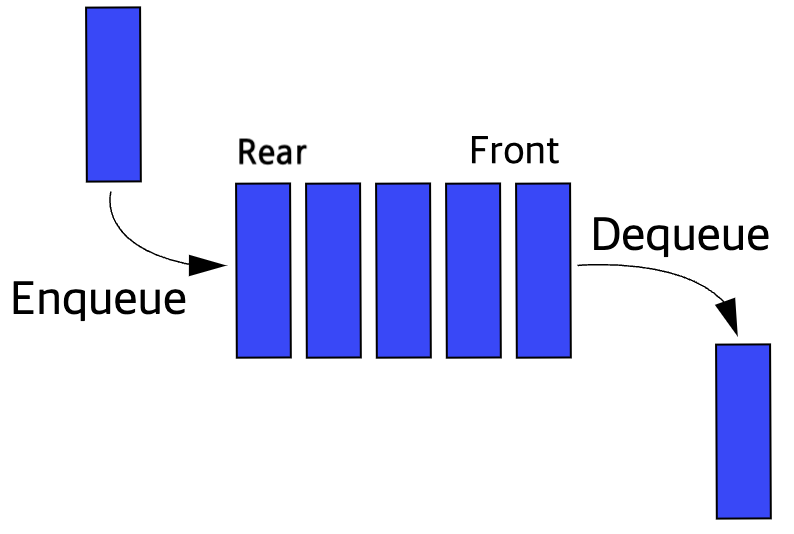
큐는 선입선출(FIFO, First-In First-Out) 방식으로, 한쪽에서 자료가 삽입(rear)되면 반대쪽에서 자료가 삭제(front)된다. 가장 오래된 자료만 인출되고, 가장 먼저 입력받은 데이터를 가장 먼저 처리해야 될 때 사용한다.
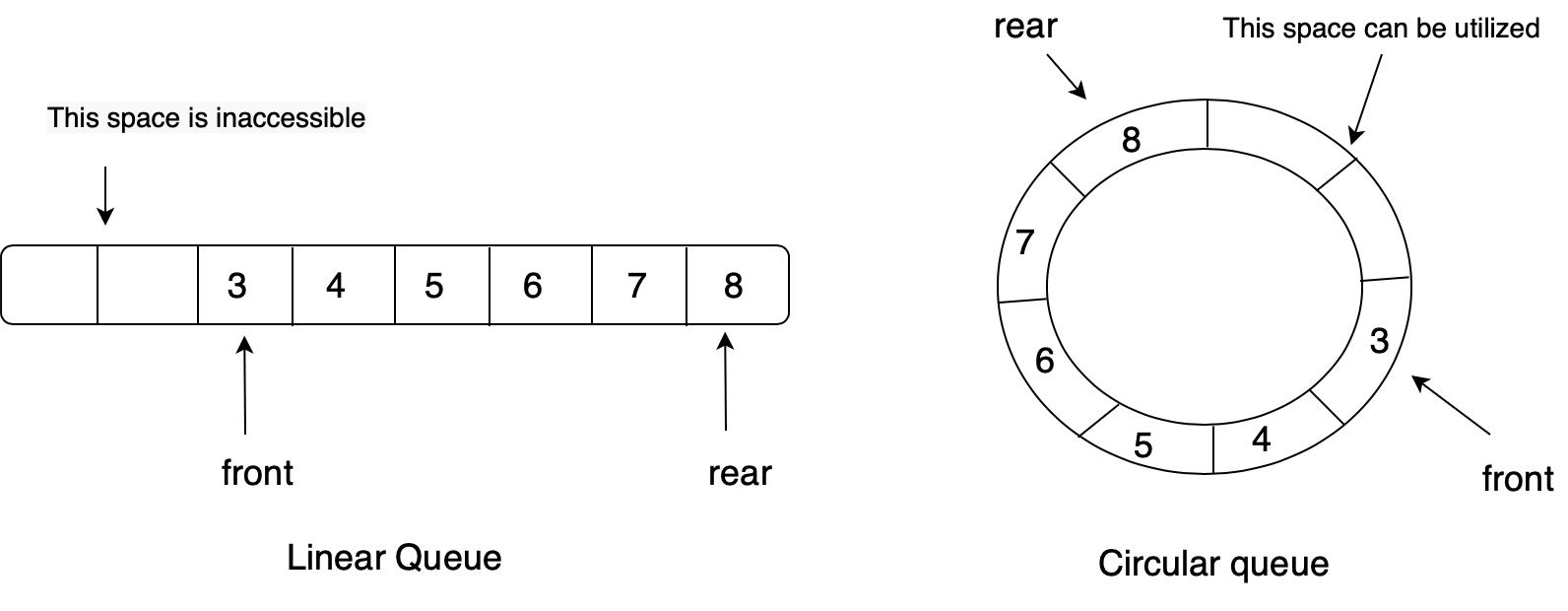
큐의 종류에는 대표적으로 선형큐, 원형큐가 있다. 선형큐와 원형큐 모두 선입선출 방식이지만 형태에 따라 기능적 차이를 보이기 때문에 상황에 따라 알맞게 선택해서 사용하면 된다.
장단점
데이터를 저장하거나 읽는 속도가 빠르다. 큐 또한 스택과 마찬가지로 중간에 위치한 데이터 삭제를 바로 할 수 없다.
선형 큐의 경우, 데이터를 삭제한다고 비워진 앞의 공간이 저절로 채워지지 않기 때문에 남은 데이터를 앞 공간으로 땡겨주는 작업이 필요하다. 이 작업을 하지 않으면 공간이 남아 있더라도 데이터를 추가할 수 없게 될 수 있다.
이러한 선형 큐의 단점을 보완한 것이 원형큐이다. 원형큐는 한 공간을 비워두어서 큐가 꽉 찬 상태인지, 여유가 있는 상태인지 판단할 수 있게 한다. front == rear인 경우, 큐가 빈 상태이고 front == (rear+1) % QUEUE_SIZE이면 큐가 꽉 찬 상태를 확인할 수 있다.
사용
순서가 중요한 데이터를 처리할 때 좋다. 프로세스 관리, BFS 구현, 캐시 구현에 사용한다.
✅ deque
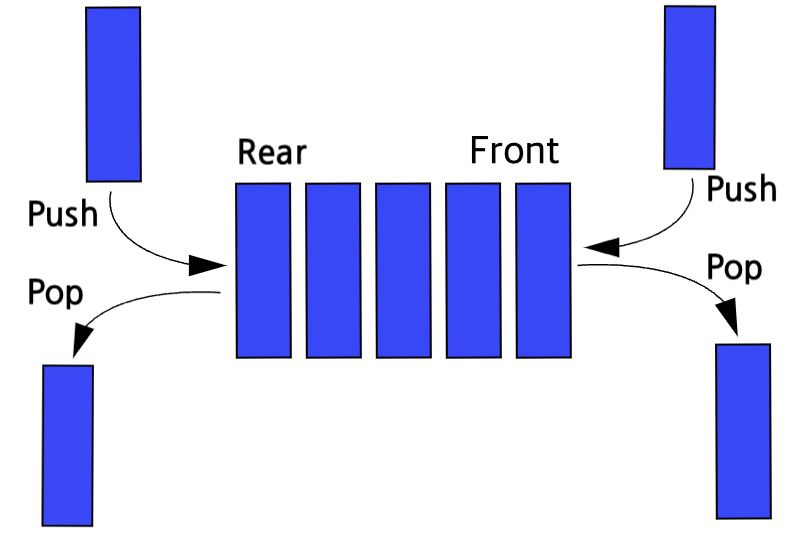
덱은 Double-Ended Queue의 줄임말로, 스택과 큐의 장점만 가져와 구성한 것이다. 한쪽에서만 삽입하고 반대쪽에서만 삭제가 가능했던 큐와 달리, 양쪽에서 삽입 삭제가 가능하다. 새로운 데이터 삽입 시, 메모리를 재할당하고 복사하지 않고 새로운 단위의 메모리 블록을 할당하여 삽입하여 가변적 크기를 가진다. 스택과 큐보다 훨씬 유연하지만 구현이 어렵다.
push_swap에서는 데이터를 top에서도 빼고, bottom에서도 빼야 하므로 나는 deque을 구현해서 사용하기로 했다. 오랜만에 연결 리스트 구현하기는 어색했지만 그래도 이번에 많이 배운 것 같다. 과제를 통과하기 위해서 요즘 카뎃들 사이에 유행하는 모래시계 알고리즘으로 풀어봤는데 탄탄한 기본기를 위해서는 정렬 알고리즘도 공부해야할 필요성을 느꼈다. 🤯
📚 참고
