✔️ SQL 주요 문법
데이터베이스 생성
CREATE DATABASE 데이터베이스_이름;데이터베이스 사용
USE 데이터베이스_이름;데이터베이스 삭제
DROP DATABASE 데이터베이스_이름;테이블 생성
CREATE TABLE 테이블_이름 ( id int PRIMARY KEY AUTO_INCREMENT, name varchar(255), email varchar(255) );테이블 정보 확인
DESCRIBE 테이블_이름;테이블 삭제
DROP TABLE 테이블_이름;연습문제 : SQL Quiz, SQL Exercises
✔️ SQL 명령어 살펴보기
SELECT : 데이터셋에 포함될 특성을 특정
SELECT 특성FROM : 결과를 도출해낼 데이터베이스 테이블 명시
SELECT 특성_1 // 특성_1, 특성_2, 특성_3 처럼 ','로 복수선택 가능, '*'로 전체선택 가능 FROM 테이블_이름WHERE : 필터 역할을 하는 쿼리문 (선택적으로 사용)
SELECT 특성_1, 특성_2 FROM 테이블_이름 WHERE 특성_1 = "특정 값" // 특정 값과 동일한 데이터 찾기 SELECT 특성_1, 특성_2 FROM 테이블_이름 WHERE 특성_2 <> "특정 값" // 특정 값을 제외한 값 찾기 SELECT 특성_1, 특성_2 FROM 테이블_이름 WHERE 특성_2 LIKE "%특정 문자열%" // 문자열에서 특정 값과 비슷한 값들을 필터링할 때, // 'LIKE'와 '\%' 혹은 '\*' 를 사용 SELECT 특성_1, 특성_2 FROM 테이블_이름 WHERE 특성_2 IN ("특정값_1", "특정값_2") // 리스트의 값들과 일치하는 데이터 찾기 SELECT * FROM 테이블_이름 WHERE 특성_1 IS NULL // 값이 없는 경우 찾기ORDER BY : 돌려받는 데이터 결과를 어떤 기준으로 정렬하여 출력할지 (선택적으로 사용, 기본은 오름차순이다.)
SELECT * FROM 테이블_이름 ORDER BY 특성_1 DESC // 내림차순으로 정렬LIMIT : 결과로 출력할 데이터의 개수 (선택적으로 사용, 가장 마지막에 추가)
SELECT * FROM 테이블_이름 LIMIT 55 // 55개만 출력DISTINCT : 유니크한 값을 받고 싶을 때
SELECT DISTINCT 특성_1 FROM 테이블_이름INNER JOIN 혹은 JOIN : 둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결
SELECT * FROM 테이블_1 JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_BOUTER JOIN : 동일한 값이 없는 행도 반환할 때 사용
SELECT * FROM 테이블_1 LEFT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B // 테이블_1 기준 SELECT * FROM 테이블_1 RIGHT OUTER JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B // 테이블_2 기준INSERT INTO : 데이터 추가
INSERT INTO 테이블_이름 (특성_1, 특성_2) VALUE (값_1, 값_2)UPDATE SET : 데이터 수정
UPDATE 테이블_이름 SET 바꿀 특성 = 변경값 WHERE 조건DELETE : 데이터 삭제
DELETE FROM 테이블_이름 WHERE 조건
✔️ 관계형 데이터베이스 설계
❓
스키마(schema)
데이터베이스에서 데이터가 구성되는 방식과 서로 다른 엔티티(entities) 간의 관계에 대한 설명을 정의한다. 즉, 데이터베이스의 "청사진"과 같다.
📂 키워드
데이터(Data) : 각 항목에 저장되는 값
테이블(Table) : 미리 정의된 열의 데이터 타입대로 작성된 데이터가 행으로 축적됨
필드(Field) : 행렬의 열에 해당됨
레코드(Record) : 테이블에 저장된 항목, 행렬의 행에 해당됨
키(key) : 테이블의 각 레코드를 구분할 수 있는 값. 레코드마다 고유한 값을 가지며 기본키(primary key)와 외래키(foreign key) 등이 있음
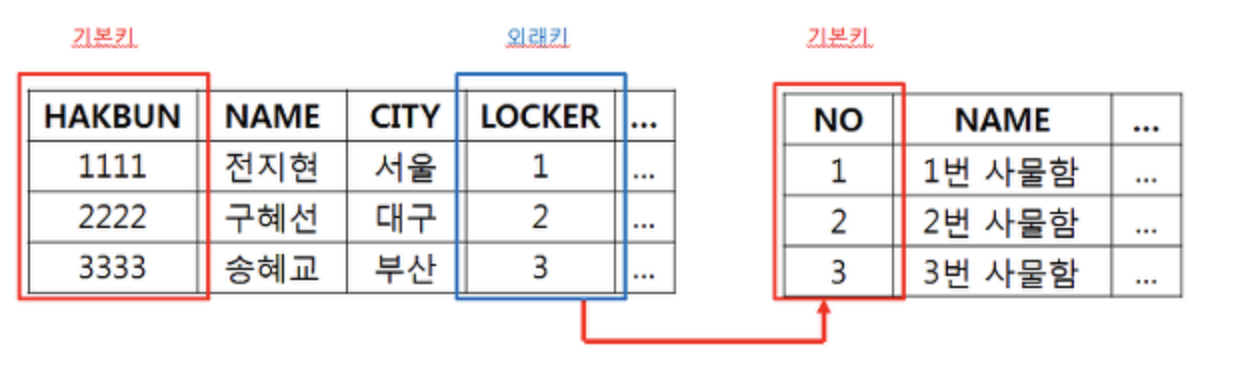
❓ Foreign Key, Primary Key
기본키(primary key): 관계형 데이터베이스 테이블의 각 레코드를 고유하게 식별하는 속성이다.
외래키(foreign key): 다른 Table을 참조하는 목적으로 사용된다.
📂 관계
1:1
하나의 레코드가 다른 테이블의 레코드 한 개와 연결된 경우이다. 직접 저장하는 게 나을 수도 있기 때문에 자주 사용하지는 않는다.
1:N
하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우이다. (부모 자식 관계가 해당된다.)
N:N
여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우이다. 1:N(일대다) 관계와 비슷하지만, 양방향에서 다수의 레코드를 가질 수 있다.
Join 테이블을 만들어 관리한다. N:N 관계는 두 개의 1:N 관계와 모양이 같다. 두 개의 테이블과 1:N(일대다) 관계를 형성하는 새로운 테이블로 N:N(다대다) 관계를 나타낼 수 있고, 이 테이블을 조인테이블이라 한다.
self referencing
테이블 내에서도 관계가 필요할 때 사용한다.
🤓 관계형 데이터베이스 설계 실습해보기
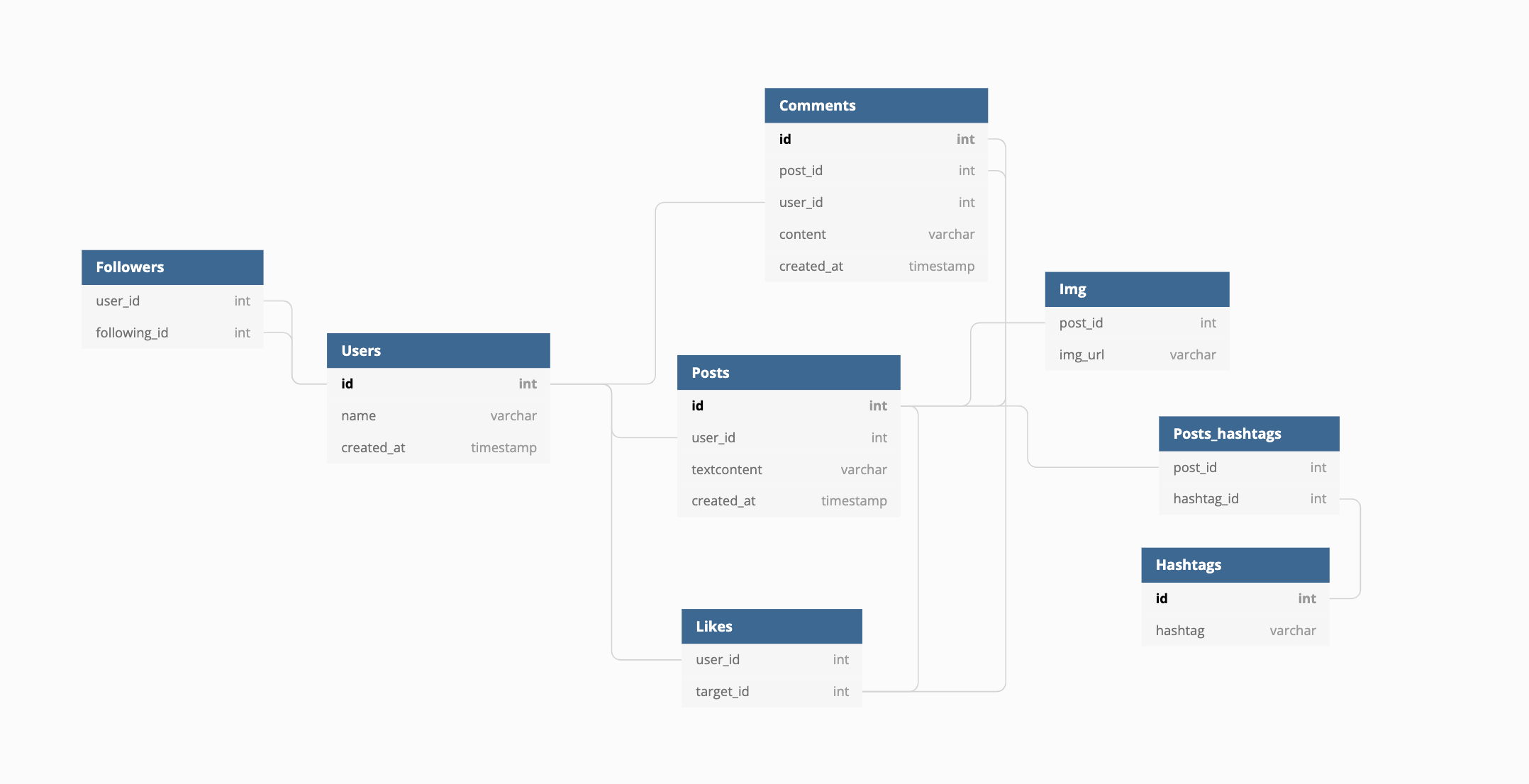
아래는 내가 작성해본 인스타그램의 스키마 디자인이다. 스키마를 통해 엔티티간의 관계와 데이터 타입, 필드 등을 알 수 있다.
Table Users { id int [pk, increment] // auto-increment name varchar created_at timestamp } Table Followers { user_id int following_id int } Table Posts { id int [pk, increment] user_id int textcontent varchar created_at timestamp } Table Img { post_id int img_url varchar } Table Posts_hashtags { post_id int hashtag_id int } Table Hashtags { id int [pk, increment] hashtag varchar } Table Comments { id int [pk, increment] post_id int user_id int content varchar created_at timestamp } Table Likes { user_id int target_id int } Ref: Posts.user_id > Users.id // 외래키를 사용하요 기본키를 참조해 관계를 나타낸다. Ref: Followers.user_id > Users.id Ref: Followers.following_id > Users.id Ref: Posts_hashtags.post_id > Posts.id Ref: Posts_hashtags.hashtag_id > Hashtags.id Ref: Img.post_id > Posts.id Ref: Comments.post_id > Posts.id Ref: Comments.user_id > Users.id Ref: Likes.user_id > Users.id Ref: Likes.target_id > Posts.id Ref: Likes.target_id > Comments.id