날짜별 정보를 담은 데이터베이스 (4) Python 데이터 분석
개요
기능 구현은 Rust에서, 게이트웨이는 Python에서 작성하고 있었지만
데이터 분석 부분은 Python으로 작성하는 게 좋다.
🤖 AI AGENT | Polyglot(다국어) 아키텍처의 정석
실무에서는 "각 언어가 가장 잘하는 것을 시킨다"는 원칙을 따릅니다.
- Rust의 역할 (Data Engineering / Ingestion): 초당 수만 건의 트래픽을 메모리 누수나 크래시 없이 받아내고, 데이터베이스에 Bulk Insert로 꽂아 넣는 "고성능 데이터 적재 엔진"으로는 Rust를 따라올 언어가 없습니다.
- Python의 역할 (Data Science / API): 적재된 데이터를 꺼내서 가공하고, 시각화하고, 인사이트를 뽑아내는 "데이터 분석가/과학자의 도구"로는 Python이 최적입니다.
💡 참고: 최근 파이썬 데이터 생태계에서 가장 각광받는 초고속 데이터 프레임 라이브러리인 Polars 조차도 "코어 엔진은 Rust로 만들고, 사용자가 조작하는 껍데기(API)는 Python으로 제공"하는 방식을 취하고 있습니다. 우리가 만든 시스템과 정확히 같은 철학입니다!
그리고 같은 Python이라고 게이트웨이에 함께 구현하기보다는
별도의 마이크로서비스로 분리하는 게 좋다.
🤖 AI AGENT | 서비스 분리
1. I/O Bound vs CPU Bound (이벤트 루프 블로킹)
- API 게이트웨이 (FastAPI): 이 서버의 유일한 목적은 클라이언트의 요청을 1ms라도 빨리 받아서 Rust로 넘기고 응답하는 것입니다(I/O Bound). 비동기(Async) 이벤트 루프를 사용해 수만 개의 요청을 동시 처리해야 합니다.
- 분석 엔진 (Pandas, Scikit-learn): 수십만 건의 데이터를 메모리에 올리고 통계와 머신러닝 연산을 수행하는 극도로 무거운 작업(CPU Bound)입니다.
- 최악의 시나리오: 만약 FastAPI 서버 안의 엔드포인트(예:
/api/v1/analyze)에서 K-Means 클러스터링을 돌린다면, 파이썬의 GIL(Global Interpreter Lock)과 동기적 연산 특성 때문에 분석이 끝나는 몇 분 동안 게이트웨이가 그대로 멈춰버립니다. 다른 유저들은 로그인 로그조차 남기지 못하고 타임아웃 에러를 겪게 됩니다.2. 독립적인 스케일링 (Independent Scaling)
- 트래픽이 폭주하여 게이트웨이 서버를 10대로 늘려야(Scale-out) 할 때, 분석 엔진까지 10대가 될 필요는 없습니다.
- 반대로 데이터가 너무 많이 쌓여 분석 서버의 메모리(RAM)를 64GB로 늘려야(Scale-up) 할 때, 게이트웨이 서버까지 고스펙을 쓸 필요는 없습니다.
- 각자의 역할에 맞는 하드웨어 스펙과 컨테이너 개수를 유연하게 조절하기 위해 물리적인 분리가 필수적입니다.
3. 라이프사이클의 차이 (Daemon vs Batch)
- 게이트웨이와 엔진: 24시간 365일 켜져 있어야 하는 데몬(Daemon) 프로세스입니다.
- 분석 모듈: 실시간으로 돌릴 필요 없이, 보통 새벽 3시에 하루치 데이터를 묶어서 처리하거나 1시간에 한 번씩 도는 배치(Batch) 작업 또는 크론잡(Cronjob)의 성격을 가집니다. (실무에서는 Apache Airflow 같은 배치 스케줄러를 통해
uv run analytics.py를 주기적으로 실행합니다.)
이상적인 최종 디렉토리 구조
따라서, 지금까지의 논의를 종합한 실무 수준의 최종 아키텍처 구조는 아래와 같이 정리됩니다.
community-board-log/ ├── docker-compose.yml <- 인프라 (DB, Redis 등) ├── database/ <- DB 스크립트 도메인 ├── proto/ <- gRPC 프로토콜 │ ├── log-engine/ <- [항상 실행] Rust 수집 엔진 (cargo run) │ ├── log-gateway/ <- [항상 실행] FastAPI 게이트웨이 (uvicorn) │ ├── main.py │ └── pyproject.toml │ └── log-analytics/ <- [주기적 실행] 데이터 분석 & ML 워커 (배치 스크립트) ├── main.py └── pyproject.toml <- pandas, scikit-learn 등 무거운 패키지는 이곳에만 격리이렇게 구성하면 시스템의 어느 한 곳에서 장애가 발생하더라도
메인 서비스에는 타격이 가지 않는 견고하고 우아한 아키텍처가 완성됩니다.
설정 파일
Python 게이트웨이를 작성할 디렉토리 및 파일을 생성한다.
~/workspace/community-board-log$ mkdir analytics && cd analytics ~/workspace/community-board-log/analytics$ uv init ~/workspace/community-board-log/analytics$ uv add pandas sqlalchemy psycopg2-binary scikit-learn python-dotenv matplotlib seaborn
의존성 파일은 자동으로 생성되며
설명 정도만 추가로 수정해 주면 된다.
analytics/pyproject.toml[project] name = "analytics" version = "0.1.0" description = "Time-Series Data Analysis and User Clustering for Action Logs" readme = "README.md" requires-python = ">=3.12" dependencies = [ "matplotlib>=3.10.9", "pandas>=3.0.3", "psycopg2-binary>=2.9.12", "python-dotenv>=1.2.2", "scikit-learn>=1.8.0", "seaborn>=0.13.2", "sqlalchemy>=2.0.49", ]
코드 작성
config.py
결과물이 저장될 output 디렉토리를 자동으로 생성하고
logger 를 초기화하는 코드를 작성한다.
analytics/config.pyimport os import logging from dotenv import load_dotenv OUTPUT_DIR = "output" os.makedirs(OUTPUT_DIR, exist_ok=True) def setup_logger(): logger = logging.getLogger("analytics_batch") logger.setLevel(logging.INFO) if not logger.handlers: # 콘솔 로그 console_handler = logging.StreamHandler() console_handler.setFormatter(logging.Formatter('%(message)s')) logger.addHandler(console_handler) # 파일 로그 file_handler = logging.FileHandler("analytics_batch.log") file_handler.setFormatter(logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')) logger.addHandler(file_handler) return logger logger = setup_logger() def get_db_url(): load_dotenv("../.env") db_url = os.getenv("DATABASE_URL") if db_url and db_url.startswith("postgres://"): db_url = db_url.replace("postgres://", "postgresql://", 1) return db_url
db.py
DB로부터 데이터를 추출하는 코드를 작성한다.
analytics/db.pyimport pandas as pd from sqlalchemy import create_engine from config import logger, get_db_url def fetch_data() -> pd.DataFrame: logger.info("환경 변수 로드 및 DB 연결 중...") db_url = get_db_url() if not db_url: logger.error("데이터베이스 접속 실패: DATABASE_URL 환경변수를 찾을 수 없음") return pd.DataFrame() try: logger.info("데이터 추출 중...") engine = create_engine(db_url) query = "SELECT user_id, action_type, created_at FROM action_logs" df = pd.read_sql(query, engine) if not df.empty: df['created_at'] = pd.to_datetime(df['created_at']) return df except Exception as e: logger.error(f"데이터베이스 연동/조회 실패: {e}") return pd.DataFrame()
analyzer.py
본격적인 분석을 수행하는 코드를 작성한다.
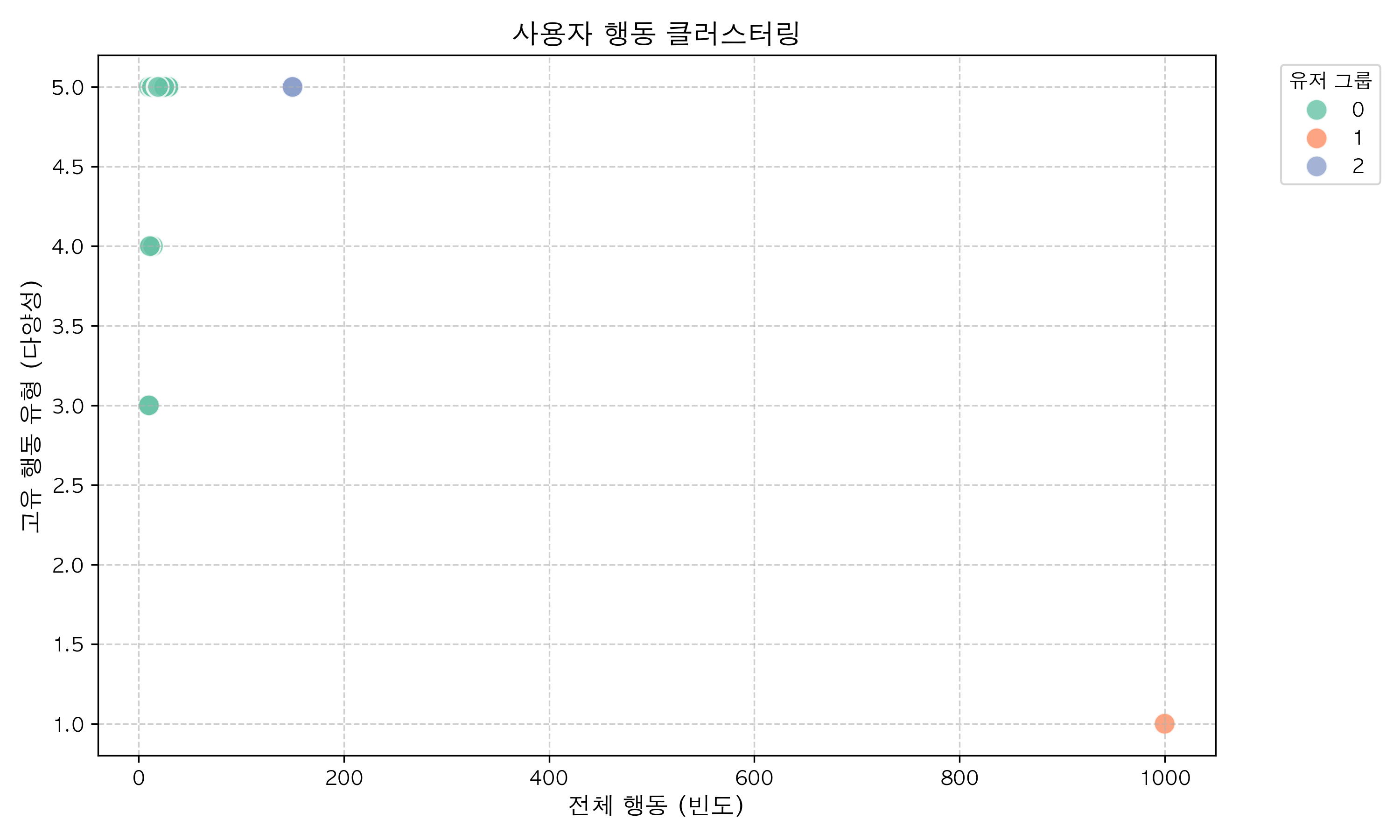
analytics/analyzer.pyimport pandas as pd from sklearn.cluster import KMeans from config import logger def analyze_traffic(df: pd.DataFrame) -> pd.DataFrame: """1분 단위 트래픽 리샘플링""" df_ts = df.set_index('created_at') traffic_per_minute = df_ts.resample('1min').size().reset_index(name='request_count') logger.info("최근 분당 트래픽 발생량:") logger.info(traffic_per_minute.tail().to_string()) return traffic_per_minute def cluster_users(df: pd.DataFrame) -> pd.DataFrame: """유저 행동 K-Means 군집화""" user_stats = df.groupby('user_id').agg( total_actions=('action_type', 'count'), # 활동량 unique_actions=('action_type', 'nunique') # 활동 다양성 ).reset_index() if len(user_stats) >= 3: features = user_stats[['total_actions', 'unique_actions']] kmeans = KMeans(n_clusters=3, random_state=42, n_init=10) user_stats['user_group'] = kmeans.fit_predict(features) logger.info("행동량 상위 5명의 K-Means 군집화:") logger.info(user_stats.sort_values(by='total_actions', ascending=False).head().to_string()) return user_stats else: logger.warning("시각화 실패: 유저 수가 3명 미만이라 군집화 수행 불가") return pd.DataFrame()
visualizer.py
시각화하고 파일로 저장하는 코드를 작성한다.
analytics/visualizer.pyimport os import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import platform from config import logger, OUTPUT_DIR if platform.system() == 'Darwin': plt.rc('font', family='AppleGothic') elif platform.system() == 'Windows': plt.rc('font', family='Malgun Gothic') else: plt.rc('font', family='NanumGothic') plt.rcParams['axes.unicode_minus'] = False def save_and_plot_traffic(traffic_df: pd.DataFrame): # CSV csv_path = os.path.join(OUTPUT_DIR, "traffic_trend.csv") traffic_df.to_csv(csv_path, index=False) logger.info(f"트래픽 집계 데이터 저장 완료: {csv_path}") # 시각화 plt.figure(figsize=(12, 5)) sns.lineplot( data=traffic_df, x='created_at', y='request_count', color='coral', linewidth=2, marker='o' ) plt.title("분당 행동 로그 트래픽 추세", fontsize=14, fontweight='bold') plt.xlabel("시간", fontsize=12) plt.ylabel("요청량", fontsize=12) plt.grid(True, linestyle='--', alpha=0.6) plt.xticks(rotation=45) plt.tight_layout() img_path = os.path.join(OUTPUT_DIR, "traffic_trend.png") plt.savefig(img_path, dpi=300) logger.info(f"트래픽 추이 시각화 저장 완료: {img_path}") plt.clf() def save_and_plot_clusters(user_stats_df: pd.DataFrame): if user_stats_df.empty: return # CSV csv_path = os.path.join(OUTPUT_DIR, "user_clusters.csv") user_stats_df.to_csv(csv_path, index=False) logger.info(f"유저 행동 정형 데이터 저장 완료: {csv_path}") # 시각화 plt.figure(figsize=(10, 6)) sns.scatterplot( data=user_stats_df, x='total_actions', y='unique_actions', hue='user_group', palette='Set2', s=120, alpha=0.8, ) plt.title("사용자 행동 클러스터링", fontsize=14, fontweight='bold') plt.xlabel("전체 행동 (빈도)", fontsize=12) plt.ylabel("고유 행동 유형 (다양성)", fontsize=12) plt.grid(True, linestyle='--', alpha=0.6) plt.legend(title="유저 그룹", bbox_to_anchor=(1.05, 1), loc="upper left") plt.tight_layout() img_path = os.path.join(OUTPUT_DIR, "user_clusters.png") plt.savefig(img_path, dpi=300) logger.info(f"유저 행동 클러스터링 시각화 저장 완료: {img_path}") plt.clf()
main.py
모듈화된 함수들을 불러와 직관적인 순서대로 실행하는 코드를 작성한다.
analytics/main.pyimport warnings from config import logger from db import fetch_data from analyzer import analyze_traffic, cluster_users from visualizer import save_and_plot_traffic, save_and_plot_clusters # 버전에 대한 Scikit-learn 경고 무시 warnings.filterwarnings('ignore', category=FutureWarning) def main(): logger.info("데이터 분석 파이프라인 시작...") # 환경변수 로드 및 DB 연결 df = fetch_data() if df.empty: logger.warning("분석 실패: 분석할 데이터가 없음") return logger.info(f"데이터 분석 준비 완료: 총 {len(df)} 건의 로그 데이터") logger.info("시계열 트래픽 추이 분석 중...") traffic_df = analyze_traffic(df) save_and_plot_traffic(traffic_df) logger.info("유저 행동 군집화 분석 중...") user_stats_df = cluster_users(df) save_and_plot_clusters(user_stats_df) logger.info("모든 분석 파이프라인 완료: 'output/' 디렉토리에 결과 저장") if __name__ == "__main__": main()
실행 및 테스트
데이터 생성 스크립트
테스트용 데이터를 만드는 스크립트를 작성한다.
~/workspace/community-board-log$ mkdir load-test && cd load-test ~/workspace/community-board-log/load-test$ uv init ~/workspace/community-board-log/load-test$ uv add httpx
load-test/pyproject.toml[project] name = "load-tester" version = "0.1.0" description = "Traffic Generator & Load Tester for Action Logs" readme = "README.md" requires-python = ">=3.12" dependencies = [ "httpx>=0.28.1", ]
main.py 를 제거하고 traffic_generator.py 파일을 생성한다.
테스트 코드니까 AI가 작성한 스크립트를 그대로 사용하겠다.
load-tester/traffic_generator.pyimport asyncio import httpx import random import time API_URL = "http://127.0.0.1:8000/api/v1/logs" NORMAL_ACTIONS = ["VIEW_POST", "LIKE_POST", "WRITE_COMMENT", "LOGIN", "SHARE"] # 🚀 핵심 추가: 동시 접속 제어기 (한 번에 200개의 티켓만 발급) # 이 숫자를 늘리면 더 강하게 때리고, 줄이면 안정적으로 때립니다. MAX_CONCURRENT_REQUESTS = 200 semaphore = asyncio.Semaphore(MAX_CONCURRENT_REQUESTS) async def send_logs(client: httpx.AsyncClient, user_id: str, count: int, is_bot: bool = False): # 세마포어 티켓을 쥐었을 때만 HTTP 요청을 보내는 래퍼 함수 async def bounded_post(payload): async with semaphore: return await client.post(API_URL, json=payload) tasks = [] for _ in range(count): action = "LIKE_POST" if is_bot else random.choice(NORMAL_ACTIONS) target = f"post_{random.randint(1, 100)}" payload = { "user_id": user_id, "action_type": action, "target_id": target } # client.post 대신 래퍼 함수를 task에 담습니다. tasks.append(bounded_post(payload)) await asyncio.gather(*tasks) print(f"[{user_id}] 로그 {count}건 전송 완료 (Bot: {is_bot})") async def main(): start_time = time.time() # timeout은 무제한으로 두고, limits도 넉넉하게 유지합니다. timeout_config = httpx.Timeout(None) limits_config = httpx.Limits(max_connections=3000, max_keepalive_connections=3000) async with httpx.AsyncClient(limits=limits_config, timeout=timeout_config) as client: print("🚀 트래픽 생성 시작... (유량 제어 적용됨)") bot_task = send_logs(client, "macro_bot_999", 1000, is_bot=True) heavy_tasks = [send_logs(client, f"heavy_user_{i}", 150) for i in range(5)] normal_tasks = [send_logs(client, f"normal_user_{i}", random.randint(10, 30)) for i in range(20)] await asyncio.gather(bot_task, *heavy_tasks, *normal_tasks) elapsed = time.time() - start_time print(f"\n✅ 모든 트래픽 전송 완료! (소요 시간: {elapsed:.2f}초)") if __name__ == "__main__": asyncio.run(main())
테스트
Rust 엔진과 Python 게이트웨이가 실행되고 있는 상태에서
테스트 데이터를 생성하고 분석 및 시각화를 수행한다.
기존에 들어갔던 테스트 데이터는 제거하고 진행하겠다.
~/workspace/community-board-log/load-test$ docker exec -it log_db psql -U admin -d log_db -c "TRUNCATE TABLE action_logs;" ~/workspace/community-board-log/load-test$ uv run traffic_generator.py 🚀 트래픽 생성 시작... (유량 제어 적용됨) [normal_user_0] 로그 10건 전송 완료 (Bot: False) [heavy_user_2] 로그 150건 전송 완료 (Bot: False) [macro_bot_999] 로그 1000건 전송 완료 (Bot: True) [normal_user_13] 로그 11건 전송 완료 (Bot: False) [heavy_user_4] 로그 150건 전송 완료 (Bot: False) [normal_user_14] 로그 13건 전송 완료 (Bot: False) [normal_user_5] 로그 11건 전송 완료 (Bot: False) [normal_user_8] 로그 25건 전송 완료 (Bot: False) [normal_user_6] 로그 29건 전송 완료 (Bot: False) [normal_user_2] 로그 22건 전송 완료 (Bot: False) [normal_user_1] 로그 26건 전송 완료 (Bot: False) [normal_user_18] 로그 18건 전송 완료 (Bot: False) [heavy_user_0] 로그 150건 전송 완료 (Bot: False) [normal_user_3] 로그 21건 전송 완료 (Bot: False) [normal_user_17] 로그 26건 전송 완료 (Bot: False) [normal_user_15] 로그 14건 전송 완료 (Bot: False) [normal_user_12] 로그 22건 전송 완료 (Bot: False) [normal_user_16] 로그 25건 전송 완료 (Bot: False) [normal_user_7] 로그 10건 전송 완료 (Bot: False) [normal_user_10] 로그 10건 전송 완료 (Bot: False) [normal_user_4] 로그 23건 전송 완료 (Bot: False) [normal_user_19] 로그 30건 전송 완료 (Bot: False) [heavy_user_3] 로그 150건 전송 완료 (Bot: False) [normal_user_11] 로그 21건 전송 완료 (Bot: False) [normal_user_9] 로그 19건 전송 완료 (Bot: False) [heavy_user_1] 로그 150건 전송 완료 (Bot: False) ✅ 모든 트래픽 전송 완료! (소요 시간: 9.08초)
그 때 Rust 엔진은
{"timestamp":"2026-05-20T04:37:50.740149Z","level":"INFO","fields":{"message":"로그 202개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:51.702104Z","level":"INFO","fields":{"message":"로그 30개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:52.702255Z","level":"INFO","fields":{"message":"로그 31개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:53.703190Z","level":"INFO","fields":{"message":"로그 31개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:54.702032Z","level":"INFO","fields":{"message":"로그 28개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:55.704257Z","level":"INFO","fields":{"message":"로그 510개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:56.703573Z","level":"INFO","fields":{"message":"로그 421개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:57.705210Z","level":"INFO","fields":{"message":"로그 454개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:58.703649Z","level":"INFO","fields":{"message":"로그 414개 성공적으로 삽입 완료"},"target":"log_engine::worker"} {"timestamp":"2026-05-20T04:37:59.703022Z","level":"INFO","fields":{"message":"로그 15개 성공적으로 삽입 완료"},"target":"log_engine::worker"}
그리고 데이터 분석
~/workspace/community-board-log/analytics$ uv run main.py 데이터 분석 파이프라인 시작... 환경 변수 로드 및 DB 연결 중... 데이터 추출 중... 데이터 분석 준비 완료: 총 2136 건의 로그 데이터 시계열 트래픽 추이 분석 중... 최근 분당 트래픽 발생량: created_at request_count 0 2026-05-20 04:37:00+00:00 2136 트래픽 집계 데이터 저장 완료: output/traffic_trend.csv 트래픽 추이 시각화 저장 완료: output/traffic_trend.png 유저 행동 군집화 분석 중... 행동량 상위 5명의 K-Means 군집화: user_id total_actions unique_actions user_group 5 macro_bot_999 1000 1 1 0 heavy_user_0 150 5 2 2 heavy_user_2 150 5 2 3 heavy_user_3 150 5 2 4 heavy_user_4 150 5 2 유저 행동 정형 데이터 저장 완료: output/user_clusters.csv 유저 행동 클러스터링 시각화 저장 완료: output/user_clusters.png 모든 분석 파이프라인 완료: 'output/' 디렉토리에 결과 저장
다음과 같은 시각화를 확인할 수 있다.