🪸 객체지향언어
객체 지향 프로그래밍 이란?
현실 세계에서 제품을 만들 때, 각각의 부품을 만들고나서 하나씩 조립하여 완성된 제품을 만들게 됩니다. 자동차를 만들 때 자동차에 들어가는 부품들 - 타이어, 차틀, 엔진, 핸들, … 등의 부품들을 조립하여 최종적으로 만들겠죠. 이때 각각의 부품들을 자바에서는 ‘객체’ 라고 표현합니다. 부품(객체)들을 먼저 만들고, 이것들을 하나씩 조립하여 완성된 프로그램을 개발하는 기법이 바로 객체 지향 프로그래밍(OOP: Object Oriented Programming)이라고 합니다. 객체 지향 프로그래밍을 이해하기 위해서는 객체에 대한 이해와 객체와의 상호작용에 대해 알아야합니다.
여러분이 계산기를 이용하여 연산을 한다고 생각해봅시다. 계산기에 숫자 5를 입력하고 + 기호를 입력한 후 4를 입력하면 결과값으로 9을 보여 주겠죠. 다시 한번 + 기호를 입력한 후 3을 입력하면 기존 결과값 9에 3을 더해 12를 보여줄겁니다. 즉 계산기는 이전에 계산한 결과값을 항상 메모리 어딘가에 저장하고 있어야 합니다.
이 내용을 자바로 구현해보겠습니다.
class Calculator {
static int result = 0;
static int add(int num) {
result += num;
return result;
}
}
public class Sample {
public static void main(String[] args) {
System.out.println(Calculator.add(5));
System.out.println(Calculator.add(4));
}
}다음과 같은 결과가 나오겠죠
5
9그런데 만일 Sample 클래스에서 2대의 계산기가 필요한 상황이 발생하면? Calculator 클래스 각각의 계산기는 각각의 결과값 만을 갖기 때문에, 클래스 하나만으로는 결과값을 따로 유지할 수 없습니다. 이런 상황을 해결하려면 다음과 같이 클래스를 각각 따로 만들어야겠죠.
class Calculator1 {
static int result = 0;
static int add(int num) {
result += num;
return result;
}
}
class Calculator2 {
static int result = 0;
static int add(int num) {
result += num;
return result;
}
}
public class Sample {
public static void main(String[] args) {
System.out.println(Calculator1.add(5));
System.out.println(Calculator1.add(4));
System.out.println(Calculator2.add(1));
System.out.println(Calculator2.add(10));
}
}5
9
1
11Calculator1과 Calculator2 모두 원하는 결과를 출력해주었습니다. 하지만, 매번 이렇게 Calculator가 필요할 때 마다 똑같은 코드(클래스)를 작성할 수는 없습니다. 또한, 지금은 add 덧셈 기능만 있지만 빼기, 나누기, 곱하기 등의 다양한 연산이 필요할 수도 있겠죠. 이럴 경우에는 중복되는 코드가 더 늘어나게 됩니다.
이와 같은 문제를 해결하기 위해 객체를 사용한다면, 다음과 같이 해결할 수 있습니다.
class Calculator {
int result = 0;
int add(int num) {
result += num;
return result;
}
}
public class Sample {
public static void main(String[] args) {
Calculator cal1 = new Calculator(); // 계산기1 객체를 생성한다.
Calculator cal2 = new Calculator(); // 계산기2 객체를 생성한다.
System.out.println(cal1.add(5));
System.out.println(cal1.add(4));
System.out.println(cal2.add(1));
System.out.println(cal2.add(10));
}
}5
9
1
11하나의 Calculator클래스 안에서 클래스 2개를 사용했을 때와 같은 결과를 출력합니다.
Calculator 클래스로 만든 별도의 계산기 2개 (cal1, cal2)를 바로 객체라고 부릅니다. cal1, cal2 객체가 각각의 역할을 수행합니다. 그리고 계산기의 결과값 역시 다른 계산기의 결과값과 상관없이 독립적인 값을 유지합니다. 객체를 사용하면 계산기 수가 늘어나더라도 객체를 생성만 하면 되기 때문에 앞의 경우와는 달리 매우 간단해집니다.
만약 곱셈 기능을 추가하려면 다음과 같이 구현할 수 있습니다. 계산기 객체의 행위, 즉 ‘곱셈’이라는 행위를 메소드로 정의할 수 있죠.
class Calculator {
int result = 0;
int add(int num) {
result += num;
return result;
}
int multiple(int num) {
result *= num;
return result;
}
}객체 지향 프로그래밍의 특징
캡슐화
캡슐화란 클래스 안에 서로 연관있는 속성과 기능들을 하나의 캡슐로 만들어 데이터를 외부로부터 보호하는 것을 말합니다. 자바에서 이렇게 캡슐화를 하는 이유는 다음과 같습니다.
- 데이터 보호 - 외부로부터 클래스에 정의된 속성과 기능들을 보호
- 데이터 은닉 - 내부의 동작을 감추고 외부에는 필요한 부분만 노출
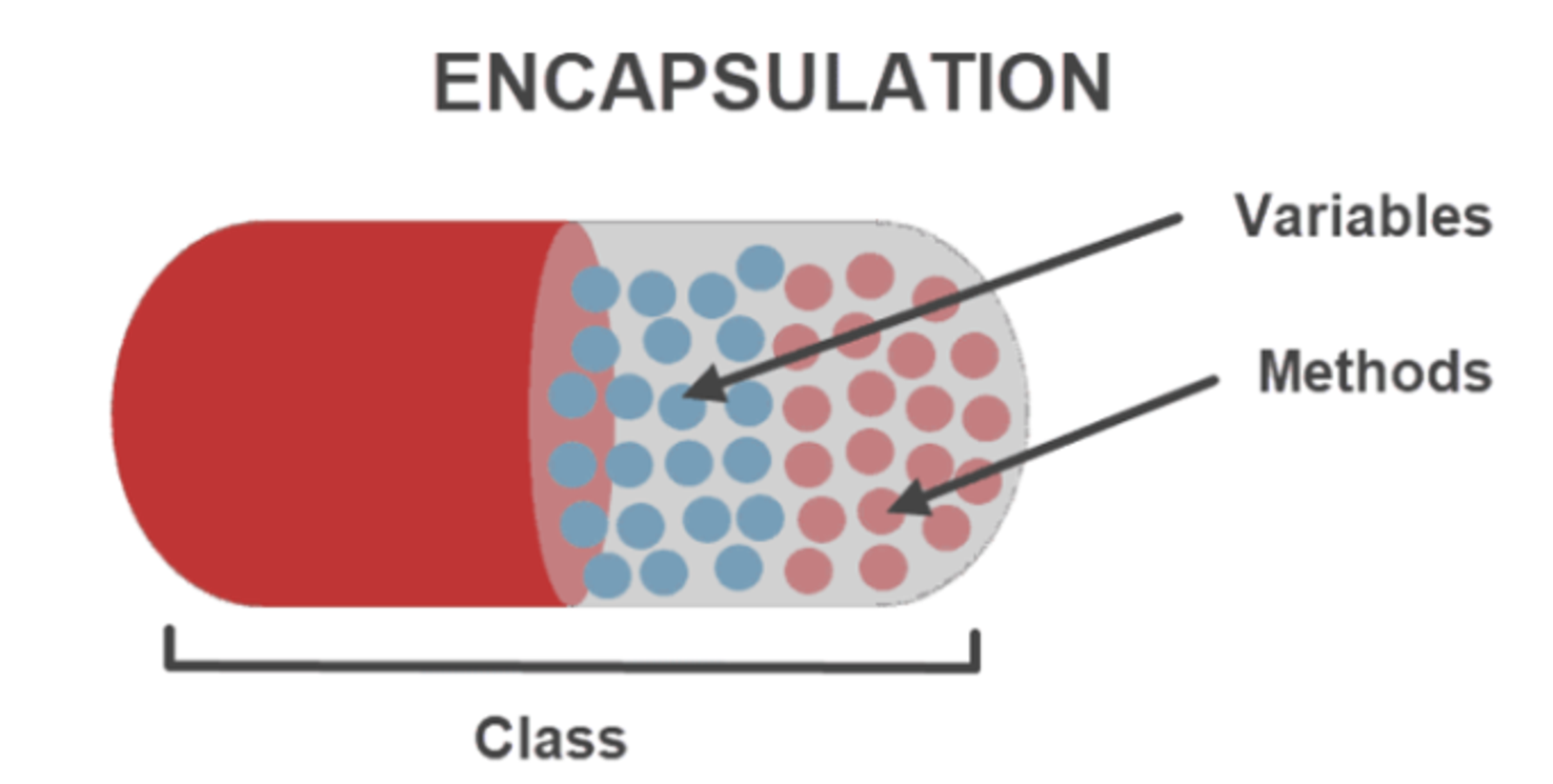
캡슐화를 구현하기 위한 방법 중에 하나는 접근제어자를 활용하는 것입니다.
다형성
다형성이란 어떤 객체의 속성이나 기능이 상황에 따라 여러가지 형태를 가질 수 있는 성질을 말합니다. 비유적으로 표현하자면, 어떤 중년 남성이 있다고 가정했을 때 그 남성의 역할이 아내에게는 남편, 회사에서는 회사원, 부모님에게는 자식 등 상황과 환경에 따라 달라지는 것과 비슷하다고 할 수 있습니다.
이동수단을 예시로 들어봅시다. 이동수단은 자동차가 될수도, 오토바이가 될 수도 있죠. 다르게 표현하면 ‘자동차는 자동차다’ , ‘자동차는 이동 수단이다’ 라는 명제는 모두 참입니다. 이동수단이라는 범위 안에 자동차와 오토바이를 하나로 묶을 수 있게 됩니다.
객체지향 프로그래밍에서 다형성이란 앞서 설명한 이동수단과 같은 넓은 범위의 타입, 즉 상위 클래스 타입의 참조 변수로 그것과 관계있는 하위 클래스들을 참조할 수 있는 능력입니다.
🪼 클래스와 객체
먼저 클래스와 객체를 각각 이해해볼까요?
| 클래스 | 객체 |
|---|---|
| 제품 설계도 | 실제 제품 |
| 붕어빵 틀 | 붕어빵 |
| 자동차 설계도 | 실제 자동차 |
클래스란 객체의 특징(속성, 기능)을 정해놓은 ‘제품 설계도’같은 것이고, 객체는 실제로 존재하는 제품을 말합니다.
그렇기 때문에 객체를 생성할 때 클래스가 필요한 것이죠.
클래스에는 객체의 특징을 표현해놓는데, ‘속성’과 ‘기능’을 정의해놓을 수 있습니다.
여기서 말하는 속성은 “필드”에 정의할 수 있고, 기능은 “메서드”에 정의할 수 있죠.
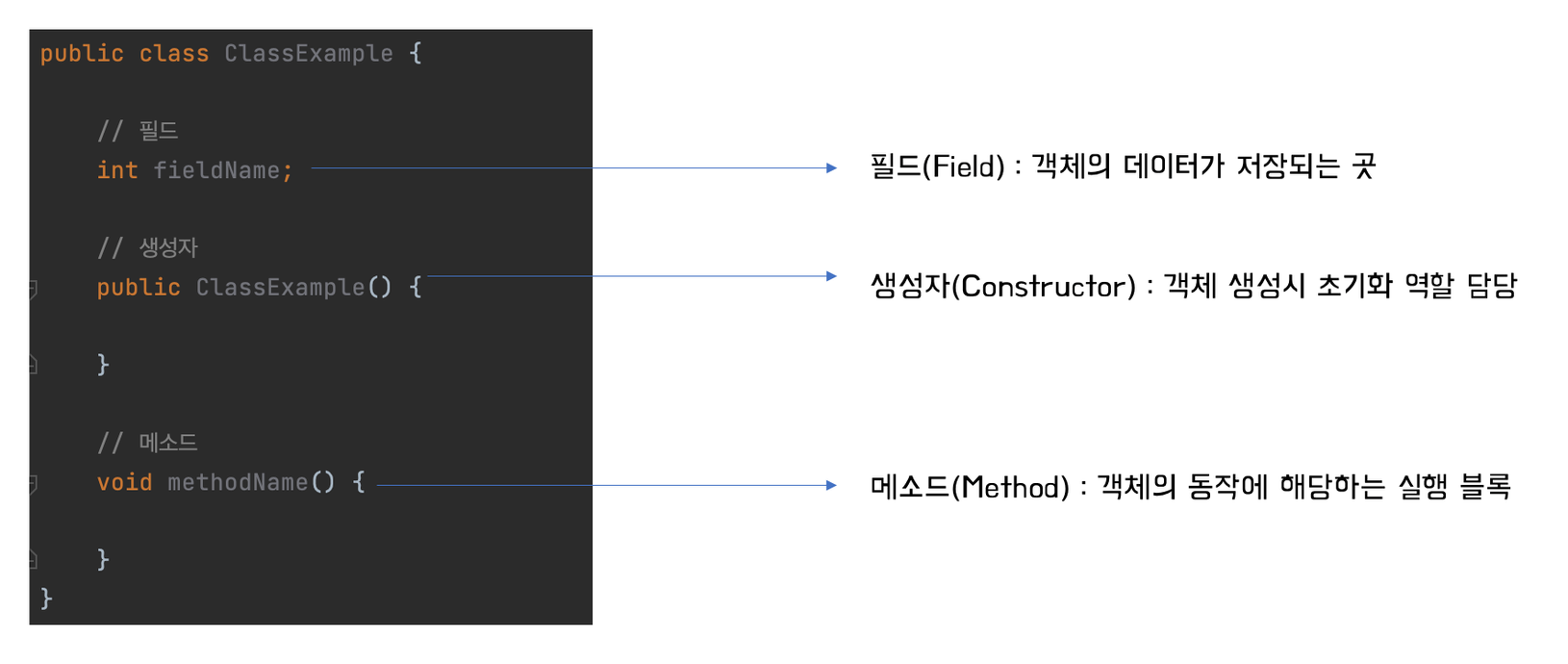
이번에는 클래스와 객체를 선언하는 방법을 알아보겠습니다.
사용하고자 하는 객체를 구상했다면, 그 객체의 대표 이름을 하나 결정하고 이것을 클래스 이름으로 합니다. 예를 들어 사람 객체의 클래스는 Person으로, 자동차 객체의 클래스는 Car 이라는 이름을 줄 수 있을 것입니다.
클래스 이름을 지을 때 다음과 같은 식별자 작성 규칙에 따라서 만들어야 합니다.
| 작성 규칙 | 예시 |
|---|---|
| 하나 이상의 문자로 이루어져야 한다. | Car, SportsCar |
| 첫 번째 글자는 숫자가 올 수 없다. | 3Car (x) |
| $ _ 외의 특수문자는 사용할 수 없다. | $Car, _Car, @Car (x), #Car (x) |
| 자바 키워드는 사용할 수 없다. | int (x), for (x) |
이제 클래스를 직접 선언해보겠습니다. 자동차 객체를 만들 생각으로 클래스를 만들어보겠습니다.
public class Car {
}위 코드는 가장 간단한 형태의 클래스 선언문입니다. 클래스의 선언만 있고 내용이 없는 껍데기뿐인 클래스인데, 이 껍데기뿐인 클래스도 아주 중요한 기능을 가지고 있습니다. 바로 객체를 생성할 수 있는 기능이죠.
여기서 public class 키워드는 클래스를 선언할 때 사용하는데, 반드시 소문자로 작성해야 합니다. 클래스 뒤에는 반드시 중괄호 { }를 붙여주는데, 중괄호 시작{은 클래스 선언의 시작을 알려주고 중괄호 끝}은 클래스 선언의 끝을 알려줍니다.
이제 클래스를 이용하여 main 에서 객체를 생성해주는 코드를 작성해보겠습니다.
public class Car {
public static void main(String[] args) {
Car car = new Car(); // car 객체 생성
}
}위 코드에서 new는 객체를 생성할 때 사용하는 키워드입니다. 이렇게 선언하면 Car 클래스의 인스턴스(instance)인 car 객체가 만들어집니다.
다양하고 무수히 많은 자동차 객체(sonata, avante, ferrari, …)들을 만들기 위해 코드를 작성해보겠습니다.
Car sonata = new Car();
Car avante = new Car();
Car ferrari = new Car();위에서 언급한 붕어빵 틀과 붕어빵과의 관계 같은, 클래스와 객체의 관계가 이해되었다면 다음 문제를 풀어봅시다.
오늘의 Quiz!
객체와 클래스에 대한 설명으로 틀린 것은?
- 클래스는 객체를 생성하기 위한 설계도(청사진)와 같은 것이다.
- new 연산자로 클래스의 생성자를 호출함으로써 객체가 생성된다.
- 하나의 클래스로 하나의 객체만 생성할 수 있다.
- 객체는 클래스의 인스턴스이다.
🦆 클래스의 구성 멤버 살피기(필드, 생성자, 메소드)
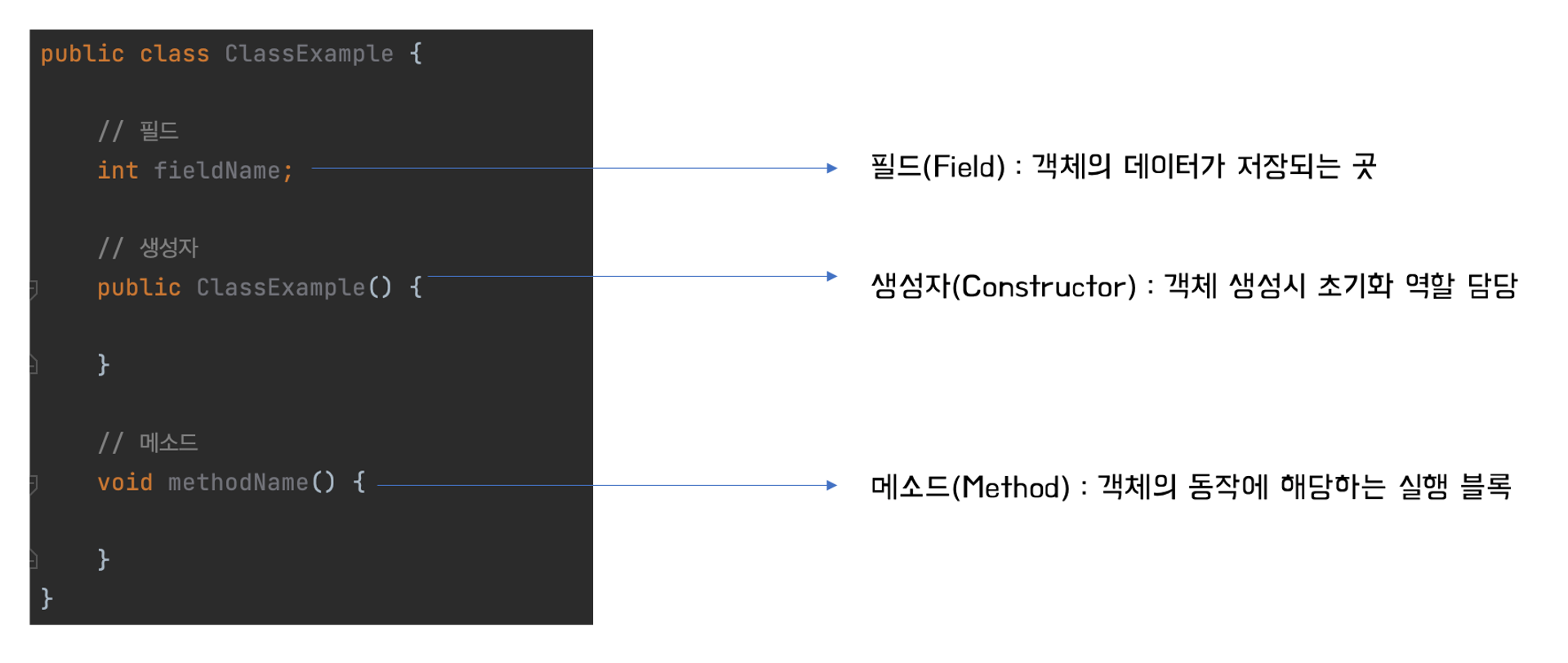
위에서 본 사진을 다시 가져와 설명해보겠습니다.
필드(멤버변수)
필드는 객체의 고유 데이터가 저장되는 곳 입니다. 선언 형태는 앞장에서 배웠던 변수(variable)와 비슷하고 클래스 전역에서 사용될 수 있으며 객체가 소멸되지 않는 한 객체와 함께 존재하는 변수입니다.
6.2 클래스와 객체 에서 작성해보았던 Car 라는 껍데기 클래스를 조금 더 발전시켜봅시다.
public class Car {
String company;
public static void main(String[] args) {
Car car = new Car();
}
}Car 클래스에 company 라는 변수를 추가했습니다. 이처럼 클래스에 선언된 변수를 멤버 변수 혹은 필드라고 합니다. 클래스에 의해 생성되는 것은 객체, 그리고 그 클래스에 선언된 변수는 멤버 변수라고 생각하면 쉽습니다. 이제부터는 필드 라는 용어로 통일하도록 하겠습니다.
위에서 company라는 객체 변수를 만들었으니 사용해보겠습니다.
먼저, 필드를 출력하기위해서는 어떻게 접근하는지를 먼저 알아야합니다. 다음과 같이 사용하여 접근할 수 있습니다.
객체.필드여기서 도트 연산자(.)는 객체가 가지고 있는 필드나 메소드를 사용하고자 할 때 사용됩니다.
도트 연산자를 사용한다면 아래 코드처럼 필드에 접근하여 출력할 수 있겠죠.
public class Car {
String company;
public static void main(String[] args) {
Car car = new Car();
System.out.println(car.company);
}
}여기서 car는 객체, company는 필드인 것 확인하고. 결과를 보겠습니다.
nullcar.company를 출력한 결과값으로 null 값이 나왔네요. null은 값이 할당되지 않은 상태를 말합니다. 필드로 company를 선언했지만, 아무런 값도 대입하지 않았기 때문에 null이라는 값이 출력된 것 입니다.
그러면 이 필드값을 변경해보겠습니다.
public class Car {
String company = "현대자동차";
public static void main(String[] args) {
Car car = new Car();
System.out.println(car.company);
}
}Car 객체의 company 필드값을 “현대자동차”로 초기화 했습니다.
디폴트 생성자
6.3.2.1 예시에서 봤던 코드중에 입력인수를 받는 생성자도 있었고, 입력인수를 받지 않는 생성자도 있었습니다.
public class Car {
String company;
//1
Car() {
}
//2
Car(String company) {
...
}
}1번 생성자와 2번 생성자의 차이점이 보이시나요? 1번 생성자와같이, 생성자의 입력 항목이 없고 생성자 내부에 아무런 내용이 없는 생성자를 디폴트 생성자 라고 부릅니다. 디폴트 생성자를 구현하면 new Car()로 Car 클래스의 객체가 만들어질 때 디폴트 생성자 Car()이 실행될 것 입니다.
만약 클래스에 생성자가 하나도 없다면, 컴파일러는 자동으로 디폴트 생성자를 추가합니다. 하지만 사용자가 작성한 생성자가 하나라도 구현되어 있다면 컴파일러는 디폴트 생성자를 추가하지 않습니다.
생성자 오버로딩
오버로딩이란, 클래스 내에 같은 이름의 함수를 여러개 선언하는 것을 말합니다. 오버로딩의 사전적 의미는 ‘많이 싣는 것’을 뜻하는데 하나의 메소드(혹은 생성자) 이름으로 여러 기능을 담는다 하여 붙여진 이름이라고 할 수 있습니다.
메소드와 생성자 모두 오버로딩을 사용할 수 있는데 우선 생성자 오버로딩은 다음과 같이 입력 항목이 다른 생성자를 만들 수 있습니다.
public class Car {
String company;
String model;
int maxSpeed;
//1번 생성자
Car(String company) {
this.company = company;
}
//2번 생성자
Car(String company, String model) {
this.company = company;
this.model = model;
}
//3번 생성자
Car(String company, String model, int maxSpeed) {
this.company = company;
this.model = model;
this.maxSpeed = maxSpeed;
}
}public class CarExample {
public static void main(String[] args) {
Car sonata = new Car("현대"); // 1번 생성자 이용
Car sportage = new Car("기아", "sportage"); // 2번 생성자 이용
Car gv80 = new Car("제네시스", "gv80", 300); // 3번 생성자 이용
}
}메소드
다른 프로그램 언어에는 함수가 별도로 존재하지만, 자바에서는 클래스 내에 함수가 있는데, 이것을 메서드라고 합니다.

한가지 더 예를들어볼까요. 믹서기를 떠올려봅시다. 우리는 주스를 만들기위해 믹서에 과일을 넣고, 믹서를 이용해 과일을 갈아 주스를 만들어냅니다.
우리가 믹서에 넣는 과일은 입력(input), 만들어진 결과물 주스는 출력(output)에 비유할 수 있습니다. 그럼 믹서기는? 믹서기가 바로 메서드 입니다. 입력값을 가지고 어떤 일을 수행한 다음 결과값을 내어놓는 것이 바로 메서드가 하는 일입니다.

6.3.1 필드(멤버변수) 에서 필드라는 개념을 배웠는데, 이 필드의 값을 할당하거나 필드의 동작을 정의하는 것은 메소드 블록 안에서 처리해줄 수 있습니다.
메소드 이용 방법
필드에 값을 대입하는 방법에는 여러 가지가 있지만 여기서는 메소드를 이용하는 방법에 대해서 알아보려고 합니다. 클래스에는 필드와 함께 메서드가 있습니다. 메서드(method)는 클래스 내에 구현된 함수를 말합니다.
이제 메서드를 이용하여 Car 클래스의 필드인 model에 값을 대입해 봅시다. 다음과 같이 setModel 메서드를 추가해 봅시다.
public class Car {
String model
void setModel(String model) {
this.model = model
}
}public class CarExample {
public static void main(String[] args) {
Car sonata = new Car();
sonata.setModel("sonata"); // model 필드의 값을 대입
}
}Car 클래스에 추가된 setModel 메서드는 다음과 같은 형태의 메서드입니다.
- 입력: String model
- 출력: void (‘리턴값 없음’을 의미)
즉, 입력으로 model이라는 문자열을 받고 출력은 없는 형태의 메서드입니다.
메소드 선언
메소드 선언은 선언부와 실행블록으로 구성됩니다.
리턴타입 메소드이름([매개변수 선언, ...]) { // 선언부
// 실행블록
}리턴(return)문
메소드 선언부의 맨 첫번째에 위치한 리턴타입은 메소드가 실행하고 리턴하는 값의 타입을 말합니다. 메소드는 리턴값이 있을 수도, 없을 수도 있는데, 메소드가 실행된 다음 결과를 호출한 곳에 넘겨줄 경우에는 리턴값이 있어야 합니다.
void powerOn() {
System.out.println("전원을 켭니다"); // void 리턴타입: 리턴타입이 없을경우
}
double divide(int x, int y) {
return x / y;
}위 divide 메소드는 다음과 같이 정의됩니다.
divide 메서드는 입력값으로 두개의 값(int 자료형 x, int 자료형 y)을 받으며
리턴값은 두 개의 입력값을 더한 값(double 자료형)이다.여기서 return은 메서드의 결과값을 돌려주는 명령어입니다.
그럼 위의 두 메소드 powerOn, divide를 호출해보겠습니다. 다음과 같이 호출할 수 있습니다.
powerOn();
double result = divide(10, 20);여기에서 powerOn 메소드는 리턴값이 없기 때문에 변수에 저장할 내용이 없습니다. 그러나 divide 메소드는 10을 20으로 나누고 0.5를 리턴하므로 이것을 저장할 변수가 있어야합니다. 리턴 받기 위해 변수는 메소드의 리턴타입인 double타입으로 선언했습니다.
만약 divide 메소드의 리턴타입을 int라고 선언한다면 double 값을 저장할 수 없기 때문에 컴파일 에러가 발생합니다.
그리고 리턴 타입이 있다고 해서 반드시 리턴값을 변수에 저장할 필요는 없습니다. 만약 리턴값이 중요하지 않고 메소드 실행이 중요할 경우에는 다음과 같이 변수 선언 없이 메소드를 호출할 수도 있습니다.
divice(10, 20);매개 변수와 인수
매개 변수(parameter)와 인수(arguments)는 혼용되는 헷갈리는 용어이므로 잘 기억해 둡시다. 매개 변수는 메소드에 전달된 입력값을 저장하는 변수를 의미하고, 인수는 메서드를 호출할 때 전달하는 입력값을 의미합니다.
public class Calculator {
double divide(int x, int y) { // x, y는 매개변수
return x / y;
}
public static void main(String[] args) {
Calculator calculator = new Calculator();
calculator.divide(10, 20); // 10, 20은 인수
}
}메서드 내에서 선언된 변수의 효력 범위
메소드 안에서 사용하는 변수의 이름을 메소드 밖에서 사용한 이름과 동일하게 사용한다면 어떻게 될까요? 다음 예제를 풀어봅시다.
public class Calculator {
void postfixOperator(int a) {
a++;
}
public static void main(String[] args) {
int a = 1;
Calculator calculator = new Calculator();
calculator.postfixOperator(a);
System.out.println(a);
}
}a값을 출력했을 때 어떤 값이 나오는지 풀어보셨나요?
그럼 풀이를 해봅시다.
이 예제의 postfixOperator 메소드는 입력으로 들어온 int 자료형의 값을 1만큼 증가시키는 역할을 합니다. main 메소드를 순서대로 분석해 보면
- main 메소드에서 a라는 int 자료형의 변수를 생성하고 a를 1로 초기화.
- postfixOperator 메소드의 인자값으로 a를 주고 호출.
- a의 값을 출력.
postfixOperator 메소드에서 a의 값을 1만큼 증가시켰으니 2가 출력되어야 할 것 같지만 막상 프로그램을 실행해 보면 1이라는 결과값이 나옵니다. 왜 그럴까요? 그 이유는 메소드에서 사용한 매개변수는 메소드 안에서만 쓰이는 변수이기 때문입니다. 즉 void postfixOperator(int a)라는 문장에서 매개 변수 a는 메소드 안에서만 쓰이는 변수이지 메소드 밖의 변수 a가 아니라는 말입니다.
다시 말해 메소드에서 쓰이는 매개 변수의 이름과 메소드 밖의 변수 이름이 같더라도 서로 전혀 영향을 주지 않습니다.
그렇다면 postfixOperator 메소드를 이용해서 main 메소드 외부의 a의 값을 1만큼 증가시킬 수 있는 방법은 없을까요? 다음과 같이 postfixOperator 메서드와 main 메소드를 변경해 봅시다.
public class Calculator {
int postfixOperator(int a) {
a++;
return a;
}
public static void main(String[] args) {
int a = 1;
Calculator calculator = new Calculator();
a = calculator.postfixOperator(a);
System.out.println(a);
}
}결과가 어떻게 나올지 예상하셨나요?
a의 값을 postfixOperator 메소드를 이용하여 1만큼 증가시켰고, 증가시킨 값을 리턴해서 main메소드에서 받아와 출력했습니다. 이전 코드와는 다르게 값이 증가되었겠죠.
요렇게 참조형으로 작성한 메소드입니다.
메서드 내에서 선언된 변수의 효력 범위
메소드 안에서 사용하는 변수의 이름을 메소드 밖에서 사용한 이름과 동일하게 사용한다면 어떻게 될까요? 다음 예제를 풀어봅시다.
public class Calculator {
void postfixOperator(int a) {
a++;
}
public static void main(String[] args) {
int a = 1;
Calculator calculator = new Calculator();
calculator.postfixOperator(a);
System.out.println(a);
}
}a값을 출력했을 때 어떤 값이 나오는지 풀어보셨나요?
그럼 풀이를 해봅시다.
이 예제의 postfixOperator 메소드는 입력으로 들어온 int 자료형의 값을 1만큼 증가시키는 역할을 합니다. main 메소드를 순서대로 분석해 보면
- main 메소드에서 a라는 int 자료형의 변수를 생성하고 a를 1로 초기화.
- postfixOperator 메소드의 인자값으로 a를 주고 호출.
- a의 값을 출력.
postfixOperator 메소드에서 a의 값을 1만큼 증가시켰으니 2가 출력되어야 할 것 같지만 막상 프로그램을 실행해 보면 1이라는 결과값이 나옵니다. 왜 그럴까요? 그 이유는 메소드에서 사용한 매개변수는 메소드 안에서만 쓰이는 변수이기 때문입니다. 즉 void postfixOperator(int a)라는 문장에서 매개 변수 a는 메소드 안에서만 쓰이는 변수이지 메소드 밖의 변수 a가 아니라는 말입니다.
다시 말해 메소드에서 쓰이는 매개 변수의 이름과 메소드 밖의 변수 이름이 같더라도 서로 전혀 영향을 주지 않습니다.
그렇다면 postfixOperator 메소드를 이용해서 main 메소드 외부의 a의 값을 1만큼 증가시킬 수 있는 방법은 없을까요? 다음과 같이 postfixOperator 메서드와 main 메소드를 변경해 봅시다.
public class Calculator {
int postfixOperator(int a) {
a++;
return a;
}
public static void main(String[] args) {
int a = 1;
Calculator calculator = new Calculator();
a = calculator.postfixOperator(a);
System.out.println(a);
}
}결과가 어떻게 나올지 예상하셨나요?
a의 값을 postfixOperator 메소드를 이용하여 1만큼 증가시켰고, 증가시킨 값을 리턴해서 main메소드에서 받아와 출력했습니다. 이전 코드와는 다르게 값이 증가되었겠죠.
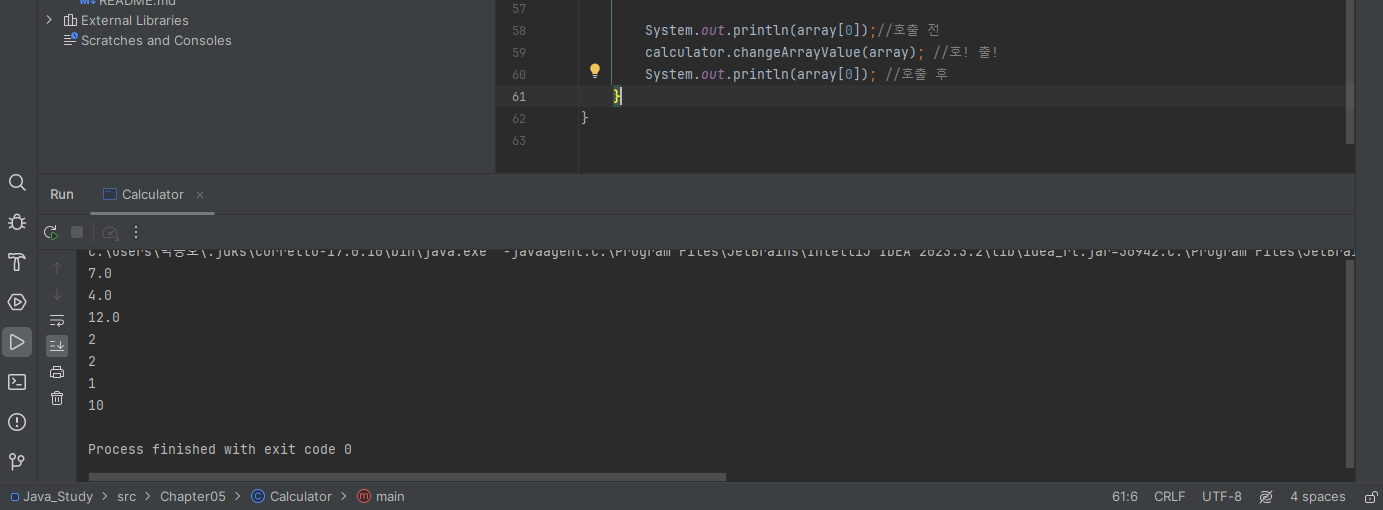
2해법은 이 예시와같이 postfixOperator 메소드에 return 문을 이용하는 방법입니다. postfixOperator 메소드는 입력으로 들어온 값을 1만큼 증가시켜 리턴하고, 따라서 a = calculator.postfixOperator(a)처럼 작성하면 a의 값은 다시 postfixOperator 메소드의 리턴값으로 대입되는 것이죠.(즉, 1만큼 증가된 값으로 a의 값이 변경).
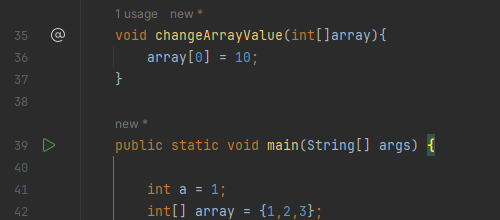
이번에는 postfixOperator 입력값이 int 자료형이 아닌 객체인 경우를 살펴보겠습니다. 메소드에 값을 전달하는 것과 객체를 전달하는 것에는 큰 차이가 있는데, 메소드의 입력으로 객체를 넘기고 메소드가 객체의 속성값(필드 값)을 변경한다면 메소드 수행 이후에도 객체는 변경된 속성값을 유지합니다. 다음 코드를 살펴보시죠
public class Calculator {
int a; // 필드(객체변수) a
void postfixOperator(Calculator cal) {
cal.a++;
}
public static void main(String[] args) {
int a = 1;
Calculator cal = new Calculator();
cal.postfixOperator(cal);
System.out.println(cal.a);
}
}2이번에는 Calculator 클래스의 필드로 a를 선언했습니다. 그리고 postfixOperator 메소드에서 Calculator 클래스의 객체를 매개변수로 입력받도록 하고, 해당 객체를 1만큼 증가시켰습니다. 그리고 main 메서드에서는 postfixOperator 메소드 호출 시 Calculator 클래스의 객체인 cal을 전달하도록 수정했습니다. 이렇게 수정하고 프로그램을 실행해보면 cal 객체의 필드 a의 값이 원래는 1이었는데 postfixOperator 메소드 실행 후 1만큼 증가되어 2가 출력되는 것을 확인할 수 있습니다.
여기서 주목해야 하는 부분은 postfixOperator 메소드의 입력 파라미터가 값이 아닌 Calculator 클래스의 객체 라는것이죠. 이렇게 메소드가 파라미터로 객체를 전달받으면, 메소드 내의 객체는 전달받은 객체 그 자체로 수행됩니다. 따라서 입력으로 전달받은 cal 객체의 필드 a의 값이 증가하게 되는 것입니다.
this 활용하기
앞서 살펴본 예제에서 다음과 같은 문장이 있었습니다.
cal.postfixOperator(cal);cal 객체를 이용하여 postfixOperator 메소드를 호출할 경우 굳이 cal 객체를 전달할 필요가 없습니다.
왜냐하면 전달하지 않더라도 postfixOperator 메소드는 this라는 키워드를 이용하여 객체에 접근할 수 있기 때문입니다. this를 이용하여 postfixOperator 메소드를 수정한 코드는 다음과 같습니다.
public class Calculator {
int a; // 필드 a
void postfixOperator() {
this.a++; // 본인 객체 접근시 this 사용
}
public static void main(String[] args) {
Calculator cal = new Calculator();
cal.a = 1;
cal.postfixOperator(); // Before) cal.postfixOperator(cal);
System.out.println(cal.a);
}
}2우리가 자신을 ‘나’라고 하듯이, 객체도 자신을 ‘this’라고 합니다.
따라서 this.a는 자신이 가지고있는 a 필드 라는 것 입니다. this는 주로 생성자와 메소드의 매개변수 이름이 필드와 동일할 경우, 혹은 인스턴스의 필드임을 명시하고자할 때 사용합니다.
🚩 final 필드와 상수
final 필드
final의 의미는 ‘최종적’이라는 뜻을 갖고 있습니다. 그렇다면 final 필드는 최종적인 필드라는 뜻인데, 정확하게는 final 필드가 초기값 지정이되면 이것이 최종적인 값이 되어, 프로그램 실행 도중에 수정할 수 없다는 것입니다. final 필드는 다음과 같이 선언합니다.
final 타입 필드명 [= 초기값];final 필드의 초기값을 줄 수 있는 방법은 아래와같이 두가지 방법이 있습니다.
- 필드 선언시
- 생성자 에서
단순 값이라면 필드 선언시 초기화를 하는것이 가장 간단합니다. 하지만 객체 생성시 외부 데이터로 초기화해야 한다면 생성자에서 초기값을 지정해야 합니다. 만약 생성자에서 final 필드의 최종 초기화를 마쳐야 하는데, 초기화되지 않은 final 필드를 그대로 남겨두면 컴파일 에러가 발생합니다.
다음 예제를 보시죠.
package Chapter06;
public class FinalFieldExample {
final String nation = "Korea";
String name;
public FinalFieldExample(String name) {
this.name = name;
}
}package Chapter06;
public class FinalField {
public static void main(String[] args) {
FinalFieldExample finalFieldExample = new FinalFieldExample("김거녁");
System.out.println("국적은 "+finalFieldExample.nation+" 입니다.");
System.out.println("이름은 "+finalFieldExample.name+" 입니다.");
}
}실행 결과는
이름은 김거녁입니다.
국적은 Korea 입니다. 가 출력되겠죠? ㅎㅎ
위 예시에서도 final로 이미 선언된 nation 필드를 다른 값으로 변경 시도하면 컴파일 오류가 발생합니다.
그러므로 final은 프로그램을 수행하면서 그 값이 바뀌면 안 될 때 사용합니다.
상수(static final)
수학에서 사용되는 원주율 파이, 지구의 무게 및 둘레는 불변의 값 입니다. 이런 불변의 값을 저장하는 필드를 자바에서는 상수라고 합니다. final 필드는 한 번만 초기화되면 수정할 수 없는 필드지만, final 필드를 상수라고 부르지는 않습니다. 왜냐하면 불편의 값은 객체 마다 저장할 필요가 없는 공용성을 띠고 있는 특징이 있고, 여러 가지 값으로 초기화될 수 없기 때문입니다. final 필드는 객체마다 저장되고 생성자 매개변수로 여러가지 값을 가질 수 있기 때문에 상수가 될 수 없습니다.
static final 타입 상수 [= 초기값];객체마다 저장할 필요가 없이 공용으로 선언하여 사용하기때문에 static 이면서 final로 선언이 됩니다. static final 필드는 객체마다 저장되지 않고 클래스에만 포함됩니다. 그리고 한 번 초기값이 저장되면 변경할 수 없죠.
다음과같은 정적블록에서의 초기화도 가능합니다.
static final 타입 상수;
static {
상수 = 초기값;
}상수 이름은 모두 대문자로 작성하는게 컨벤션입니다. 만약 서로 다른 단어가 혼합된 이름이라면 언더바(_)로 단어들을 연결해줍니다.
다음은 상수 필드를 올바르게 선언한 코드입니다.
static final double PI = 3.14159;
static final double EARTH_SURFACE_AREA;public class Earth {
static final double EARTH_RADIUS = 6400;
static final double EARTH_SURFACE_AREA;
static {
EARTH_SURFACE_AREA = 4 * Math.PI * EARTH_RADIUS * EARTH_RADIUS;
}
}public class EarthExample {
public static void main(String[] args) {
System.out.println("지구의 반지름: " + Earth.EARTH_RADIUS + "km");
System.out.println("지구의 표면적: " + Earth.EARTH_SURFACE_AREA + " km^2");
}
}지구의 반지름: 6400.0km
지구의 표면적: 5.147185403641517E8 km^2⛔ 접근 제어자
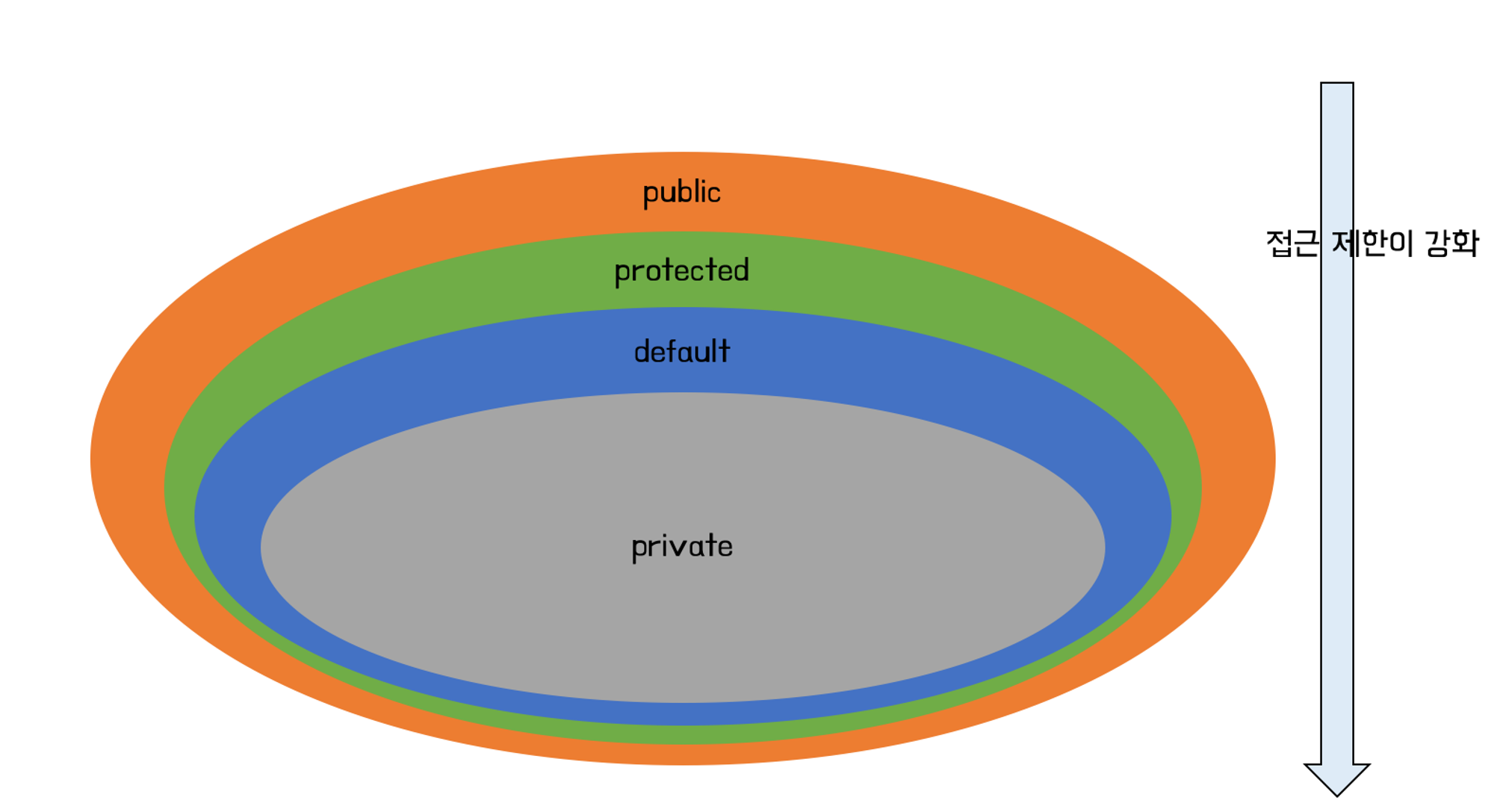
접근 제어자(access modifier)를 사용하여 변수나 메소드의 사용 권한을 설정할 수 있습니다. 다음과 같은 접근 제어자를 사용하여 사용 권한을 설정할 수 있다.
- private
- default
- protected
- public
다른 곳에서 데이터에 접근하지 못하게 하는 역할을 합니다.
접근 제어자는 private으로 갈수록 점점 접근 범위가 적어집니다. 하나씩 순서대로 보겠습니다.
private
접근 제어자가 private으로 설정되었다면 private이 붙은 변수나 메서드는
🧐해당 클래스 안에서만 접근이 가능 합니다.
public class Secret {
private String name;
private String getName() {
return this.name;
}
}
name 변수와 getName 메소드는 오직 Secret 클래스 에서만 접근이 가능하고 다른 클래스에서는 접근이 불가능합니다.
6.5.2 default
접근 제어자를 별도로 설정하지 않는다면 변수나 메소드는 default 접근 제어자가 자동으로 설정되어 동일한 패키지 안에서만 접근이 가능합니다. 반대로 다른 패키지라면 사용할 수 없도록 제한됩니다.
package house; // 패키지가 동일하다.
public class HouseKim {
String lastname = "kim"; // lastname은 default 접근제어자로 설정된다.
}package house; // 패키지가 동일하다.
public class HousePark {
String lastname = "park";
public static void main(String[] args) {
HouseKim kim = new HouseKim();
System.out.println(kim.lastname); // HouseKim 클래스의 lastname 변수를 사용할 수 있다.
}
}kimHouseKim과 HousePark의 패키지는 house로 동일합니다. 따라서 HousePark 클래스에서 default 접근 제어자로 설정된 HouseKim의 lastname 변수에 접근이 가능합니다.
6.5.3 protected
접근 제어자가 protected로 설정되었다면 protected가 붙은 변수나 메소드는 `동일 패키지의 클래스 또는 해당 클래스를 상속받은 클래스에서만 접근이 가능`합니다.
package Chapter06;
public class HousePark {
protected String LastName = "Park";
public static void main(String[] args) {
HouseKim kim = new HouseKim();
System.out.println(kim.LastName);
}
}package Chapter06;
public class InheritHousePark extends HousePark{
public static void main(String[] args) {
InheritHousePark park = new InheritHousePark();
park.LastName = "";
}
}
6.5.4 public
접근 제어자가 public으로 설정되었다면 public 접근 제어자가 붙은 변수나 메소드는 어떤 클래스에서도 접근이 가능합니다.
아래 코드에서 public 접근제어자로 info 필드를 선언하고 초기화합니다.
package car;
public class Car {
protected String company = "kia";
public String info = "this is public message.";
}public 접근 제어자가 붙었기 때문에 패키지가 다른 Sonata클래스에서도 sonata.info 접근이 가능합니다.
package car.example;
import car.Car;
public class Sonata extends Car {
public static void main(String[] args) {
Sonata sonata = new Sonata();
System.out.println(sonata.company);
System.out.println(sonata.info);
}
}kia
this is public message.🧐 자 그럼 정리해볼까요??
Public = 공용 데이터 접근
protected = 동일한 패키지 혹은 상속받은 클래스에서 접근 가능
default = 동일한 패키지에서 접근 가능
protected = 해당 클래스에서만 접근 가능
+main calss는 public으로 설정하는게 관례라고하네요~!
🎃 Getter, Setter 메소드
Setter 메소드
객체 지향 프로그래밍에서 일반적으로 객체의 데이터는 객체 외부에서 직접적으로 접근하는 것을 막습니다. 그 이유는 객체의 데이터를 외부에서 마음대로 읽어들이고 수정할 경우 객체의 무결성 (결점이 없는 성질)이 깨질 수 있기 때문입니다.
예를 들어, 자동차의 속도는 음수가 될 수 없는데, 외부에서 음수로 변경하면 객체의 무결성이 깨집니다.
car.speed = -100;이런 문제점을 해결하기 위해 객체 지향 프로그래밍에서는 메소드를 통해 데이터를 변경하는 방법을 선호합니다. 데이터는 외부에서 접근할 수 없도록 막고, 메소드는 공개해서 외부에서 메소드를 통해 데이터에 접근하도록 유도합니다. 그 이유는 메소드는 매개값을 검증해서 유효한 값만 데이터로 저장할 수 있기 때문입니다. 이러한 역할을 하는 메소드가 Setter 메소드입니다.
Setter 메소드 사용하는 것을 코드로 보겠습니다.
public class Car {
private int speed;
public void setSpeed(int speed) {
if (speed < 0) {
this.speed = 0;
return;
} else {
this.speed = speed;
}
}
}speed 필드는 외부에서 직접 접근이 불가능하도록 막아놓고(private), Setter 메소드로 speed값을 변경해주도록 공개(public)했습니다. 값 변경에 대한 제약조건은 Setter 메소드에 넣을 수 있겠죠. 실제로 실무에서는 이렇게 사용합니다.
Getter 메소드
외부에서 객체의 데이터를 읽을 때도 메소드를 사용하는것이 좋습니다. 객체 외부에서 객체의 필드값을 사용하기 부적절한 경우도 있는데 이런 경우에는 메소드로 필드값을 가공한 후 외부로 전달하면 됩니다. 예를 들어 자동차의 속도를 마일에서 KM단위로 환산하여 외부로 리턴해줄 수 있겠죠.
public class Car {
private int speed;
public double getSpeed() {
double km = speed * 1.6;
return km;
}
}클래스를 선언할 때 가능하면 필드를 private으로 선언해서 외부로부터 직접접근을 보호하고, 필드에 대한 Setter/Getter 메소드를 작성하여 필드값을 안전하게 변경/사용하는 것이 좋습니다.

private 타입 fieldName;
// Getter
public 리턴타입 getFieldName() {
return fieldName;
}
// Setter
public void setFieldName(타입 fieldName) {
this.fieldName = fieldName;
}만약 필드 타입이 boolean일 경우에는 관례상 get으로 시작하지 않고, is로 시작합니다. 예를들어 stop 필드의 Getter와 Setter는 다음과 같이 작성할 수 있습니다.
private boolean stop;
// Getter
public boolean **is**Stop() {
return stop;
}
// Setter
public void setStop(boolean stop) {
this.stop = stop;
}그럼 위의 예시를 모두 사용하여 Sonata 클래스의 Getter, Setter 메소드를 구현해보겠습니다.
public class Sonata {
private int speed;
private boolean stop;
void setSpeed(int speed) {
if (speed < 0) {
this.speed = 0;
return;
} else {
this.speed = speed;
}
}
public int getSpeed() {
return speed;
}
public boolean isStop() {
return stop;
}
public void setStop(boolean stop) {
this.stop = stop;
}
public static void main(String[] args) {
Sonata sonata = new Sonata();
// 잘못된 속도 변경
sonata.setSpeed(-50);
System.out.println("현재 속도: " + sonata.getSpeed());
// 올바른 속도 변경
sonata.setSpeed(60);
System.out.println("변경 후 속도: " + sonata.getSpeed());
// 멈춤
if (!sonata.isStop()) {
sonata.setStop(true);
}
System.out.println("멈춤 후 속도: " + sonata.getSpeed());
}
}현재 속도: 0
변경 후 속도: 60
멈춤 후 속도: 60💫 메소드 재정의
🖊️ 이번장에서는 메소드를 재정의할 수 있는 메소드 오버라이딩, 메소드 오버로딩에 대한 개념을 익혀보겠습니다.부모 클래스의 모든 메소드가 자식 클래스의 입맛에 맞게 설계되어있다면 가장 이상적인 상속이겠지만, 어떤 메소드는 자식 클래스가 사용하기에 적합하지 않을 수 있습니다. 이 경우 상속된 일부 메소드는 자식 클래스에서 다시 수정해서 사용해야 합니다. 자바는 이런 경우를 위해 메소드 오버라이딩(Overriding) 기능을 제공합니다.
메소드 오버로딩
메소드의 이름은 동일하고 입력 항목이 다른 경우를 메소드 오버로딩(method overloading)이라고 부릅니다. 아래 코드와 같은 개념으로 이해하시면 됩니다.
- 동일한 리턴 타입과 메소드명, 다른 매개변수
void sleep()
void sleep(int hour)예시를 통해서 한번 알아볼게요. Animal, Dog, HouseDog 클래스 중 HouseDog에 오버로딩 예시가 있습니다.
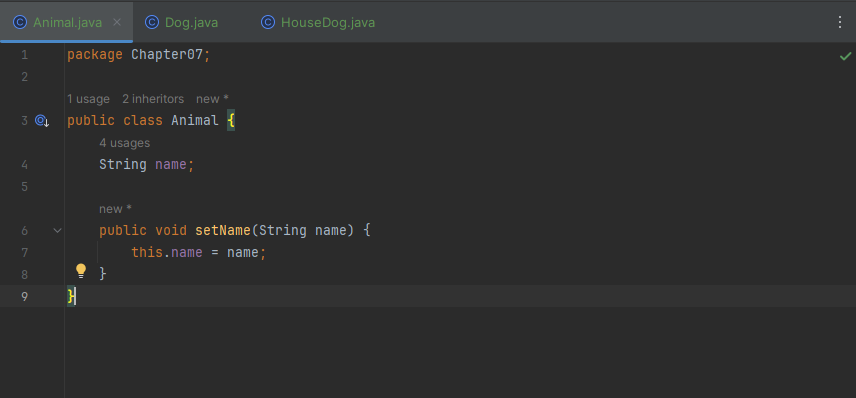
Animal
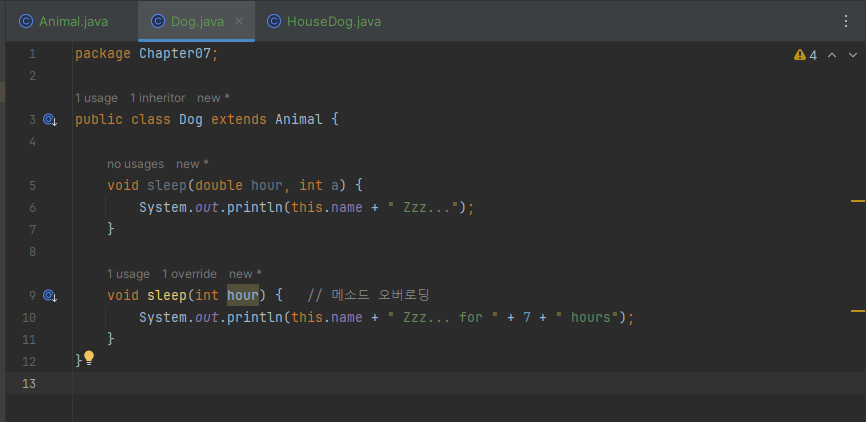
Dog
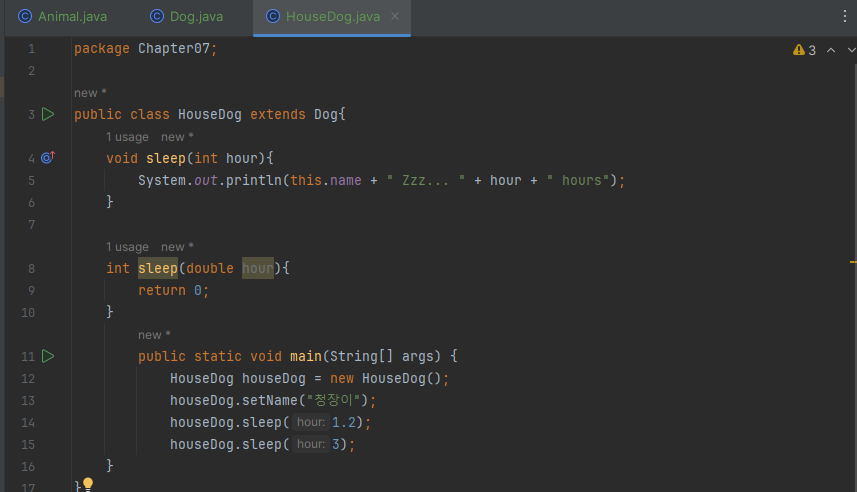
HouseDog
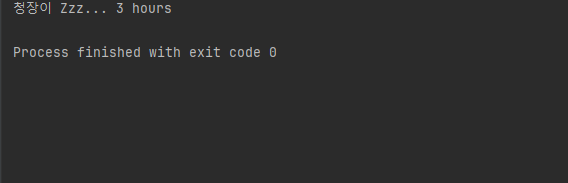
실행결과
메소드 오버라이딩(@Override)
메소드 오버로딩과 비슷하게 메소드를 재정의할 수 있는 방법입니다. 상속된 부모의 메소드 내용이 자식 클래스에 맞지 않을 경우, 자식 클래스에서 동일한 메소드를 재정의할 수 있습니다. 이것이 메소드 오버라이딩 개념이고 메소드가 오버라이딩 되었다면 부모 객체의 메소드는 숨겨지기 때문에, 자식 객체에서 메소드를 호출하면 오버라이딩된 자식 메소드가 호출됩니다.
직접 코드로 확인해보겠습니다.
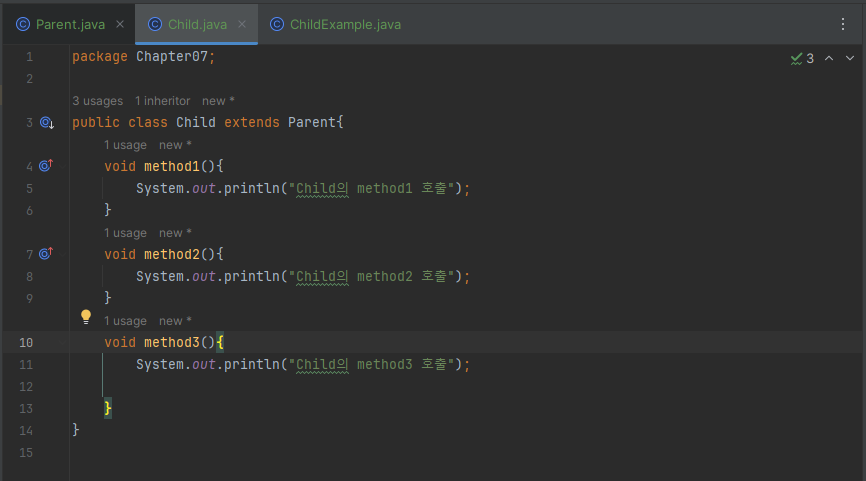
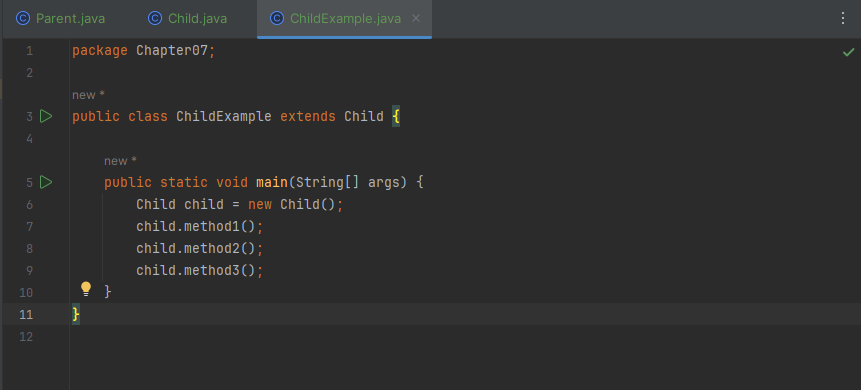
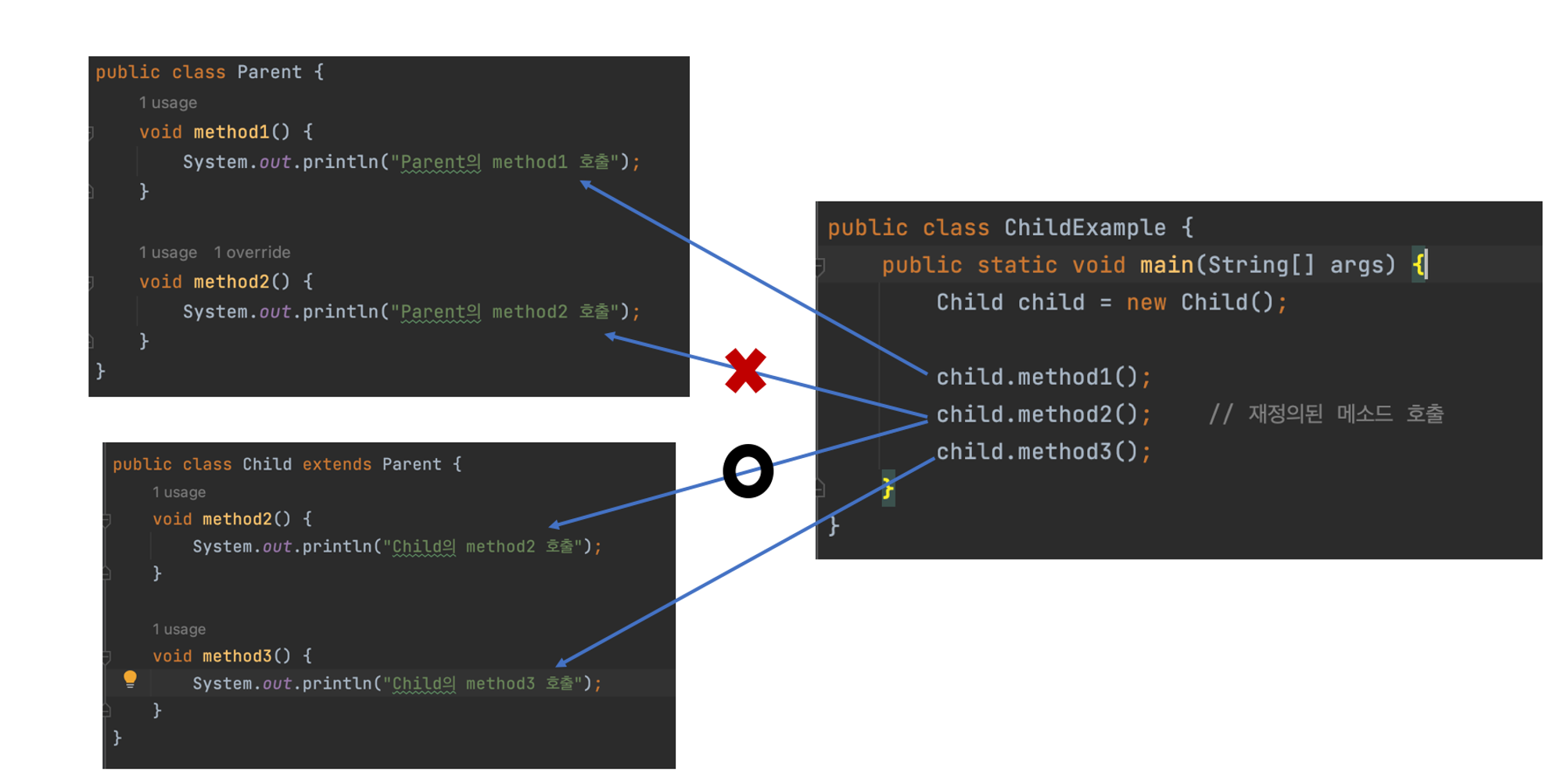
메소드를 오버라이딩할 때는 다음과 같은 규칙에 주의해서 작성해야 합니다.
- 부모의 메소드와 동일한 시그니처(리턴타입, 메소드이름, 매개변수 리스트)를 가져야 한다.
- 부모 클래스의 메소드보다 접근 제한을 더 강하게 오버라이딩 할 수는 없다.
- 새로운 예외(Exception)를 throws 할 수 없다. (예외처리 Part에서 배웁니다)
접근제한을 더 강하게 오버라이딩 할 수 없다는 것은 부모 메소드가 public 접근 제한을 갖고 있을경우 오버라이딩 하는 자식 메소드는 default나 private 접근제한으로 수정할 수 없다는 뜻입니다. 여기서 반대로는 가능합니다. 만약 부모 메소드가 default 접근 제한을 갖는다면 재정의되는 자식 메소드는 default 또는 public 접근 제한을 가질 수 있겠죠.
부모가 접근 가능하도록 설정해놨는데, 부모 허락없이 자기 맘대로 쓰면 안된다... 느낌
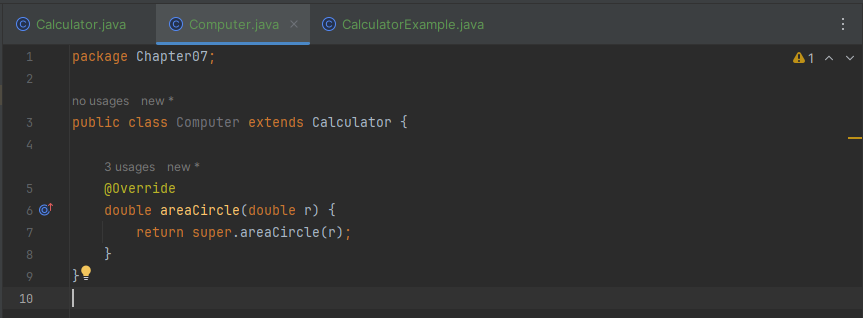
다음 예제는 Calculator의 자식 클래스인 Computer에서 원의 넓이를 구하는 Calculator의 areaCircle() 메소드를 사용하지 않고, 좀 더 정확한 원의 넓이를 구하도록 오버라이딩 했습니다.
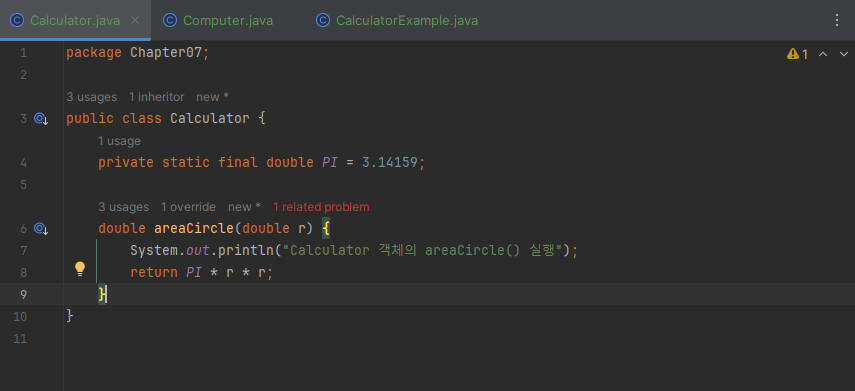 부모 클래스 정의
부모 클래스 정의
 자식 클래스 정의 - 상속
자식 클래스 정의 - 상속
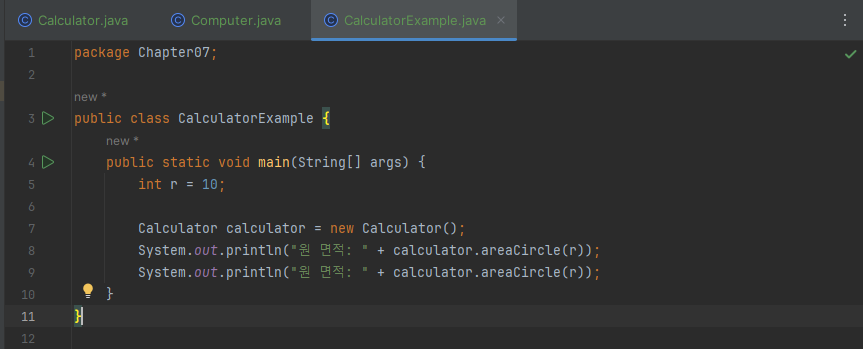 출력
출력
🌀 추상클래스
🖊️ 인터페이스 역할도 하면서, 클래스의 기능도 가지고있는 자바의 돌연변이 같은 클래스인 추상클래스에 대해 알아봅시다.
1. 추상클래스의 개념
2. 추상클래스의 용도
3. 추상클래스의 선언
4. 추상메소드와 오버라이딩
추상메서드
추상 메서드란 자식 클래스에서 반드시 오버라이드 해야만 사용할 수 있는 메소드를 말합니다.
추상메서드를 선언하는 이유는, 자식 클래스에서 반드시 추상메서드를 구현하도록 하기 위함입니다. 일종의 ‘규제’이죠. 상속받아 사용하는 자식 클래스에서는 자신에게 필요한 내용으로 재정의하여 사용할 수 있습니다.
추상 메서드는 다음과 같이 선언합니다.
abstract 리턴타입 메소드명();
이렇게 반드시 Override 해야만 선언이 가능합니다.
추상클래스 개념
- 추상클래스란, 추상메서드를 하나 이상 포함하는 클래스입니다.
추상(abstract)은 실체 간에 공통되는 특성을 추출한 것을 말합니다. 예를 들어, 새, 곤충, 물고기 등의 실체에서 공통되는 특성을 추출해보면 동물이라는 공통점이 있겠지요. 또 다른 예로 삼성, 현대, LG 등의 실체에서 공통되는 특성을 추출해보면 ‘회사’라는 공통점이 있습니다. 이와같이 실체들의 공통되는 특성을 가지고 있는 것을 클래스로 따로 빼놓은 것이 추상클래스 입니다.
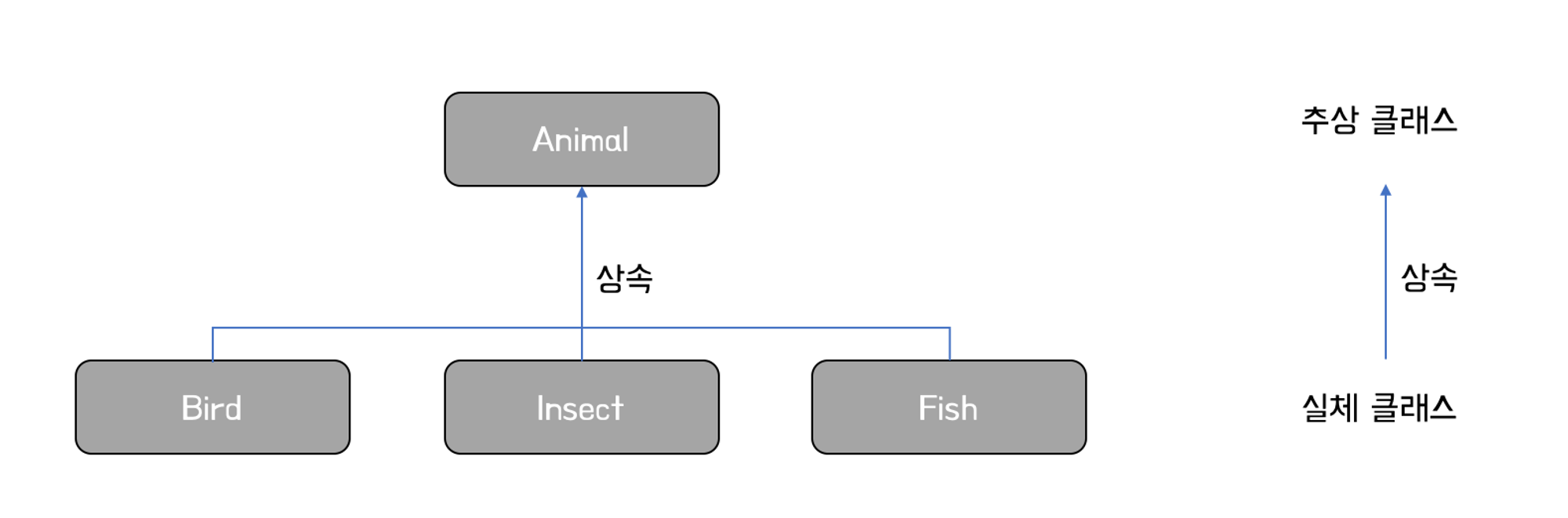
추상클래스는 실체 클래스의 공통되는 필드와 메소드를 추출해서 만들었기 때문에 일반 클래스와는 달리 객체를 직접 생성해서 사용할 수 없습니다. 다시 말해, 추상클래스는 new 연산자를 사용해서 인스턴스를 생성하지 못합니다.
Animal animal = new Animal(); (X)추상클래스는 새로운 실체 클래스를 만들기 위해 부모 클래스로만 사용됩니다. 예를 들어 Ant 클래스를 만들기 위한 Animal 클래스는 다음과 같이 사용할 수 있습니다.
class Ant **extends** Animal { ... }추상 클래스의 용도
실체 클래스들의 공통적인 특성(필드, 메소드)을 뽑아내어 추상 클래스로 만드는 이유가 무엇일지 다음 두가지가 있습니다.
-
실체 클래스들의 공통된 필드와 메소드의 이름을 통일할 목적
→ 실체 클래스를 설계하는 사람이 여러 사람일 경우, 정의해야하는 필드나 메소드가 제각기 다른 이름을 가질 수 있습니다. 동일한 데이터와 기능임에도 이름이 다르다보니 객체마다 사용 방법이 달라질텐데, 이럴때 추상클래스를 정의함으로써 어느정도 필드나 메소드이름을 통일시킬 수 있는 장점이 있습니다.
-
실체 클래스를 작성할 때 시간을 절약
공통적인 필드와 메소드는 추상 클래스인 Phone에 모두 선언해두고, 실체 클래스마다 다른 점만 실체 클래스에 선언하게되면 실체 클래스를 작성하는데 시간을 절약할 수 있습니다.
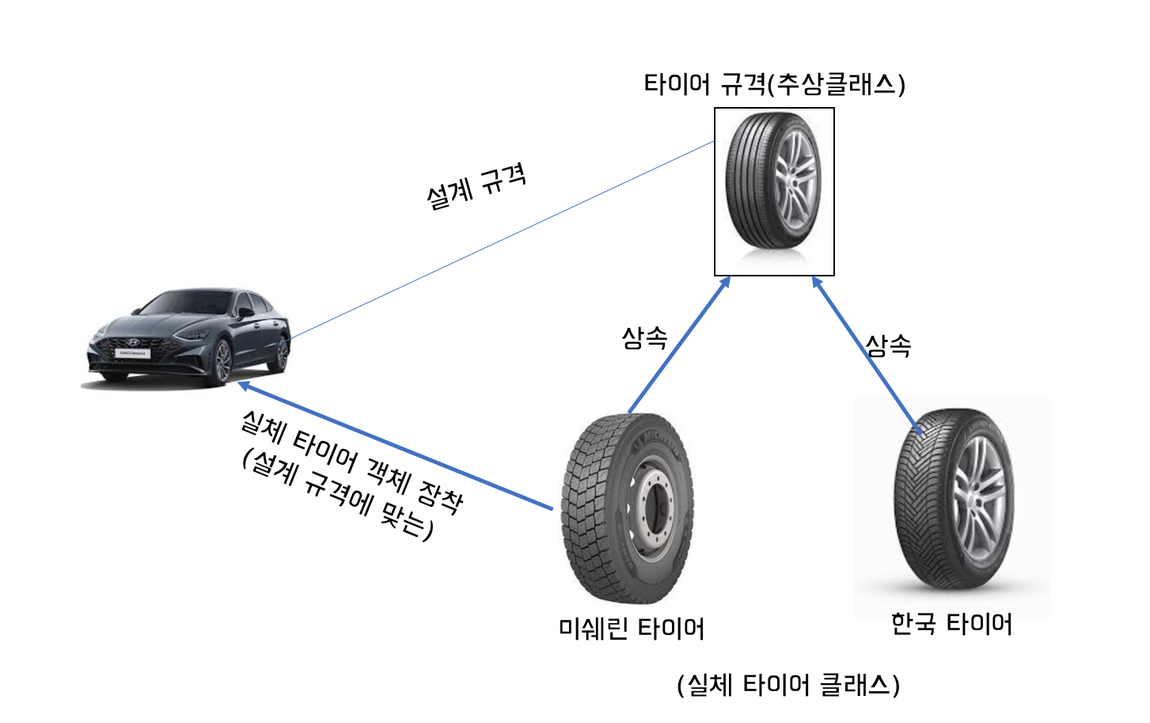
위 그림을 보면서 예를 들어보겠습니다. 자동차를 설계할 때 일반적인 타이어 규격에 맞추어 설계를 해야합니다. 이는 일반적인 타이어 규격에 준수하는 어떠한 타이어든 부착할 수 있도록 하기 위해서 입니다. 여기서 타이어 규격은 타이어 추상 클래스라고 볼 수 있고, 타이어 규격에 준수하는 한국타이어나 금호타이어는 추상클래스를 상속하는 실체 타이어 클래스라고 볼 수 있습니다. 이처럼 설계 규격을 통일하고 오류나 실수 없이 구현하기 위해 추상클래스를 사용하기도 합니다.\
7.5.4 추상 클래스의 오버라이딩
추상클래스는 실체 클래스가 공통적으로 가져야 할 필드와 메소드들을 정의해 놓은 추상적인 클래스이므로 실체 클래스의 멤버(필드, 메소드)를 통일하는데 목적이 있습니다.
간혹 메소드의 선언만 통일하고, 실행 내용은 실체 클래스마다 달라야 하는 경우가 있습니다. 예를들어 모든 동물은 소리를 내기 때문에 Friends 추상클래스에서 sound() 메소드를 정의했다고 합시다. 그렇다면 어떤 소리를 내는지는 각각의 친구들을 구현한 실체 클래스에서 sound()를 작성해야겠죠.
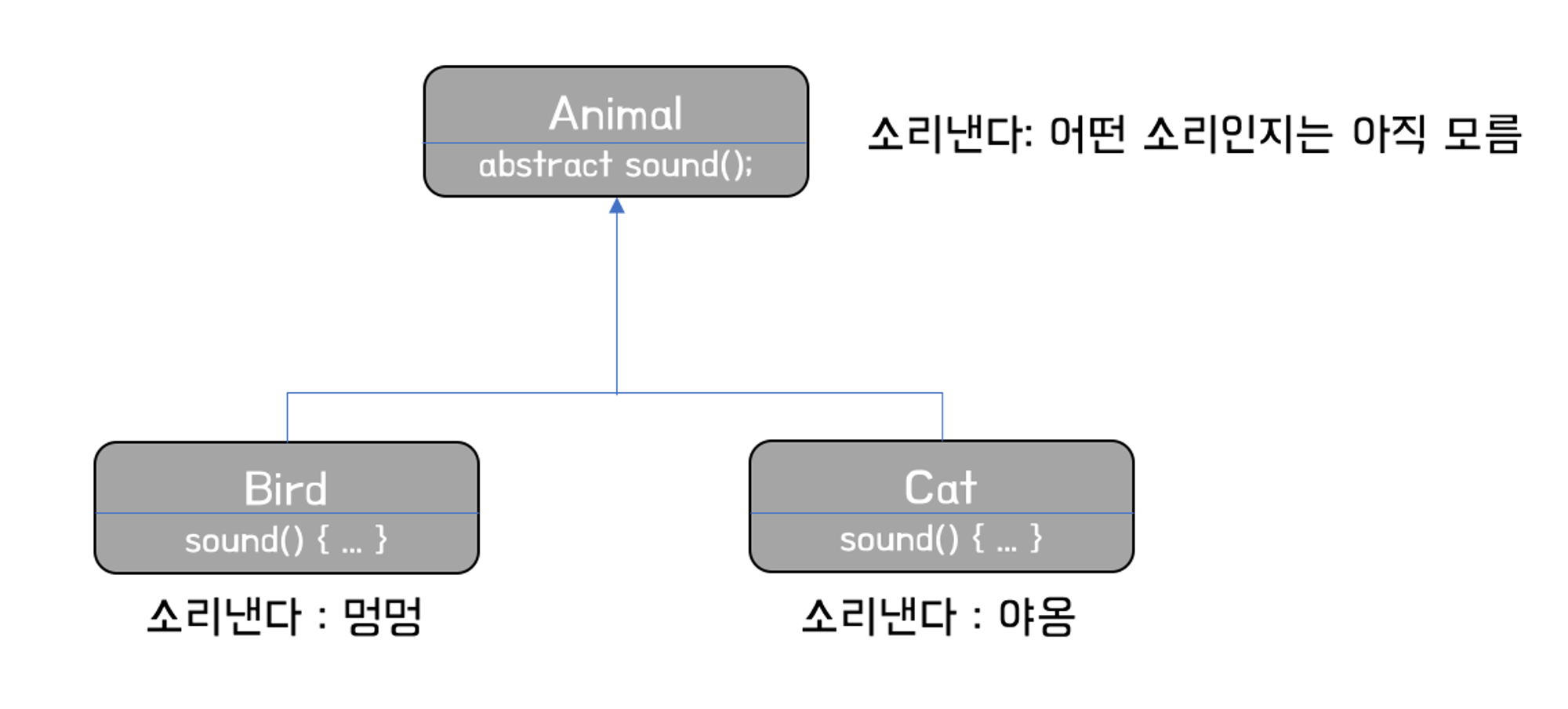
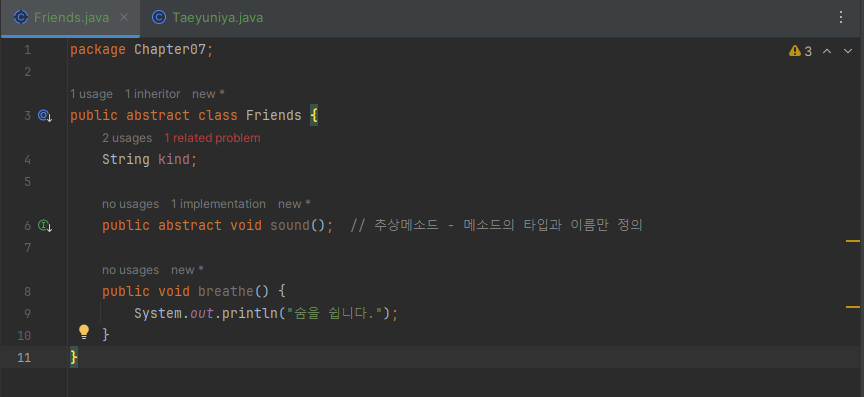
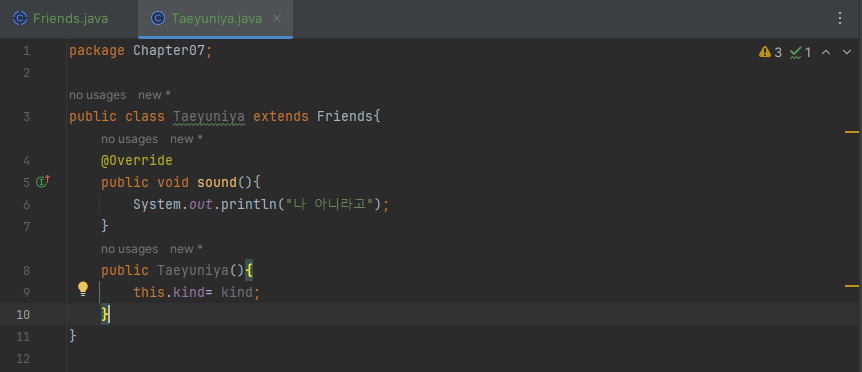
보면서 복습해보도록 하자... 아직 멀었구나 나도
