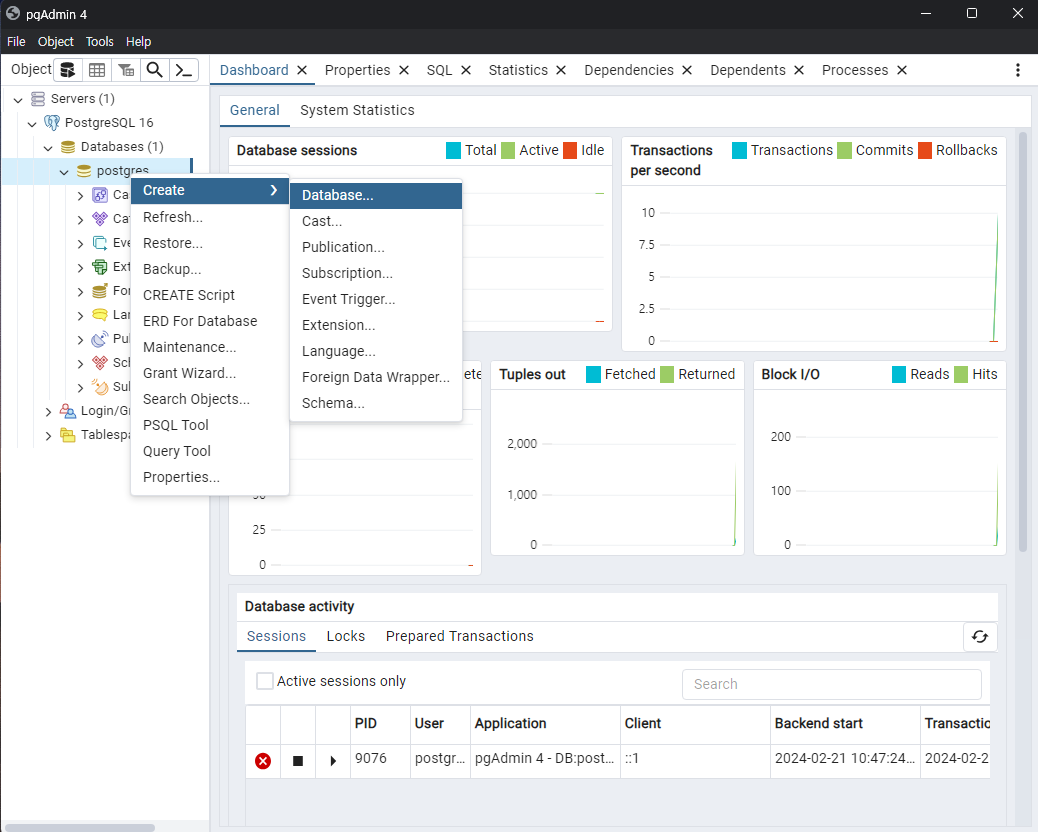
 먼저 Database를 Create 합니다.
먼저 Database를 Create 합니다.
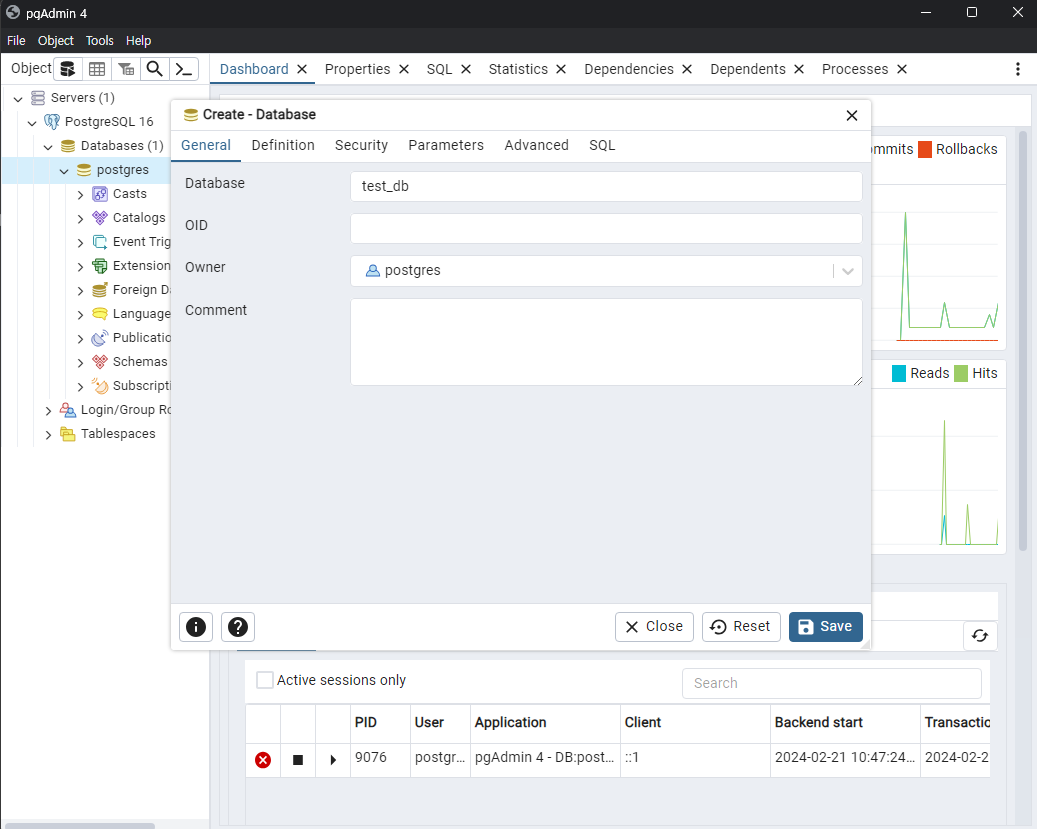 Database 제목은 test_db로 설정하고 Save 하겠습니다.
Database 제목은 test_db로 설정하고 Save 하겠습니다.
생성된 test_db에 Query Tool 생성 후
CREATE TABLE students (
name VARCHAR(255) NOT NULL,
age INT NOT NULL,
address VARCHAR(255) NOT NULL
);위와같은 코드를 입력하고 실행버튼을 누르겠습니다.
 이렇게되면 student 라는 이름의 Table이 생성됩니다.
이렇게되면 student 라는 이름의 Table이 생성됩니다.
student라는 테이블 생성이 완료되었다면 테이블에 실습용 데이터를 쌓아보겠습니다. 아래의 SQL문을 입력 후 실행 버튼을 누릅니다.
INSERT INTO students (name, age, address) VALUES
('이황', 28, '경상북도'),
('정약용', 29, '경기도'),
('김정호', 30, '전라북도'),
('박지원', 31, '전라북도'),
('김홍도', 32, '경기도'),
('신윤복', 33, '서울특별시'),
('김광균', 34, '서울특별시'),
('한용운', 35, '경상남도'),
('박두진', 36, '경기도');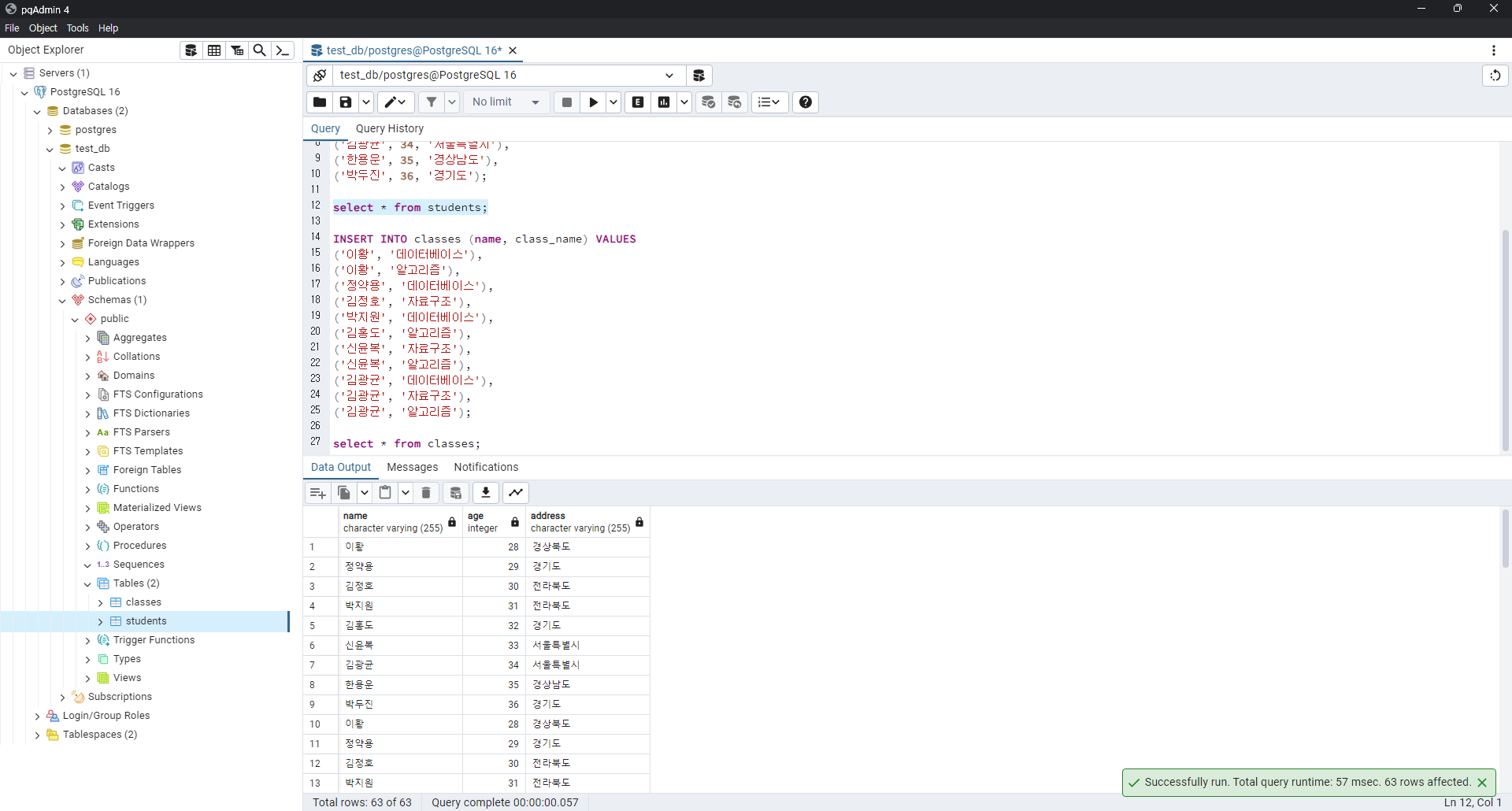 이후 select * from $$$; 를 통해 데이터를 확인할 수 있습니다.
이후 select * from $$$; 를 통해 데이터를 확인할 수 있습니다.
🧐 조회
SELECT, FROM, WHERE
조회에서는 SELECT, FROM, WHERE 세 가지를 기억하시면 됩니다.
| SELECT | 조회할 열을 지정 |
|---|---|
| FROM | 조회할 테이블을 지정 |
| WHERE | 조회할 데이터를 필터링 |
예시로 사용할 데이터
RDBMS는 테이블 형태로 데이터를 관리합니다.
아래와 같이 학생들의 정보가 있는 students 테이블이 있다고 가정합니다.
| name | age | address |
|---|---|---|
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
특정 열을 조회
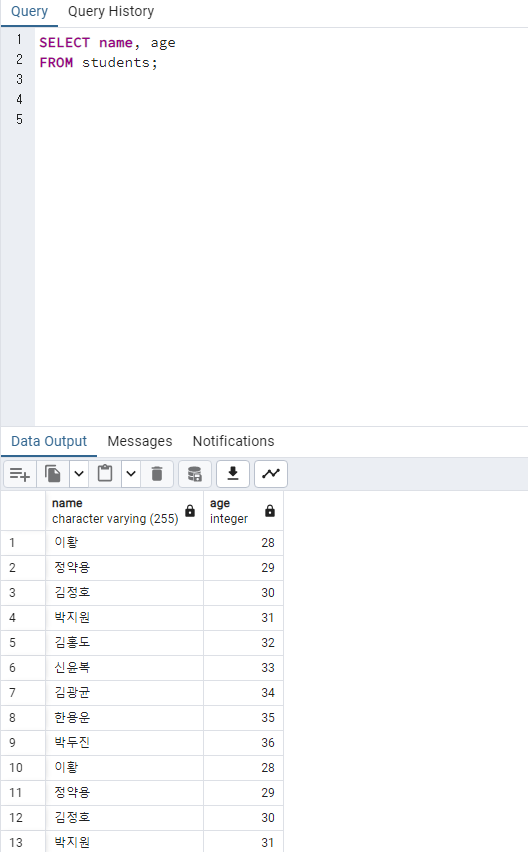
학생의 이름과 나이만 조회합니다.
SELECT name, age
FROM students;결과
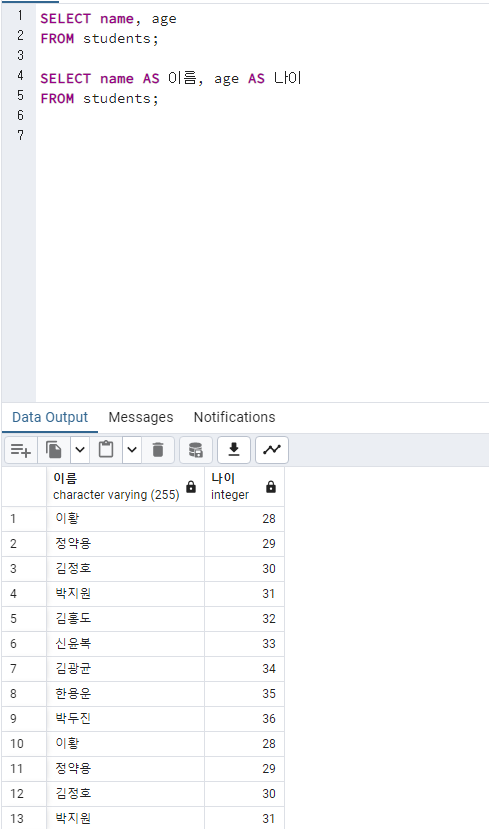
별칭을 사용하여 열 이름 변경
학생의 이름에 해당하는 열을 “이름”으로, 나이에 해당하는 열을 “나이”로 변경합니다.
SELECT name AS col1, age AS col2
FROM students;결과
조건을 사용하여 데이터 필터
조건을 만족하는 행만 조회합니다. 나이가 30살 이상인 학생만 조회합니다.
SELECT *
FROM students
WHERE age >= 30;결과

😺 삽입
INSERT INTO
테이블에 새로운 행(row)을 삽입할 때 INSERT INTO 문을 사용합니다.
예시로 사용할 데이터
RDBMS는 테이블 형태로 데이터를 관리합니다.
아래와 같이 학생들의 정보가 있는 students 테이블이 있다고 가정합니다.
| name | age | address |
| --- | --- | --- |
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
한 행 삽입
students 테이블에 새로운 학생 정보를 삽입합니다.
INSERT INTO students (name, age, address)
VALUES ('김이박', 40, '서울특별시');name 열에는 ‘김이박’, age 열에는 40, address 열에는 ‘서울특별시’를 삽입한다는 의미입니다.
40은 작은 따옴표로 감싸지않은 점을 주목해봅시다. name과 address는 문자열이 와야하므로 작은따옴표를 사용했고, age는 숫자(정수)가 와야하기 때문에 작은 따옴표를 사용하지 않았습니다.
결과

한 행 삽입 + 특정 열만
students 테이블에 새로운 학생 정보를 삽입합니다. 이번에는 name 열에는 ‘신기루’, age 열에는 41, address 열에는 아무런 값도 삽입하지 않으려고 합니다.
INSERT INTO students (name, age)
VALUES ('신기루', 41);위의 SQL문을 실행하면 어떤 일이 일어날까요? 아마 아래와 같은 에러가 발생할 것입니다.
ERROR: 실패한 자료: (신기루, 41, null)"address" 칼럼(해당 릴레이션 "students")의 null 값이 not null 제약조건을 위반했습니다.
address 열에 반드시 데이터를 입력해야하는데 그렇지 않아 발생한 에러입니다. address 열은 not null이라는 속성으로 세팅되어 있던 것이죠. not null 속성은 테이블을 생성할 때 정할 수 있습니다.
만약 address 열이 not null 속성이 아니라면 어땠을까요? SQL문을 실행하면 아래의 결과와 같이 address에 NULL 이라는 값이 들어갑니다. 참고로 NULL은 ‘값이 존재하지 않음’을 나타낼 때 사용합니다.
여러 행 삽입
이번에는 student 테이블에 세 명의 학생 정보를 삽입합니다.
INSERT INTO students (name, age, address)
VALUES ('학생1', 20, '경기도'), ('학생2', 22, '경기도'), ('학생3', 23, '경기도');위의 SQL문을 실행하면 세 명의 학생 정보가 한 번에 삽입됩니다. 여러 행을 한 번에 삽입한다고 해서 bulk insert 라고도 합니다.
조회 후 삽입
이번에는 조금 복잡한 SQL문입니다. 테이블을 조회한 후에 그 결과를 삽입할 수 있습니다.
INSERT INTO students (name, age, address)
SELECT name, age, address FROM students WHERE age < 30;- 먼저 SELECT, FROM, WHERE 부분을 살펴볼까요? students 테이블에서 age가 30미만인 학생만 조회합니다.
- INSERT INTO 에서는 1번에서 조회한 학생 정보를 students 테이블에 삽입합니다.
위의 SQL문을 실행하면 students 테이블에는 age가 30미만인 학생들의 정보가 중복으로 존재할 것이라고 예상할 수 있습니다.
결과
| name | age | address |
|---|---|---|
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
| 김이박 | 40 | 서울특별시 |
| 신기루 | 41 | NULL |
| 학생1 | 20 | 경기도 |
| 학생2 | 22 | 경기도 |
| 학생3 | 23 | 경기도 |
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 학생1 | 20 | 경기도 |
| 학생2 | 22 | 경기도 |
| 학생3 | 23 | 경기도 |
🔮 수정
UPDATE, SET, WHERE
테이블에 새로운 행(row)을 수정할 때 사용합니다.
수정에서는 UPDATE, SET, WHERE 세 가지를 기억하시면 됩니다.
| UPDATE | 수정할 테이블을 지정 |
|---|---|
| SET | 데이터 수정 |
| WHERE | 수정할 데이터를 필터링 |
예시로 사용할 데이터
RDBMS는 테이블 형태로 데이터를 관리합니다.
아래와 같이 학생들의 정보가 있는 students 테이블이 있다고 가정합니다.
| name | age | address |
|---|---|---|
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
필드 한 개 수정
students 테이블의 학생 나이를 수정합니다.
UPDATE students
SET age = 99
WHERE name = '이황';‘이황’이라는 이름을 가진 학생의 나이를 99로 수정하는 SQL문입니다.
결과

필드 여러 개 수정
students 테이블의 학생 나이와 주소를 수정합니다.
UPDATE students
SET age = 10,
address = '서울특별시'
WHERE name = '정약용';‘정약용’이라는 이름을 가진 학생의 나이를 10으로, 주소를 ‘서울특별시’로 수정하는 SQL문입니다.
결과
조건부 수정
students 테이블에서 나이가 33살 미만인 학생들의 주소를 ‘인천광역시’로 수정합니다.
UPDATE students
SET address = '인천광역시'
WHERE age < 33;🙅 삭제
DELETE
테이블의 행(row)을 삭제할 때 사용합니다.
| DELETE FROM | 삭제할 테이블을 지정 |
|---|---|
| WHERE | 삭제할 데이터를 필터링 |
예시로 사용할 데이터
RDBMS는 테이블 형태로 데이터를 관리합니다.
아래와 같이 학생들의 정보가 있는 students 테이블이 있다고 가정합니다.
| name | age | address |
|---|---|---|
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
특정 행 삭제
DELETE
FROM students
WHERE name = '이황';‘이황’이라는 이름을 가진 학생을 삭제합니다.
결과
| name | age | address |
|---|---|---|
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
여러 행 삭제
DELETE
FROM students
WHERE age BETWEEN 30 AND 33;나이가 30~33살 사이인 학생을 삭제합니다.
결과
| name | age | address |
|---|---|---|
| 정약용 | 29 | 경기도 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
모든 행 삭제
DELETE
FROM students;테이블의 모든 데이터를 삭제합니다.
결과
| name | age | address |
|---|
