
🔢 내장 함수
함수란?
데이터베이스에서 함수는 프로그래밍에서의 함수와 역할이 동일합니다.
입력 값을 받아 계산(작업)을 수행하고 결과를 반환하는 구조로 되어 있습니다.
주로 간단한 연산, 수치 변환 등 위해 사용합니다.
내장 함수란?
DBMS에서 기본적으로 제공하는 함수입니다.
사용자가 별도로 함수를 만들지 않아도 DBMS를 설치했다면 기본적으로 사용할 수 있는 함수입니다. 내장 함수는 DBMS마다 약간의 차이가 있을 수 있습니다.
예시에서 사용할 데이터
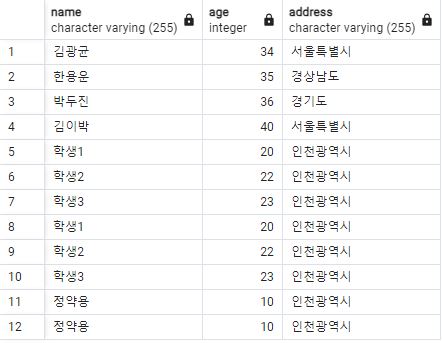
자주 사용하는 내장 함수들
SUM
숫자의 합을 반환합니다.
ex) 모든 학생의 나이의 합을 구합니다.
SELECT SUM(age) FROM students;결과
헤헤 잘 나왔죠?

AVG
숫자의 평균을 반환합니다.
ex) 모든 학생의 나이의 평균을 구합니다.
SELECT AVG(age) FROM students;결과
ㅇㅅㅇ
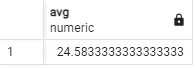
MAX
숫자의 최대값을 반환합니다.
ex) 학생 나이의 최대 값을 구합니다.
SELECT MAX(age) FROM students;결과
MIN
숫자의 최소값을 반환합니다.
ex) 학생 나이의 최소 값을 구합니다.
SELECT MIN(age) FROM students;결과

COUNT
행의 개수를 반환합니다.
ex) 학생들의 주소에서 중복을 제거한 값이 몇 개인지 구합니다.
SELECT COUNT(DISTINCT address) FROM students;결과

CONCAT
두 문자열을 연결합니다.
ex) 학생들의 이름과 주소를 하나의 문자열로 만듭니다.
SELECT CONCAT(name, address) FROM students;결과

LENGTH
문자열의 길이를 반환합니다.
ex) 학생들의 주소가 몇 글자인지 구합니다.
SELECT address, LENGTH(address) FROM students;결과

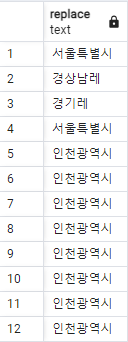
REPLACE
특정 문자열을 다른 문자열로 치환합니다.
ex) 학생들의 주소에서 “도”를 “레”로 바꿉니다.
SELECT REPLACE(address, '도', '레') FROM students;결과
NOW
현재의 날짜와 시간을 반환합니다.
SELECT NOW();🕌 그룹화, 정렬
예시에서 사용할 데이터
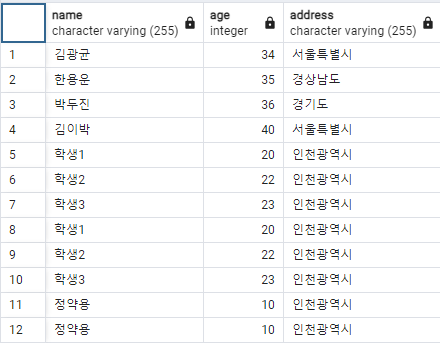
그룹화?
같은 값을 가진 행끼리 하나의 그룹으로 뭉치는 기능입니다. 예시를 보면 좀 더 이해가 쉬울 것 같습니다.
학생 테이블에 있는 데이터를 “주소” 기준으로 그룹을 나누고 싶습니다. 그리고 각 “주소”별로 몇 명의 학생이 있는지 알고 싶다고 가정해봅시다. 그룹화를 위해 DBMS에서는 아래와 같은 과정을 거칠 것 입니다.
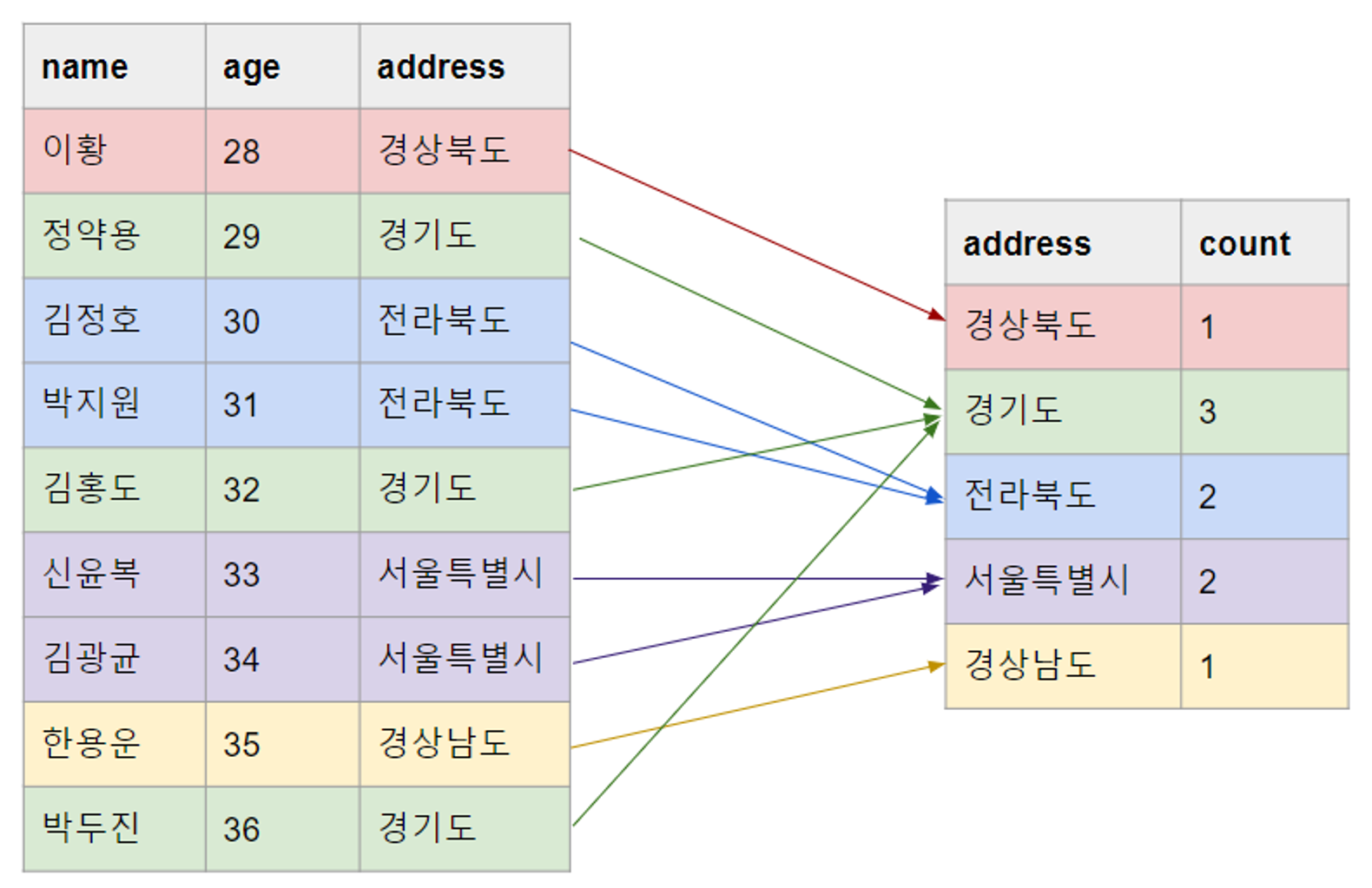
이처럼 그룹화는 잘 활용하면 다양한 기준으로 데이터를 분석할 수 있어서 핵심 기능 중에 하나입니다.
GROUP BY
위에서 설명한 그룹화를 SQL문에서는 GROUP BY 구문을 사용하여 실행할 수 있습니다.
문법은 아래와 같습니다.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열- GROUP BY 절은 FROM, WHERE절 뒤에 위치합니다.
- GROUP BY 절에는 어떤 열을 기준으로 그룹화할 지 명시하여야합니다.
- GROUP BY 절에 명시된 열은 SELECT 절에도 존재하여야합니다.
- WHERE 절 실행 후에 GROUP BY가 실행됩니다.
주소별 학생 수
students 테이블에 있는 데이터를 “주소” 기준으로 그룹핑하고, 그룹별 학생수를 구합니다.
SELECT address, COUNT(*)
FROM students
GROUP BY address결과

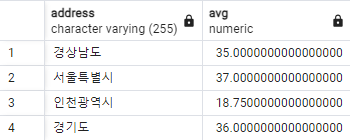
주소별 학생 평균 나이
주소별 학생들의 평균 나이를 구합니다.
SELECT address, AVG(age)
FROM students
GROUP BY address결과
HAVING
HAVING은 GROUP BY 절에 의해 생성된 그룹 중에서 원하는 조건에 부합하는 그룹 만을 선택하는 구문입니다.
문법은 아래와 같습니다.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
HAVING 그룹 필터 조건- GROUP BY 연산 후 HAVING절에 의해 필터링됩니다.
- 실행 순서: WHERE -> GROUP BY -> HAVING
학생 수가 2명 이상인 주소만 조회하고 싶을 때
students 테이블에 있는 데이터를 “주소” 기준으로 그룹핑하고 학생수를 구합니다. 그리고 HAVING 절을 이용하여 학생 수가 2명 이상인 그룹만 필터링합니다.
SELECT address, COUNT(*)
FROM students
GROUP BY address
HAVING COUNT(*) >= 2ORDER BY
ORDER BY는 특정 기준에 따라 정렬하는 구문입니다. 문법은 아래와 같습니다.
SELECT 열, 집계함수
FROM 테이블
[WHERE 필터 조건]
GROUP BY 열
HAVING 그룹 필터 조건
ORDER BY 열 [ASC | DESC]- 실행 순서: WHERE -> GROUP BY -> HAVING -> ORDER BY
- ORDER BY 절에는 어떤 열을 기준으로 정렬할 지 명시하여야합니다.
- ORDER BY에 명시된 열은 SELECT 절에 존재하지 않아도 됩니다. (GROUP BY와 차이점)
- ORDER BY 절에는 두 가지 옵션이 있습니다. 별도로 옵션을 명시하지 않으면 기본 값은 ASC입니다.
- ASC: 오름차순
- DESC: 내림차순
나이가 많은 학생부터 차례로 조회
SELECT *
FROM students
ORDER BY age DESCORDER BY 절에 있는 DESC에 주목해봅시다. 나이가 많은 학생부터 정렬을 해야하기 때문에 DESC(내림차순) 옵션을 주었습니다.
결과
| name | age | address |
|---|---|---|
| 박두진 | 36 | 경기도 |
| 한용운 | 35 | 경상남도 |
| 김광균 | 34 | 서울특별시 |
| 신윤복 | 33 | 서울특별시 |
| 김홍도 | 32 | 경기도 |
| 박지원 | 31 | 전라북도 |
| 김정호 | 30 | 전라북도 |
| 정약용 | 29 | 경기도 |
| 이황 | 28 | 경상북도 |
나이가 많은 학생 TOP 3만 조회
SELECT *
FROM students
ORDER BY age DESC
LIMIT 3“LIMIT 3”에 주목해봅시다. 우리는 모든 학생 정보가 아닌 나이가 가장 많은 학생 3명의 정보만 필요하기 때문에 결과의 개수를 제한하는 구문인 LIMIT을 사용했습니다.
LIMIT은 이와 같이 ORDER BY와 조합하여 많이 사용합니다.
결과
| name | age | address |
|---|---|---|
| 박두진 | 36 | 경기도 |
| 한용운 | 35 | 경상남도 |
| 김광균 | 34 | 서울특별시 |
GROUP BY + HAVING + ORDER BY
지금까지 배운 것을 모두 활용하여 쿼리를 실행해보려 합니다.
SELECT address, COUNT(*)
FROM students
WHERE age >= 29
GROUP BY address
HAVING COUNT(*) >= 2
ORDER BY COUNT(*) DESC;실행 순서는 “WHERE -> GROUP BY -> HAVING -> ORDER BY” 입니다.
- (WHERE) 나이가 29세 이상인 학생만 필터링
- (GROUP BY) 주소를 기준으로 그룹핑
- (HAVING) 학생 수가 2명 이상인 그룹만 필터링
- (ORDER BY) 학생 수가 많은 순서대로 정렬
결과
| address | count |
|---|---|
| 경기도 | 3 |
| 서울특별시 | 2 |
| 전라북도 | 2 |
🤝 JOIN, UNION
테이블 여러 개를 한 번에 조회할 순 없을까?
이전에 관계형 데이터베이스에서는 테이블과 테이블 사이에 관계가 있다고 설명드린 적이 있습니다.
하나의 테이블에 원하는 데이터가 모두 있다면 좋겠지만 두 개 이상의 테이블을 엮어야 원하는 결과가 나오는 경우도 있습니다. 이럴 때 사용하는 것이 JOIN입니다.
예시에서 사용할 데이터
students 테이블
| name | age | address |
|---|---|---|
| 이황 | 28 | 경상북도 |
| 정약용 | 29 | 경기도 |
| 김정호 | 30 | 전라북도 |
| 박지원 | 31 | 전라북도 |
| 김홍도 | 32 | 경기도 |
| 신윤복 | 33 | 서울특별시 |
| 김광균 | 34 | 서울특별시 |
| 한용운 | 35 | 경상남도 |
| 박두진 | 36 | 경기도 |
classes 테이블
| name | class_name |
|---|---|
| 이황 | 데이터베이스 |
| 이황 | 알고리즘 |
| 정약용 | 데이터베이스 |
| 김정호 | 자료구조 |
| 박지원 | 데이터베이스 |
| 김홍도 | 알고리즘 |
| 신윤복 | 자료구조 |
| 신윤복 | 알고리즘 |
| 김광균 | 데이터베이스 |
| 김광균 | 자료구조 |
| 김광균 | 알고리즘 |
JOIN을 시작하기 전에
기본적으로 JOIN을 하기 위해선 테이블을 연결하기 위한 key가 있어야 합니다. (테이블 간의 관계를 나타내려면 접점이 되는 데이터가 있어야겠죠?)
예시에서 사용할 데이터를 보시면 두 개의 테이블 모두 “name” 이라는 열을 가지고 있고, “name” 열을 이용해서 두 테이블을 엮어보겠습니다.
참고로 students와 classes의 관계는 1:N 관계입니다. 즉, 학생 한 명이 여러 개의 강의를 수강할 수 있다는 의미이죠.
INNER JOIN
두 테이블을 연결할 때 가장 많이 사용하는 것이 INNER JOIN입니다. 보통 JOIN이라고 하면 INNER JOIN을 의미합니다.
아래는 수강 신청을 한 학생들의 정보를 조회하는 SQL문입니다.
SELECT *
FROM students AS A
INNER JOIN classes AS B
ON A.name = B.name;- INNER JOIN 전, 후로 명시한 두 개의 테이블을 JOIN한다는 의미입니다.
- students 테이블은 AS라는 구문을 이용해 A라는 별명을 붙여주었고, classes 테이블은 B라는 별명을 붙여주었습니다.
- ON 구문에는 어떤 열을 기준으로 INNER JOIN을 수행할 지 조건을 적어줍니다. 여기서는 A 테이블의 name 열과 B 테이블의 name 열을 기준으로 INNER JOIN을 수행합니다.
결과
| name | age | address | name-2 | class_name |
|---|---|---|---|---|
| 이황 | 28 | 경상북도 | 이황 | 알고리즘 |
| 이황 | 28 | 경상북도 | 이황 | 데이터베이스 |
| 정약용 | 29 | 경기도 | 정약용 | 데이터베이스 |
| 김정호 | 30 | 전라북도 | 김정호 | 자료구조 |
| 박지원 | 31 | 전라북도 | 박지원 | 데이터베이스 |
| 김홍도 | 32 | 경기도 | 김홍도 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 알고리즘 |
| 김광균 | 34 | 서울특별시 | 김광균 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 데이터베이스 |
“학생들의 나이, 주소” + “수강 신청 정보”를 한 번에 확인할 수 있습니다. 여기서 주목해야할 것은 수강 신청을 하지 않은 “한용운”, “박두진” 학생은 조회가 되지 않은 점입니다. 이는 INNER JOIN의 특성을 알아야 이해가 쉬운데요.
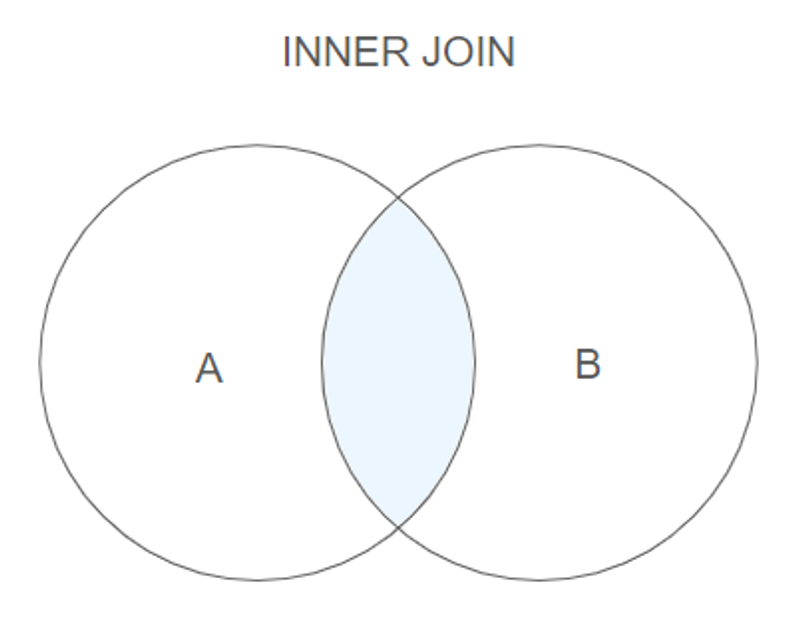
위의 그림은 INNER JOIN이 동작하는 방식을 표현하였습니다. 집합의 교집합을 생각하면 이해가 빠를 것 같은데요. 즉, student와 classes 두 테이블 모두에 지정한 열의 데이터가 있어야 INNER JOIN이 됩니다. “한용운”, “박두진” 학생은 student에는 있지만 classes에는 없기 때문에 INNER JOIN의 결과에서는 보이지 않았던 것이죠.
FULL OUTER JOIN
아래는 FULL OUTER JOIN을 이용해 students 테이블과 classes 테이블을 조회하는 SQL문입니다.
SELECT *
FROM students AS A
FULL OUTER JOIN classes AS B
ON A.name = B.name;결과
| name | age | address | name-2 | class_name |
|---|---|---|---|---|
| 이황 | 28 | 경상북도 | 이황 | 알고리즘 |
| 이황 | 28 | 경상북도 | 이황 | 데이터베이스 |
| 정약용 | 29 | 경기도 | 정약용 | 데이터베이스 |
| 김정호 | 30 | 전라북도 | 김정호 | 자료구조 |
| 박지원 | 31 | 전라북도 | 박지원 | 데이터베이스 |
| 김홍도 | 32 | 경기도 | 김홍도 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 알고리즘 |
| 신윤복 | 33 | 서울특별시 | 신윤복 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 알고리즘 |
| 김광균 | 34 | 서울특별시 | 김광균 | 자료구조 |
| 김광균 | 34 | 서울특별시 | 김광균 | 데이터베이스 |
| 한용운 | 35 | 경상남도 | NULL | NULL |
| 박두진 | 36 | 경기도 | NULL | NULL |
