Python Pypy 비교
https://www.acmicpc.net/blog/view/55
백준 알고리즘 이용에 관해서 설명한 글에서 기타 FAQ 부분에 이런 내용이 있었다.
Q. 파이썬으로 OOOO번을 시간 내에 못 푸나요?
A. 파이썬이 원래 극도로 느리기 때문에 제대로 된 풀이로도 시간초과가 날 수 있습니다.
그럴 때는 Pypy로 제출하시면 웬만한 문제들은 풀 수 있습니다.
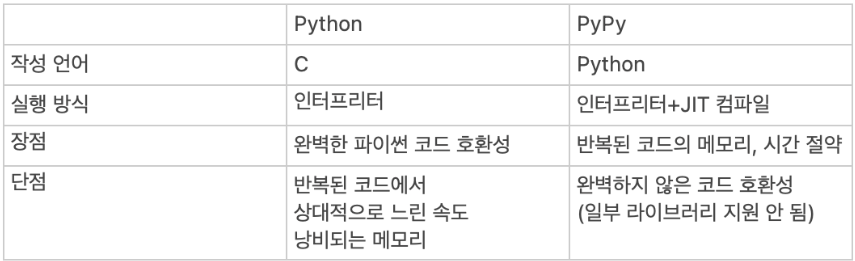
(꽤 어려운 문제들의 경우 이것도 안 될 수도 있습니다.)파이썬이 인터프리터 언어로 컴파일 언어에 비해서 느리다는 걸 알았지만
Pypy는 느린 속도를 보완한 언어라는 건가 싶어서 알아보았다.
결론부터 얘기하자면 반복적으로 사용되는 코드가 많은 경우 Pypy가 유리하고
반복 사용이 안되면서 간단한 코드는 Python이 더 유리하다고볼 수 있다.
Python Pypy 차이
JIT(Just-In-Time) 컴파일이란?
인터프리터 언어에서 프로그램 실행속도를 올리기 위해서
실행 도중에 필요한 코드가 있을 때마다 컴파일하는 실행 방법이다.
제대로 이해하기 위해선 인터프리터 방식, 컴파일 방식, JTI 컴파일 방식을 구분하는게 좋다.
- 인터프리터 방식: 소스 코드를 빌드하지 않고, 런타임 시 한 줄씩 읽으며 변환해 실행한다.
- 컴파일 방식: 소스 코드를 빌드시 컴파일하여 기계어로 변환하고, 런타임 시 기계어를 실행한다.
- JIT 컴파일 방식: 소스 코드를 빌드하지 않고, 런타임 시 한 줄씩 읽으며 변환해 실행하고
반복된 코드는 컴파일하여 기계어로 실행하여 반복해서 읽으며 변환하지 않는다.
JIT 방식은 반복되는 함수나 반복문은 컴파일하여 실행해
인터프리터가 한 번 컴파일한 부분은 다시 읽지 않아도 되서 절약이 된다.
JVM도 pypy와 마찬가지로 JIT방식을 사용한다.
예제코드 적용 결과
백준 알고리즘 문제에서 반복문을 많이 사용한 코드를 python과 pypy를
각각 적용하여 메모리와 실행시간을 비교해보았다.
9020번 : https://www.acmicpc.net/problem/9020
import sys
input = sys.stdin.readline
# 골드바흐 수: 2보다 큰 모든 짝수는 두 소수의 합으로 나타낼 수 있다.
# 소수인지 판별하는 함수
def is_prime(num):
cnt = 0
for i in range(2,num+1):
if(num%i==0):
cnt+=1
if(cnt==1):
return True
return False
# 2~Max까지의 소수를 구해 리스트로 만들기
def make_prime_list(max):
sosu_list = []
for i in range(2,max):
if(is_prime(i)):
sosu_list.append(i)
return sosu_list
# 압력된 값에서 리스트에서 중복을 허용하여 두 소수를 뽑아 합이 일치하는 쌍 구하기
def get_couple_sosu(num, sosu_list):
big_prime = int(num/2)
small_prime = int(num/2)
# 합을 나타낸 두 수가 모두 소수인 경우
if(big_prime in sosu_list and small_prime in sosu_list):
return print(small_prime, big_prime)
# 입력값/2+입력값/2가 소수에 없는 경우
else:
# 둘 중에 하나라도 소수가 아니면 값을 변경
while(big_prime not in sosu_list or small_prime not in sosu_list):
big_prime+=1
small_prime-=1
return print(small_prime, big_prime)
# 입력값 받기
T = int(input())
inputs = []
for i in range(0,T):
inputs.append(int(input()))
maxValue = max(inputs)
prime_list = make_prime_list(maxValue)
for input in inputs:
get_couple_sosu(input,prime_list)
같은 코드를 Python에서 Pypy로 바꿨을 뿐인데
실행시간은 약78%가 감소했지만
메모리는 약 358% 추가로 사용했다.
그러면 그냥 pypy만 쓰면 되는거 아닌가?
결론부터 얘기하면 현재 pypy는 호환성과 메모리 사용에 있어 아쉬움이 있다.
파이썬으로 작성된 코드는 잘 작동하지만 C언어 기반의 CPython으로 작성된 라이브러리의 경우
호환성 문제가 나타나고 있다.
또한 인터프리터 방식에 비해 추가로 컴파일하여 저장하는 코드가 있으므로 메모리 사용량이
더 많을 수 밖에 없다.
pypy가 지금도 개발 중이므로 추후에 안정화가 된다면 모든 파이썬 코드에 적용할 수 있을꺼라 기대한다.
재귀함수
재귀함수란? 종료 조건이 도달할 때까지 자신의 함수를 계속 호출하는 함수를 말한다.
함수 안에 자신을 호출하는 함수가 있다.
재귀함수를 쓰는 이유는? vs 반복문
반복문으로도 재귀함수를 하는 것과 같은 기능을 대부분 구현할 수 있으나
반복문에 비해서 재귀함수가 가지는 장점은
- 변수 갯수를 줄일 수 있다.
-> 반복문은 실행과정에서 필요한 변수를 전부 정의하고 할당해야하지만
재귀함수의 경우 재사용을 하기 때문에 정의하고 할당해야할 변수의 갯수가 적다. - 간결하게 표현할 수 있다.
-> 반복문으로 표현하면 복잡할 실행코드도 재귀함수로 표현하면
더 간결하게 표현가능하다.
재귀함수를 쓰면 불편한 경우는?
우선 재귀함수가 어떻게 동작하는지 알아야하고
그걸 적절한 수학식과 코드로 표현할 수 있어야 합니다.
- 메모리 사용량이 많다.
-> 함수를 계속 호출하기 때문에 호출할 때마다
추가로 함수와 인자를 실행정보를 메모리에 저장해야되기 때문에 - 컨텍스트 스위칭 비용이 추가로 발생한다.
-> 재귀함수 특성상 함수를 호출하고 다시 복귀하고 하는 과정을
많이 반복하게 되는데 이 과정에서 컨텍스트 스위칭 비용이 발생한다.
컨텍스트 스위칭(Context Switching)이란?
여러 프로세스 또는 스레드를 실행하는 경우
하나에서 다른 프로세스 또는 스레드로 전환하는 것을 말합니다.
기존에 실행된 정보를 저장한 게 '컨텍스트(context)'
전환과정에서 발생하는 리소스 소모를 '컨텍스트 스위칭 비용'이라고 합니다.
재귀함수는 함수를 여러번 호출하며 각 호출한 함수마다 하나의 프로세스 또는 스레드에
저장되게 됩니다.
_(under bar) in Python
_는 파이썬에서 여러 용도로 쓰이는데 주된 용도는 크게 3가지이다.
- 변수가 자리를 차지하지만 할당하고 싶지 않을 때
- import할 패키지 명을 지정해줄 때
- 숫자 자리를 구분할 때
변수에 큰 의미를 두지 않는 경우
파이썬에서는 변수가 위치상 지정하나 큰 의미를 두고 싶지 않은 경우 를 사용할 수 있다.
예를 들어 for문에 인자로 변수를 할당하지만 굳이 이름이 필요하지는 않는 경우
(under bar)로 표현할 수 있다.
for _ in range(N):
# 반복문 실행 코드import할 패키지 명을 지정해줄 때
- 폴더 안에 __init__.py라는 파일이 있으면
그 폴더를 패키지로 지정해줄 수 있다. - 함수 안에 __를 붙이면 그 함수를 import하여 쓸 수 있다.
# /underBar/__init__.py
def print_under_package():
print("use underBar package")# hello.py
def __printHello():
print("use __printHello!")# use_Under_Bar.py
import hello
import underBar
hello.__printHello()
underBar.print_under_package()
이렇게 구성하고 use_Under_Bar.py를 실행하면
지정한 함수를
숫자 자리를 구분할 때
number = 1_000_000_000
print(number)
# 출력값: 1000000000문자열을 정렬 - 람다식
inputs = ['a', 'but', 'not', 'more']
# 리스트를 길이 순으로 정렬 후, 사전 순으로 정렬
inputs.sort(key=lambda x: (len(x),x))
for word in inputs:
print(word)
# 출력값
a
but
not
more