배경
디프만에서 진행한 프로젝트에서 팔로우 한 사람들의 소식을 타임라인 형식으로 보여주는 API 가 있습니다.
해당 API 가 상당히 느리다는 제보를 받아 이를 수정하기로 결정했습니다.
원인
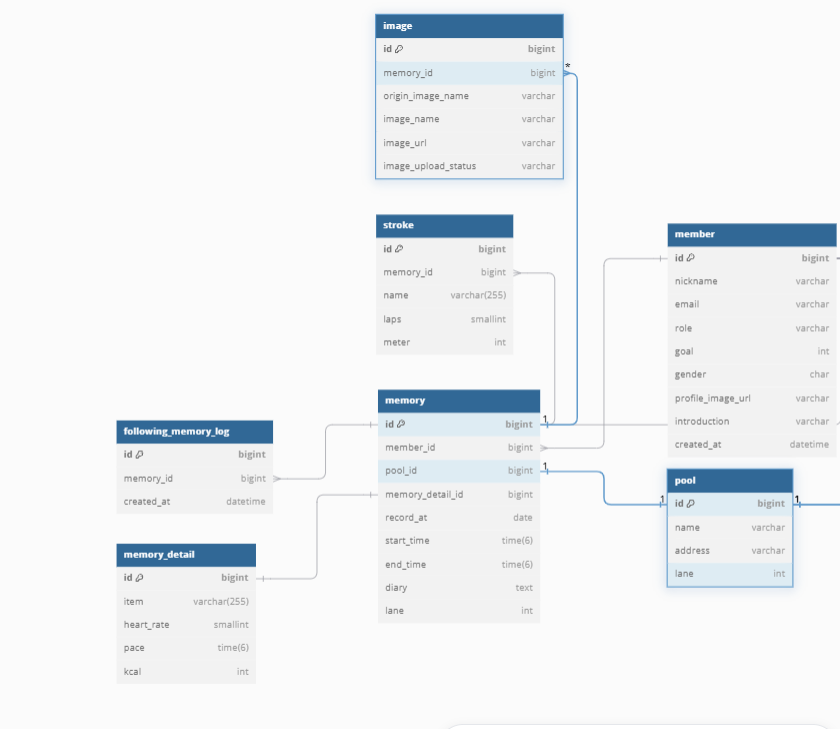
Memory에 Stroke, Image가 1:N 관계를 가진 상태입니다.
@Override
public List<FollowingMemoryLog> findLogsByMemberIdAndCursorId(Long memberId, Long cursorId) {
QFriendEntity friend = QFriendEntity.friendEntity;
List<FollowingMemoryLogEntity> contents =
queryFactory
.selectFrom(followingMemoryLog)
.join(followingMemoryLog.memory, memoryEntity)
.fetchJoin()
.join(followingMemoryLog.memory.member, memberEntity)
.fetchJoin()
.leftJoin(followingMemoryLog.memory.memoryDetail)
.fetchJoin()
.leftJoin(followingMemoryLog.memory.strokes, strokeEntity)
.fetchJoin()
.join(friend)
.on(friend.following.eq(memberEntity))
.fetchJoin()
.where(friend.member.id.eq(memberId), cursorIdLt(cursorId))
.limit(11)
.orderBy(followingMemoryLog.id.desc())
.fetch();
return contents.stream().map(FollowingMemoryLogEntity::toModel).toList();
}위의 쿼리를 통해 Memory와 1:N 관계인 데이터를 Fetch Join으로 가져오고 있었고, 페이지네이션을 적용하였습니다.
서버 로그를 확인해 본 결과, 아래와 같은 로그를 발견할 수 있었습니다.

해당 로그는 Hibernate가 모든 레코드를 메모리로 가져온 다음, 첫 번째/최대 결과 제한을 두려고 한다는 뜻입니다.
그리고 실행된 쿼리 로그를 살펴본 결과, 페이지네이션을 적용했음에도 불구하고 Limit 명령어가 적용되지 않았음을 확인할 수 있었습니다.
원인은 OneToMany 관계에서 Fetch Join을 적용한 상태에서 Pagination을 적용했기 때문이었습니다.
OneToMany 관계에서 Fetch Join으로 데이터를 한번에 다 가져오면서 하나의 Entity를 조회할 때와 달리 레코드의 개수가 변하게 됩니다. (ex - Memory : Stroke 가 1 : N 관계를 가진 경우, Memory 3개, Memory 1개 당 Stroke 3개인 경우 총 9 개의 레코드를 조회하게 됩니다.)
이로 인해 JPA는 어떤 데이터를 기준으로 Paging을 수행해야 하는 지 알 수 없게 되어 모든 레코드를 한번에 Memory에 올려둔 다음, 메모리에서 Pagination 을 수행하는 방식으로 진행하게 됩니다.
해당 방법은 Memory를 많이 사용하는 만큼, 성능 이슈를 불러올 수 있었습니다.
해결 방법
해결 방법은 생각보다 간단했습니다.
바로 Fetch Join을 해제해서 1:N 관계의 데이터들을 한번에 조회하지 않고, 쿼리를 나누어 조회하면 해결됩니다.
하지만 Fetch Join을 무작정 해제하면 N+1 문제가 발생할 수 있습니다.
이를 위해 어플리케이션 단에서 쿼리를 분리하거나, Batch Size를 조정하면 됩니다.
저는 Batch Size를 조절하여 N+1 문제를 해결할 수 있었습니다.
성능 비교
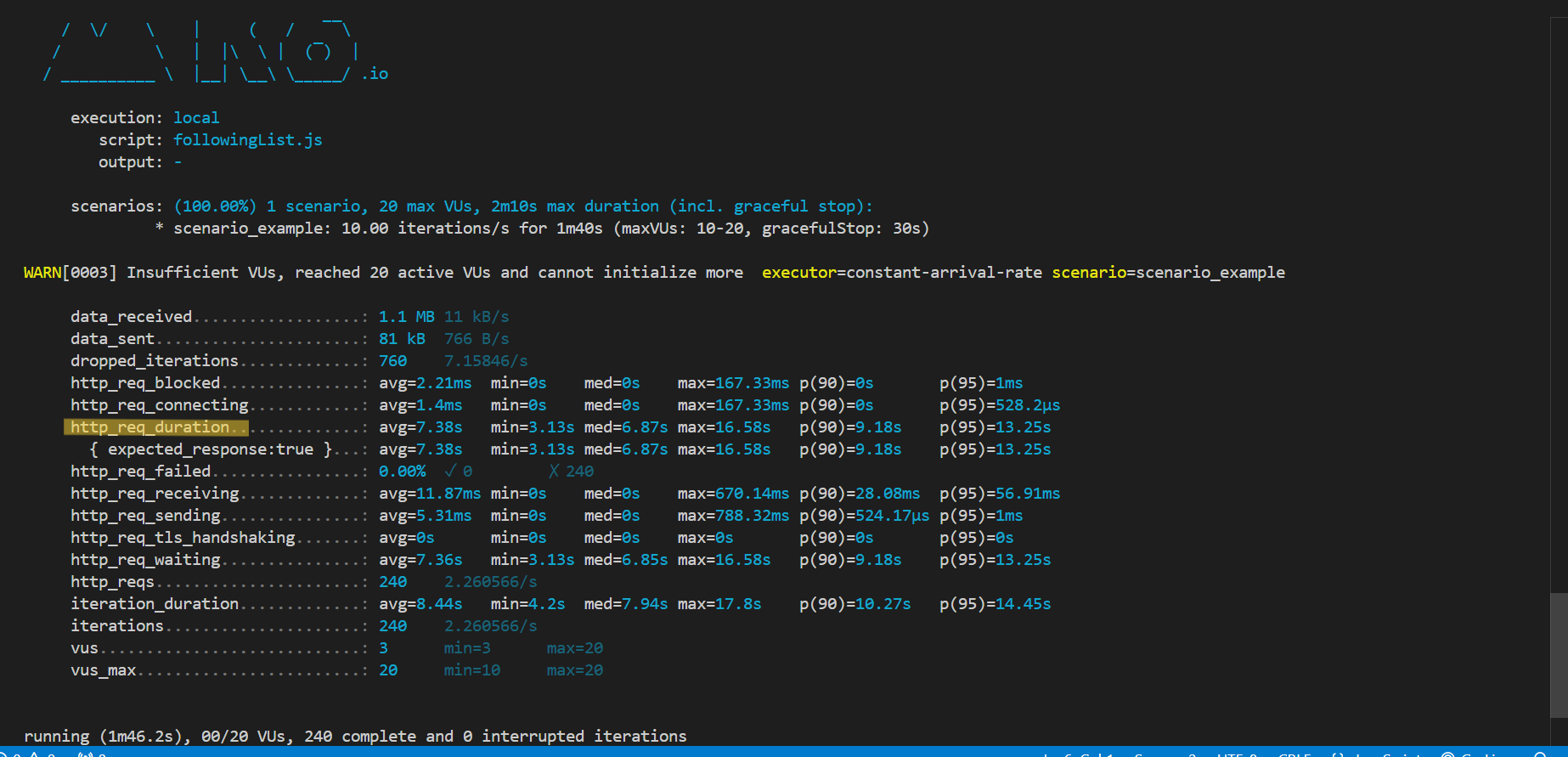
성능 비교를 위해 성능 테스트 툴인 k6을 통해 http_req_duration(원격 서버가 요청을 받고 처리하고 응답할 때까지 걸린 시간) 을 비교해봤습니다.
개선 전
개선 후
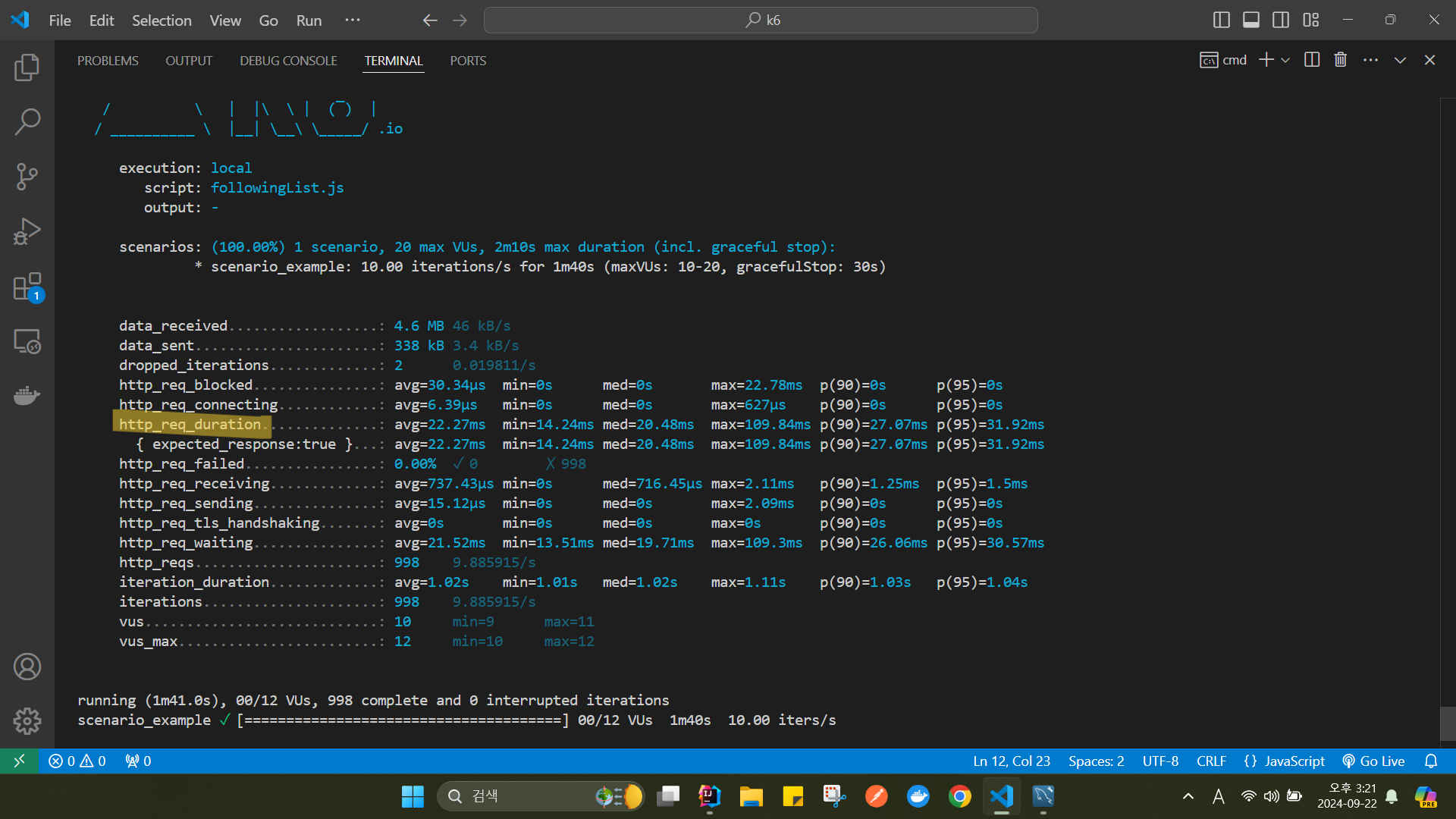
속도가 7.38sec -> 22.27ms 로 대폭 상승했음을 확인할 수 있었습니다.
