디프만에서 진행한 Swimie 서비스에는 본인이 팔로우 한 사람의 소식을 조회 할 수 있는 기능이 있습니다.
정책 상, 팔로우 소식 데이터는 현재부터 100일 간의 데이터만 보여주도록 되어 있습니다. 팔로우 소식 관련 메타 데이터를 따로 MySQL에 저장해두고 있어 100일 이전의 데이터는 모두 지워줘야 했습니다.
Spring Batch?
일반적으로 배치 프로그은 사용자와의 상호작용 없이 여러 작업들을 미리 정해진 일련의 순서에 따라 일괄적으로 처리하는 것을 뜻합니다.
배치 프로그램의 필수 요소는 아래와 같습니다.
- 대용량 데이터를 처리할 수 있어야 한다.
- 심각한 오류 상황 이외에는 사용자의 개입 없이 동작해야 한다.
- 유효하지 않은 데이터의 경우도 처리하여 비정상적인 동작 중단이 발생하지 않아야 한다.
- 어떤 문제가 생겼는지, 언제 발생했는지 등을 추적할 수 있어야 한다.
- 주어진 시간 내에 처리를 완료할 수 있어야 하고, 동시에 동작하고 있는 다른 애플리케이션을 방해하지 말아야 한다.
Spring Batch 의 경우 Spring Framework의 특성 기반으로 하고, 로깅 및 추적, 트랜잭션 관리, 재시도 및 재처리, 병렬 처리 등 대량의 데이터를 처리하는데 팔요한 기능들을 제공합니다.
Spring Batch VS Scheduler
종종 Batch와 Scheduler 가 비교되곤 합니다. 하지만 둘의 역할은 완전히 다릅니다.
Scheduler는 특정 비즈니스 작업을 일정 시간 동안 반복할 때 사용됩니다. 반면 배치는 대용량 데이터를 처리할 때 사용됩니다.
이로 인해 Batch에서 일정 시간마다 배치 작업을 실행해야 할 때 Scheduler를 같이 사용하고는 합니다.
Spring Batch 구조
Spring Batch는 아래와 같은 구조로 설계되었습니다.
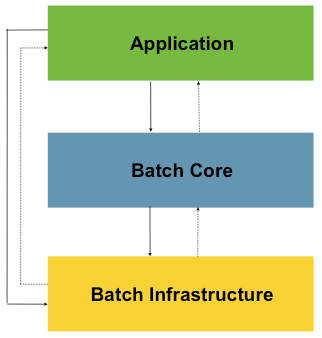
-
Application : 개발자가 작성한 모든 배치 작업과 사용자 정의 코드
-
Batch Core : 배치 작업을 시작하고 필요한 핵심 런타임 클래스(JobLauncher, Job, Step)
-
Batch Infrastructure : 개발자와 어플리케이션이 사용하는 Reader, Writer, RetryTemplate
이러한 Spring Batch 구조로 인해 개발자는 Application 계층의 비즈니스 로직에 더 집중할 수 있게 되었고, Batch Core 의 클래스들로 배치의 동작을 제어할 수 있게 되었습니다.
Spring Batch 용어
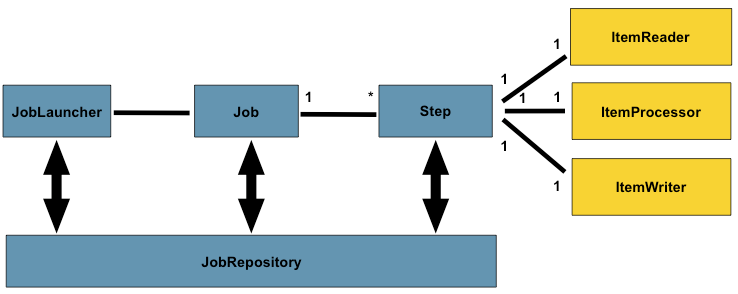
Spring Batch에서 자주 사용하는 용어는 아래와 같습니다.
Job
전체 배치 프로세스를 캡슐화한 엔티티로 Step 인스턴스를를 위한 컨테이너입니다. 여러 Step를 가질 수 있습니다. Java 혹은 XML 파일로 설정할 수 있습니다.
Job 구성 요소
-
Job 고유의 이름
-
Step 정의 및 순서 설정
-
Job 재시작 유무
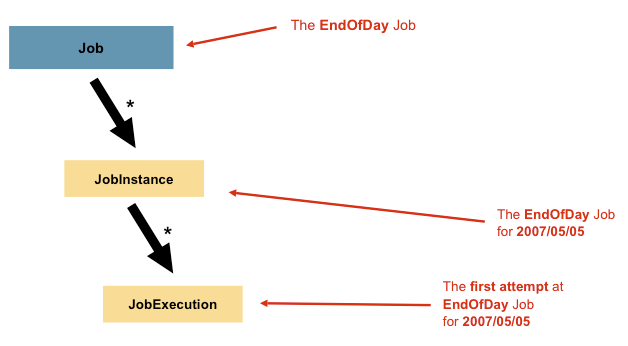
Job Instance
배치 처리에서 Job 이 실행될 때 하나의 논리적 작업 실행 단위 입니다. 만약 하루에 한번 실행되어야 하는 Job가 있다면 Job Instance는 하루에 1개씩 생성됩니다. (1월 1일 JobInstance, 1월 2일 JobInstance, …)
한번 생성된 JobInstance는 해당 날짜의 데이터를 처리하는데 사용되며, 만약 실행이 실패한 경우, 같은 JobInstance를 다시 실행하여 작업을 완료할 수 있습니다.
Job Parameter
Job Instance를 구분하기 위해 사용되는 파라미터입니다. 매일 8시에 실행되는 배치에 2024/10/01 에 실행된 Job Instance의 파라미터는 startDate=2024/10/01 이 됩니다.
JobExecution
JobInstance의 1회 시행 시도를 뜻합니다. 만약 1번 배치 실행이 실패하면 동일한 JobInstance가 실행되고, 다른 JobExecution이 생성됩니다.
Step
Job의 하위 단계로 실제 배치 작업이 이루어지는 단위입니다. 1개 이상의 Step로 Job가 구성되며, 각 Step는 순차적으로 일어납니다.
Tasklet vs Chunk
Tasklet는 단순히 하나의 Step에서 단일 작업을 수행하도록 설계되었습니다. 복잡한 로직이 필요 없는 간단한 작업에 적합합니다.
Chunk는 대규모 데이터를 효율적으로 처리하기 위한 작업으로 데이터를 작은 Chunk단위로 나누어 처리하고, 트랜잭션도 Chunk 단위로 이루어집니다.
또한 Chunk 방식은 ItemReader, ItemProcessor, ItemWriter로 구성되어 있습니다.
ItemReader
배치 작업에서 처리할 아이템을 읽어옵니다. 여러 형식의 데이터 소스로부터 데이터를 읽어오는 다양한 ItemReader 구현체가 제공됩니다.
ItemProcessor
ItemReader에서 읽어온 아이템을 변환시킬 수 있습니다. 경우에 따라서는 사용하지 않아도 됩니다.
ItemWriter
ItemProcessor에서 처리한 데이터에 대해 최종적으로 기록하는 역할을 합니다.
JobRepository
배치 작업 관련 모든 정보를 저장하는 메커니즘입니다. Job Launcher, Job, Step 구현을 위한 CRUD 연산을 제공합니다. Job 실행과정에서 생성된 StepExecution, JobExecution은 저장소로 저장되고, 이를 통해 실행 상태를 추적합니다.
JobLauncher
작업의 시작과 실제 실행을 관리하는 인터페이스로, Job와 Job Parameter를 받아 Job를 실행시킵니다.
작성한 코드
해당 코드는 Spring Boot 3 기준으로 작성되었습니다.
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-batch'application.yml
spring:
datasource:
url: ${MYSQL_URL}
username: ${MYSQL_USERNAME}
password: ${MYSQL_PASSWORD}
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: none
properties:
hibernate:
format_sql: true
show-sql: true
batch:
job:
enabled: true # default 값은 true, 만약 false인 경우 스프링이 자동으로 job를 샐행하는 것을 막습니다.
name: ${JOB_NAME:NONE} # 지정한 배치 Job 만 실행되도록 Job 이름 설정, :NONE 은 환경변수로 JOB_NAME이 넘어오지 않으면 배치가 실행되지 않도록 한다.
jdbc:
initialize-schema: always # always로 설정 시 어플리케이션이 실행될 때마다 배치 메타테이터 테이블을 자동 생성해준다.
logging:
level:
org:
orm:
jpa: INFO추가적으로 spring.batch.job.name에서 여러 job 이름을 , 로 명시해서 실행하는 기능이 제거되었습니다.
BatchConfig
만약 커스텀한 JobLauncherApplicationRunner이 필요하면 커스텀한 BatchConfig를 생성해주면 됩니다.
@Configuration
@EnableConfigurationProperties(BatchProperties.class) // (1)
public class BatchConfig {
@Bean
@ConditionalOnMissingBean
@ConditionalOnProperty(
prefix = "spring.batch.job",
name = "enabled",
havingValue = "true",
matchIfMissing = true) // (2)
public JobLauncherApplicationRunner jobLauncherApplicationRunner(
JobLauncher jobLauncher,
JobExplorer jobExplorer,
JobRepository jobRepository,
BatchProperties properties) {
JobLauncherApplicationRunner runner =
new JobLauncherApplicationRunner(jobLauncher, jobExplorer, jobRepository); // (3)
String jobName = properties.getJob().getName();
if (StringUtils.hasText(jobName)) {
runner.setJobName(jobName); // (4)
}
return runner;
}
}@EnableConfigurationProperties(BatchProperties.class) : BatchProperties의 설정 값을 가져옵니다.
@ConditionalOnMissingBean : 프로젝트에 동명의 Bean이 정의되었을 경우 해당 Bean을 사용하지 않고, 동명의 Bean이 존재하지 않으면 현재 등록된 Bean을 쓰게끔 유도합니다. 해당 어노테이션으로 Spring Boot에서 자동으로 추가되는 해주는 JobLauncherApplicationRunner가 사용자가 설정한 JobLauncherApplicationRunner 빈을 덮어 쓰지 않게 해줍니다.
@ConditionalOnProperty : Property(application.yml)에 해당하는 값이 특정 조건을 만족할 때만 Bean을 생성해줍니다. 해당 코드에는 spring.batch.job.enabled 값이 true인 경우에만 빈을생성하도록 되어 있다. matchIfMissing 은 매칭되는 것이 없으면 빈을 생성할지 말지 결정하는 속성으로 만약 application.yml에 spring.batch.job.enabled 속성이 누락되어도 빈을 생성할 수 있도록 true로 설정해주었습니다.
StringUtils.hasText(jobName) : BatchProperties에서 설정된 job.name을 가져와 빈 문자열이 아니라면 runner에 설정을 해줍니다. 이 설정을 통해 실행 될 Batch Job를 지정해줄 수 있습니다.
(사실 이 클래스는 기존 스프링 부트의 BatchAutoConfiguration과 설정이 똑같아서 굳이 추가를 해주지 않아도 되지만 만약 JobLauncherApplicationRunner를 커스터마이징 해주어야 하는 상황이라면 위와 같은 설정에 부가적인 설정을 해주어야 합니다.)
JobConfig
실행 시킬 Job를 설정해주는 클래스입니다.
@Configuration
@RequiredArgsConstructor
public class FollowingLogDeleteJobConfig {
private final PlatformTransactionManager transactionManager;
private final FollowingLogDeleteJobExecutionListener listener;
private final FollowingLogItemReader itemReader;
private final FollowingLogItemWriter itemWriter;
@Bean
public Job followingLogDeleteJob(JobRepository jobRepository) {
return new JobBuilder("followingLogDeleteJob", jobRepository) // (1)
.listener(listener)
.start(followingLogDeleteStep(jobRepository)) // (2)
.build();
}
@Bean
@JobScope // (3)
public Step followingLogDeleteStep(JobRepository jobRepository) {
return new StepBuilder("followingLogDeleteStep", jobRepository)
.<FollowingMemoryLogEntity, FollowingMemoryLogEntity>chunk(10, transactionManager)
.reader(itemReader) // (4)
.writer(itemWriter) // (5)
.allowStartIfComplete(true)
.build();
}
}@Bean
public Job followingLogDeleteJob(JobRepository jobRepository) {
return new JobBuilder("followingLogDeleteJob", jobRepository) // (1)
.listener(listener)
.start(followingLogDeleteStep(jobRepository)) // (2)
.build();
}(1)
Job 이름을 설정해줍니다.
(2)
Job 실행 전후 로그 생성을 위해 listener를 추가해주었습니다.
추가할 listener가 없다면 삭제해도 좋습니다.
FollowingLogDeleteJobExecutionListener
@Slf4j
@Component
@RequiredArgsConstructor
public class FollowingLogDeleteJobExecutionListener implements JobExecutionListener {
@Override
public void beforeJob(@NonNull JobExecution jobExecution) {
log.info("100일 이후의 FollowingMemoryLog 삭제 Batch Job 시작");
}
@Override
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("100일 이후의 FollowingMemoryLog 삭제 Batch Job이 완료되었습니다");
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
log.error("100일 이후의 FollowingMemoryLog 삭제 Batch Job이 실패하였습니다");
} else {
log.info(
"100일 이후의 FollowingMemoryLog 삭제 Batch Job 종료 Status : {}",
jobExecution.getStatus());
}
}
}JobExecutionListener 는 Job 성공/실패와 상관없이 실행되는 이벤트 리스너입니다. 실행 전/후 로그를 남기기 위해 beforeJob, afterJob 를 Override 했으며, afterJob 에서 배치 성공/실패에 따라 로그를 다르게 남기기 위해 Batch Status에 따라 로그를 다르게 남기도록 분기처리를 했습니다.
@Bean
@JobScope // (3)
public Step followingLogDeleteStep(JobRepository jobRepository) {
return new StepBuilder("followingLogDeleteStep", jobRepository)
.<FollowingMemoryLogEntity, FollowingMemoryLogEntity>chunk(10, transactionManager) // (4)
.reader(itemReader) // (5)
.writer(itemWriter) // (6)
.allowStartIfComplete(true)
.build();
}(3)
Job 내부의 Step를 선언해줍니다.
@JobScope는 Job Parameter를 사용하기 위해 선언해주어야 합니다.
@JobScope는 Spring Batch 실행 시 Job 실행 시점에 Bean을 생성하게 해줍니다.
(4)
chunk는 각 커밋 사이에 처리되는 row 수를 뜻합니다.
한번에 하나씩 데이터를 읽어 Chunk 라는 덩어리를 만들고, Chunk 단위로 트랜잭션을 다룹니다.
만약 도중 Batch가 실패할 경우 Chunk 만큼 롤백이 되고 이전까지의 커밋은 트랜잭션이 반영됩니다.
(5)
데이터를 읽어오기 위해 ItemReader를 설정해줍니다.
Spring 같은 경우 DB, XML, JSON, File 등의 데이터를 배치로 읽어올 수 있는데 여기서는 DB의 데이터를 처리합니다.
ItemReader의 경우 대표적인 구현체로 JdbcCursorItemReader, JdbcPagingItemReader, JpaPagingItemReader 가 존재하여 해당 구현체를 활용하여도 되나 ItemReader 인터페이스를 커스텀하게 구현하여 사용해도 됩니다.
저희 팀 같은 경우 ItemReader를 커스텀하게 구현하는 방법을 사용했습니다.
@StepScope
@Component
public class FollowingLogItemReader implements ItemReader<FollowingMemoryLogEntity> {
@PersistenceContext private EntityManager em;
private static final int PAGE_SIZE = 10;
private int currentIndex = 0;
private List<FollowingMemoryLogEntity> followingMemoryLogEntities;
@Override
public FollowingMemoryLogEntity read() {
if (followingMemoryLogEntities == null
|| currentIndex >= followingMemoryLogEntities.size()) {
fetchNextPage();
}
if (followingMemoryLogEntities != null
&& currentIndex < followingMemoryLogEntities.size()) {
return followingMemoryLogEntities.get(currentIndex++);
}
return null;
}
private void fetchNextPage() {
currentIndex = 0;
LocalDateTime now = LocalDateTime.now();
LocalDateTime before100Days = now.minusDays(100);
TypedQuery<FollowingMemoryLogEntity> query =
em.createQuery(
"SELECT f FROM FollowingMemoryLogEntity f WHERE f.createdAt < :date",
FollowingMemoryLogEntity.class);
query.setParameter("date", before100Days);
query.setFirstResult(currentIndex);
query.setMaxResults(PAGE_SIZE);
followingMemoryLogEntities = query.getResultList();
}
}위의 코드는 만약 최초로 데이터를 읽어올 때 (followingMemoryLogEntities 가 null 인경우) fetchNextPage() 메서드로 한번에 데이터를 10개씩 가져옵니다.
이후 데이터를 해당 데이터를 하나씩 ItemWriter로 전달합니다.
fetchNextPage()로 읽어온 데이터를을 ItemWriter로 다 전달하면(pageSize 만큼) 다음 데이터로 이동합니다. 만약 더이상 읽어올 데이터가 없다면 null을 리턴하여 ItemReader를 종료시킵니다.
@PersistenceContext private EntityManager em; 은 EntityManager를 빈으로 주입할 때 사용하는 어노테이션으로 EntityManagerFactory에서 새로운 EntityManager를 생성하거나 혹은 Transaction에 의해 기존의 EntityManager를 반환해줍니다.
일반적으로 스프링은 싱글톤 기반으로 동작하기 떄문에 EntityManager를 여러 스레드에서 공유를 하며 사용하는데, @PersistenceContext 를 추가해주어 동시성 문제가 발생하지 않습니다.
(6)
ItemReader에서 읽어온 데이터를 ItemWriter에서 처리를 해줍니다.
중간에 데이터를 가공하기 위해 ItemReader와 ItemWriter 사이 ItemProcessor 단계를 추가해주어도 되나 해당 코드에는 필요가 없어 추가하지 않았습니다.
데이터가 chunk 만큼 쌓인 뒤에 ItemWriter로 전달이 되어 chunk 단위로 작업이 실행됩니다.
ItemWriter 에도 대표적으로 JdbcBatchItemWriter, HibernateItemWriter, JpaItemWriter 가 있고, ItemWriter 인터페이스를 직접 구현해도 됩니다.
저희 팀 같은 경우 ItemWriter 역시 커스텀하게 만들어 구현하였습니다.
@StepScope
@Component
@RequiredArgsConstructor
public class FollowingLogItemWriter implements ItemWriter<FollowingMemoryLogEntity> {
@PersistenceContext EntityManager em;
@Override
public void write(Chunk<? extends FollowingMemoryLogEntity> chunk) throws Exception {
List<? extends FollowingMemoryLogEntity> followingMemoryLogEntities = chunk.getItems();
List<Long> followingMemoryLogIds =
followingMemoryLogEntities.stream().map(FollowingMemoryLogEntity::getId).toList();
if (!followingMemoryLogIds.isEmpty()) {
em.createQuery("DELETE FROM FollowingMemoryLogEntity f WHERE f.id IN :ids")
.setParameter("ids", followingMemoryLogIds)
.executeUpdate();
em.flush();
}
}
}ItemReader에서 데이터를 읽어와 chunk 단위 만큼 데이터가 쌓이면 chunk 단위만큼 트랜잭션이 작동이 됩니다.
주의해야 할 점은 delete 를 하기 위해 벌크 연산을 사용했는데, 벌크 연산의 경우 영속성 콘텍스트를 무시하고 데이터베이스에 직접 쿼리를 하기 때문에 영속성 콘텍스트와 DB 의 데이터가 불일치하게 되는 문제가 발생합니다.
이를 해결하기 위해 마지막에 em.flush()를 추가해줍니다.
마무리
이후 완성된 배치를 실행 시킬 스케쥴링이 필요합니다.
저희 팀 같은 경우 기존에 Jenkins를 활용하고 있었고, 멀티모듈로 Batch 서버를 기존 서버와 분리해두었으며, 특정 시간대에만 Batch를 실행 시키기만 하면 되어서 Jenkins로 특정 시간에 Batch를 실행 시키도록 설정을 해주었습니다.
