서론
이전 글에서 인덱스의 자료구조에 대해 알아보았다. 이번엔 인덱스의 타입에 대해 알아보자. 인덱스는 두 가지의 타입이 있는데, 하나는 Clustered Index, 하나는 Non Clustered Index이다.
타입에 따라 인덱스를 설정하기에 좋은 조건과 나쁜 조건이 있는데, 이유가 뭔지 실제로 인덱스가 어떻게 구성되고 값을 찾아서 어떻게 탐색 하는지 보면 알 수 있다.
Clustered Index
Clustered Index를 사용하면 테이블에 데이터가 순서대로 저장된다. 인덱스 자체에 순서가 생기고 그 인덱스에 데이터를 직접 연결한다. 그렇기 때문에 한 테이블에는 한 개의 Clustered Index만 존재하게 된다.
MySQL에서는 Primary Key를 생성하면 자동으로 Clustered Index가 설정 된다.
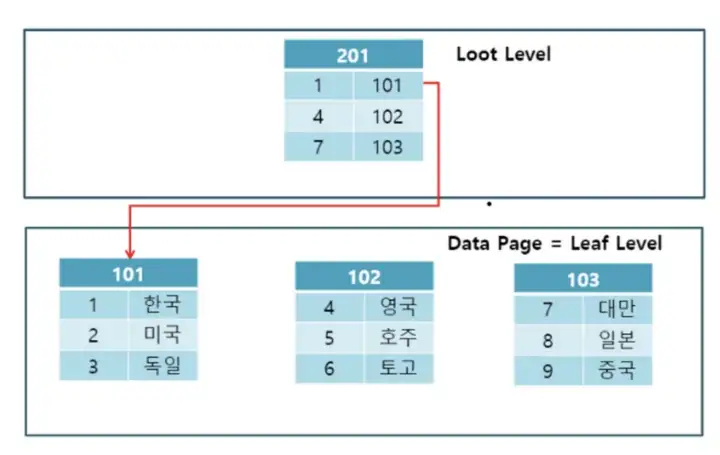
위 처럼 Clustered Index는 하나의 루트노드와 여러 개의 리프노드를 가지게 되며 루트 노드에 인덱스와 찾으려는 데이터가 저장된 데이터 페이지가 함께 존재하게 된다.
1이라는 Index를 가진 데이터를 찾으려면 101번 데이터 페이지로 이동하게 되고 이 데이터 페이지 안에 데이터가 존재하게 된다.
Clustered Index의 경우에 B tree구조로 탐색이 빠르지만 만약 중간에 값을 삽입하거나 중간에 값을 바꾸는 경우 순서를 다시 재정렬하는 페이징 과정이 일어나므로 효율이 좋지 않다. 삭제하는 경우도 중간에 값이 삭제되어 B Tree 구조를 유지해야 하기 때문에 동일하다.
즉 Clustered Index는 자주 업데이트 되지 않는 경우, 정렬이 필요한 경우, 읽기 작업이 많은 경우 유리하다.
또 정렬되어 있기 때문에 부등호 연산으로 범위 값을 가져오는 경우, JOIN 조건에 사용하는 경우에도 유리하며 정렬 동작으로 많은 리소스를 소모하는 ORDER BY, GROUP BY 연산시에도 유리하다.
Non Clustered Index
Non Clustered Index는 테이블에 저장된 데이터들을 물리적으로 정렬하지 않는다. 대신 인덱스 페이지를 따로 생성한다. 따라서 Clustered Index와 다르게 한 테이블에 여러 개의 Index를 설정할 수 있다.
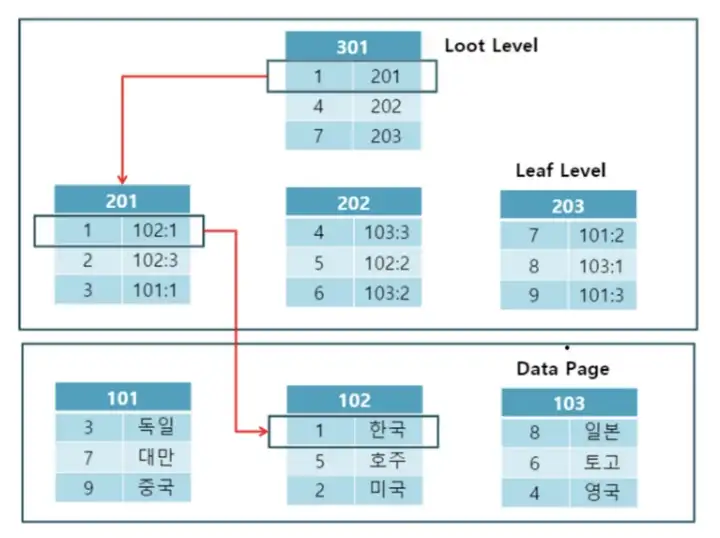
Non Clustered Index의 경우엔 루트 노드와 여러 개의 리프 노드(인덱스 페이지) 그리고 그 인덱스 페이지들이 데이터 페이지와 연결되어 있다.
한국이라는 데이터를 찾기 위해서 1번 인덱스로 검색을 시작하면 먼저 201번 인덱스 페이지로 이동한다. 그리고 201번 인덱스 페이지에서 값이 102번 데이터 페이지의 1 위치에 존재한다는 포인터를 보고 데이터 페이지에 접근하게 된다.
Non Clustered Index는 이렇게 검색을 위해 한 단계를 더 거치기 때문에 Clustered Index보다 검색이 느리지만 데이터를 매 삽입, 수정, 삭제에 정렬 시킬 필요가 없어 이 경우엔 유리하다.
하지만 한 테이블에 인덱스가 많아지면 한 번의 수정, 삭제에 있어서 건드려야 하는 인덱스 페이지가 많아지기 때문에 업데이트가 자주 발생하지 않는 테이블에 설정하는 것이 좋다.
또 인덱스의 경우 선택도가 5~10% 정도에 설정하는 것이 좋은데, 이유는 데이터 내 중복되는 값이 많으면 인덱스 테이블을 타고 데이터 페이지에 접근하는 것 보다 데이터 페이지에 바로 접근하여 테이블을 스캔하는 편이 더 좋을 수 있기 때문이다.
