서론
백엔드 개발을 처음 배울 때 데이터베이스에 쿼리를 날릴 때는 생 쿼리를 작성해서 넣곤했다. 어떤 언어의 어떤 프레임워크 또는 라이브러리를 쓰느냐에 따라 달랐지만 일반적으로preparedStatement에 쿼리문을 문자열로 넣고 직접 통신하는 방식으로 배웠다.
하지만 지금 사용하는 모든 백엔드 프레임워크에는 무조건 적용할 수 있는 ORM 기술이 있다. Django는 자체적으로 ORM이 존재하고 NodeJS 진영에는 TypeORM이 있고 Java 진영에는 JPA가 존재한다.
원래 Typescript를 사용한 TypeORM을 사용해본적이 있어서 최근 포트폴리오용 프로젝트에 JPA를 대강 아는채로 바로 적용해보았다. 하지만 한 번 제대로 알아두어야 하겠다는 생각이 들었고 유튜브에 무료 강의중 굉장히 좋은 강의가 한글로 있어서 듣고 배운 점에 대해서 적어보려고 한다.
이 글은 유튜브 강의 및 구글링을 통해 배운 내용을 정리한 것으로 글에 오류가 있을 수 있습니다.
이 글은 JPA를 간단히 사용해본 사람이 조금 더 코어한 부분을 알고자 정리한 내용으로 사용 방법은 없고 코드도 간단하게 개념을 작성한 내용이라 작동하지 않을 수 있습니다.
JPA를 사용하는 이유
기본적으로 JPA와 같은 ORM은 백엔드 코드를 작성하는 언어와 데이터베이스 사이의 통신을 돕는 역할을 한다. 즉 쿼리문을 날리지 않고 자바 코드로 데이터베이스를 건드릴 수 있게 해주는게 주 역할을 한다.
따라서 복잡한 쿼리를 직접 작성할 필요가 없이 Java 코드로 대부분의 문제를 해결할 수 있게 된다. 일반적으로 쿼리를 작성한다 하면 위에 언급한 것 처럼 문자열을 보내게 되는데, 그렇게 하면 컴파일 과정에서 에러를 잡기가 힘들다.
또 방언이라는 게 존재한다. 방언은 JPA가 데이터베이스를 해석하는 방식을 말하는데, 통일된 자바 코드로 여러 다른 종류의 데이터베이스에 적용할 수 있도록 만들어져 있다. 만약 PostgreSQL을 사용하다가 어떠한 이유로 MySQL을 사용해야 할 일이 생기면 서로 다른 쿼리 문법 때문에 이동 자체가 불가능할 수 있는데 JPA는 이러한 문제를 알아서 해결 해준다.
그리고 JPA는 이런 단순한 문제보다 더 굉장히 중요한 문제를 해결해준다.
Java 언어는 객체지향 언어이므로 원시 타입을 제외하면 모든 것이 객체이다. 하지만 데이터베이스는 그렇지 않다. 데이터베이스는 SQL이라는 특수한 언어를 사용한다. 이 부분에서 Java 코드와 데이터베이스의 패러다임 불일치가 생긴다.
하나는 상속이다. 객체지향의 가장 중요한 특징 중 하나인데, SQL은 상속이라는 기능이 아예 없다. 만약 신발을 판매하는 이커머스의 백엔드를 개발한다고 하자.
신발만을 판매해오다가 사업을 확장해서 옷도 판매한다고 해보자. 제품 테이블은 제품 이름과 제품 사진, 가격 등 공통된 애트리뷰트를 가지고 있을 수 있지만 신발만의 고유한 치수와 같은 애트리뷰트가 존재하므로 이때문에 장바구니나 주문 시스템 등에 모두 영향을 줄 수 있다.
class Shoes {
private Long Id;
private String name;
private Integer price;
private String itemImage;
}하지만 JPA는 객체지향의 상속을 데이터베이스에 적용시킬 수 있도록 해준다. 즉 제품이라는 클래스에 공통된 제품 애트리뷰트를 넣고 또 다른 특징을 가진 제품이 생기면 그냥 제품을 상속 받아서 추가할 수 있도록 해준다.
class Item {
private Long Id;
private String name;
private Integer price;
private String itemImage;
private Integer size;
}
상속 이전의 객체
class Shoes extends Item {
private Integer size;
}class Item extends Bottom {
private BottomType bottomType;
}공통된 속성인 Item을 받고 추가 속성들을 넣는다.
또 다른 JPA의 패러다임 불일치 해결은 어떤 서비스를 이용하는 사용자 정보가 있고 Java 코드로 그 사용자를 가져온다고 하자.
User user1 = userDao.getUserById(1L);
User user2 = userDao.getUserById(1L);이렇게 한 유저의 정보를 다른 변수에 담는다고 하자.
여기서 if (user1 == user2) 는 어떤 결과를 보여주게 될까? 코드를 보았을 때 원래 개발자가 의도한 대로라면 당연히 true가 나와야 한다. 하지만 상황에 따라 언제든지 false일 수 있다.
기본적인 개념이지만 Call By Reference 때문이다. user1과 user2를 담는 주소가 다르다면 당연히 둘이 일치 하지 않고 만약 userDao가 다른 빈에서 가져온 객체라면 결과가 다르게 나올 수 있기 때문이다.
하지만 JPA는 이러한 문제들을 바로 영속성 컨텍스트라는 개념을 도입하여 모두 해결해준다.
영속성 컨텍스트
영속성 컨텍스트는 굉장히 추상적인 개념인데, 이해하기가 조금 어려울 수 있다. 먼저 영속성은 Entity 즉 테이블의 애트리뷰트를 저장하는 환경을 뜻한다.
컨텍스트는 최근 안드로이드 개발을 하면서도 굉장히 헷갈렸던 개념인데, 어떠한 구조의 정보들 의미한다. 즉 둘을 합치면 테이블의 구조나 속성등 등을 알고 있는 추상적인 환경을 의미하게 된다.
나름대로 이해를 하고 의식의 흐름대로 작성한 내용이다.
즉 자바 코드와 영속성 컨텍스트와 데이터베이스는 대강 아래와 같은 구조를 가지게 되는데
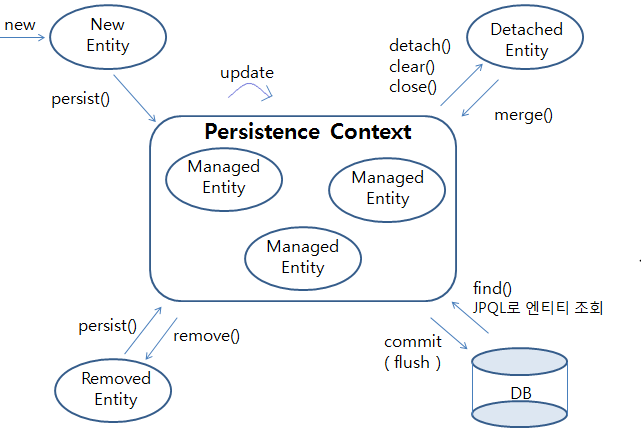
엔티티가 영속성 컨텍스트에 접근하고 그 안에 영속 상태가 되어 저장된 다음 DB와 통신을 하게되는 구조를 가지게 된다.
간단히 말하자면 자바의 객체지향 적인 부분을 JPA가 알아서 쿼리문으로 변경해서 DB에 날린다고 보면 된다.
JPA Entity의 생명 주기
위 사진을 보면 엔티티에 다양한 종류가 있는데, JPA에는 이 각 Entity에 생명주기가 존재한다.
- 비영속 상태:
@Entity어노테이션으로 지정된 객체를new키워드로 생성한 상태 - 영속 상태:
em.persist(entity)를 통해 영속성 컨텍스트안에 들어가서 영속성 컨텍스트의 관리를 받는 상태(이 경우엔 캐시 및 스냅샷이 생성된다. 이후 설명) - 준영속 상태:
em.detach(entity)를 통해 영속성 컨텍스트 안의 엔티티를 꺼낸 상태 em.remove(entity)를 통해 엔티티를 삭제한 상태
이렇게 영속성 컨텍스트안에 들어간 영속 상태의 엔티티들이 영속성 컨텍스트의 관리를 받는데, 이를 통해 JPA는 성능에서의 이점을 얻을 수 있다.
기본적으로 JPA는 데이터베이스와 Java 사이에 무언가를 더한 형태라서 성능 상에서의 불리한 점이 있다고 하지만 생명주기를 통해 이러한 문제를 해결한다.
하나는 1차 캐시이다. 만약 한 트랜잭션에서 한 명의 유저를 두 번 조회할 일이 있다고 해보자. 일반적인 경우에는 당연히 Java에서 데이터베이스에 두 번의 쿼리를 통해 유저 정보를 가져오게 될 것이다.
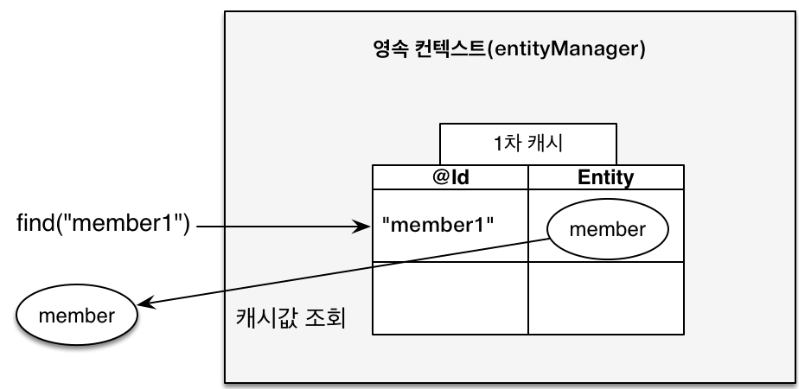
하지만 JPA에서는 한 번 유저를 조회하면 영속성 컨텍스트가 그 유저 정보를 캐시에 넣어둔다. 그리고 또 그 유저를 조회할 일이 생기면 데이터베이스에 쿼리문을 날려서 조회해오는 것이 아닌 캐시에 저장된 유저를 다시 한번 가져오게 된다.
또 하나는 업데이트의 간편함이다. 일반적으로는 유저의 정보를 업데이트 할때는
User user = repository.getUserById(id);
user.setName(newUserName);
repository.updateUser(user);뭐 이런 방식으로 업데이트 정보를 저장해주는 마지막 줄 코드를 작성해주어야 하지만 JPA는
User user = repository.getUserById(id);
user.setName(newUserName);이런식으로 setter만 적용해주어도 알아서 변경 된 부분을 업데이트해준다. 이 역시 영속성 컨텍스트가 해주는데, user라는 변수를 가져오면 이 user는 영속 상태, 즉 영속성 컨텍스트 안에 존재하게 되는데, 위에서 말한 것 처럼 영속상태가 되면 user의 캐시만을 생성하는 것이 아닌 user의 현재 정보인 스냅샷도 생성하게 된다.
그리고 영속 상태가 종료되면 저장해두었던 스냅샷과 비교하여 변경된 부분들을 알아서 JPA가 데이터베이스에 업데이트를 해준다.
결론
이 외에도 단 방향 매핑, 양 방향 매핑, JPQL 작성 등 다양한 내용을 배웠지만 코드 작성은 이미 TypeORM을 사용해본 경험을 토대로 구글링해가며 해보았기 때문에 다루지 않았다. 하지만 그렇게 그때 그때 구글링하며 코드를 작성하니 생각치 못한 오류가 많이 생겼고 해결하는데 애를 먹거나 해결하고도 정확히 왜 해결되었는지 알지 못했다.
하지만 이번 강의를 듣고 JPA가 내부적으로 어떻게 동작하는지, 단 방향 매핑과 양 방향 매핑을 하는 방법이라던지 레이지 로딩 방식으로 데이터를 불러오는 것과 EAGER 방식의 차이, GeneratedColumn의 옵션 차이 등 많은 내용을 배울 수 있었다.
JPA를 사용 할 때 조금 복잡한 쿼리들은 구글링해서 찾은 JPQL을 통해 작성해곤 했는데, 일반적으로 JPA는 queryDSL과 함께 사용하는 경우가 많다고 하니 다음에는 queryDSL에해 배워보도록 하겠다. 참고로 유튜브에서 들은 강의는 여기에서 볼 수 있다. 강의 수준이 높고 한국어로 되어있음에도 무료로 유튜브에 올라와 있어서 공유해본다.
