서론
2년전 다른 회사의 경력 주니어 백엔드 개발자 면접에서 가장 마지막으로 받았던 질문이 있다. 당시 어설픈 지식으로 대답을 하지 못했었는데,
테이블에 새로운 Row를 Insert 할 때 데이터베이스가 다운되어 있다면 어떻게 하실건가요?
였다.
당시에 했던 대답이 잘 기억나진 않지만 아마 질문의 의도를 잘 파악하지 못하고 예외처리해서 실패했을 경우 제시도 카운트를 두고 몇 번 더 시도하도록 할 것 같습니다. 라고 했던 것 같다.
돌아온 대답은 당연히 데이터베이스가 다운되어 있기 때문에 그 역시 해결 방법이 아니라는 대답을 들었다. 면접이 끝나고 추가 질문이 있냐고 하자, 마지막 질문에 대한 답을 물어봤는데, 정답은 메시지큐를 사용하는 것이었다.
메시지큐 정말 많이 들어봤다. Kafka, RabbitMQ, Amazon SQS 등 서비스가 많은데, 이런 경우에 사용하는거구나 했다. 이번에 Spring Boot MSA 강의를 들으며 간단히 Kafka를 사용해보았고, 강의를 듣고 추가로 궁금했던 점까지 공부해본 내용을 적어볼까 한다.
Message Queue
메시지 큐는 비동기 통신을 지원하며 각 서비스가 독립적으로 통신할 수 있도록 도와주는 서비스이다. Queue의 개념 그대로 하나의 Queue인데, 다양한 서비스로부터 들어온 데이터를 받아서 하나씩 그에 대한 처리를 도와준다.
이런 메시지큐를 사용하는 이유는
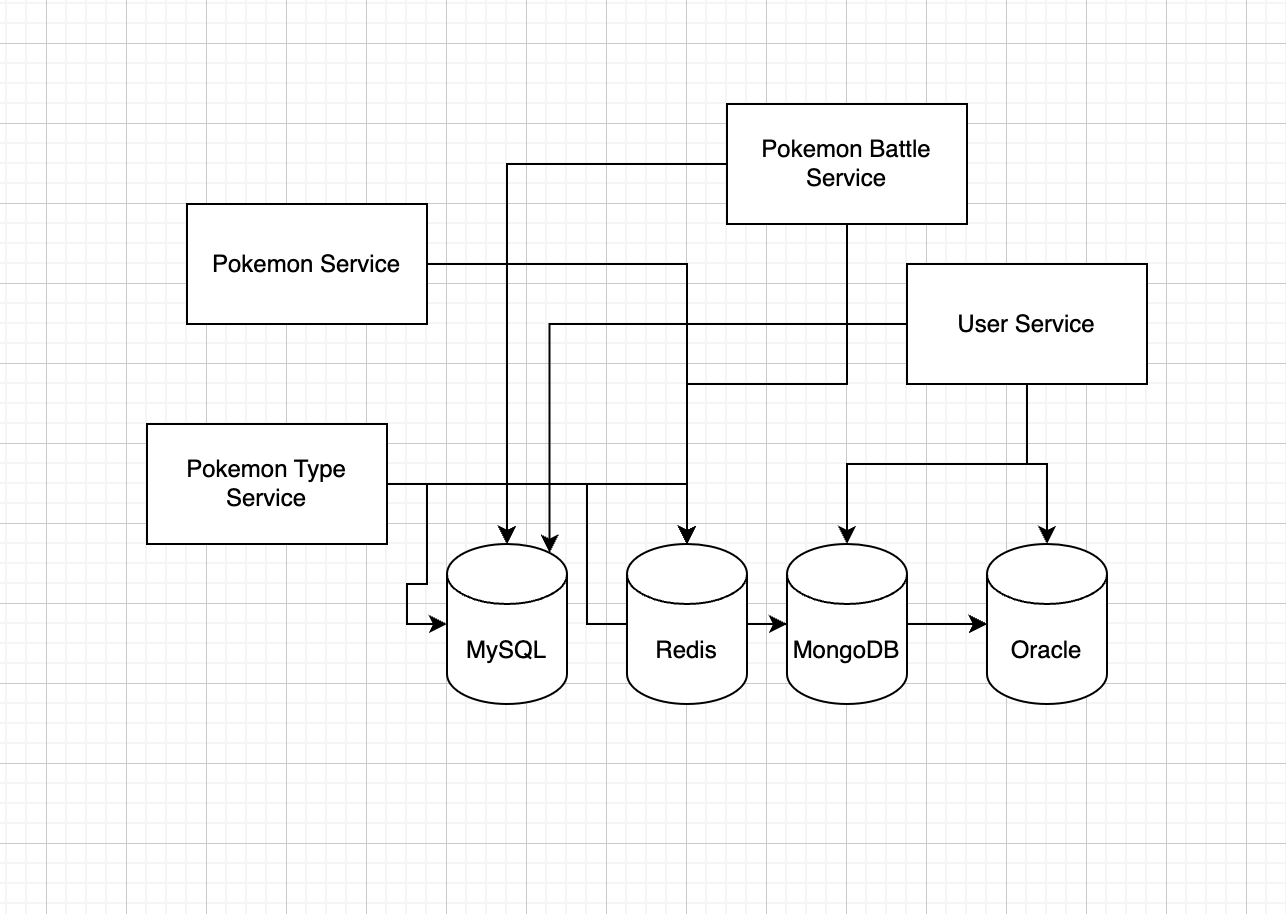
예를 들어 이런식으로 MSA 구조의 서버가 구성되어 있다고 하자. 여러 개의 서비스가 있고 각각 얽혀있으며, 서로 다른 종류의 데이터베이스들을 사용하며 하나의 어플리케이션을 만든다고 하자.
이런 경우 모든 서비스에 각각 디비를 연결해서 서로 처리를 해주어야한다. 이전 글에 따르면 MSA에서 데이터가 중복되는 일이 생길 수 있다고 하지만 이 구조는 중복을 떠나서 유지보수가 너무 복잡하다.
이 때 메시지큐를 사용하는데 메시지큐는 서비스 들 중간에 자리해서 들어온 요청을 일정하게 처리한다. 이 때 사용하는 방식이 Producer-Consumer 방식에 해당한다.
Producer는 데이터를 생산한다. 이 때 Producer는 MessageQueue 내의 특정 Topic에 데이터를 보내게 된다. 생산한 데이터를 카프카에 보내기만 하고 이 후는 신경쓰지 않는다.
Consumer는 생산한 데이터를 소비한다. 특정 Topic에 대하여 들어온 데이터를 처리해준다.
이러한 방식은 각 서비스(애플리케이션, 데이터 베이스 등..)을 독립적으로 통신할 수 있도록 도와주고 복잡히 얽힌 설계를 풀어준다.
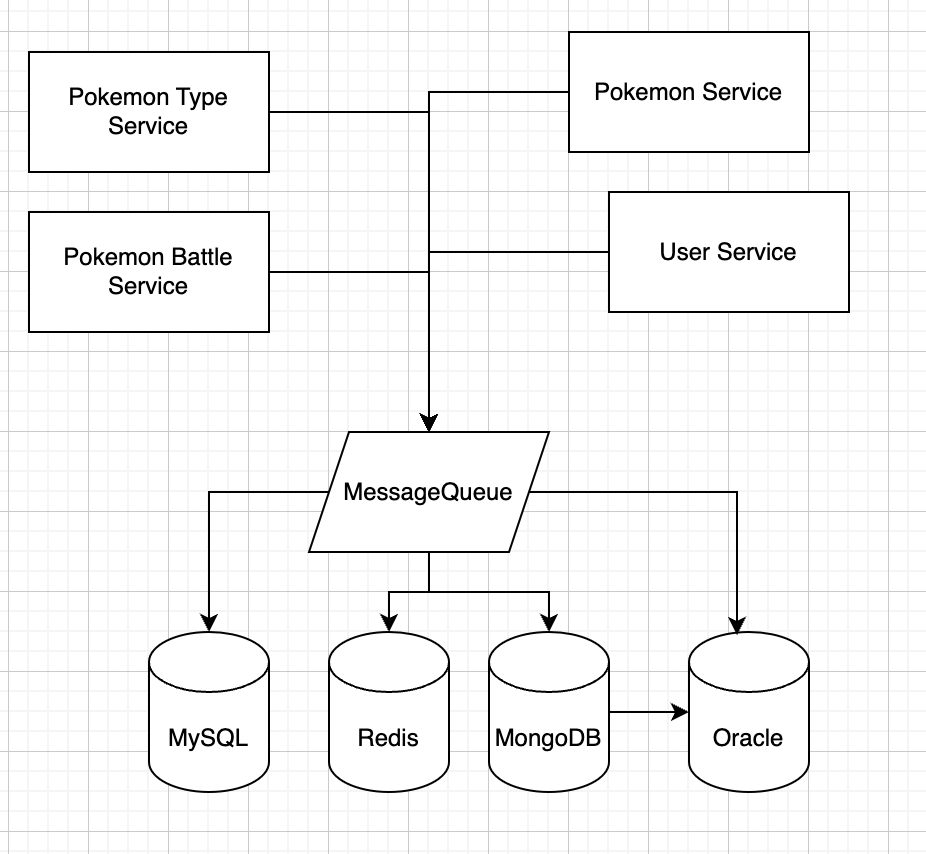
대략 이런 느낌이다. 이 메시지 큐가 그러면 내가 이전에 받은 면접 질문과는 어떤 연관이 있었을까?
Message Queue의 특징
MessageQueue에는 아래와 같은 특징이 있다.
- Producer로 부터 들어온 값이 바로 Consumer에 전달되지 않고 일정한 시간차를 두어 부하를 조절하고 동시성 문제를 해결한다.
- Producer, Consumer를 Scale out하여 트래픽이 많은 상황에서 대응할 수 있다.
- 들어온 메시지가 큐에 저장되어 있으므로 컨슈머가 해당 데이터 사용에 실패하더라도 메시지가 손실되지 않고 재처리가 가능하다.
이외에도 많은 특징이 있지만 가장 중요한 마지막 부분이다. 다양한 이유로 데이터 처리에 실패하더라도 그 데이터가 메시지 큐안에 보관되어 있기 때문에 데이터베이스가 다운되어 있더라도 메시지안에 데이터가 들어있기 때문에 재처리를 할 수 있다. 가 면접관이 원하던 대답이었을 것이다.
들어오는 데이터가 만약 로그성의 중요하지 않은 데이터라면 날아가두도록 두어도 되었겠지만 만약 정말 중요한 정보였다면 메시지 큐를 레이어에 추가하여 안정성을 가져가는 것도 좋은 방법인 것 같다. 실제로 해당 회사는 사용자의 결제가 실패하는 경우가 있어 3% 정도의 영업 이익 손실이 나고 있었다고 했다.
Message Queue의 종류와 특징
이러한 MessageQueue 서비스에는 대표적으로 Kafka, RabbitMQ, Amazon SQS를 많이 사용한다. 이중에서 Kafka와 RabbitMQ의 특징을 간단하게 알아보자.
Kafka
Kafka는 LinkedIn에서 개발한 분산 메시지 시스템으로, 대량의 데이터를 빠르게 처리하고 실시간으로 스트리밍하는데 최적화되어 있다. 이벤트를 로그에 저장하고 여러 대의 Consumer가 동일하게 읽을 수 있다.
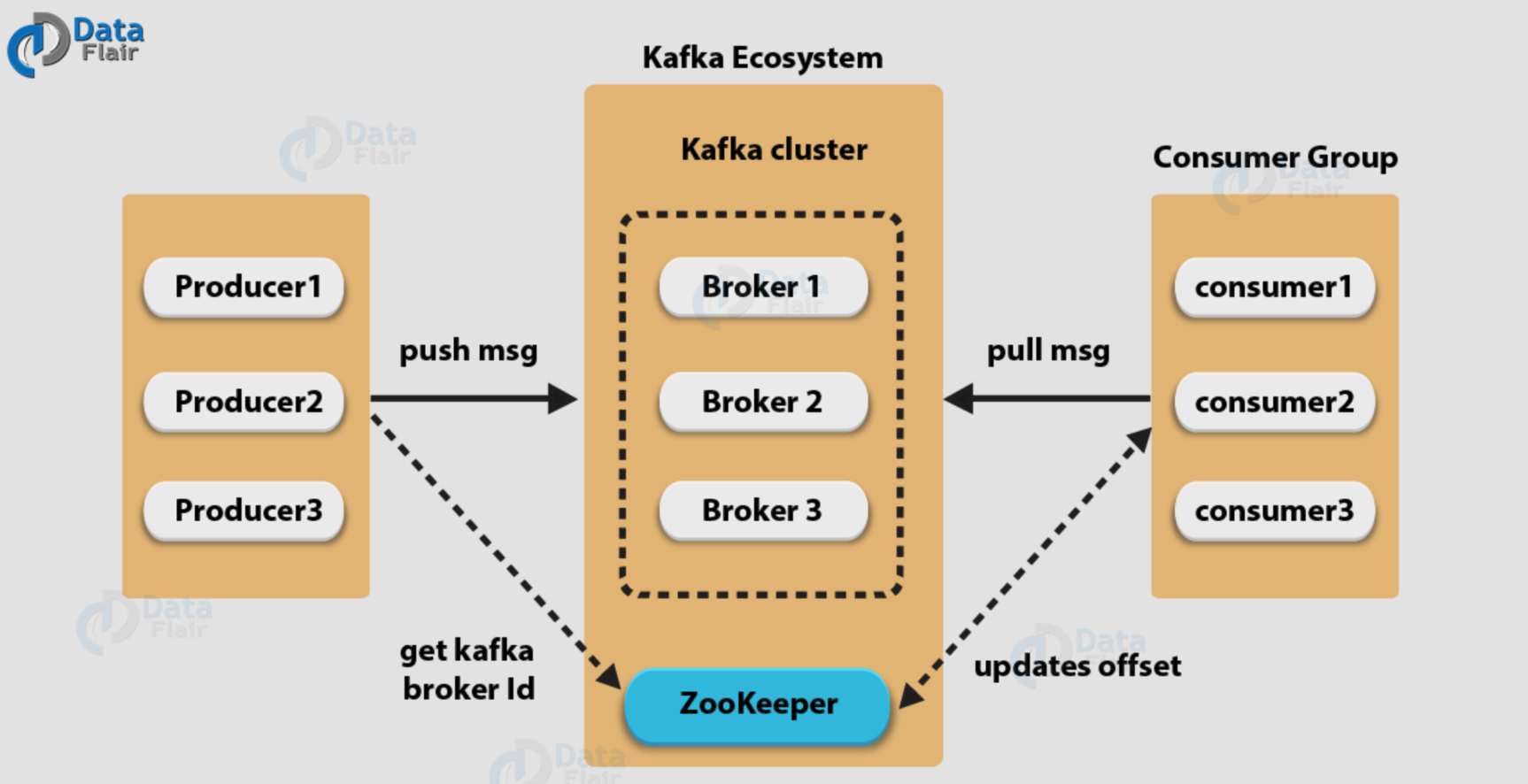
중간에 존재하는 Broker가 카프카 서버를 의미하여 메시지를 저장하고 Producer와 Consumer에게 메시지를 전달한다. Zookeeper는 이 카프카 서버들 즉 브로커들을 담은 클러스터를 관리하고 조정한다. Zookeeper가 각 브로커의 상태가 정상인지, 어떤 브로커들이 있는지, 토픽에는 뭐가 있는지 등을 관리하고 분산된 여러 브로커와 통신하며 일관적으로 메시지를 전달할 수 있도록 조정해준다.
도식을 보면 카프카 클러스터에 여러대의 브로커가 존재하는데, 이렇게 많은 브로커로 병렬처리를 통해 대용량의 데이터를 처리할 수 있으며 Zookeeper를 통해 내결함성을 책임지는 것이 Kafka의 가장 큰 특징이다.
최근에는 이 Zookeeper에 의존하지 않고 카프카를 동작하는 KRaft 프로토콜이 생겼다고 한다. 참조
RabbitMQ
RabbitMQ는 메시지 브로커로 Producer와 Consumer간의 메시지 전달에 집중한다. 메시지는 컨슈머가 읽고나면 삭제하고 Kafka에 비해서는 낮은 처리량을 보여준다. AMQP 프로토콜을 사용하는데, 이 프로토콜은 메시지 지향 미들웨어에서 사용하는 프로토콜이다.
아래 도식을 보자.
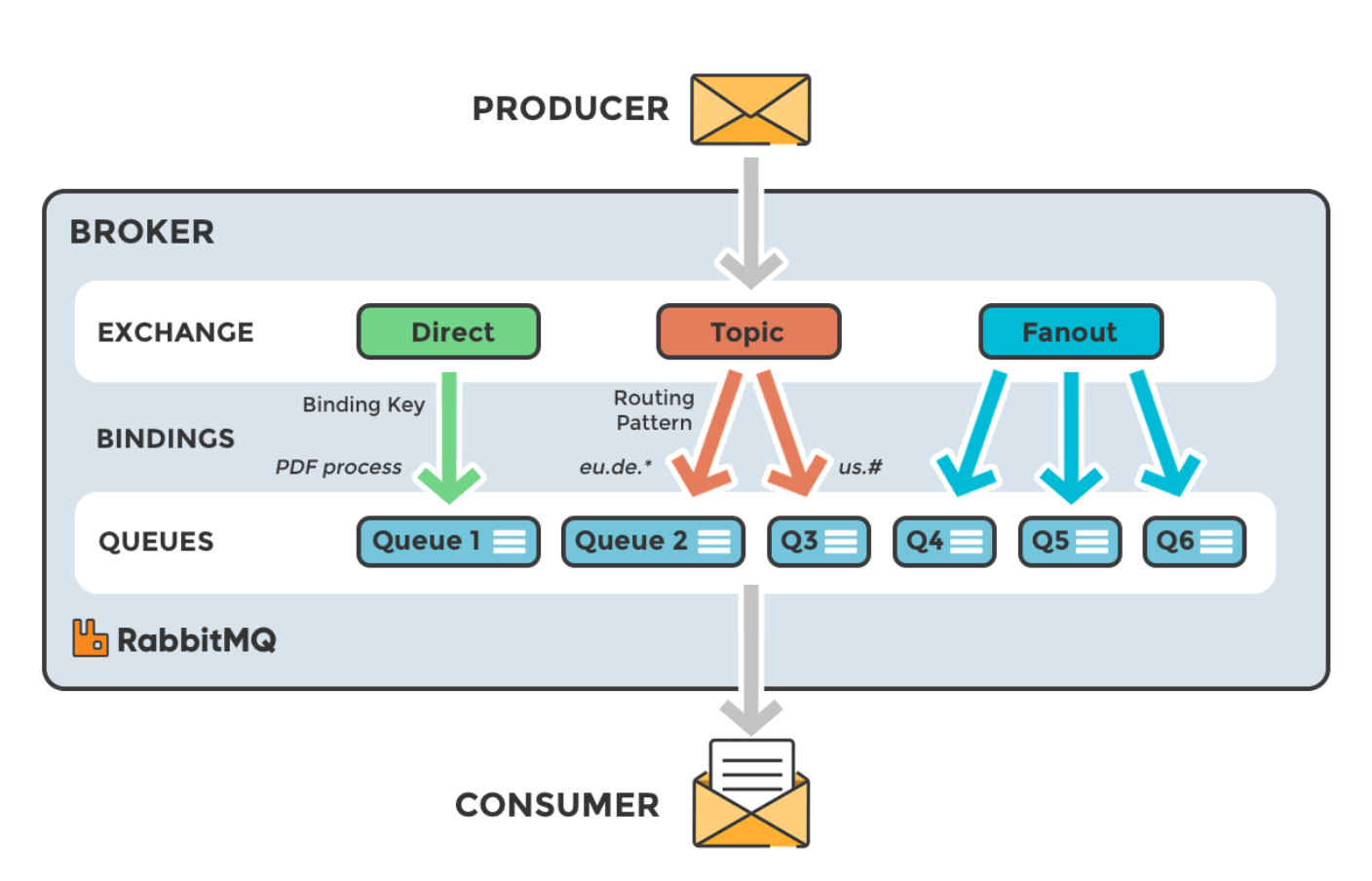
프로듀서가 데이터를 전달하면 Exchange라는 과정을 거치는데, 데이터를 바로 전달하지 않고 다양한 Exchange 방식에 의해 필요한 큐에 전달한다. 이 Exchange에 라우팅 키, 패턴, 조건 등을 설정하며 이게 AMQP 프로토콜의 특징이라고 할 수 있다.
Spring Boot에서의 사용
그러면 이제 간단히 스프링부트에서 메시지큐를 연결하고 사용해보자. 내가 만든 간단한 서비스는 포켓몬 서비스이며 Spring Boot로 작성하고, Kafka를 사용하며 Docker를 통해 배포했다.
서비스는 2개 포켓몬 타입 서비스, 포켓몬 서비스가 있으며,
포켓몬 타입 서비스는 포켓몬의 타입들을 가지고 있고(전기, 물, 불, 독 등..)
포켓몬 서비스는 포켓몬들을 가지고 있다(피카츄-전기, 리자몽-불, 또도가스-독 등...)
포켓몬 서비스에서는 포켓몬을 새로 추가할 수 있는데, 만약 포켓몬 타입 서비스에 존재하지 않는 타입을 가진 포켓몬 (예 두드리짱-페어리)를 추가한다면 포켓몬 서비스의 생성 API가 카프카에 메시지를 보내고, 포켓몬 타입 서비스는 그 메시지를 받아서 새로운 타입을 추가하게 된다.
먼저 각 서비스에 Spring-Kafka 디펜던시를 추가한다.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>추가한 후 컨슈머부터 작업해보자. 여기서 컨슈머는 포켓몬 타입 서비스로 포켓몬이 추가되었을 때 그 타입에 대한 메시지를 받는다.
@Configuration
@RequiredArgsConstructor
@EnableKafka
public class KafkaConsumerConfig {
private final Environment env;
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, env.getProperty("developer.kafka.bootstrap-server"));
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "pokemonGroup");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(properties);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory
= new ConcurrentKafkaListenerContainerFactory<>();
kafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
return kafkaListenerContainerFactory;
}
}기동된 카프카서버의 주소를 BOOTSTRAP_SERVERS_CONFIG에 넣고, 데이터를 받는 쪽이므로 들어온 데이터를 역직렬화하는 코드도 추가해준다.
@Service
@RequiredArgsConstructor
@Slf4j
public class PokemonTypeConsumer {
private final PokemonTypeRepository pokemonTypeRepository;
@KafkaListener(topics = "create-pokemon-type")
public void createPokemonType(String kafkaMessage) {
log.info("Kafka Message = {}", kafkaMessage);
Map<Object, Object> map = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
try {
// 카프카로 들어온 Json 형태의 메시지를 Map으로 변환한다.
map = mapper.readValue(kafkaMessage, new TypeReference<Map<Object, Object>>() {});
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
String typeName = (String) map.get("type");
// 존재하지 않는 타입이라면 타입을 추가하지 않는다.
if (pokemonTypeRepository.findByName(typeName) == null) { return; }
PokemonType pokemonTypeEntity = PokemonType.of(typeName);
pokemonTypeRepository.save(pokemonTypeEntity);
}
}이제 create-pokemon-type이라는 토픽을 이 컨슈머가 보게 된다. 그리고 메시지가 전달되면 아래 createPokemonType이라는 메소드가 호출되어 repository로 데이터를 전달하게 될 것이다.
이제 프로듀서측, 즉 포켓몬 서비스를 확인해보자.
@Configuration
@EnableKafka
@RequiredArgsConstructor
public class KafkaProducerConfig {
private final Environment env;
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> properties = new HashMap<>();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, env.getProperty("developer.kafka.bootstrap-server"));
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(properties);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}이 쪽에는 프로듀서의 설정을 해준다. 역시 카프카의 서버정보를 BOOTSTRAP_SERVER에 넣고, 데이터를 전달하는 쪽이므로 직렬화 설정을 해준다.
@Service
@Slf4j
@RequiredArgsConstructor
public class PokemonTypeProducer {
private final KafkaTemplate kafkaTemplate;
public String send(String type) {
ObjectMapper mapper = new ObjectMapper();
String kafkaMessage = "";
String pokemonTypeString = type.toLowerCase();
RequestCreatePokemonType kafkaMessageObject = new RequestCreatePokemonType(pokemonTypeString);
try {
kafkaMessage = mapper.writeValueAsString(kafkaMessageObject);
} catch (JsonProcessingException ex) {
ex.printStackTrace();
}
kafkaTemplate.send("create-pokemon-type", kafkaMessage);
return type;
}
}그리고 단순히 카프카 템플릿에 토픽과 메시지를 전달해주면 된다. 전달하는 메시지 형태는 어떤 형태든 상관없으나 유니버셜한 Json을 사용했다.
@PostMapping("/pokemons")
public ResponseEntity<ResponsePokemon> createNewPokemon(
@RequestBody RequestCreatePokemon requestCreatePokemon
) {
Pokemon pokemonEntity = Pokemon.from(requestCreatePokemon);
service.addPokemon(pokemonEntity);
ResponsePokemon result = ResponsePokemon.fromEntity(pokemonEntity);
String type = requestCreatePokemon.getType();
pokemonTypeProducer.send(type);
return ResponseEntity.status(HttpStatus.CREATED).body(result);
}이제 실제로 포켓몬 서비스에서 위에서 작성한 PokemonTypeProducer의 send 메소드를 사용한다. 이 단순한 설정만으로 메시지가 카프카에 전달되고 컨슈머는 이를 보고 있다가 컨슈머의 메소드를 실행하게 된다.
카프카를 기동하려면 카프카를 다운 받고 주키퍼 서버를 켜고 카프카 서버를 켜서 주키퍼와 연동하는 복잡한 과정을 거쳐야 하는데, 위 과정을 진행한 코드가 있는 리포지토리 주소를 아래 첨부한다.
