협업 필터링
사용자들로부터 누적된 데이터들을 분류하고 분류된 데이터를 기준으로 새로운 데이터에 대입하여 분류하는 방법
사용자들의 과거 데이터가 미래에도 유지될 것을 전제로 함
Memory-Based Approach
- 최적화, 매개변수를 학습하지 않음, 단순한 산술 연산
- 코사인 유사도, 피어슨 상관도 사용
- 아이템 기반, 사용자 기반 필터링 등`이 있음
장점: 쉽게 만들 수 있음, 결과의 설명력이 좋음. 도메인 의존적이지 않음
단점: 데이터가 별로 없는 경우 성능이 안좋음, 확장 가능성이 낮음Model-Based Approach
- 기계학습을 이용
- 최적화 방법, 매개 변수를 학습함
- 행렬분해, SVD, 신경망 사용
장점: 데이터가 많지 않아도 사용 가능
단점: 결과의 설명력이 낮고 도메인 의존적
Model-Based Approach는 머신러닝의 영역으로 보이고 Mahout은 Memory-Based Approach를 지원하므로 Memory-Based에 대해서만 알아보자.아이템 기반 협업 필터링
사람들이 과거에 좋아했던 상품과 비슷한 상품을 좋아한다는 사실을 전제
고객의 선호도를 기준으로 기존 상품들과 예측하고자 하는 상품의 유사도를 계산
고객들의 선호도만을 이용, 고객 간의 유사도는 고려하지 않음
아마존, 넷플릭스의 상품 추천

사용자 기반 협업 필터링
비슷한 선호도를 가지는 여러 사람들의 다른 상품에 대한 평가에 근거
비슷한 성향을 가진 유저들을 찾고 그 유저들의 선호도를 이용
두 유저가 모두 평가를 한 상품이 있어야 하고 두 유저 사이에서만 상관 관계를 구할 수 있음
SNS 친구 추천에 사용
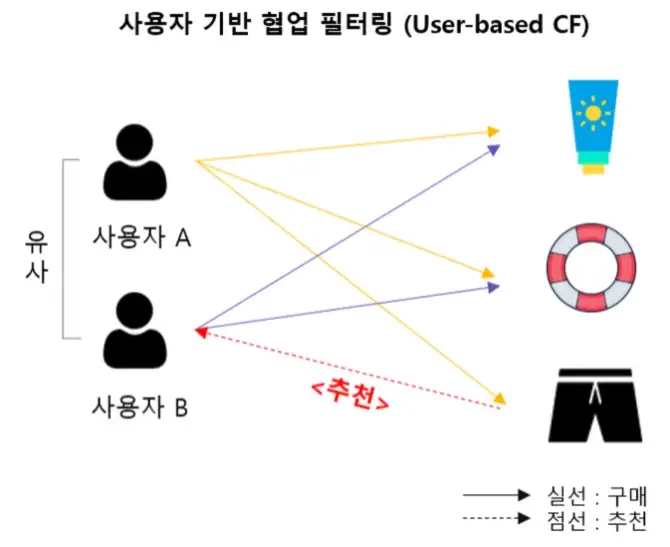
이미지 출처 https://www.codingworldnews.com/news/articleView.html?idxno=2477
연산 방식
두 방식 모두 유사도를 측정하는데, 유사도는 상품, 유저 그래프간의 거리를 말한다. 거리측정 방법에는 사용자(row), 아이템(column) 행렬을 통해서 거리를 측정한다. 방법에는 세 가지가 있는데 코사인 유사도, 피어슨 유사도, 유클리디안 거리측정법이 있다.
코사인 유사도
두 그래프 지점이 같은 방향을 보고 있는지 비교
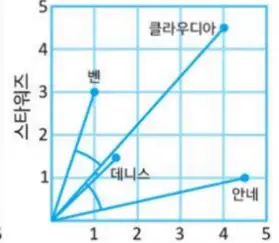
피어슨 유사도
- 코사인 유사도는 유저마다 개인적인 평가 성향을 반영하지 못한다. 이를 보완하기 위해 약간의 보정을 거친다.
- 특정 유저의 점수 기준이 극단적으로 높거나 낮을 경우 유사도에 큰 영향을 주기 때문에 이를 막기 위한 상관 계수를 사용
유클리디안 거리 측정
- 피타고라스 정리를 통해 간단히 거리를 계산
- 다차원의 경우 공식을 추가하여 추가 계산
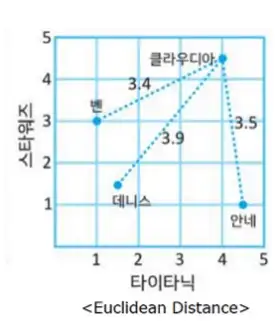
이미지 출처: https://kmhana.tistory.com/31
Mahout으로 사용자 기반 필터링 구현
mahout은 위 복잡한 연산을 도와주는 아파치의 라이브러리이다. 하둡을 기반으로 맵 리듀스를 통해 클러스터링, 분류, 분석 작업을 수행한다.
연산 과정은
- 유저id, 상품id, 선호도를 나열한 csv 파일 생성
- 해당 csv 데이터를 반영한 데이터 모델 생성
- 유저 상관도 계산(코사인, 피어슨..)
- 데이터 모델, 상관도를 통한 추천
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-integration</artifactId>
<version>0.12.2</version>
</dependency>각 빌드 매니져에 맞도록 디펜던시를 추가해준다.
@Data @AllArgsConstructor @NoArgsConstructor
public class MahoutDto {
private String userId;
private String goodsId;
private long purchaseCount;
}Mahout에 들어갈 Dto를 설정해준다. 선호도는 유저가 아이템을 얼마나 선호하는지에 대한 정보인데, 내 경우엔 유저가 상품을 몇 번 구매했는지로 설정했다.
HashMap<Integer, String> users = new HashMap<>();
HashMap<Integer, String> goods = new HashMap<>();
BufferedWriter bw = new BufferedWriter(new FileWriter(file, true));
for (MahoutDto mahout : mahoutDto) {
String userId = mahout.getUserId();
String goodsId = mahout.goodsId();
String row = userId.hashCode() + "," + goodsId.hashCode() + "," + mahout.getPurchaseCount();
users.put(userId.hashCode(), userId);
goods.put(goodsId.hashCode(), goodsId);
bw.write(row);
bw.newLine();
}
bw.flush();
bw.close();csv 파일을 생성한다. mahout은 성능을 위해 id를 long으로만 받기 때문에 String을 id로 가지고 있는 항목들을 .hashCode() 를 통해 변환해주었다. 또 hash 는 단방향 암호화기 때문에 복호가 불가능하여 해당 정보를 담은 Map도 생성해주었다.
해당 정보를 바탕으로 csv 파일을 작성한다.
FileDataModel dm = new FileDataModel(new File("test.csv"));
UserSimilarity user = new PearsonCorrelationSimilarity(dm);
ThresholdUserNeighborhood nh = new ThresholdUserNeighborhood(0.1, user, dm);
GenericUserBasedRecommender recommender = new GenericUserBasedRecommender(dm, nh, user);
List<RecommendedItem> recommend = recommender.recommend("someuserid".hashCode(), 2);
for (RecommendedItem item : recommend) {
int itemID = (int) item.getItemID();
float value = item.getValue();
String goodsId= goods.get(itemID);
System.out.println("goodsId= " + goodsId+ " value = " + value);
}위에 1~4 연산과정에 맞게 mahout을 이용하여 유사한 상품 찾아낼 수 있다.
recommend 에 추천받을 userId와 개수를 파라미터로 넣어주면 된다.
여기서 ThreshHoldUserNeighberhood 로 아웃풋의 정도를 계산했는데, 데이터가 충분치 않거나 비슷한 유저가 없을 경우 NearestNUserNeighborhood 를 사용하여 고정 값으로 찾을 수도 있다.
아이템 기반 필터링
FileDataModel dm = new FileDataModel(new File("test.csv"));
LogLikelihoodSimilarity sim = new LogLikelihoodSimilarity(dm);
GenericItemBasedRecommender recommender = new GenericItemBasedRecommender(dm, sim);
List<RecommendedItem> recommend = recommender.recommend("someuserid".hashCode(), 3);
System.out.println("recommend = " + recommend);
for (RecommendedItem item : recommend) {
int itemID = (int) item.getItemID();
float value = item.getValue();
System.out.println("themeCode = " + itemID + " value = " + value);
}아이템 기반 필터링은 위와 같이 유사도 측정 방식을 바꿔준 후에 적용하면 된다. 여기서 측정방식은 loglikelihood 방식을 사용했는데, likelihood 는 확률 분포의 모수가 어떤 확률 변수의 표집값과 일관되는 정도를 나타내는 값이라고 한다.
말이 굉장히 어려운데, 주어진 관측값(샘플)들과 실제 확률분포의 일관된 정도를 나타낸다.
예를 들어 동전을 던졌을 때 앞면일 확률은 0.5이다. 동전을 두 번 던졌을 때 모두 앞면이 나올 확률은 0.25이다. 하지만 사실 동전을 던질 때 바람도 불 것이고 동전이 떨어질 때 바닥면의 상태도 있고 실제로 정확히 0.5 의 확률이 나오진 않는다.
그렇다면 동전을 여러 번 던졌을 때 0.5에 가깝게 확률이 나오는 군집의 유사도가 높다고 볼 수 있다.
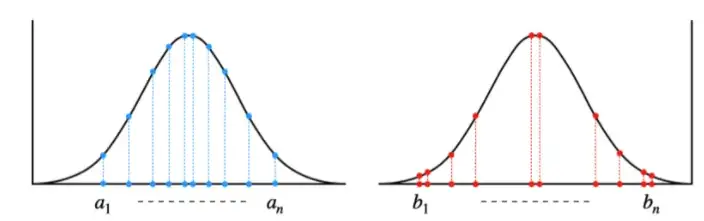
이미지 출처: https://paul-hyun.github.io/nlp-tutorial-02-04-negative-log-likelihood/
위 그래프에서 a1-an 그래프가 b1-bn 그래프보다 likelihood 를 더 잘 측정했다고 볼 수 있다.
일반적인 정확도, 사용빈도는 아이템 기반 필터링이 유저 기반 필터링보다 좋다고 한다.
