학습한 내용
import json
import os
import glob
import csv
# 가져올 파일들 경로
path='./data/train/label/*/*.json'
# 경로를 리스트 형태로
filelist=glob.glob(path)
# 빈 딕셔너리
keydata={}
# csv 파일 생성 쓰기모드
with open('./json.csv','w') as f:
w = csv.writer(f)
# 맨 처음 라벨 쓰기
w.writerow(['cate1','cate2','cate3','width','height','weight'])
# 파일경로를 하나씩 불러옴
for filename in filelist:
#파일 하나씩 열기
with open(filename, 'r') as f:
json_data = json.load(f)
#json data를 열어서 필요한 변수 추출
cate1=json_data['cate1']
cate2=json_data['cate2']
cate3=json_data['cate3']
width=json_data['width']
height=json_data['height']
weight=json_data['weight']
#dictionary 형태로 변경
keydata.update({'cate1':cate1})
keydata.update({'cate2':cate2})
keydata.update({'cate3':cate3})
keydata.update({'width':width})
keydata.update({'height':height})
keydata.update({'weight':weight})
# csv에 한줄 작성 for문 반복
w.writerow(keydata.values())실행결과
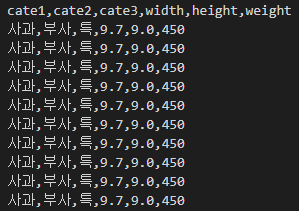
학습한 내용 중 어려웠던 점 또는 해결못한 것들
json 파일을 불러와서 csv로 만들었으나 파일을 실제로 다운받아서 열어보면 한글이 깨짐
linear regression 코드는 작성중
해결방법 작성
인코딩관련해서 찾아봐야겠다
학습 소감
gpu로 하니까 확실히 빨라서 좋다.
