학습한 내용
#goorm에서 작업 데이터다운로드
from zipfile import ZipFile
import gdown
import argparse
file_destinations = {
'FaceMaskDetection': 'QC_raw.zip', }
file_id_dic = {
'FaceMaskDetection': '1kFwz43HOFbOg7Qiplwuz1Oi-4jTOS038'
}
def download_file_from_google_drive(id_, destination):
url = f"https://drive.google.com/uc?id={id_}"
output = destination
gdown.download(url, output, quiet=True)
print(f"{output} download complete")
parser = argparse.ArgumentParser(
description='data loader ... '
)
parser.add_argument('--data', type=str, help='key for selecting data..!!')
args = parser.parse_args()
download_file_from_google_drive(
id_=file_id_dic[args.data], destination=file_destinations[args.data]
)
# 압축 풀기
test_file_name = "./QC_raw.zip"
with ZipFile(test_file_name, 'r') as zip:
zip.printdir()
zip.extractall()실행결과
#dataset path불러와서 파일 하나씩 transform과 labeling
from torch.utils.data import Dataset
import glob
from PIL import Image
import os
CATEGORY = {'apple_fuji_l': 0, 'apple_fuji_m': 1, 'apple_fuji_s': 2,
'apple_yanggwang_l': 3, 'apple_yanggwang_m': 4, 'apple_yanggwang_s': 5,
'cabbage_green_l': 6, 'cabbage_green_m': 7, 'cabbage_green_s': 8,
'cabbage_red_l': 9, 'cabbage_red_m': 10, 'cabbage_red_s': 11,
'chinese-cabbage_l': 12, 'chinese-cabbage_m': 13, 'chinese-cabbage_s': 14,
'garlic_uiseong_l': 15, 'garlic_uiseong_m': 16, 'garlic_uiseong_s': 17,
'mandarine_hallabong_l': 18, 'mandarine_hallabong_m': 19, 'mandarine_hallabong_s': 20,
'mandarine_onjumilgam_l': 21, 'mandarine_onjumilgam_m': 22, 'mandarine_onjumilgam_s': 23,
'onion_red_l': 24, 'onion_red_m': 25, 'onion_red_s': 26,
'onion_white_l': 27, 'onion_white_m': 28, 'onion_white_s': 29,
'pear_chuhwang_l': 30, 'pear_chuhwang_m': 31, 'pear_chuhwang_s': 32,
'pear_singo_l': 33, 'pear_singo_m': 34, 'pear_singo_s': 35,
'persimmon_bansi_l': 36, 'persimmon_bansi_m': 37, 'persimmon_bansi_s': 38,
'persimmon_booyu_l': 39, 'persimmon_booyu_m': 40, 'persimmon_booyu_s': 41,
'persimmon_daebong_l': 42, 'persimmon_daebong_m': 43, 'persimmon_daebong_s': 44,
'potato_seolbong_l': 45, 'potato_seolbong_m': 46, 'potato_seolbong_s': 47,
'potato_sumi_l': 48, 'potato_sumi_m': 49, 'potato_sumi_s': 50,
'radish_winter-radish_l': 51, 'radish_winter-radish_m': 52, 'radish_winter-radish_s': 53}
class QCDataset(Dataset):
def __init__(self, data_path, transform=None):
self.path = sorted(glob.glob(os.path.join(data_path, "*", "*", "*.png")))
self.transform = transform
def __getitem__(self, index):
image = self.path[index]
json = self.path[index][:-3]+'json'
# ./dataset/train\apple_fuji\apple_fuji_L_1-10_5DI90.png
img = Image.open(image).convert("RGB")
if self.transform is not None :
img = self.transform(img)
# label_temp = onion_red_S_75-19_4DI45.png
label = image.lower().split('/')[-1]
if 'chinese-cabbage' in label:
# chinese-cabbage_l
label = label.split('_')
label = label[0] + '_' + label[1]
else :
label = label.split('_')
label = label[0] + '_' + label[1] + '_' + label[2]
labeling = CATEGORY[label]
return img, labeling, label
def __len__(self):
return len(self.path)#여러모델 저장
import torch
import torch.nn as nn
import torchvision.models as models
device = "cuda" if torch.cuda.is_available() else "cpu"
# https://tutorials.pytorch.kr/beginner/finetuning_torchvision_models_tutorial.html
def initialize_model(model_name, num_classes, use_pretrained=True):
# Initialize these variables which will be set in this if statement. Each of these
# variables is model specific.
model_ft = None
input_size = 0
if model_name == "resnet18":
""" Resnet18"""
model_ft = models.resnet18(pretrained=use_pretrained)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "resnet34":
model_ft = models.resnet34(pretrained=use_pretrained)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "resnet50":
model_ft = models.resnet50(pretrained=use_pretrained)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "resnext50_32x4d":
model_ft = models.resnext50_32x4d(pretrained=use_pretrained)
model_ft.fc = nn.Linear(1280, num_classes)
input_size = 224
elif model_name == "ghostnet":
model_ft = torch.hub.load('huawei-noah/ghostnet', 'ghostnet_1x', pretrained=use_pretrained)
model_ft.fc = nn.Linear(1280, num_classes)
input_size = 224
elif model_name == "mobilenet":
model_ft = models.mobilenet_v2(pretrained=use_pretrained)
num_ftrs = model_ft.last_channel
model_ft.classifier[1] = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet"""
model_ft = models.alexnet(pretrained=use_pretrained)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg11_bn":
""" VGG11_bn"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg16_bn":
model_ft = models.vgg16_bn(pretrained=use_pretrained)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg16":
model_ft = models.vgg16(pretrained=use_pretrained)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet"""
model_ft = models.densenet121(pretrained=use_pretrained)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
"""
Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
# Handle the auxilary net
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# Handle the primary net
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size#모델학습결과
import pandas as pd
import torch
import matplotlib.pyplot as plt
import os
import numpy as np
import tqdm
data = []
def train(num_epoch, model, train_loader, test_loader, criterion, optimizer,
save_dir, val_every, device):
print("String... train !!! ")
best_loss = 9999
for epoch in range(num_epoch):
for i, (imgs, labels, _) in enumerate(train_loader):
imgs, labels = imgs.to(device), labels.to(device)
output = model(imgs)
loss = criterion(output, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, argmax = torch.max(output, 1)
acc = (labels == argmax).float().mean()
print("Epoch [{}/{}], Step [{}/{}], Loss : {:.4f}, Acc : {:.2f}%".format(
epoch + 1, num_epoch, i +
1, len(train_loader), loss.item(), acc.item() * 100
))
valid_acc = 0
if (epoch + 1) % val_every == 0:
valid_acc, valid_loss = validation(epoch + 1, model, test_loader, criterion, device)
if valid_loss < best_loss:
print("Best prediction at epoch : {} ".format(epoch + 1))
print("Save model in", save_dir)
best_loss = valid_loss
save_model(model, save_dir)
data.append([acc.item() * 100, loss.item(), valid_acc, best_loss])
print()
pd_data = pd.DataFrame(data, columns=['train_accu', 'train_loss', 'test_accu', 'test_loss'])
save_model(model, save_dir, file_name="last.pt")
return model, pd_data
def validation(epoch, model, test_loader, criterion, device):
print("Start validation # {}".format(epoch))
model.eval()
with torch.no_grad():
total = 0
correct = 0
total_loss = 0
cnt = 0
for i, (imgs, labels, _) in enumerate(test_loader):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
total += imgs.size(0)
_, argmax = torch.max(outputs, 1)
correct += (labels == argmax).sum().item()
total_loss += loss
cnt += 1
avg_loss = total_loss / cnt
print("Validation # {} Acc : {:.2f}% Average Loss : {:.4f}%".format(
epoch, correct / total * 100, avg_loss
))
model.train()
return correct / total * 100, avg_loss
def save_model(model, save_dir, file_name="best.pt"):
output_path = os.path.join(save_dir, file_name)
torch.save(model.state_dict(), output_path)
def eval(model, test_loader, device):
print("Starting evaluation")
model.eval()
total = 0
correct = 0
with torch.no_grad():
for i, (imgs, labels, _) in tqdm(enumerate(test_loader)):
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
# 점수가 가장 높은 클래스 선택
_, argmax = torch.max(outputs, 1)
total += imgs.size(0)
correct += (labels == argmax).sum().item()
print("Test acc for image : {} ACC : {:.2f}".format(
total, correct / total * 100))
print("End test.. ")
def loss_acc_visualize(history, modelname, path="./results"):
os.makedirs("./results", exist_ok=True)
plt.figure(figsize=(20, 10))
plt.suptitle(f"SGD; 0.01")
plt.subplot(121)
plt.plot(history['train_loss'], label='train_loss')
plt.plot(history['test_loss'], label='test_loss')
plt.legend()
plt.title('Loss Curves')
plt.subplot(122)
plt.plot(history['train_accu'], label='train_accu')
plt.plot(history['test_accu'], label='test_accu')
plt.legend()
plt.title('Accuracy Curves')
plt.savefig(os.path.join(str(path),f'loss_acc_{modelname}.png'))
def visual_predict(model, modelname, data, path="./results"):
os.makedirs("./results", exist_ok=True)
c = np.random.randint(0, len(data))
img, labels, category = data[c]
with torch.no_grad():
model.eval()
# Model outputs log probabilities
out = model(img.view(1, 3, 224, 224).cuda())
out = torch.exp(out)
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.imshow(img.numpy().transpose((1, 2, 0)))
plt.title(labels)
plt.subplot(122)
plt.barh(category, out.cpu().numpy()[0])
plt.savefig(os.path.join(str(path),f'predict_{modelname}.png'))#메인코드 시드고정 vgg16모델 사용
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import os
import numpy as np
import random
import dataset, models, utils
# seed
def set_seed(seed = 7777):
# Sets the seed of the entire notebook so results are the same every time we run # This is for REPRODUCIBILITY
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
device = "cuda" if torch.cuda.is_available() else "cpu"
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.2),
transforms.RandomVerticalFlip(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.2, 0.2, 0.2])
])
test_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.2, 0.2, 0.2])
])
train_data = dataset.QCDataset("./Training", transform=train_transform)
test_data = dataset.QCDataset("./Validation", transform=test_transform)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=64, shuffle=False)
modelname = "vgg16"
model, size = models.initialize_model(modelname, 54, use_pretrained=True)
model = model.to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.025, momentum=0.9)
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
epochs = 10
val_every = 10
save_weights_dir = "./weight"
os.makedirs(save_weights_dir, exist_ok=True)
"""model load => model test"""
# model.load_state_dict(torch.load("./weight/best.pt", map_location='cpu'))
if __name__ == "__main__":
model, data = utils.train(epochs, model, train_loader, test_loader, criterion, optimizer, save_weights_dir, val_every, device)
utils.loss_acc_visualize(data, modelname)
utils.visual_predict(model, modelname, test_data)
# utils.eval(model, test_loader, device)실행결과
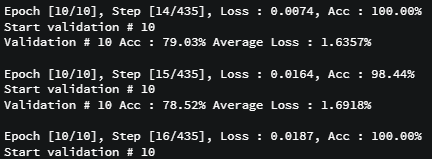
학습중
학습한 내용 중 어려웠던 점 또는 해결못한 것들
해결방법 작성
학습 소감
생각보다 이미지 분류 정확도가 높아서 신기하다
들어가는 데이터가 잘 정제되어있어서 그럴텐데
일반적으로 찍는 사진의 경우 어떨지 궁금하다.
