
Transformer이 등장한 "Attention Is All You Need (Ashish Vaswani, Noam Shazer, Niki Parmar, Jakob Uzkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin), 2017"에 대한 해설 및 리뷰, (PyTorch) 코드 설명입니다.
요약
먼 옛날 RNN이랑 Attention이라는 뗄레야 뗄 수 없는 베프가 있었어요
그런데 구글은 RNN이 마음에 안 들었어요
RNN은 느릿느릿하고 순서대로 처리하는걸 좋아해서
멀티태스킹도 안되는 친구였거든요~
그래서 RNN을 무리에서 떨구고
Attention을 왕으로 만들고자 하는
"Transformer" 모델 제안을 (피폐물 뚝딱) ...
번역 성능이 이전 SoTA 보다 Training 비용은 1/4로 단축되면서,
단일모델 기준 최고성능 찍고
정말 RNN은 역사가 되었습니다 ...
1. Introduction
Recurrent Model 3대장
해당 논문이 쓰인 당시 RNN (순환신경망), LSTM (장단기 메모리), GRU (게이트 순환 유닛)이 NLP 나와바리의 SoTA 공신인 Recurrent Language Model 3대장이었다.
Recurrent Model 한계점
Recurrent Model은 통상적으로 입력, 출력 시퀀스의 symbol positions 에 따라 계산을 수행한다. 이 positions 에 따라 계산을 단계적으로 수행하면서, hidden states (은닉 상태)의 시퀀스를 생성한다.
즉, 쉽게 말하자면 - 문장이 있을 때 - 문장을 각각 구성요소(단어, 부호 등)로 나누고 - 구성요소를 하나씩 단계적으로 계산/처리하면서 - 단계 마다 hidden state (은닉 상태)이라는 것을 단계적으로 생성하여 - 최종적으로 hidden states 시퀀스를 생성하는 것이다.
하지만 이런 식으로 단계적으로 처리하는, 시퀀스 계산에는 한계점이 있다. 이러한 시퀀스 계산/처리는 병렬화가 어렵다. t 시점의 hidden state인 ht를 만들기 위해선, t-1 시점의 hidden state ht-1이 입력값으로 필요하기 떄문에 병렬처리가 어려운 것이다. 무조건 앞단계가 끝나야 뒷단계를 시작할 수 있는, 일직선으로 이어져야 하는 것...
병렬처리를 하면 엄청난 시간, 비용을 아낄 수 있다는 장점이 있는데 - 몇억개의 데이터가 모델에 입력되는 요즘 시대에 병렬이 안되는 것은 큰 문제이다. 그리고 이 문제는 문장이 길어질수록 더 골치가 아파진다. 결국 메모리가 부족해지거든요.
Attention .. Recurrent Model과 헤어져!
그리고 요요요 Attention 들은 항상 Recurrent Network와 함께 사용된다. 애초에 RNN이 긴 문장 처리를 어려워하며, 인코더-디코더 구조에서 발생하는 정보 손실이라는 단점을 보완하기위해 등장한 메커니즘이다.
이 둘이 사이가 좋은게 꼴보기 싫다.
Attention은 진짜 NLP task, 시퀀스 모델링 등에 정말 필요한 친구인데 ..
가능성이 무궁무진해보이는데
비효율적인 RNN과 붙어 다니는게 참 미운 것이다.
본격적인 Attention과 RNN 사이 "이간질"
그래서 제안합니다! Transformer!
순환? 필요없구요, Attention만 데려가겠습니다.
장점?
- 병렬화 쌉가능 (significantly more) ~ 효율 상승 ~
- new SoTA ~
(RNN은 이제 역사 속으로...)
2. Background
병렬화를 위한 기존 노력들
: CNN 을 기반으로 했던 것들 (input, output 모두에 대해 hidden representation 을 병렬로 처리했음)
- Extended Neural GPU
- ByteNet
- ConvS2S (Meta)
병렬화 덕분에 연산량, 연산속도 차원에선 무척 효율적이었으나 - 문장이 길어질 경우 성능이 떨어졌다. 구조상, 임의의 input position과 임의의 output position의 신호를 연관짓기 위한 계산/연산이 - position 사이 거리가 커질 수록 - 같이 커진다는 것이다. 이렇게 될 경우, 거리가 긴 position 끼리는 의존성을 배우기 어려워진다.
Self-Attention
시퀀스를 계산/연산을 통해 representation 으로 변환하는 과정에서, 시퀀스 position들 간 상관관계를 사용한다.
쉽게 표현하자면 한 문장에서 단어들 간의 상관관계를 바탕으로 representation 을 만들기에, context에서 보다 attention이 필요한 단어나 요소들에 대해 더 주목할 수 있는 것.
주요 Task - reading comprehension, abstractive summarization, textual entailment, learning task-independent sentence representations
End-to-end memory networks
: "End-To-End Memory Networks (Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus)"
기존 RNN처럼 시퀀스-순환이 아닌, recurrent attention mechanism 을 기반으로 한 network!
주요 Task - simple-language question answering, language modeling
Transformer의 novelty?
Transformer은 최초로 시퀀스-순환 RNN도 아니고, CNN도 아닌,
Self-Attention 에만 의존하여 input & output을 representation으로 처리해주는 변환 모델이다.
3. Model Architecture
"Attention Is All You Need" - PyTorch Code Example
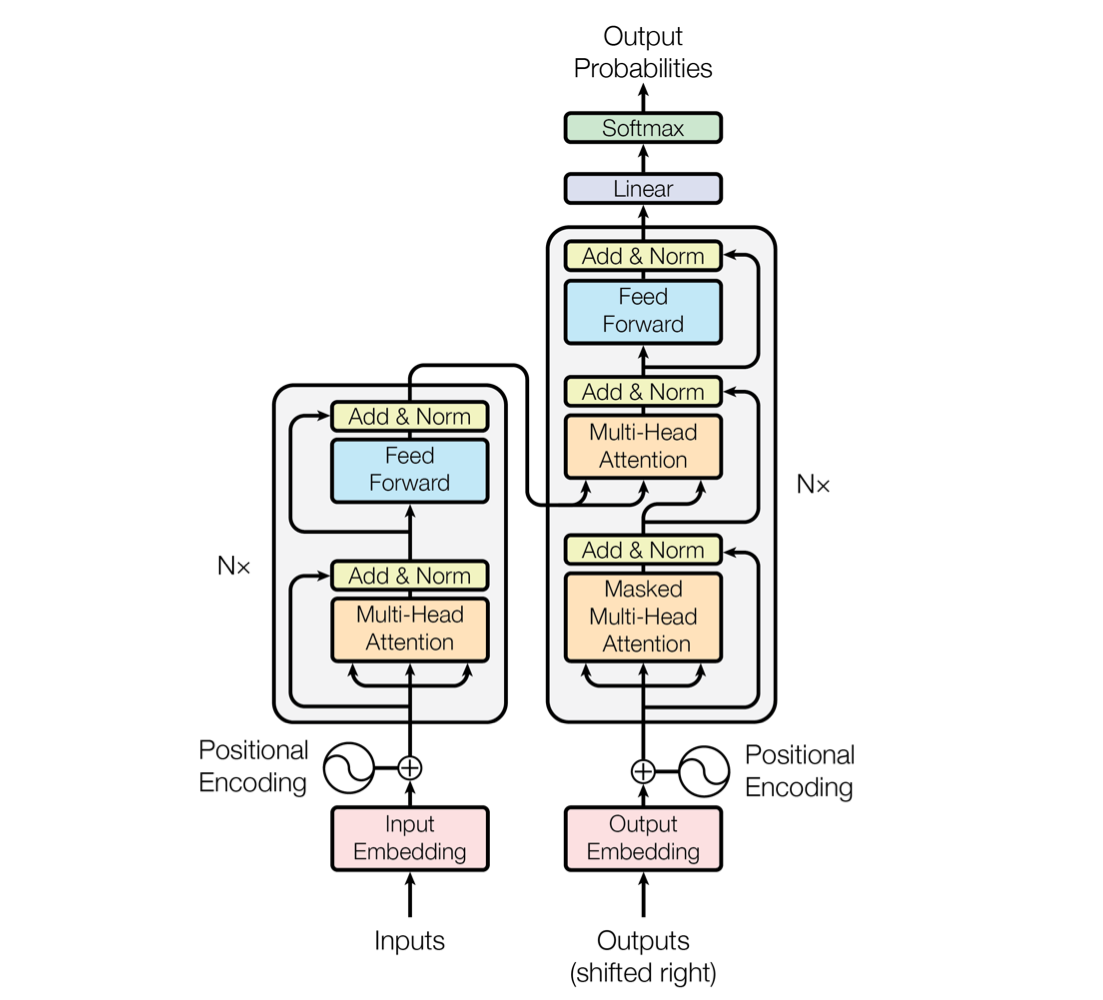
3.1 Encoder and Decoder Stacks
Encoder
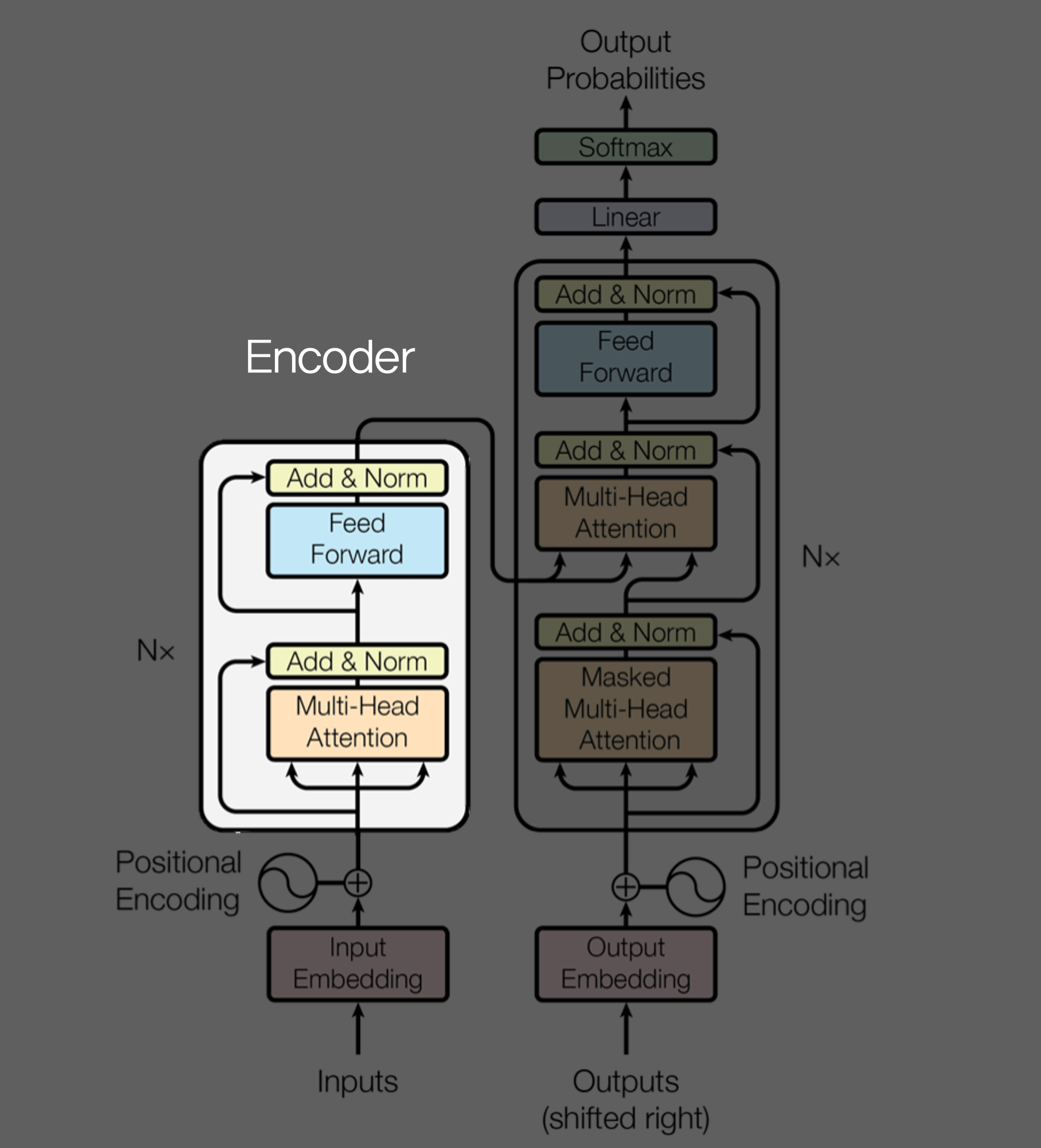
Encoder Layer 를 구성하는 sub-layer:
- Multi-Head Self-Attention
- Position-wise Feed-Forward Network
크게 이 둘이라고 보면 된다.
각 sub-layer 의 output은 'Add & Normalization' 을 거치는데, 이를 수식화해서 표현하면

즉, (sub-layer을 거치기 전 input + sub-layer의 output) 더해주는 셈이다.
이유는? sublayer을 통해 소실되는 정보를 보존하기 위해서일까? 몰루..
1 class EncoderLayer(nn.Module):
2 ''' Compose with two layers '''
3
4 def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
5 super(EncoderLayer, self).__init__()
6
7 ## sub-layer
8 self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
9 self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
10
11 def forward(self, enc_input, slf_attn_mask=None):
12 enc_output, enc_slf_attn = self.slf_attn(
13 enc_input, enc_input, enc_input, mask=slf_attn_mask)
14 enc_output = self.pos_ffn(enc_output)
15 return enc_output, enc_slf_attn
16 클래스 정의도 간단명료하다.
- line 8 : Multi-Head Attention layer
- line 9 : Position-wise Feed Forward Network layer
- line 12 ~ 13
- enc_output :
- enc_slf_attn :
- line 14 : enc_output이 Position-wise Feed Forward 를 거쳐간다.
- 'Add & Normalization' 코드는 여기서 각 sublayer 내부에 존재하는 듯 하다.
Decoder
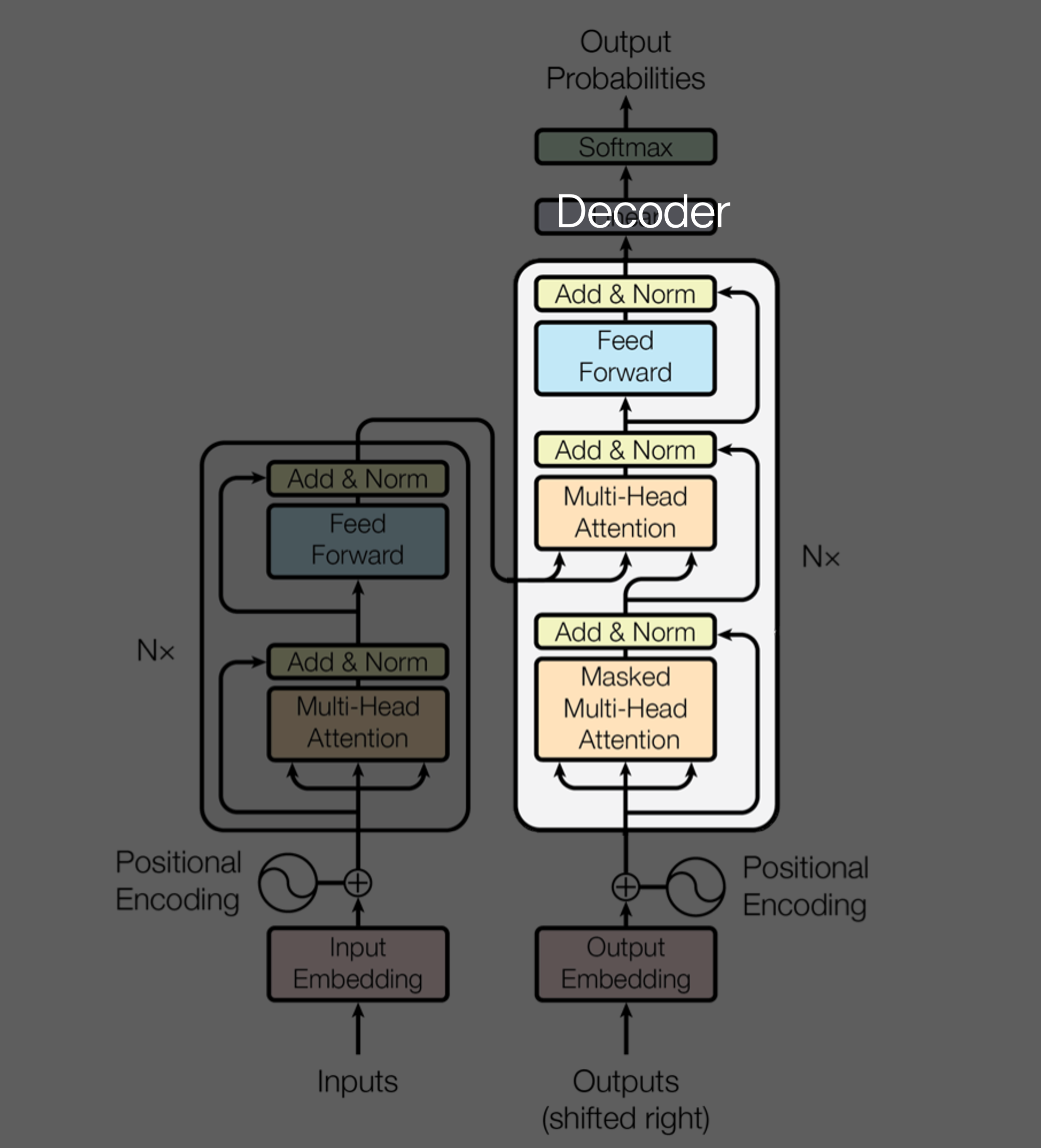
Decoder Layer 를 구성하는 sub-layer :
- Masked Multi-Head Self-Attention Layer
- Multi-Head Self-Attention Layer
- Position-wise Feed Forward Network Layer
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask)
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn3.2 Attention
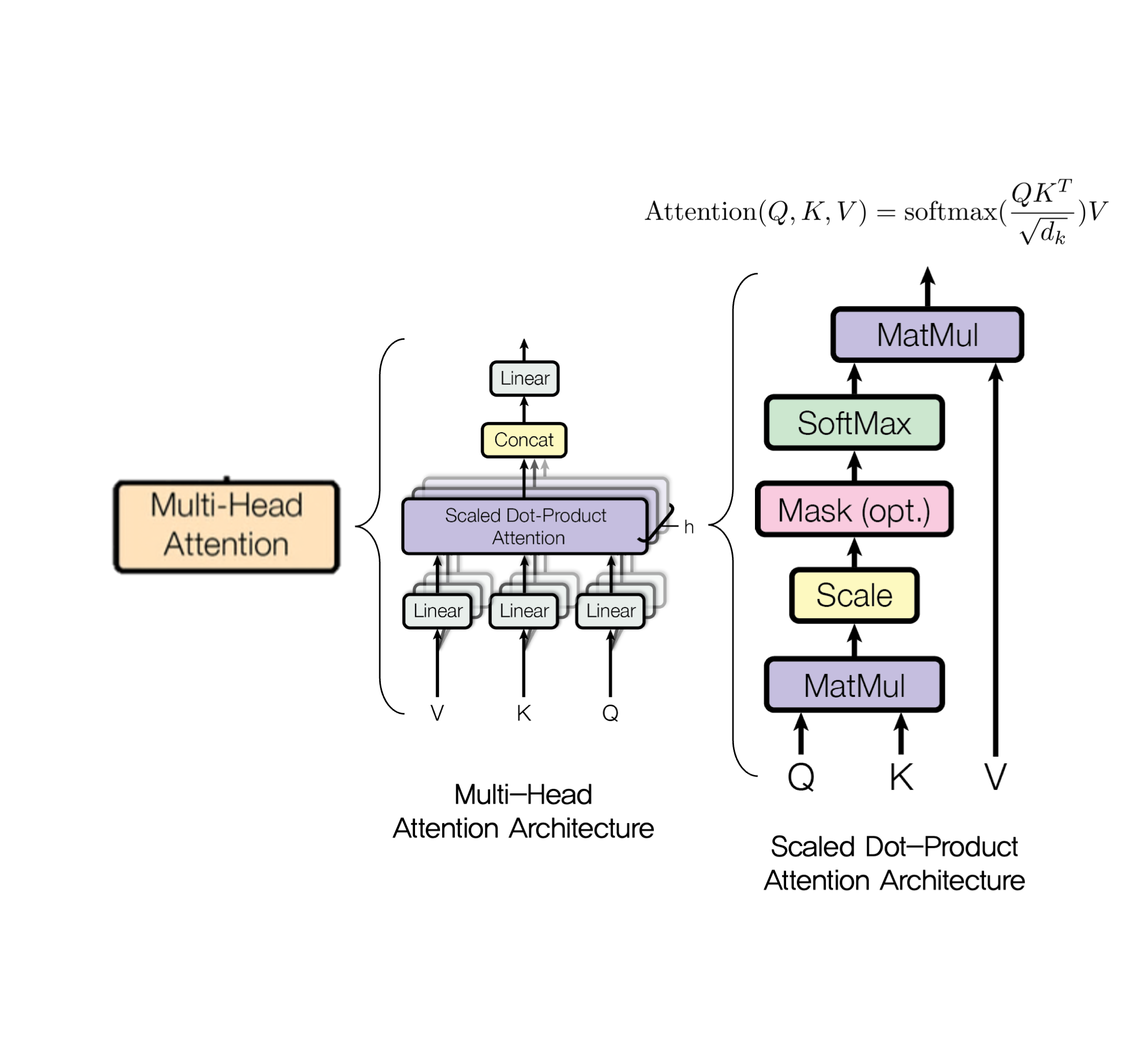
3.2.1 Scaled Dot-Product Attention
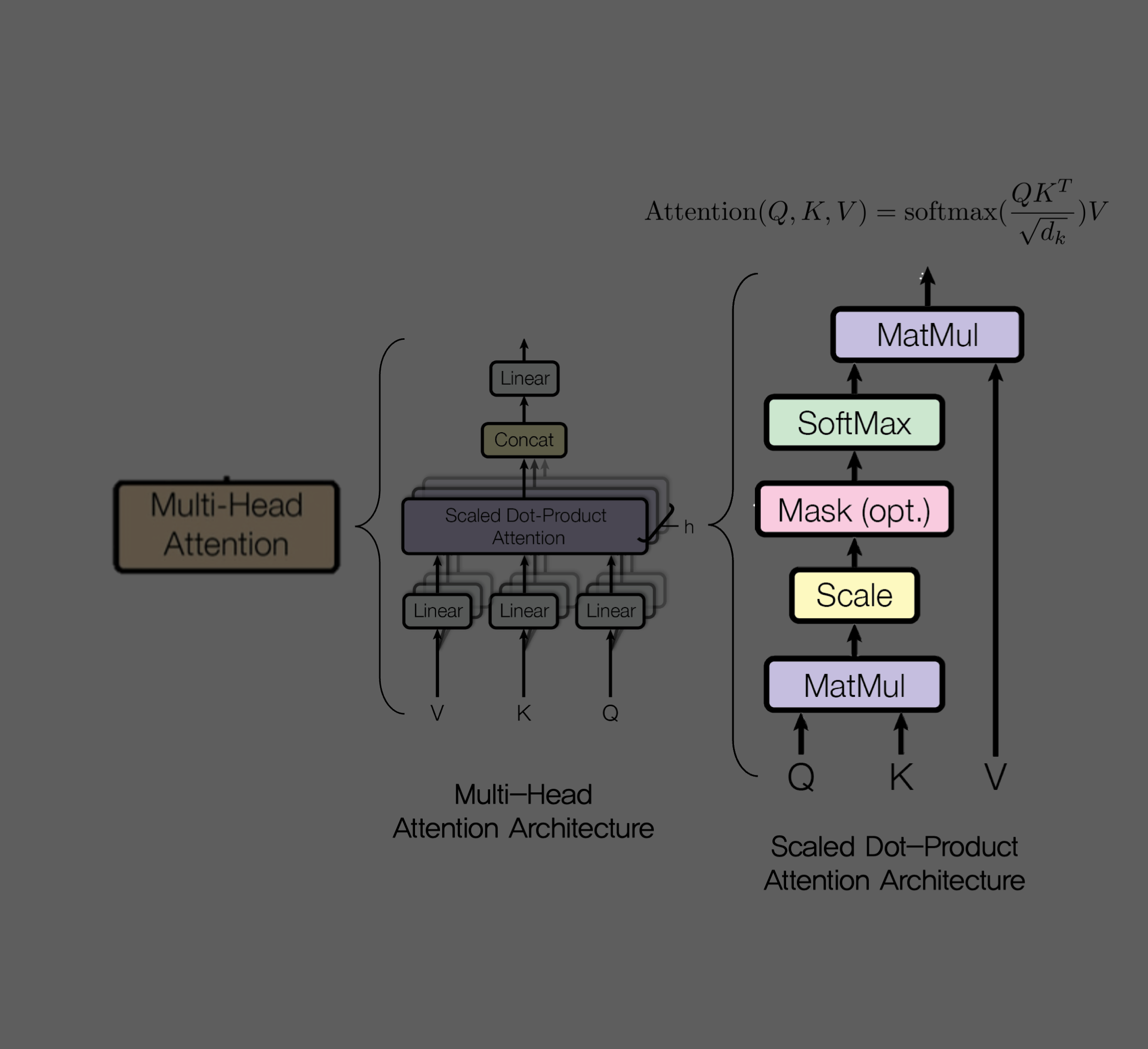
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn3.2.2 Multi-Head Attention
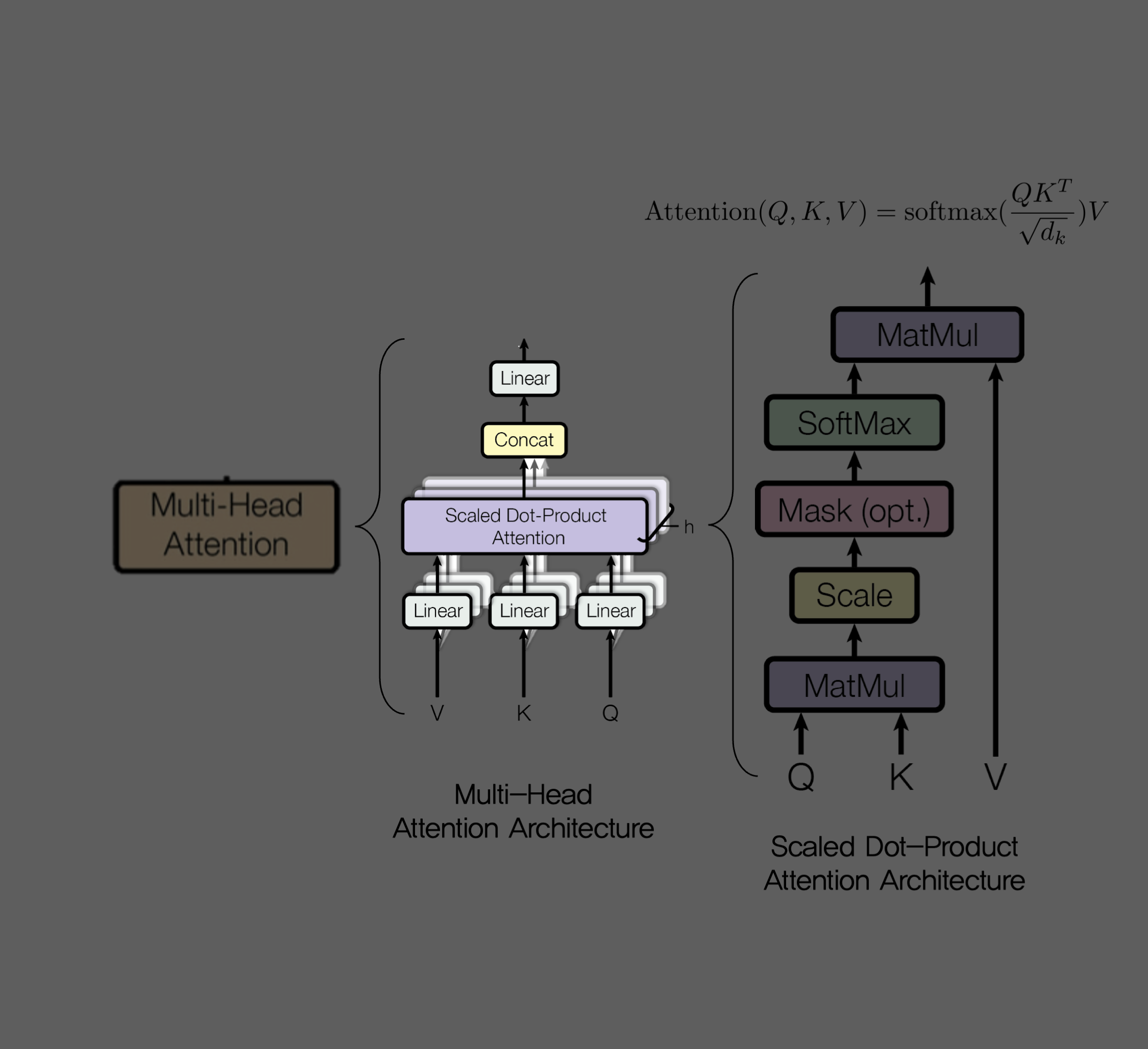
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)
def forward(self, q, k, v, mask=None):
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
sz_b, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
q = self.w_qs(q).view(sz_b, len_q, n_head, d_k)
k = self.w_ks(k).view(sz_b, len_k, n_head, d_k)
v = self.w_vs(v).view(sz_b, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1) # For head axis broadcasting.
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
q = q.transpose(1, 2).contiguous().view(sz_b, len_q, -1)
q = self.dropout(self.fc(q))
q += residual
q = self.layer_norm(q)
return q, attn3.2.3 Applications of Attention in our Model
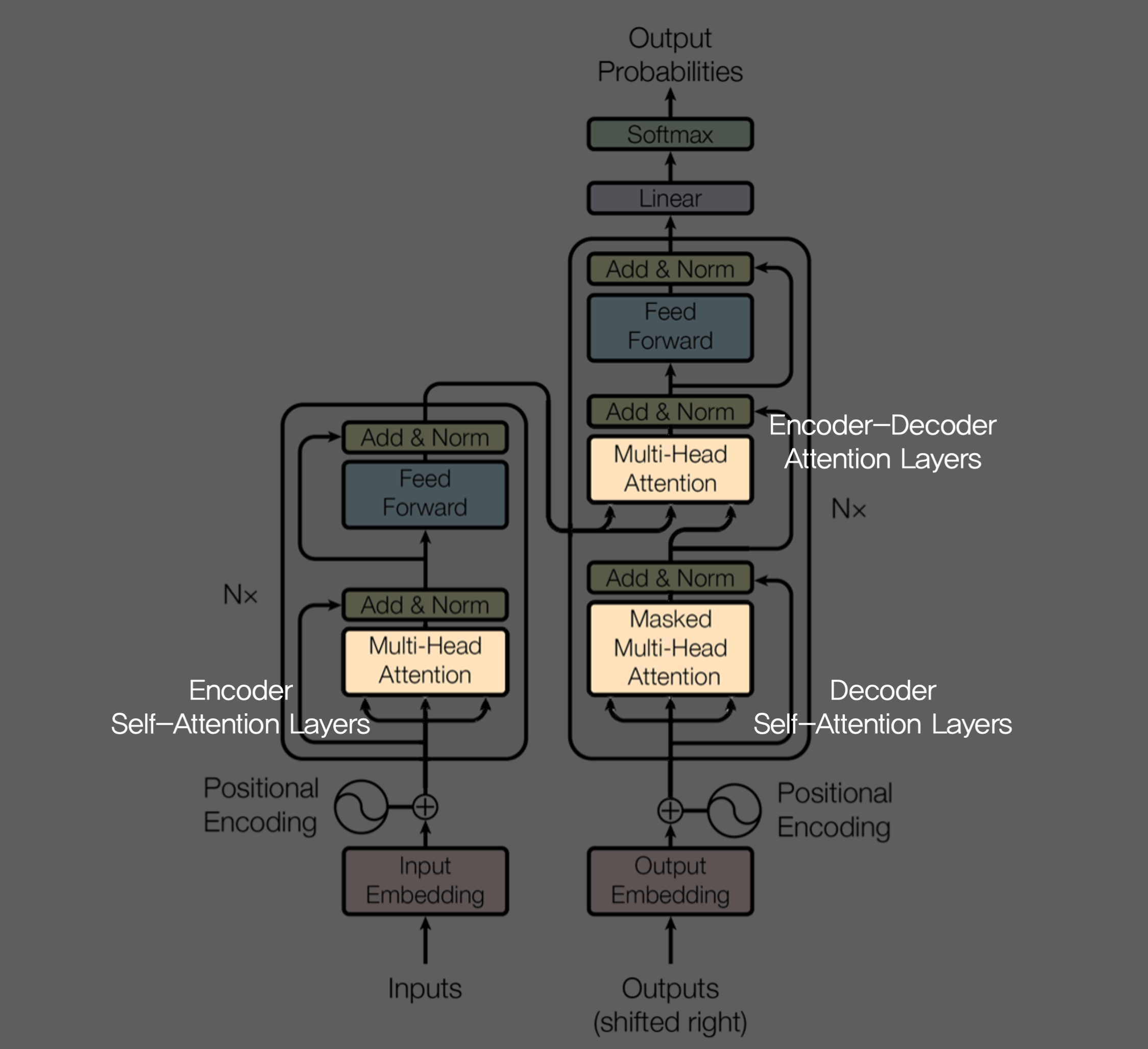
(1) Encoder-Decoder Attention Layers
(2) Encoder's Self-Attention Layers
(3) Decoder's Self-Attention Layers
3.3 Position-wise Feed-Forward Networks
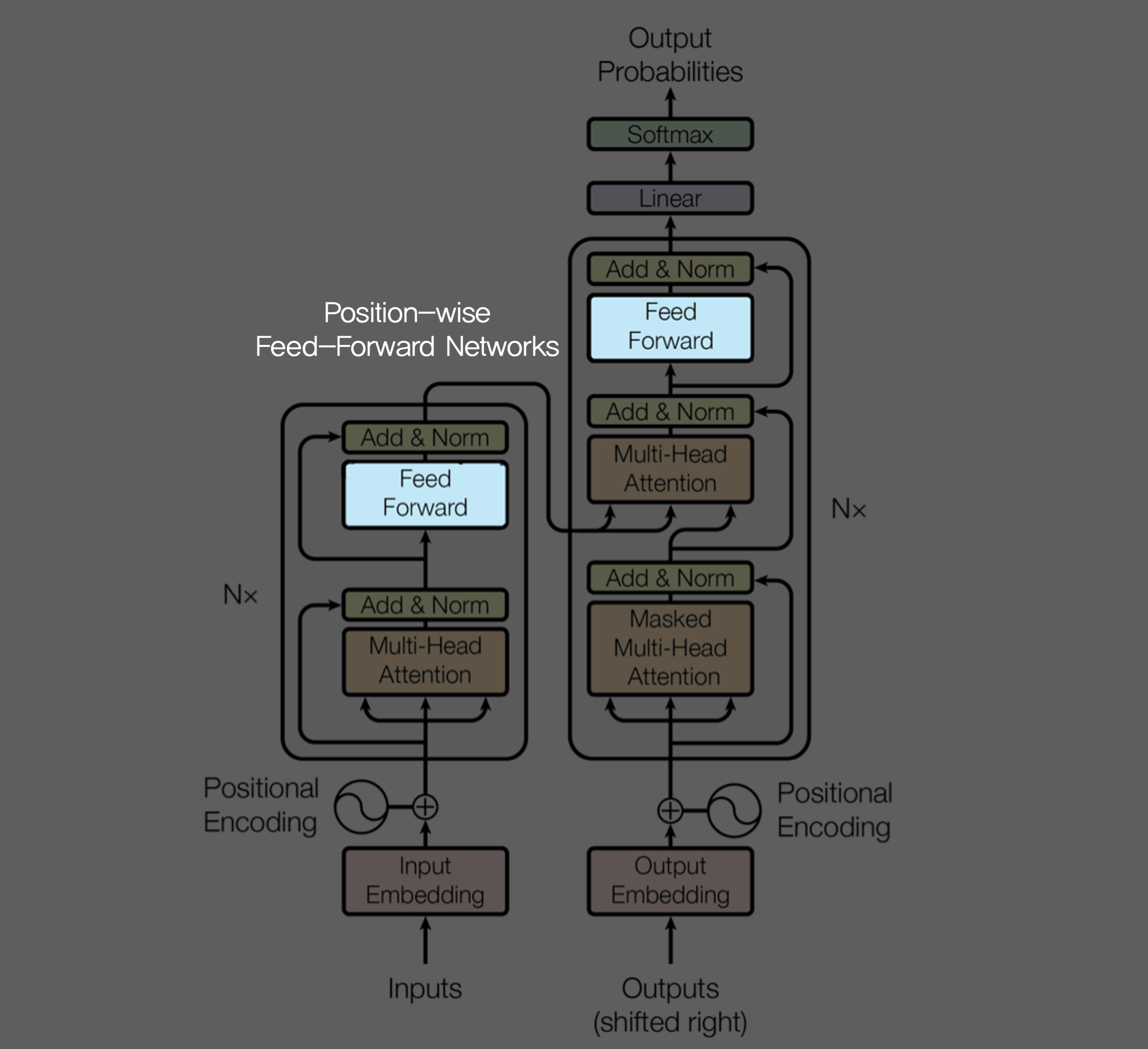
앞서 Encoder에도 있고, Decoder 에도 있던 Feed Forward Network!
평범하지만 늘 필요한 fully-connected feed forward network 이며, 각각의 position 마다 동일하게 한번씩 적용된다.
class PositionwiseFeedForward(nn.Module):
''' A two-feed-forward-layer module '''
def __init__(self, d_in, d_hid, dropout=0.1):
super().__init__()
self.w_1 = nn.Linear(d_in, d_hid) # position-wise
self.w_2 = nn.Linear(d_hid, d_in) # position-wise
self.layer_norm = nn.LayerNorm(d_in, eps=1e-6)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
residual = x
x = self.w_2(F.relu(self.w_1(x)))
x = self.dropout(x)
x += residual
x = self.layer_norm(x)
return 3.4 Embeddings and Softmax
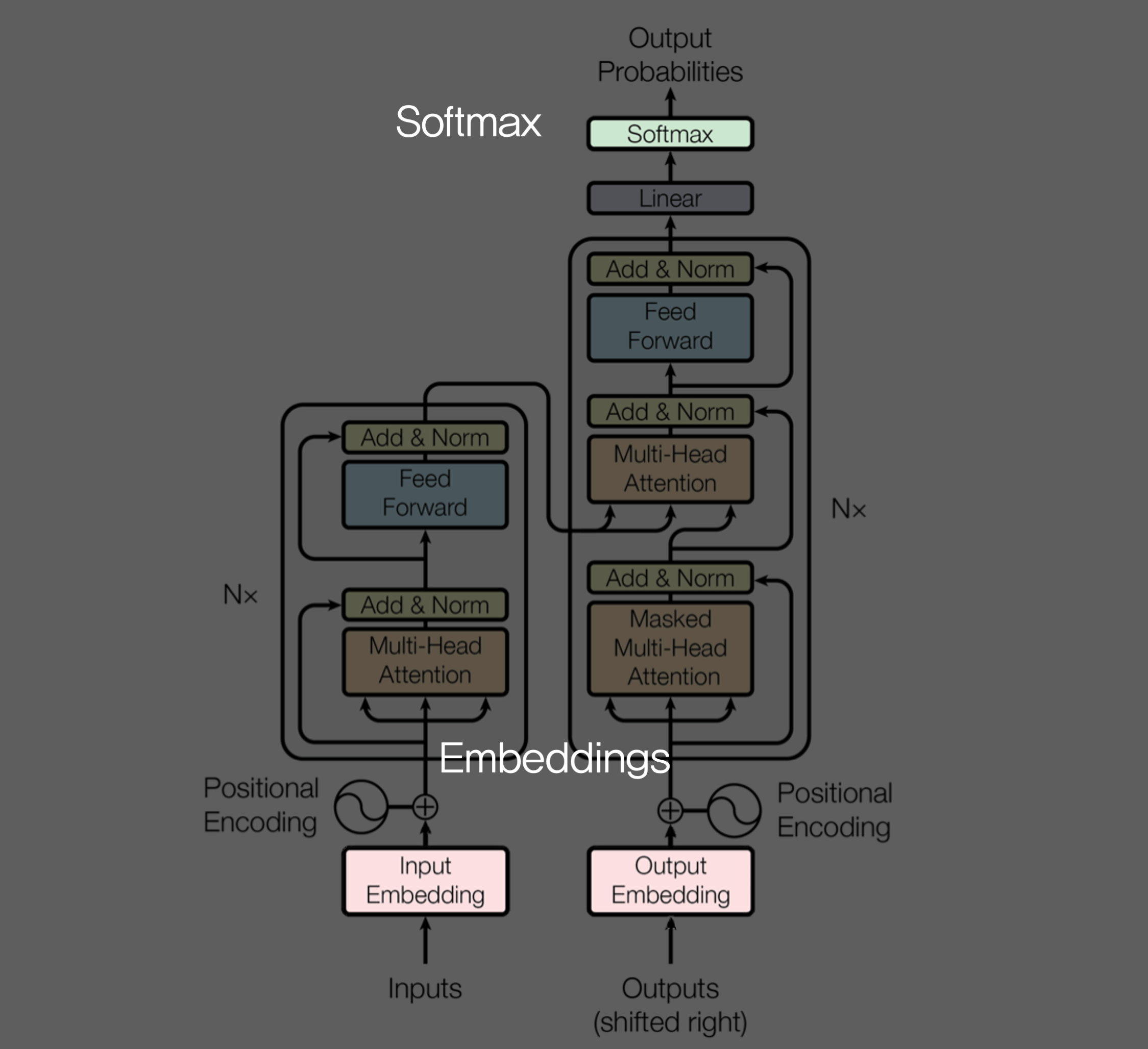
3.5 Positional Encoding
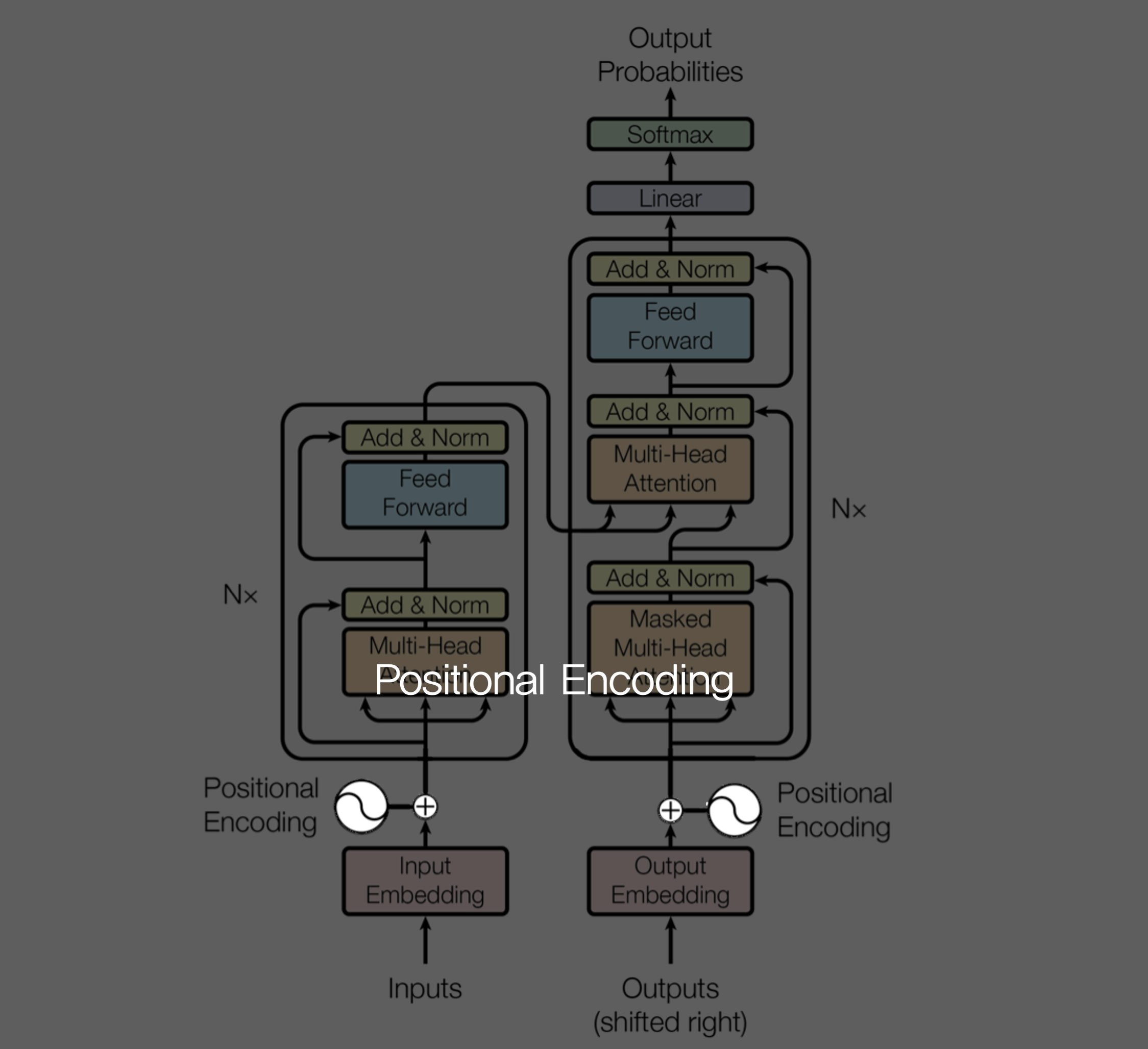
class PositionalEncoding(nn.Module):
def __init__(self, d_hid, n_position=200):
super(PositionalEncoding, self).__init__()
# Not a parameter
self.register_buffer('pos_table', self._get_sinusoid_encoding_table(n_position, d_hid))
def _get_sinusoid_encoding_table(self, n_position, d_hid):
''' Sinusoid position encoding table '''
# TODO: make it with torch instead of numpy
def get_position_angle_vec(position):
return [position / np.power(10000, 2 * (hid_j // 2) / d_hid) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_position_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
def forward(self, x):
return x + self.pos_table[:, :x.size(1)].clone().detach()4. Why Self-Attention
self-attention layers vs. 순환신경망, 합성곱신경망 layers
(1) Layer 당 연산복잡도
(2) 병렬화할 수 있는 연산량
(3)
5. Training
6. Results
6.1 Machine Translation
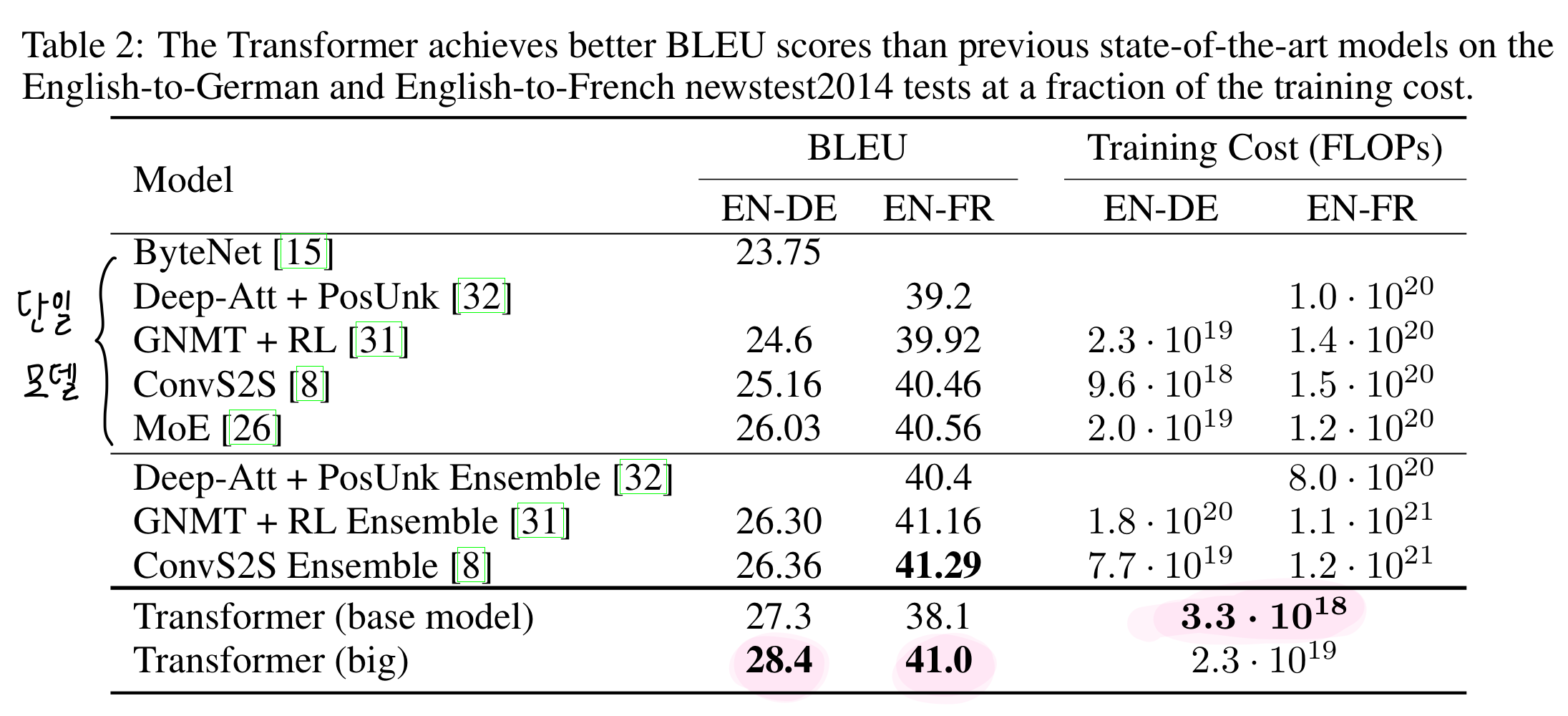
WMT 2014 English-to-French 번역 task에 있어 단일 모델 중 최고의 성능 보임 (Ensemble은 단일 모델이 아닌, 여러 모델을 활용하는 것).
이전 SoTA 모델 대비 Training Cost 는 1/4 정도로 감소!
엄청나게 효율적인데, 또 단일모델 기준 성능은 일빠따다 이말.
6.2 Model Variations
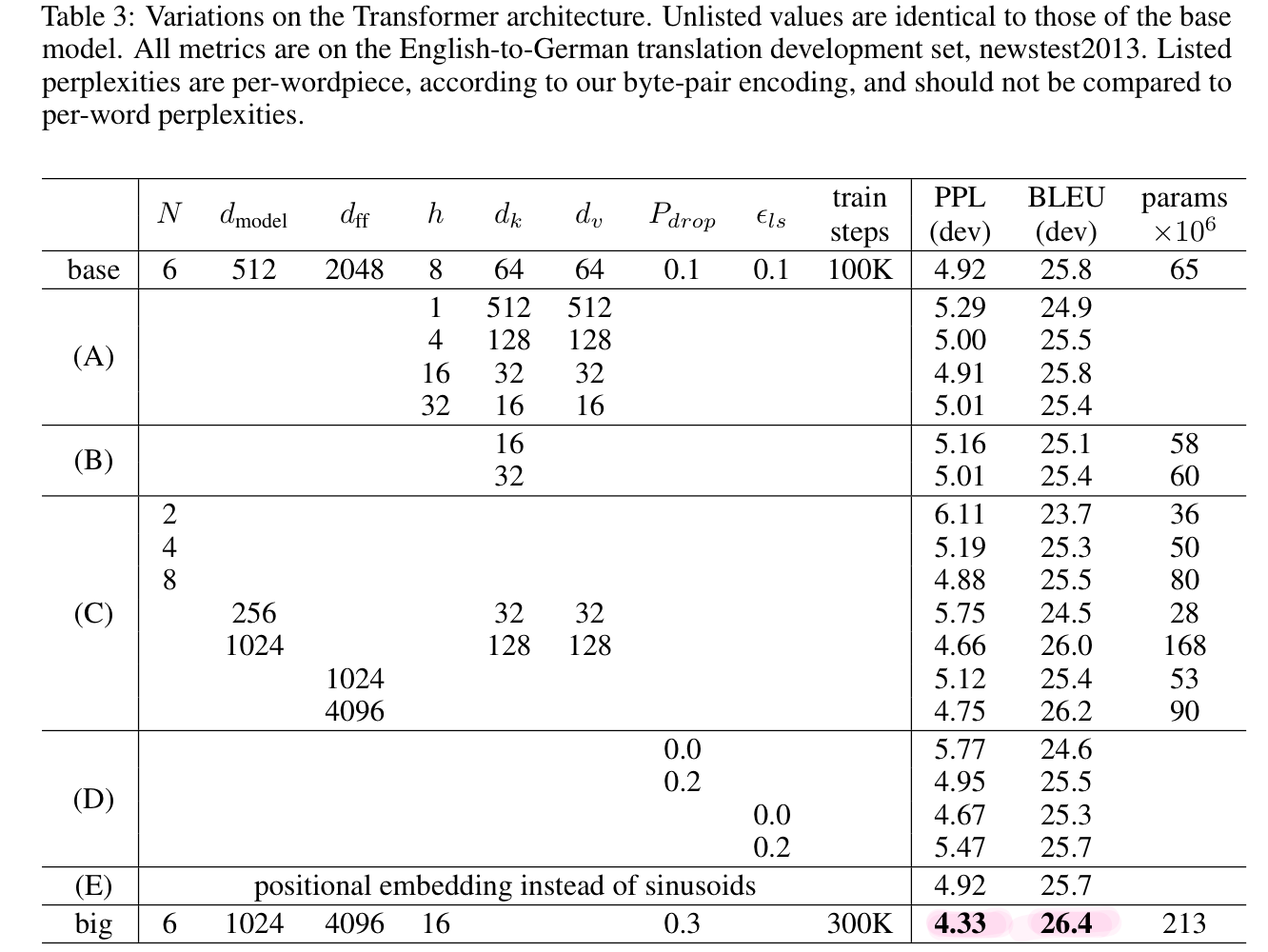
7. Conclusion
Less Sequential 이 답입니다 여러분 ~ 이라네요
