Redis VS MySQL 비교
💡Redis
- In-Memory 기반 Database
- 메모리에 저장하기 때문에 속도가 빠르다
- Replication, Sharding 등 분산 시스템을 제공하여 Scale out이 편리하다
- Sharding 방식에서는 Hash를 이용해 데이터의 정합성을 유지하지만, Replication의 경우 lag이 발생할 수 있기 때문에 데이터의 정합성이 떨어질 수 있다.
💡MySQL
- Disk 기반 Database
- 메모리에 접근하는 것 보다 Disk I/O가 느리기 때문에, 인메모리 기반 데이터베이스보다 느리다
- 메모리보다 디스크가 가격이 저렴하기 때문에, 대용량 데이터베이스 구성이 가능하다.
- 데이터의 정합성이 지켜진다.
Disk I/O 때문에 MySQL이 느린걸까?

- Jmeter 테스트를 통해 부하를 주는 동안 리소스 모니터링을 해보았다.
- stock_price.ibd 파일이 쿼리 수행에 필요한 파일이다.
- 현재 서버에 저장된 stock_price.ibd 파일의 용량은 720MB이다.
- 처음에는 stock_price.ibd 파일에 System이 접근 하였지만, 요청이 계속 되며 같은 요청이 들어왔기 때문에 Window Os는 더이상 System에 접근하지 않는 모습을 보여준다.
- 실제 서비스 환경에서는 RDBMS가 많은 데이터를 가지고 있고, 다양한 리소스에 접근해야 하기 때문에 일어나지 않을 수 있지만, 현재 테스트 상황에서 MySQL보다 Redis가 빠른 이유는 Disk I/O 때문은 아니라는 것을 알 수 있다.!
Response Latency
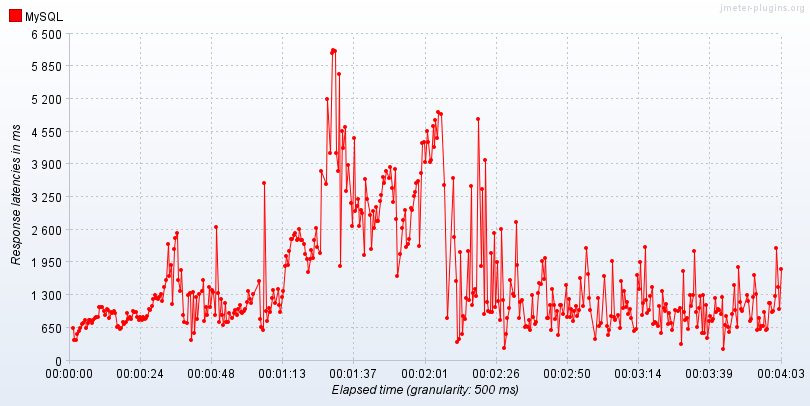
- MySQL을 사용 했을 때, Response Latency를 측정 해보았다.
- 처음에는 조금씩 증가하는 모습을 보여주지만 일정 시간이 지난 뒤에는 안정권에 들어서며 다시 Response Latency가 감소한 것을 볼 수 있다.
- 측정 결과, Latency가 줄어든 시점부터 더 이상 Disk I/O가 발생하지 않는다는 것 발견했다.
- RDBMS는 기본적으로 Disk에서 가져오는 것으로 알고 있었지만, 특정 상황에서는 Disk I/O가 발생하지 않을 수 있는 것이다.
언제 Disk I/O가 발생하지 않을까?
1. InnoDB의 Buffer Pool에 데이터가 존재할 경우
- 먼저 InnoDB 설정으로 Buffer Pool Size를 설정할 수 있다.
- Buffer Pool은 데이터베이스에서 자체적으로 자주 사용되는 데이터들을 저장하는 공간이다.
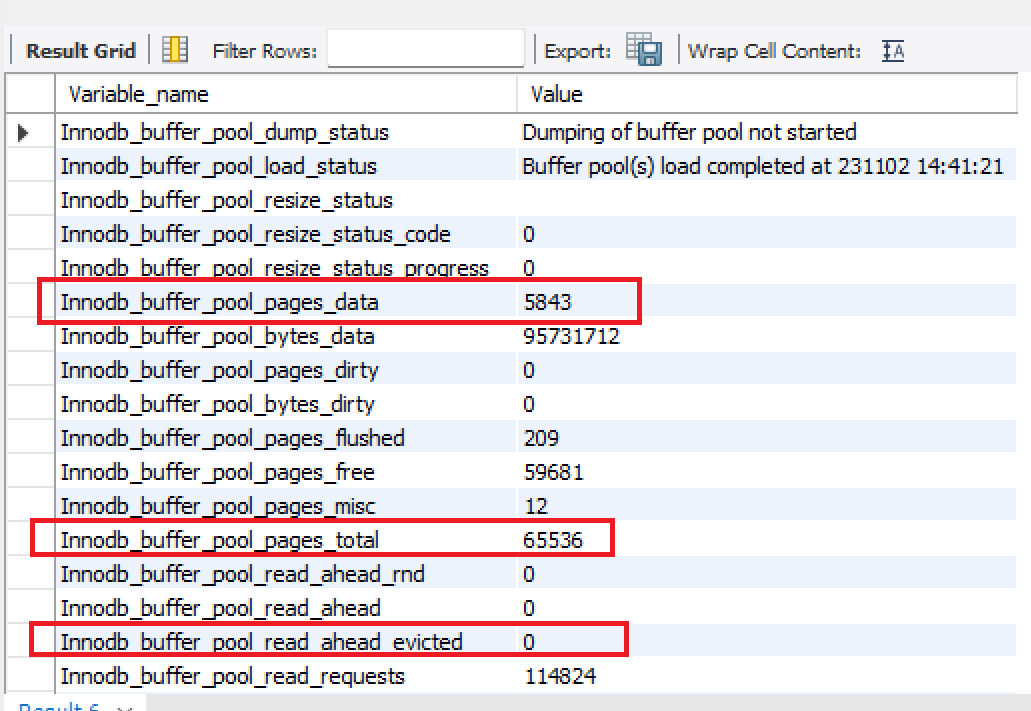
- 테스트를 수행한 뒤 buffer pool과 관련된 값 3가지를 확인해보면 잘 저장되었는지 알 수 있다.
- 65536 페이지 중, 5843개의 페이지를 사용한 것이고, evicted가 0개이기 때문에 모든 데이터를 페이지에 저장하여 따로 교체되는 비용은 발생하지 않았다는 것을 의미한다.
2. 운영체제의 페이지 교체 알고리즘에 의해, 메모리에 데이터가 존재할 경우
- 그렇다면 buffer pool을 줄여서 evicted가 일어나게 되면 Disk I/O가 일어날까?
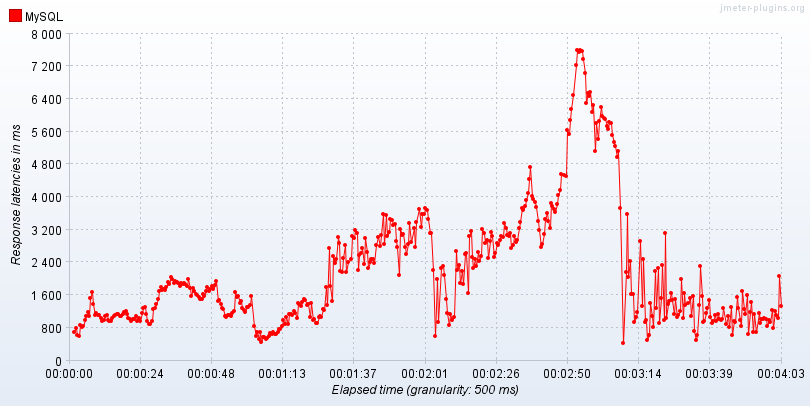
- Buffer Pool을 0MB로 설정하고 실행 해봐도, 느리긴 하지만 시간이 지나면 안정화 되는 모습을 볼 수 있다.
- 실제로 리소스 모니터링을 해봤을 때도 Disk I/O가 발생하지 않았다.
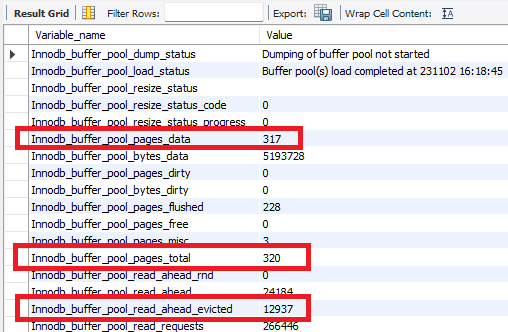
- 하지만 데이터 베이스를 확인하면 페이지는 이미 꽉 차있고, evicted도 많이 발생한 것을 알 수 있다.
- 즉, 메모리에 이미 데이터가 존재하기 때문에 Disk I/O를 할 필요가 없는 것이다.
페이지 교체 알고리즘
- Window - Clock 알고리즘
- Linux - Second Chance 알고리즘
- FIFO에 기반을 두고, 참조비트와 갱신비트를 함께 검사하여 메모리를 내리는 방식이다
- FIFO, Clock(NRU), LFU, LRU, MFU
- 운영체제의 페이지 교체 정책에 따라, Buffer pool을 사용하지 않아도 Disk I/O가 발생하지 않을 가능성이 있다.
나의 서버 구조
- 그렇다면 왜 Latency를 측정하면 Redis가 더 빠르게 나오는 것일까?
- In-Memory 기반이라는 가정은 이미 RDBMS도 메모리에서 가져올 수 있기 때문에 아닐 것이다.
- 다른 이유로 인해 느려지는 것이라면, 어떤 이유가 있을까?
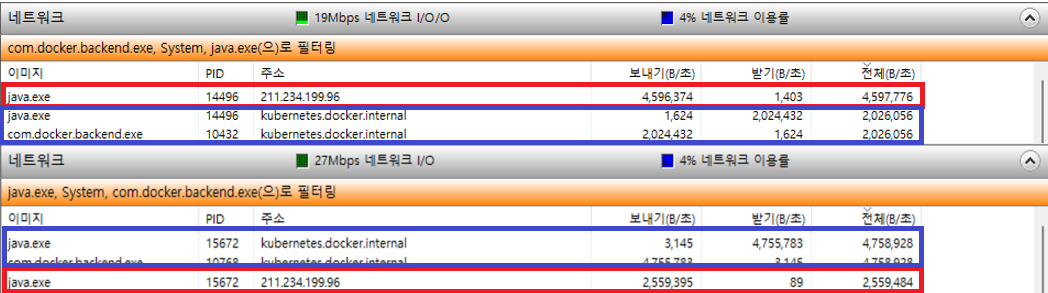
- 위가 Redis, 아래가 MySQL
- 전송중인 데이터의 양이 다르고, 같아 보이지만 아주 중요한 차이가 있다.
- Redis의 경우 Client에게 전송하는 데이터가, 서버와 Redis간에 전송하는 데이터의 2배이다.
- MySQL의 경우 Client에게 전송하는 데이터가, 서버와 MySQL간에 전송하는 데이터의 0.5배이다
- 즉 서버와 데이터베이스간의 통신에서 4배의 차이가 발생하는 것이다.
Redis 데이터 전달 구조
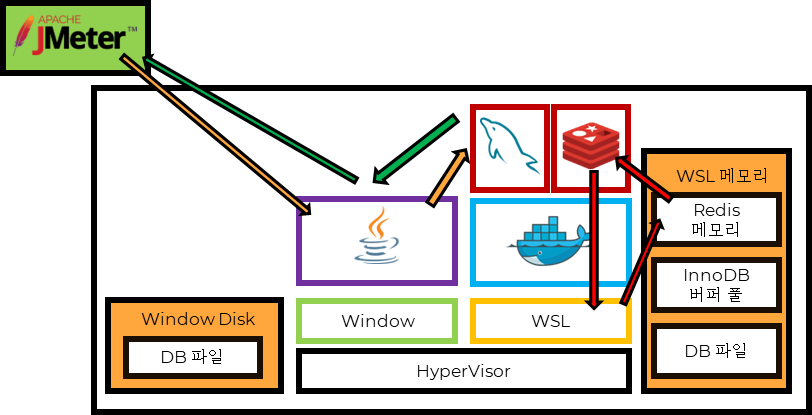
- JMeter를 통해 Http 요청
- jvm에서 요청을 받아서 Redis로 전달
- Redis는 WSL의 리소스에 메모리를 할당 해두고, 자신의 메모리에 접근
- 접근된 데이터를 바탕으로 Response 전달
MySQL 데이터 전달 구조
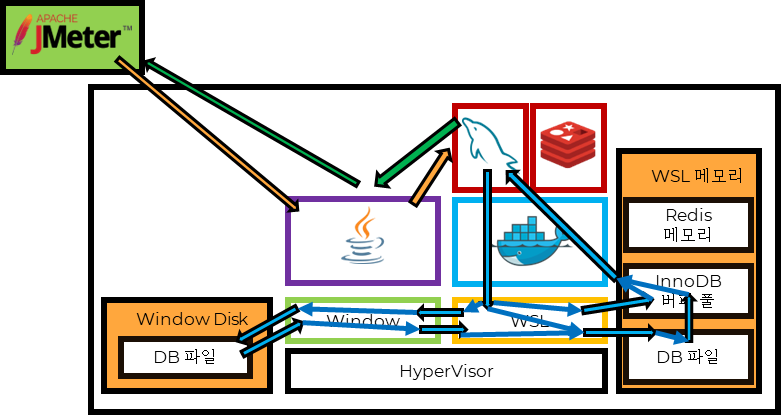
- JMeter를 통해 Http 요청
- jvm에서 요청을 받아서 MySQL로 전달
- MySQL이 데이터에 접근
- InnoDB 버퍼 풀 확인 ⇒ Memory
- WSL 메모리에 올라가 있는 DB 파일 확인 ⇒ Memory
- WSL에서 Window에 데이터를 요청하여 DB파일 메모리에 적재 ⇒ Disk I/O
- Response 전달
네트워크 비용이 핵심
- 결국 WSL과 컨테이너 사이에 통신이 발생하게 된다.
- 이 통신에서 전달하는 데이터가 4배 차이 나기 때문에, 일어나는 현상이다.
- 서비스가 커진다면 Disk I/O가 문제가 될 수 있다.
- 자주 사용되는 정보는 DB Buffer Pool과, OS의 메모리에 자동으로 캐싱된다고 할 수 있다.
- 그렇다면 Redis는 어떤 관점으로 바라봐야 할까?
- 데이터 크기의 차이로 인해 병목이 발생할 수 있고, 결과물을 Redis에 저장한다면 더 적은 네트워크 비용이 발생하여 Latency를 줄일 수 있다.
- 서비스가 커질 경우 로컬 캐싱이 이루어지지 않고 buffer pool과 메모리가 계속 교체될 수 있기 때문에 Redis를 활용하여 직접 캐싱해야할 수 있다.
- 메인 데이터베이스에 주는 부담을 Redis를 통해 줄여 다른 서비스에 더 빠른 응답을 제공할 수 있다.

실생활에 가치를 더하는 개발자