
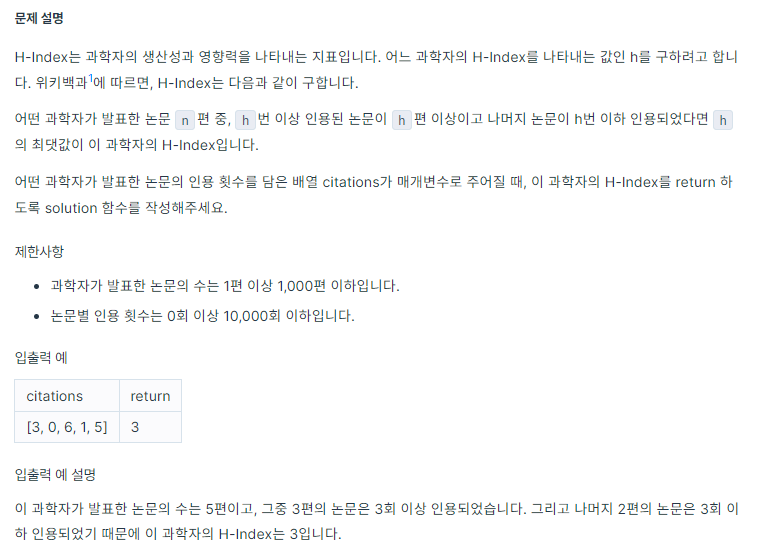
문제
풀이
오름차순
def solution(citations):
citations.sort()
n = len(citations)
for i in range(n):
if citations[i] >= n-i:
return n-i
return 0내림차순
def solution(citations):
citations.sort(reverse=1)
for i in range(len(citations)):
if citations[i]<=i:
return i
return len(citations) #citations 배열 모두 인용된 것으로 간주됨결과

해석
문제를 해석하는 것에 어려움은 있었지만 이해는 했다. 하지만 코드를 어떻게 짜야할 지 전혀 감이 오지 않았다.. 계속 고민해본 결과 안풀릴 것 같아 다른 사람의 코드를 참고하여 작성했다.
조건
- h번 이상 인용된 논문이 h편 이상이어야 함.
- 나머지 논문이 h번 이하 인용되어야 함.
오름차순
예시에 따른 오름차순의 코드를 먼저 해석해보자면,
i = 0, 1, 2, 3, 4
citations[i] = 0, 1, 3, 5, 6
n-i = 5, 4, 3, 2, 1
n-i의 경우 citations[i]번 이상 인용된 논문의 갯수로 해석했다.
5는 [0, 1, 3, 5, 6] : i=0일 때, 0번 인용된 논문 [0, 1, 3, 5, 6]의 갯수인 것이다.
4는 [1, 3, 5, 6] : i=1일 때, 1번 인용된 논문 [1, 3, 5, 6]의 갯수인 것이다.
... 과 같다.
for문이 돌아가면서 인용된 논문의 갯수를 최댓값부터 1씩 줄여나간다.
최댓값을 찾아야하기 때문에 가장 큰 값부터 시작한다.
내림차순

I believe in myself.