파이프 라인 만들기
전처리에 필요한 값들 불어오기
from pyspark.ml.feature import Imputer, StringIndexer, VectorAssembler, MinMaxScaler
# Gender
stringIndexer = StringIndexer(inputCol = "Gender", outputCol = 'GenderIndexed')
# Age
imputer = Imputer(strategy='mean', inputCols=['Age'], outputCols=['AgeImputed'])
# Vectorize
inputCols = ['Pclass', 'SibSp', 'Parch', 'Fare', 'AgeImputed', 'GenderIndexed']
assembler = VectorAssembler(inputCols=inputCols, outputCol="features")
# MinMaxScaler
minmax_scaler = MinMaxScaler(inputCol="features", outputCol="features_scaled")
stages = [stringIndexer, imputer, assembler, minmax_scaler]- 전처리에 사용했던 피처 관련 라이브러리를 스테이지에 어레이 형태로 모아줌
훈련에 사용할 알고리즘을 넣어주기
from pyspark.ml.classification import LogisticRegression
algo = LogisticRegression(featuresCol="features_scaled", labelCol="Survived")
lr_stages = stages + [algo]- 파이프라인에 사용할 알고리즘 모델도 어레이에 넣어줌
파이프라인에 도구들 넣어주기
from pyspark.ml import Pipeline
pipeline = Pipeline(stages = lr_stages)- 스파크가 제공하는 파이프라인에 모아둔 어레이를 스테이지 인자로 넘겨줌
트레인, 테스트셋 만들기
df = data.select(['Survived', 'Pclass', 'Gender', 'Age', 'SibSp', 'Parch', 'Fare'])
df.show()
train, test = df.randomSplit([0.7, 0.3])- 훈련에 사용할 컬럼들을 골라주고 트레인, 테스트셋 만들어줌
만든 파이프라인을 통해 학습 진행하고 테스트 결과 보기
lr_model = pipeline.fit(train)
lr_cv_predictions = lr_model.transform(test)
evaluator.evaluate(lr_cv_predictions)
0.8618733062330615- 만든 파이프라인에 트레인셋을 학습시켜주고
- transform 메소드로 테스트 값을 실행시켜주고 평가 메소드로 수치를 확인
평가기 선정
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator(labelCol='Survived', metricName='areaUnderROC')- 평가 답안을 labelcol에 설정해주고 어떤 지표를 설정할지 metricName에 골라줌
- areaUnderROC 를 사용
ParamGrid 사용하기
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
paramGrid = (ParamGridBuilder()
.addGrid(algo.maxIter, [1, 5, 10])
.build())
cv = CrossValidator(
estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=5
)
- 알고리즘에 필요한 하이퍼 파라미터를 여러개 옵션으로 설정해주고(여기서는 학습 횟수)
- CrossValidator를 통해 각 옵션에 위에서 만든 도구들을 넣어줌
ParamGrid, Pipeline 적용한 모델 사용하기
# Run cross validations.
cvModel = cv.fit(train)
lr_cv_predictions = cvModel.transform(test)
evaluator.evaluate(lr_cv_predictions)
0.8603489159891599- 종합해 학습한 cvModel를 통해 테스트를 진행하고 평가 진행
parmagrid 에 의한 결과를 살펴보기
import pandas as pd
params = [{p.name: v for p, v in m.items()} for m in cvModel.getEstimatorParamMaps()]
pd.DataFrame.from_dict([
{cvModel.getEvaluator().getMetricName(): metric, **ps}
for ps, metric in zip(params, cvModel.avgMetrics)
])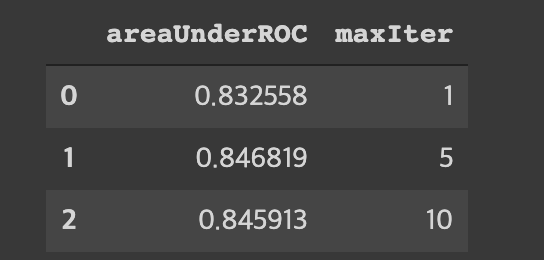
- cvModel.getEstimatorParamMaps()을 통해 maxIter의 숫자들 가져와주고
- cvModel.avgMetrics를 통해 평가 지표를 가지고 옴
- 데이터 프레임화 시켜서 각 파라미터별 평가수치를 모니터링 가능

컴퓨터가 좋아