Spark의 구동
- Spark는 기본적으로 메모리 기반
- 메모리가 부족해지면 디스크사용
- 분산 컴퓨터 환경 지원
- 배치 프로그래밍, 스트리밍 프로그래밍, SQL, 머신 러닝, 그래프 분석 등의 서비스 지원
Spark의 구조
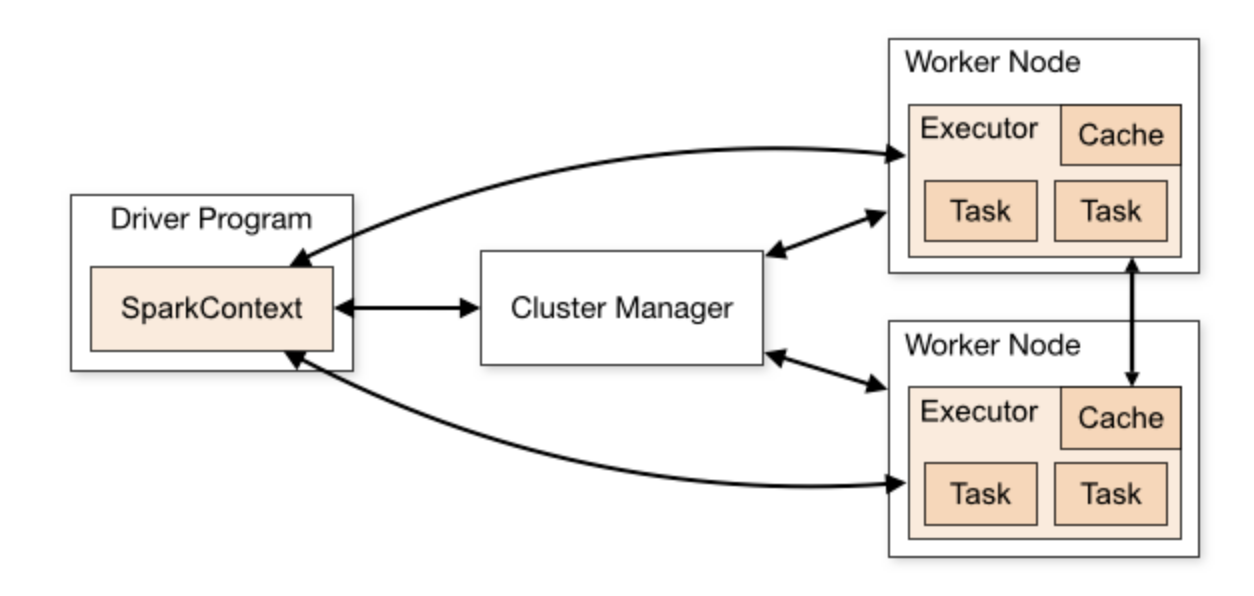
- 드라이버 프로그램의 존재
- 클러스터 매니저를 통해 데이터를 워크노드에 분산시켜줌
Spark 프로그래밍 개념
- RDD(Resilient Distributed Dataset)
- 로우레벨 프로그래밍 API로 세밀한 제어 가능
- 코딩의 복잡도 증가 - Dataframe & Dataset(판다스의 데이터프레임과 흡사)
- 하이레벨 프로그래밍 API로 점점 많이 사용하는 추세
- SparkSQL을 사용한다면 쓰게 됨
Pandas비교
공통점
- 구조화된 데이터를 읽어오고 저장
- csv, json 등 다양한 포맷 지원
- 웹과 관계형 데이터베이스에서 읽어오는 것도 가능 - 다양한 통계 제공
- 평균, 표준편차 등 컬럼별 계산가능
- 컬럼간 correlation 계산 가능 - 데이터 청소작업(데이터 전처리)
- 컬럼별로 값이 존재하지 않는 경우 디폴트 값 지정
- 컬럼별로 값의 범위를 조정 - Visualization
- Matplotlib와 연동해 다양한 형태의 시각화 지원
Pandas의 데이터 구조
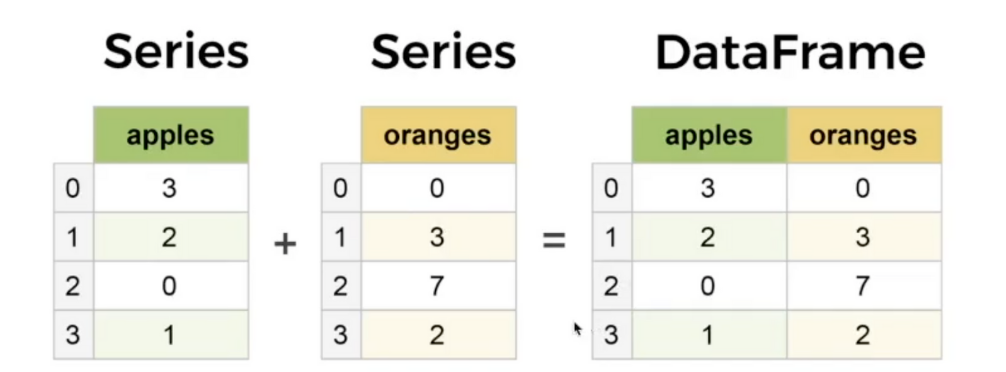
- 엑셀의 시트에 해당하는 것이 Dataframe
- 엑셀 시트의 컬럼에 해당하는 것이 Series
- 입력 dataframe을 원하는 최종 dataframe으로 계속 변환하는 것이 핵심
차이점
- Pandas는 소규모의 구조화된 데이터를 다루는데서 최적
- Spark는 큰데이터를 여러 서버에 병렬 처리를 지원함

컴퓨터가 좋아