모델 빌딩과 관련된 흔한 문제들
- 트레이닝 셋의 관리가 안됨
- 모델 훈련 방법이 기록이 안됨
- 모델 훈련에 많은 시간 소요
- 모델 훈련이 자동화가 안된 경우 매번 각 스텝들을 노트북 등에서 일일히 수행
- 에러가 발생할 여지가 많음(휴먼오류?)
ML Pipeline의 등장
- 앞서 언급한 문제들 중 2, 3번을 해결가능
- 자동화를 통해 에러 소지를 줄이고 반복을 바르게 가능하게 해줌
Spark MLib 관련 개념 정리
ML 파이프라인이란?
- 데이터 과학자가 머신러닝 개발과 테스트를 쉽게 해주는 기능
- 머신러닝 알고리즘에 관계없이 일관된 형태의 API를 사용해 모델링이 가능
- ML 모델개발과 테스트를 반복가능하게 해줌
4개의 요소로 구성
- 데이터프레임
- Transformer
- Estimator
- Parameter
데이터 프레임
- ML 파이프라인에서는 데이터프레임이 기본 데이터 포맷
- 기본적으로 CSV, JSON, Parquet, JDBC(관계형 데이터베이스)를 지원
- ML 파이프라인에서 다음 2가지의 새로운 데이터소스를 지원
- 이미지 데이터 소스(jpeg, png 등의 이미지들을 지정된 디렉토리에서 로드)
- LIBSVM 데이터소스(label과 features 두 개의 컬럼으로 구성되는 멋니러닝 트레이닝셋 포맷)
Transformer
- 입력 데이터프레임을 다른 데이터프레임으로 변환
- 하나 이상의 새로운 컬럼을 추가 - 2 종류의 Transformer가 존재하며 transform이 메인 함수
- Feature Transformer와 Learning Model - Feature Transformer
- 입력 데이터프레임의 컬럼으로부터 새로운 컬럼을 만들어내 이를 추가한 새로운 데이터프레임을 출력으로 내줌. 보통 피쳐 엔지니어링을 하는데 사용
- Imputer, StringIndexer, VectorAssembler등 - Learning Model
- 머신러닝 모델에 해당
- 피쳐 데이터프레임을 입력으로 받아 예측값이 새로운 컬럼으로 포함된 데이터 프레임을 출력으로 내줌: prediction, probability
Estimator
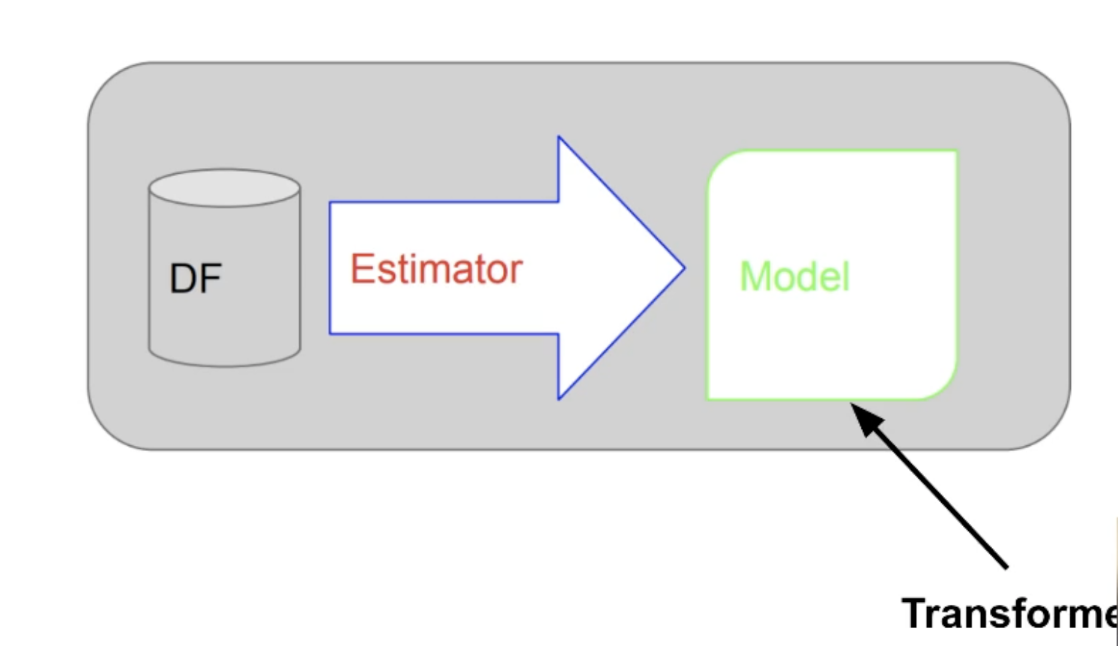
- 머신러닝 알고리즘에 해당 fit이 메인함수
- 트레이닝셋 데이터프레임을 입력으로 받아서 머신러닝 모델을 만들어냄
- 예를 들어 LogisticRegression은 Estimator이고 LogisticRegression.fit()을 호출하면 머신 러닝 모델(Transformer)을 만들어냄 - ML Pipeline도 Estimator
- Estimator는 저장과 읽기 함수 제공
- 즉 모델과 ML Pipeline을 저장했다가 나중에 다시 읽을 수 있음
Parameter
- Transformer와 Estimator의 공통 API로 다양한 인자를 적용해줌
- 두 종류의 파라미터 존재
- Param(하나의 이름과 값)
- ParamMap(Param리스트) - 파라미터 예
- 훈련 반복수 지정을 위해 setMaxIter() 사용
- ParamMap(lr.maxIter -> 10) - 파라미터는 fit(Estimator)혹은 transform(Transformer)에 인자로 지정 가능

컴퓨터가 좋아