스파크 설치
- pyspark,py4j를 설치해줌
- 설치 후 로컬스토리지 확인하면 샘플데이터가 설치됨
- 기본적으로 깔리는 csv 들이 있음
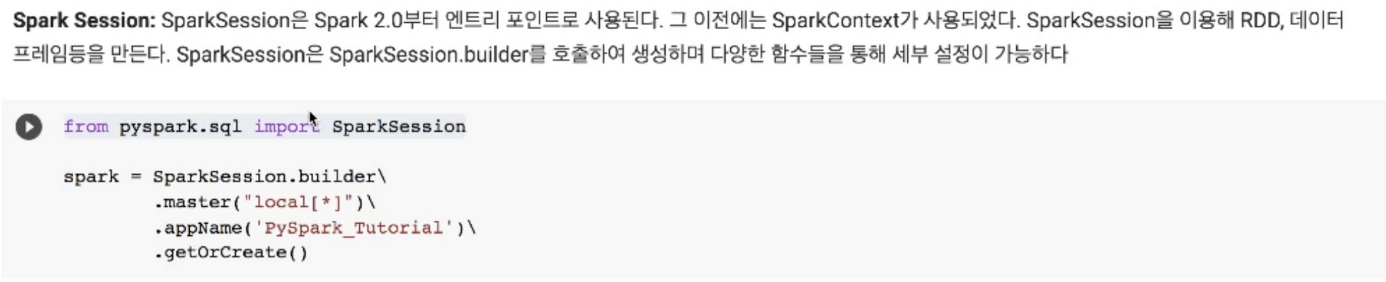
- 마스터에 local[*]은 코어를 얼마나 사용할지 설정
- * 표시를 두면 전부를 사용하는 것, 숫자를 지정하면 숫자만큼의 코어를 사용하겠다는 설정
- 앱네임을 지정해주고 이미 존재하면 가져오거나 없으면 생성
- 설정한 값으로 세션이 열림
Python 객체를 RDD로 변환해보기
python 리스트 생성
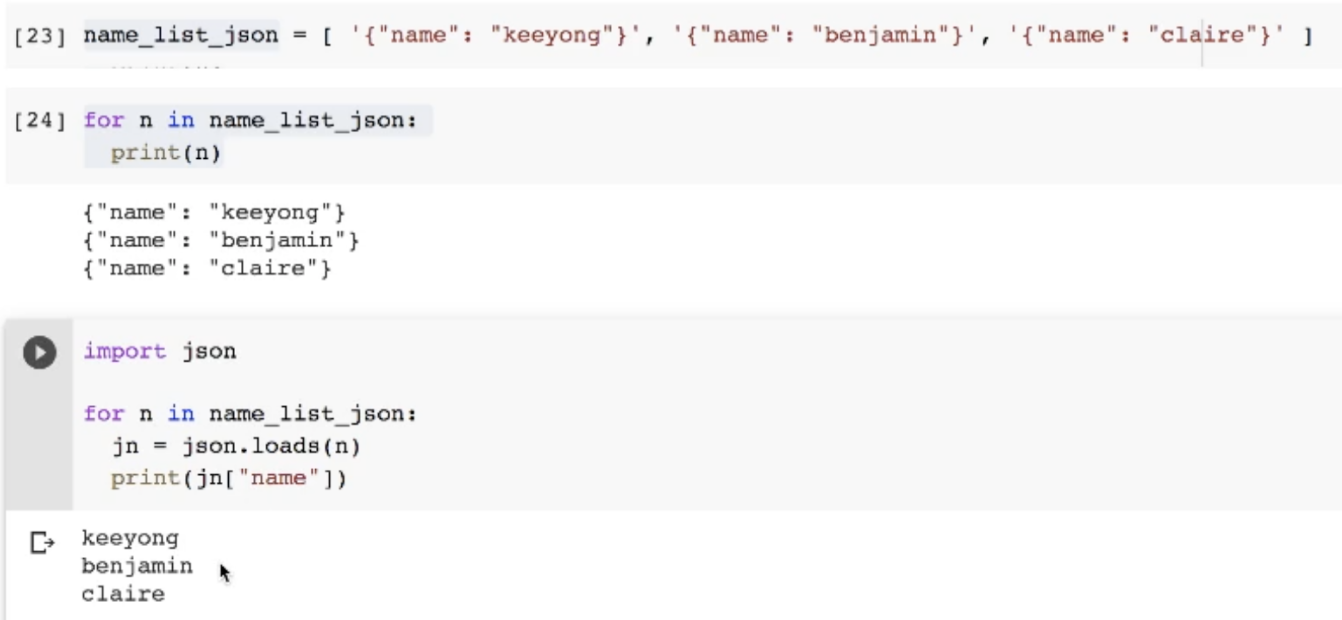
- 오브젝트와 비슷한 스트링을 가진 리스트를 만들어줌(사실상 제이슨)
- 리스트들을 for 문을 통해 출력해보면 제이슨 형태로 나옴
- json 모듈을 사용해 리스트 안에 각 값을 제이슨화시키고
- 키가 name인 값을 가져오면 밸류만 출력해줌
파이썬 리스트 to RDD
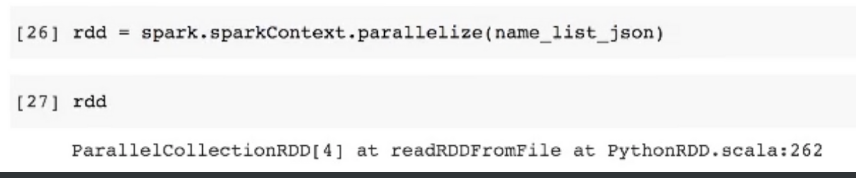
- spark에서 제공하는 parallelize 메소드로 리스트를 패럴화 시킴
- 하지만 이 상태에선 아직 패럴되지 않고
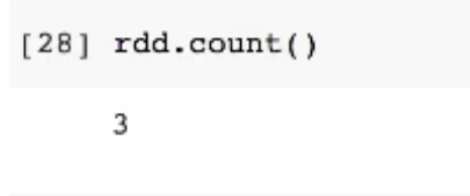
- count 같은 직접적인 메소드가 실행될때 패럴라이즈가 진이뤄짐
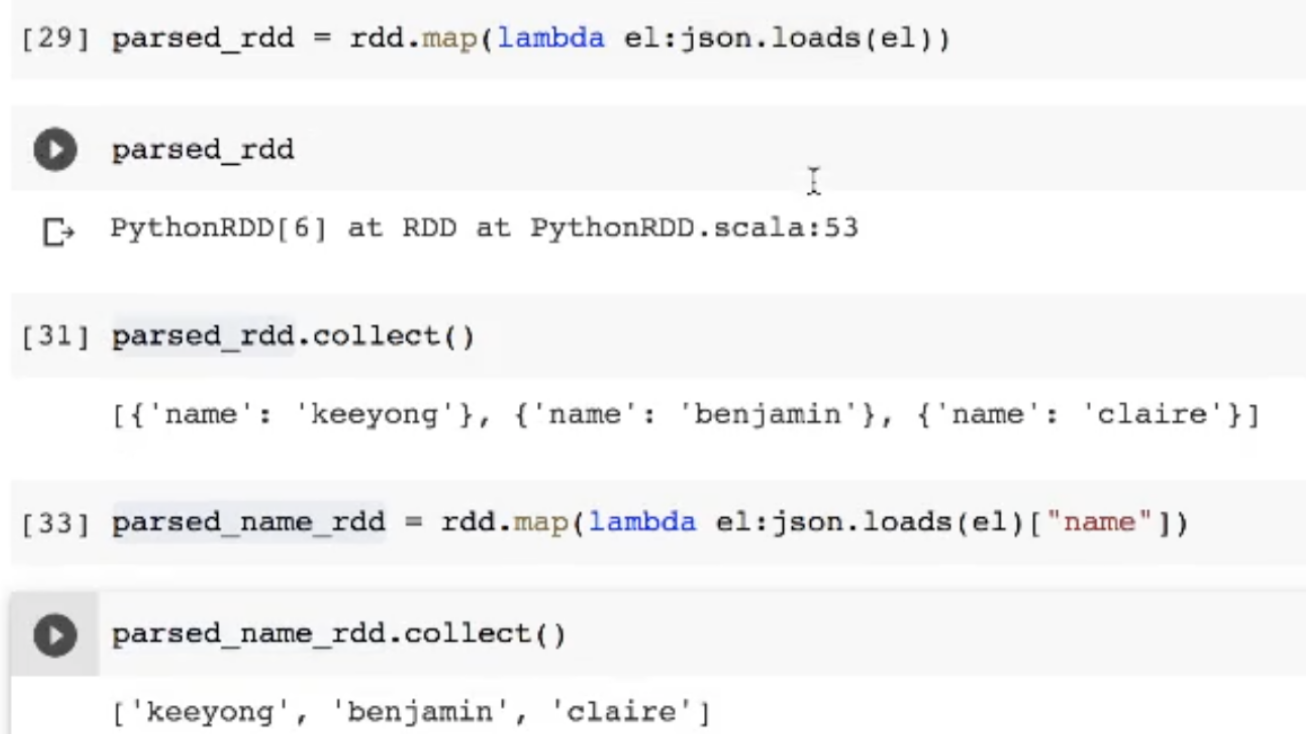
- 패럴된 rdd에 map을 사용해서 각 값을 제이슨화시켜주는 람다함수 사용
- map을 해줬다고 당장 뭐가 진행되지 않음
- collect를 진행하면 그때 패럴된 데이터들을 가져옴
- 비슷한 방식으로 각 값중 키값이 name인 값을 가져와줌
파이썬 리스트를 데이터 프레임으로 변환하기
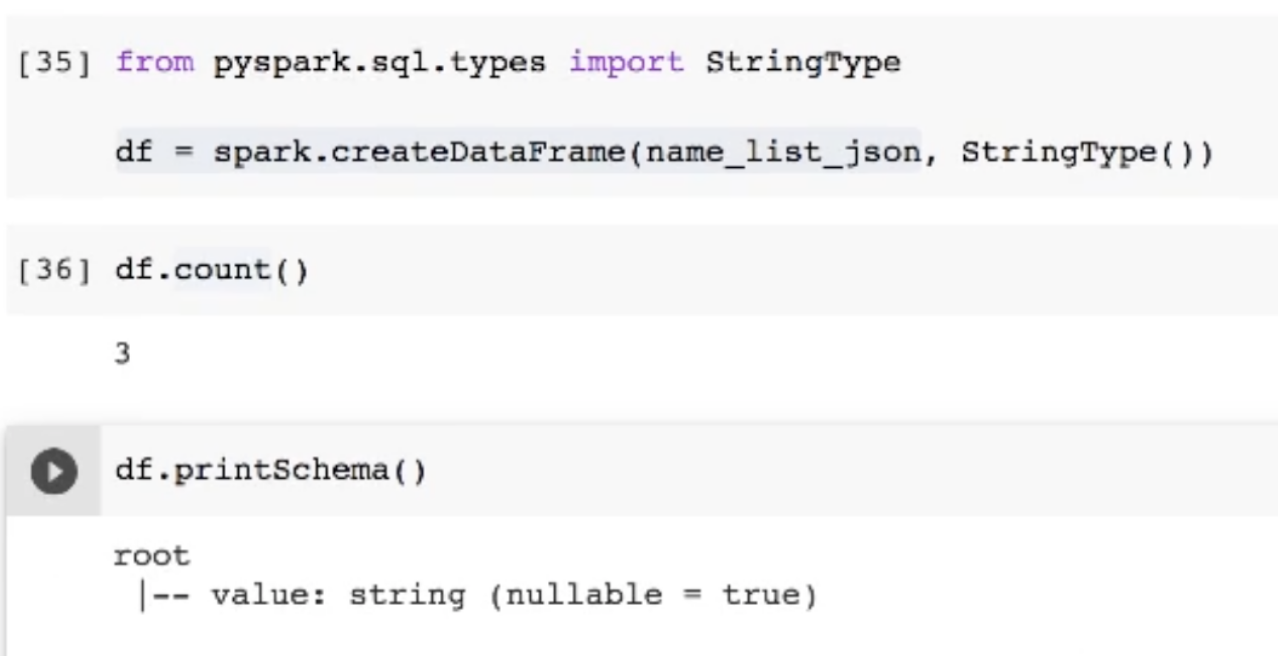
- createDataFrame 메소드를 사용해 첫번째 인자에 리스트를, 두번째 인자로 첫번째 인자를 어떤 타입으로 할지 옵션을 넣어줄 수 있음
- df 스키마를 보면 string 타입으로 설정됨

- df.select 에 * 을 사용하면 전체를 가져와준다는 의미
- 안에 값을 넣어주면 그 컬럼을 가져온다는 것
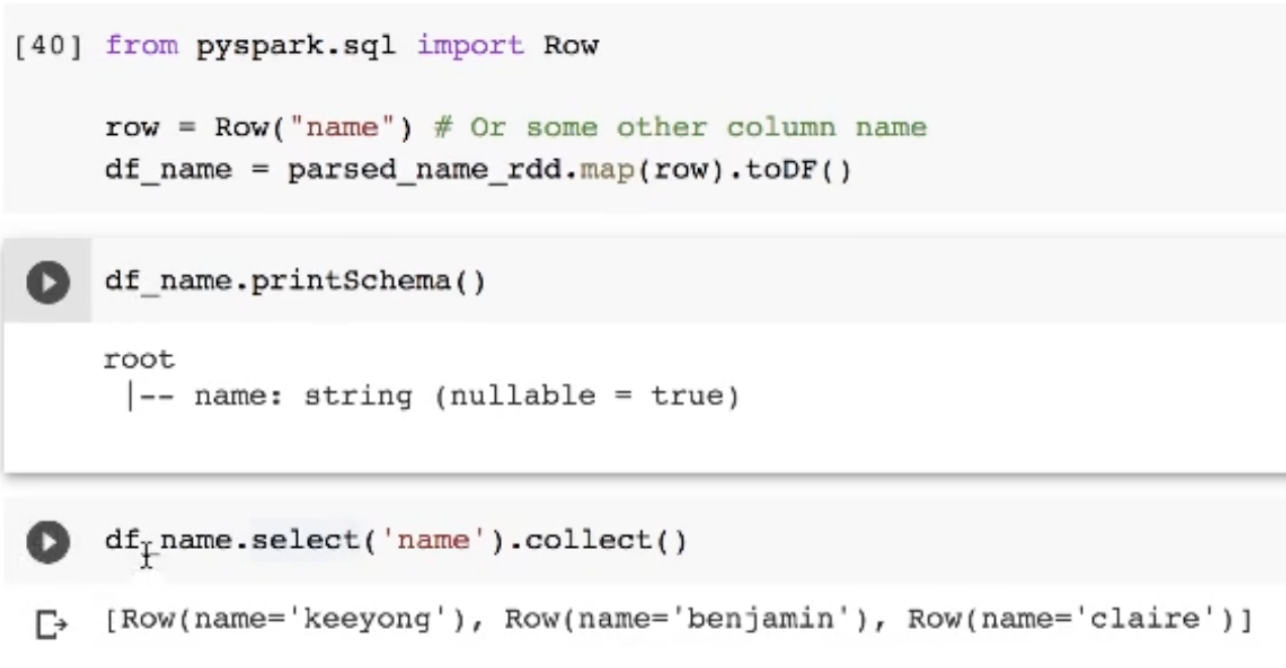
- 컬럼에 이름이 없기에 value라고 돼있음
- Row를 통해 컬럼 이름을 정해주고
- map을 통해 각 로우에 컬럼이름을 부여할 수 있음

컴퓨터가 좋아