SQL
1.[SQL] 관계형 데이터베이스
구조화된 데이터를 저장하고 질의할 수 있도록 해주는 스토리지엑셀 스프레드시트 형태의 데이블로 데이터를 정의하고 저장데이블에는 컬럼과 레코드의 존재관계형 데이터베이스를 조작하는 프로그래밍 언어테이블 정의를 위한 DDL(Data Definition Language)테이블
2.[SQL] 관계형 데이터베이스- 구조
박스가 데이터베이스, 그 아래가 테이블들데이터베이스는 폴더, 테이블은 엑셀파일로 보면 됨위쪽 스키마 양식대로 아래 테이블이 작성됨행은 레코드필드(컬럼)는 이름과 타입과 속성(primary key)으로 구성됨
3.[SQL] SQL

관계형 데이터베이스에 있는 데이터(테이블)를 질의하거나 조작해주는 언어SQL은 1970년대 초반에 IBM이 개발한 구조화된 데이터 질의 언어두 종류의 언어로 구성됨테이블의 구조를 정의하는 언어테이블에서 원하는 레코드들을 읽어오는 질의 언어테이블에 레코드를 추가/삭세/갱
4.[SQL] schema
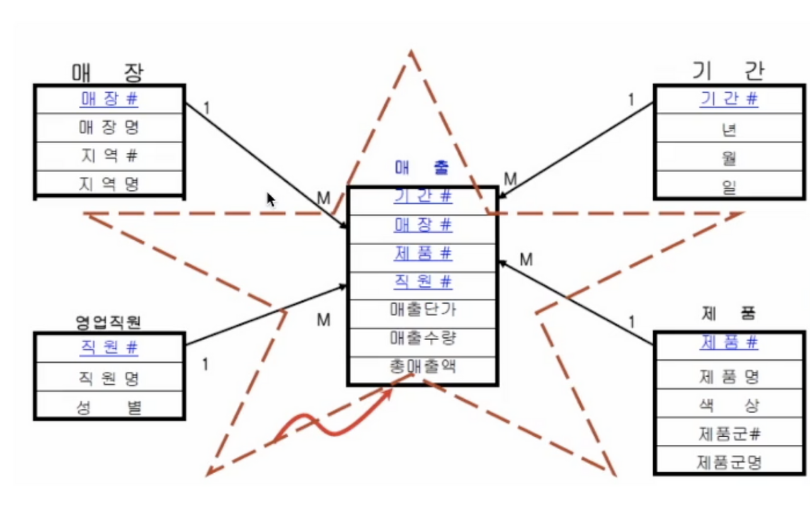
Production DB용 관계형 데이터베이스에서는 보통 스타 스키마를 사용해 데이터를 저장데이터를 논리적 단위로 나눠 저장하고 필요시 조인스토리지의 낭비가 덜하고 업데이터가 쉬움데이터 웨어하우스에서 사용하는 방식테이블에 모든 정보가 담기도록 한번에 열이 구성됨스토리지
5.[SQL] 데이터 웨어하우스
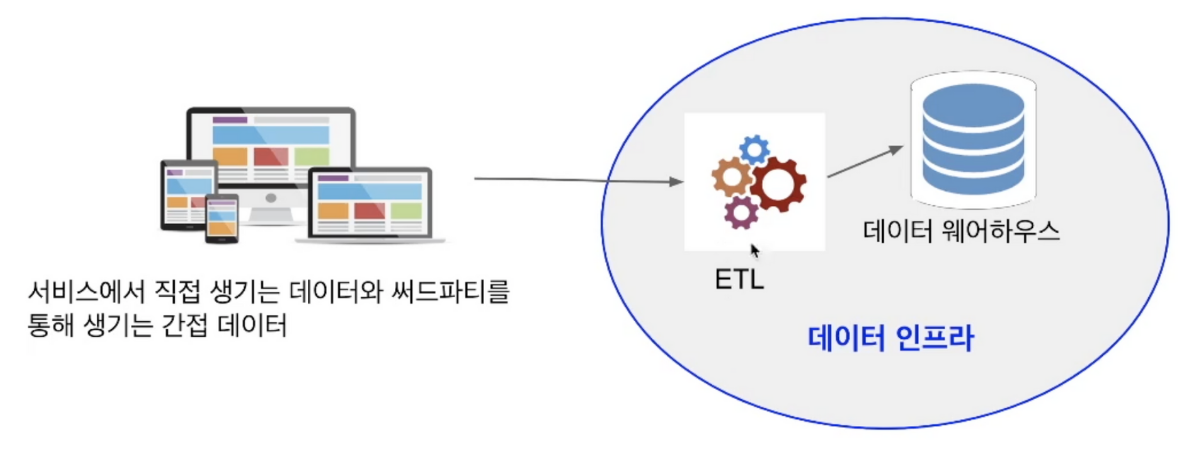
회사에 필요한 모든 데이터를 저장프로덕션 데이터베이스와는 별도여야 함데이터 웨어하우스는 고객이 아닌 내부 직원을 위한 데이터베이스 \- 처리속도가 아닌 처리 데이터 크기가 더 중요함ETL 혹은 데이터 파이프라인외부에 존재하는 데이터를 읽어다가 데이터 웨어하우스로 저장
6.[SQL] 예제 데이터베이스 정보
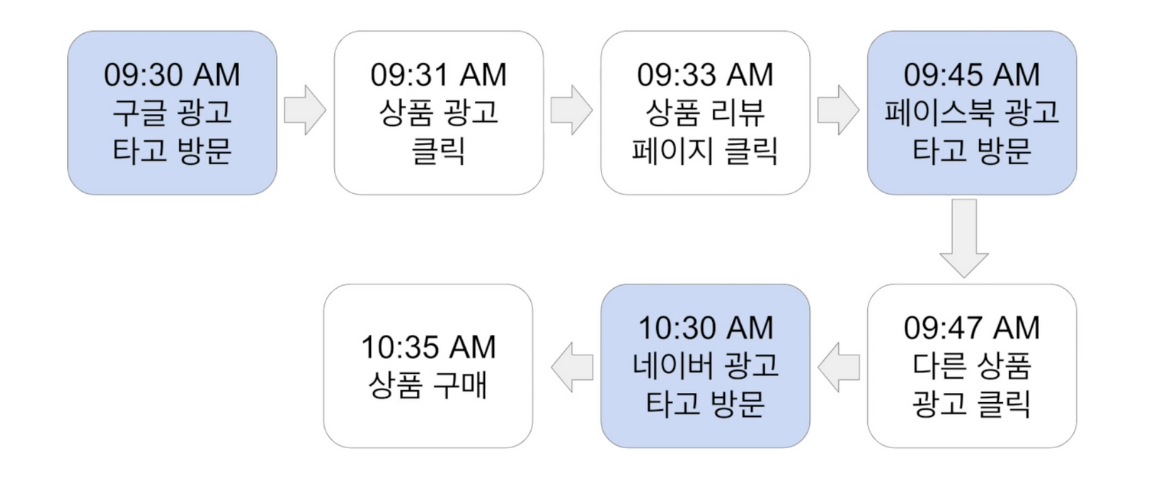
보통웹서비스에서 등록된 사용자마다 부여하는 유일한ID세션마다 부여되는 ID사용자의 방문을 논리적인 단위로 나눈 것 \- 사용자가 외부 링크(보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성 \- 사용자가 방문 후 30분간 interaction이 없다가
7.[SQL] SQL 기본 문법
다수의 SQL문을 실행하다면 세미콜론으로 분리 필요 \- SQL문1; SQL문2; SQL문3;"--": 인라인 한줄짜리 주석"/--/: 여러 줄에 걸쳐 사용 가능한 주석키워드의 대문자 사용, 테이블, 필드 이름 정하기 등 팀 프로젝트라면 팀에서 사용하는 규칙을 만들고
8.[SQL] SELECT, CASE WHEN, NULL, COUNT, STRING, 판다스 연동

SELECT
9.[SQL] GROUP BY, AGGREGATE
테이블의 레코드를 그룹핑하여 그룹별로 다양한 정보를 계산그룹핑을 할 필드를 결정(하나 이상의 필드가 될 수 있음)GROUP BY로 지정(필드 이름을 사용하거나 필드 일련번호를 사용)Aggregate함수를 사용Aggregate란 COUNT, SUM, AVG, MIN, M
10.[SQL] CTAS, CTE
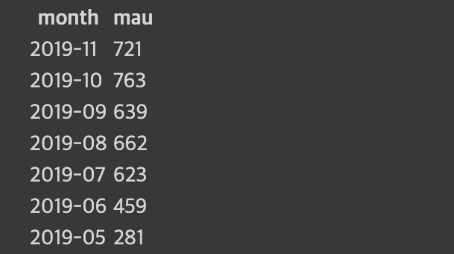
SELECT를 가지고 테이블 생성자주 조인하는 테이블들이 있다면 이를 CTAS를 사용해서 조인해두면 편리해짐중복된 레코드들 체크하기최근 데이터의 존재 여부 체크하기(freshness)Primary key uniqueness가 지켜지는지 체크하기값이 비어있는 컬럼들이 있
11.[SQL] 숙제하기1

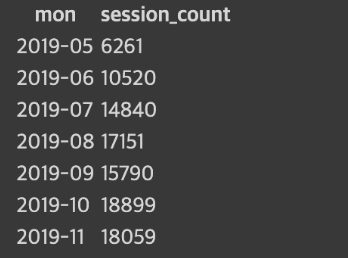
트랜잭션과 채널 테이블이 추가됨4가지 테이블을 가지고 과제 수행session_timestamp, user_session_channel, session_transaction 테이블 사용아래와 같은 필드로 구성\- month\- channel\- uniqueUsers(총방
12.[SQL] 다양한 JOIN
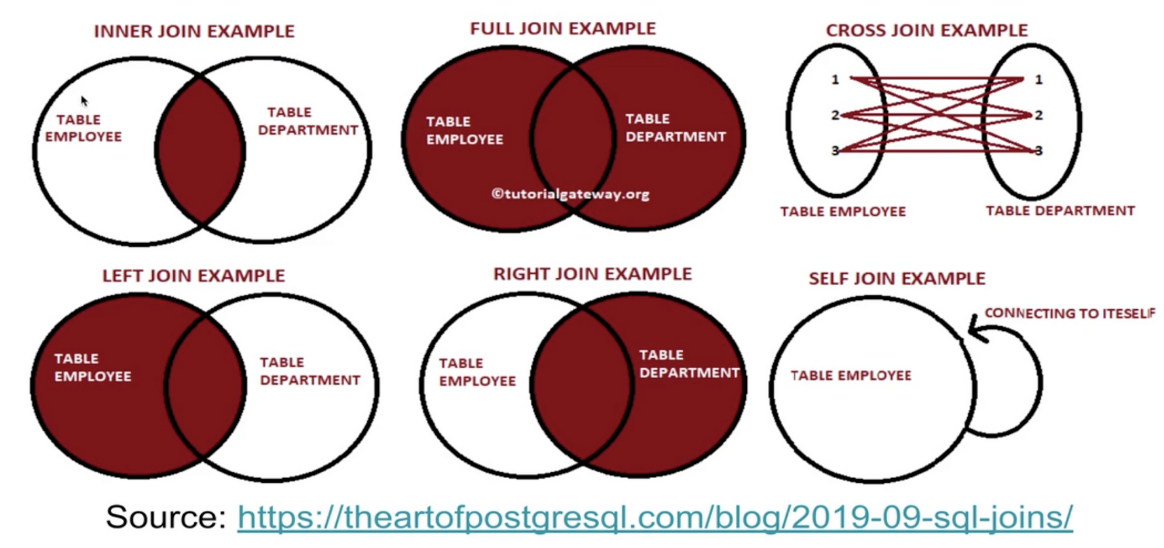
SQL 조인은 두 개 혹은 그 이상의 테이블들을 공통 필드를 가지고 머지하는데 사용된다. 이는 스타 스키마로 구성된 테이블들로 분산되어 있던 정보를 통합하는데 사용된다.왼쪽테이블의 결과는 전부 표시하고 다른쪽 데이터들중 왼쪽데이터와 연관된 것들만 가져옴오른쪽테이블의 결
13.[SQL] BOOLEAN 타입 정리, NULL 의 BOOLEAN 연산

flag 컬럼에 정보가 담긴 테이블flag = True, flag is True는 동일표현flag is True, flag is not False 는?트루 2개 인건 동일False가 아닌것에 NULL값도 포함되서 가운트됨NULL 비교는 항상 IS 혹은 IS NOT으로
14.[SQL] 숙제2
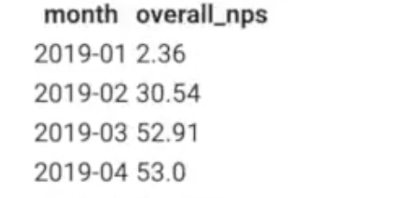
유저 세션 채널과 타임스탬프를 세션아이디를 매개로 엮음userid가 251인 것만 가져옴타임스탬프를 기준으로 시간정렬을 하면 채널 컬럼의 처음과 마지막이 사용자별 처음과 마지막 채널이 됨WITH을 통해서 테이블을 조인하는 조합으로 하는 first, last 테이블을 만
15.[SQL] Transaction, DELETE FROM vs TRUNCATE
Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법DDL, DML 중 레코드를 수정/추가/삭제한 것에만 의미가 있음BEGIN과 END 혹은 BEGIN과 COMMIT 사이에 해당 SQL들을 사용ROLLBACK계좌 이체: 인출과 입금의 두 과정
16.[SQL] UNION, EXCEPT, INTERSECT (집합 명령)

여러개의 테이블들이나 SELECT 결과를 하나의 결과로 합쳐줌UNION VS UNION ALL\- UNION은 중복을 제거테이블을 만들고 컬럼도 만들어주고UNION으로 밸류를 합쳐주면중복된 값은 제외된 상태로 합쳐짐UNION ALL은 중복된 정보도 상관없이 밸류를 쌓음
17.[SQL] LISTAGG

GROUP BY에서 사용되는 Aggregate 함수 중의 하나사용자 ID별로 채널을 순서대로 리스트유저세션채널과 타임스탬프 테이블을 묶어주고userid를 받고 ts를 기준으로 정렬한 channel들을 아이디를 그룹핑해 그 안에 한줄로 표현LISTAGG 두번째 인자는 나
18.[SQL] WINDOW, LAG
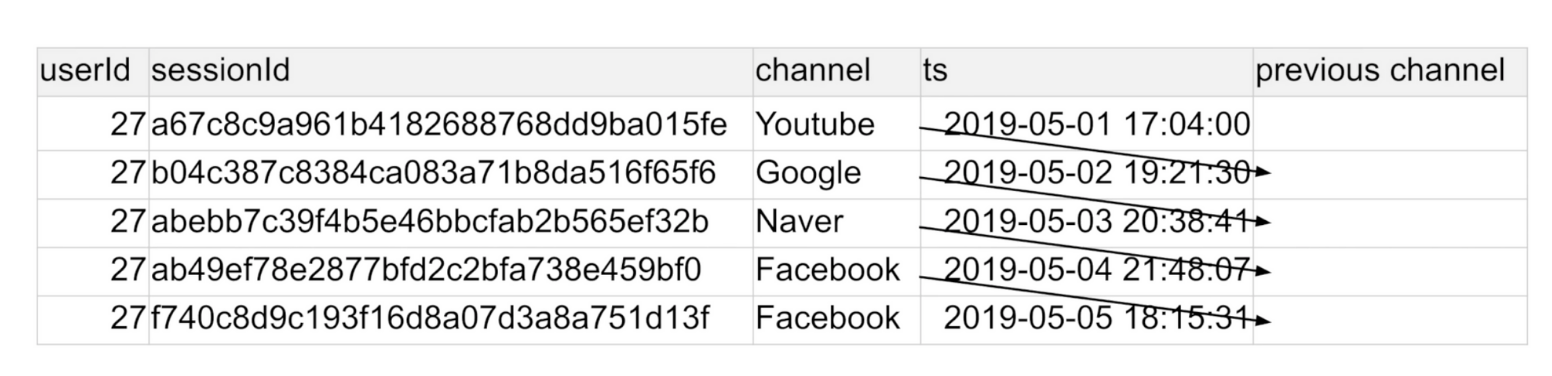
어떤 사용자 세션에서 시간순으로 봤을 때\- 앞 세션의 채널이 무엇인지 알고 싶다면?\- 혹은 다음 세션의 채널이 무엇인지 알고 싶다면?LAG의 두번째 인자 숫자는 몇번째 전 데이터를 읽어 올까 하는 설정previous channel에 유저아이디, 시간순으로 정렬된 c
19.[SQL] JSON Parsing Functions

JSON의 포맷을 이미 아는 상황에서만 사용가능한 함수JSON_EXTRACT_PATH_TEXT 함수의 첫번째 인자는 JSON정보, 두번째 인자부터는 뎁스를 하나씩 들어가는 방식f4의 f6정보를 가져오니까 "star"를 리턴함f4 까지만 가져오니까위 제이슨정보를 리턴함