5. 참조 타입

5.1 데이터 타입 분류
자바의 데이터 타입에는 크게 두가지가 존재한다.
-
기본 타입(primitive)기본 타입은 여태까지 보아왔던 (정수, 실수, 문자, 논리 리터럴)을 저장한다. -
참조 타입(referecne)참조 타입은 객체의 번지를 참조하는 타입으로배열,열거,클래스,인터페이스타입을 말한다.
기본 타입과 참조 타입은 변수가 어떤 값을 저장하느냐? 에서 차이가 있다.
기본 타입은 실제 값을 변수에 저장하지만,
참조 타입은 메모리의 번지를 값으로 갖는다.

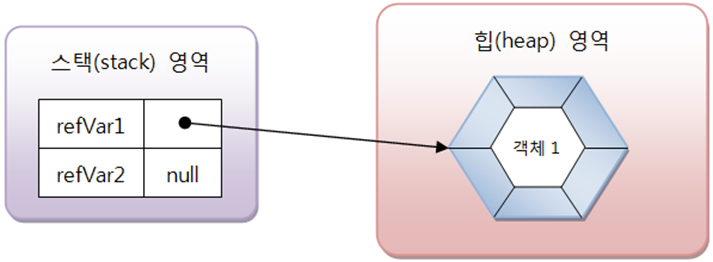
age와 price는 기본 타입이므로 직접 값을 저장하지만, String 클래스 변수인 name, hobby는 힙 영역의 객체 주소값을 가르키고 있다.
여기서 String 클래스 변수를 참조 타입 변수라고 한다.
5.2 메모리 사용 영역

시작하기전, JVM은 OS에서 할당 받은 메모리를 세 영역으로 구분한다.
메소드 영역(Method Area), 힙 영역(Heap Area), JVM 스택 영역 (Stack Area)
5.2.1 메소드(Method) 영역
- 메소드 영역에는 코드에서 사용되는 클래스(~.class)를 클래스 로더로 읽는다.
- 클래스별로 데이터, 코드 등을 분류해서 정리하는데 아래와 같다.
- 런타임 상수풀, 필드(field) 데이터, 메소드 (method) 데이터, 메소드 커드, 생성자(constructor)
- 메소드 영역은 JVM이 시작할 때 생성되고 모든 스레드가 공유하는 영역이다.
Q. 메소드 영역을 모든 스레드가 공유한다는 것이 어떤 의미를 가질까?
5.2.2 힙(Heap) 영역
- 힙 영역은 객체와 배열이 생성된다.
- 객체와 배열은 JVM 스택 영역의 변수나 다른 객체의 필드에서 참조한다.
- 참조하는 변수나 필드가 없다면 JVM은 가비지 컬렉터를 실행시켜 쓰레기 객체를 제거한다.
- 자바는 코드로 객체를 직접 제거시키는 방법을 제공하지 않는다

5.2.3 JVM 스택(Stack) 영역
- JVM 스택 영역은 각 스레드마다 하나씩 존재하며 스레드가 시작될 때 할당된다. (따로 추가해주지 않을시 main 1개)
- JVM 스택은 메소드를 호출할 때 마다 프레임(Frame)을 추가(Push)하고 메소드가 종료되면 프레임을 제거(Pop)한다.
- 예외 발생시 나오는 printStackTrace() 메소드로 보여주는 Stack Trace의 각 라인은 하나의 프레임을 표현한다.
- 프레임 내부에는 로컬 변수 스택이 있고, 기본 타입 변수와 참조 타입 변수가 추가(push) 되거나 제거(pop) 된다.
- 변수가 생성되는 시점은 초기화 될때, 즉 값이 저장될 때 이다.
- 변수는 선언된 블록(Scope)안에서만 존재하고 블록을 벗어나면 스택에서 제거된다.
(다시한번) 기본타입 변수는 값을 저장하는 스택 영역에 있지만, 참조 변수는 값이 아니라 힙/메소드 영역의 객체 주소를 가진다.
5.3 참조 변수의 ==, != 연산
3장 에서 언급하였듯이, 참조 타입 변수끼리 비교를 한다는 것은 주소값을 비교하는 것이다.
따라서 동일 객체를 참조하고 있을 경우에는 true, 아니라면 false를 반환한다.
5.4 null과 NullPointerException
- 참조 타입 변수는 힙 영역의 객체를 참조하지 않는다는 뜻으로 null(널) 값을 가질 수 있다.
- null 값도 초기값으로 사용할 수 있기 때문에 null로 초기화된 참조 변수는 스택 영역에 생성된다.
- 참조 타입 변수가 null 값을 가지는지 확인 하려면
==,!=연산을 사용하면 된다.

- NullPointerException은 참조 타입 변수를 잘못 사용되면 발생된다.
- 아래와 같이 적절히 초기화 되지 않은 VO, DTO가 NPE를 뿜곤 했었다.

str변수가 참조하는 String 객체가 없기에 NPE가 발생한다. (== null.length())
5.5 String 타입
- 사실 문자열을 String 변수에 저장한다는 말을 틀린 표현이다.
- 문자열은 String
객체로 생성되고, 변수는 String 객체를참조한다. - 변수는 스택 영역에 생성되고, 객체는 힙 영역에 String 객체로 생성된다.
- 또한, 자바는 문자열 리터럴이 동일하다면(문자열이 같다면) String 객체를 공유하도록 되어있다.
- 단, new 연산자를 사용해 직접 String 객체를 생성시킬 수 있다. 이때, 앞선 예시와 다르게 문자열 리터럴이 같아도 같은 곳을 참조하지 않는다.
- 즉 아래와 같은 예시에서
==연산을 한다면 주소값을 비교하기에s1==s2는true이고,s1==s3는false이다.
String s1 = "우이천";
String s2 = "우이천";
String s3 = new String("우이천");5.6 배열 타입
5.6.1 배열이란?
변수를 1억개 저장해야 한다면 1억개의 변수를 생성해야 할까? 아니다.
같은 타입의 많은 양의 데이터를 다루는 프로그램에서는 좀 더 효율적인 방법을 고안했는데 이것이 배열이다.
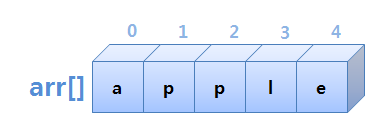
배열은 같은 타입의 데이터를 연속된 공간에 나열시키고, 각 데이터에 인덱스(index)를 부여해 놓은 자료구조이다.
즉, "N번째에 X값을 저장해놓겠어요"하는 것이다.
변수를 1억개 생성하는 것 뿐만 아니라 1억번 다룬다고 할때에도 유용하다.(반복문)
단, 배열은 같은 타입의 데이터만 저장할 수 있다.
만약 다른 타입 값을 저장하려 하면 타입 불일치 컴파일 오류가 발생한다.
또한, 한번 생성된 배열을 늘리거나, 줄일 수 없다.
5.6.2 배열 선언
배열 선언하는 방법은 아래와 같이 두가지 방법이 있다.
1. 타입[] 변수;
2. 타입 변수[];강사분께서 따로 설명이 없으신데 JAVA에선 둘다 사용이 되는 갑다.
(굳이 왜)그렇지만 대부분 1을 선호하시는 것 같고, 2는 C/C++에서 자주 봤다.
배열 변수는 참조 변수에 속한다. 배열도 객체이므로 힙에 생성된다.
만약 배열 변수가 null 값을 가진 상태에서 변수[인덱스]로 값을 접근하거나 저장하게 되면 NPE가 발생한다.
5.6.3 값 목록으로 배열 생성

이렇게 생성된 배열에서 1번째 값을 바꾸고 싶다면 아래와 같이 바꿀 수 있다.
String[] var={"우", "이", "천"};
var[1] = "우이천";위의처럼 값의 목록으로 배열 객체를 생성할 때 주의할 점이 있는데, 이미 선언한 후에 다른 실행문에서 중괄호를 사용한 배열 생성은 허용되지 않는다.
메소드의 매개값이 배열일 경우에도 마찬가지다.
아래와 같이 값 목록을 생성함과 동시에 new 연산자를 사용해야 한다.
/* method */
int add(int[] scores) {...}
int result1 = add({1,2,3}); //error
int result2 = add(new int[]{1,2,3});5.6.4 new 연산자로 배열 생성
값의 목록이 없지만, 향후 값들을 저장할 배열을 미리 만들고 싶다면 new 연산자로 배열 객체를 생성할 수 있다.
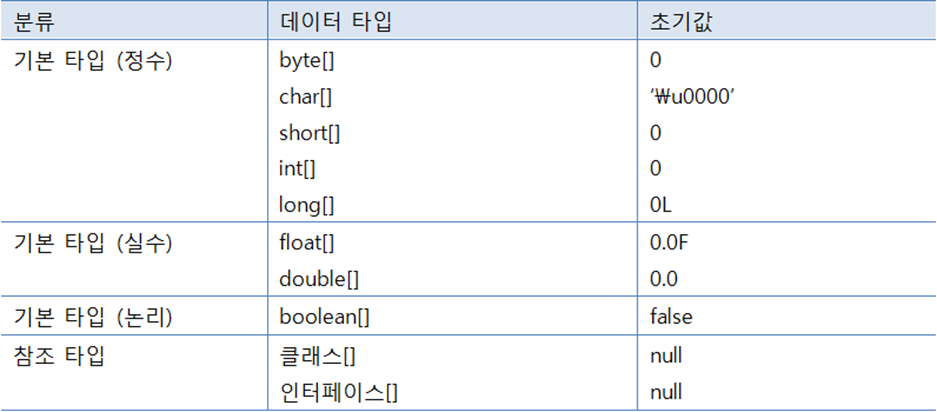
new 연산자로 배열을 처음 생성할 경우, 배열은 자동적으로 기본값으로 초기화 된다.

5.6.5 배열 길이
(세줄요약)
- 배열 변수엔
필드변수length가 있어.으로 접근하면 된다. - 필드변수이므로 값 변경이 불가능하다.
반복문(for)돌릴 때 유용하다.
배열변수.length;
배열변수.length = 10 //error5.6.6 커맨드 라인 입력
psvm
main 메소드의 매개값 String[] args가 왜 필요한지 이제 이해 할 수 있다.
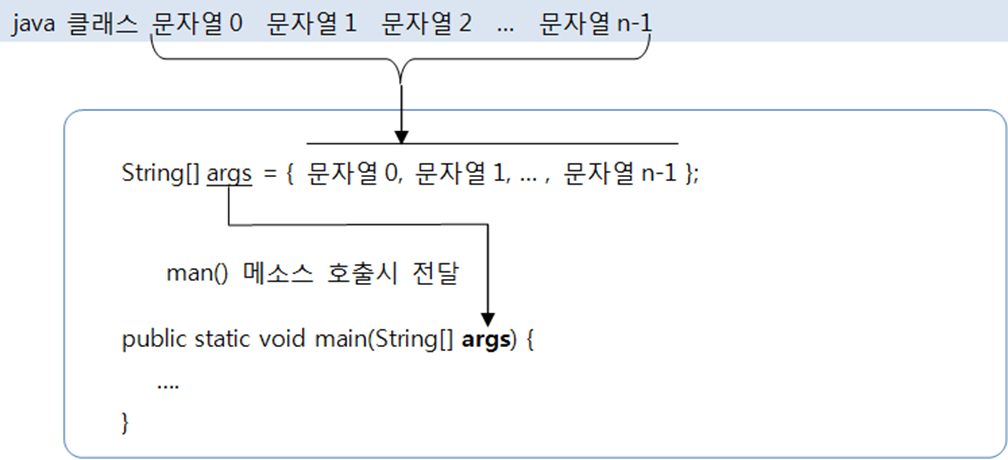
즉, java *.class 문자열0 문자열1 ... 을 한다면 문자열 n개를 main 메소드의 매개변수로 전달한다는 것이다.
5.6.7 다차원 배열
1차원 배열은 1행 N열로 이루어져 있다.
2차원 배열은 N'행 M열로 이루어져 있다.
ex) 2행 3열 배열
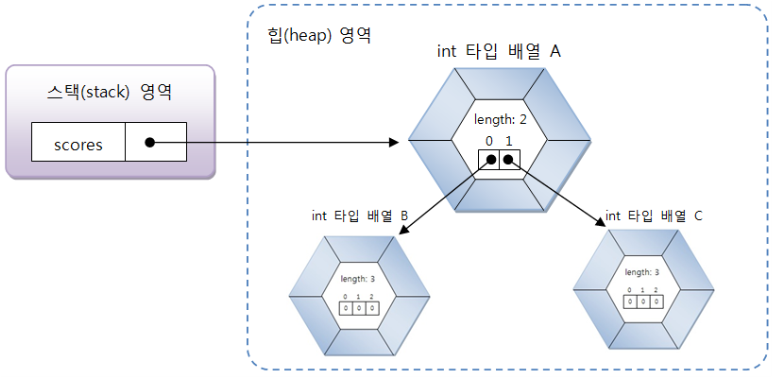
int[][] scores = new int[2][3]
C/C++를 사용하다보면, 먼저 2차원 배열을 동적으로 만드는 순서는 아래와 같다.
1. 1차원 배열 포인터를 잡는 2차원 포인터 (void** ptr)를 할당한다.
2. 그 이후 반복문을 통하여 1차원 배열들을 할당한다.
3. 2차원 포인터가 1차원 포인터들의 첫번째 주소값을 할당한다.
(매우 귀찮다. 코드 라인도 늘고 stl 쓴다.)
위 과정과 매우 비슷하다.
그러므로 score.lengh는 2(2행이므로), score[idx].length는 3(3열이므로) 가 될 것이다.
물론 각 행마다 열의 수를 다르게 일일이 설정해 줄 수도 있다.
- 주의점 : 배열의 길이를 정확히 알고 인덱스를 사용하지 않는다면,
ArrayIndexOutOfBoundsException을 내뿜는다.
또한 아래와 같이 배열을 선언할 수도 있다.
int[][] scores = {{95,80},{95, 96}};이렇게 선언하면, scores는 2행 2열을 갖는 2차원 배열이고, scores[idx]는 2열을 갖는 1차원 배열이 될 것이다.
5.6.8 객체를 참조하는 배열
기본 타입(byte, char, ...) 배열은 각 항목에 직접 값을 갖지만, 참조 타입(클래스, 인터페이스) 배열은 각 항목에 객체의 번지를 가지고 있다. 즉, 객체를 참조하게 된다.
String[] strArray = new String[3];
strArray[0] = "Java";
strArray[1] = "C++";
strArray[2] = "C#";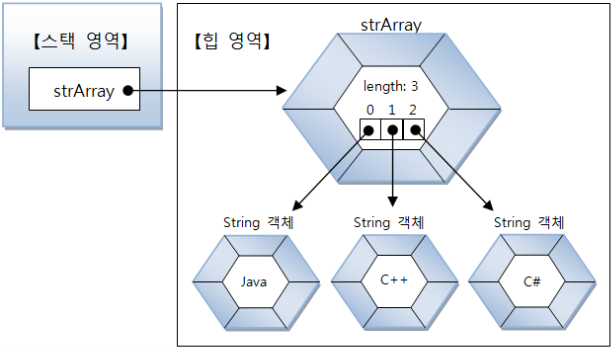
5.6.9 배열 복사
배열은 한 번 생성하면 크기를 변경할 수 없기 때문에 더 많은 저장공간이 필요하다면, 보다 큰 배열을 새로 만들고 이전 배열로부터 항목 값들을 복사해야 한다.
for문이나, System.arraycopy()를 사용하면 된다. (다른 좋은 API 많을 것 같아서 생략)
5.6.10 향상된 for문

기존 사용하던 for문
for(int i=0; i<scores.size(); i++){
sum+=scores[i]
}향상된 for문
for(int score : scores){
sum+=score;가독성도 좋아지는 것 같다. enhanced for문 짱이다 짱!
다만 인덱스 접근이 불가능 하므로, 순회에 사용하기 적절하다.
5.7 열거 타입
데이터 중 몇 가지로 한정된 값만을 갖는 경우가 흔히 있다. (private static final int)
ex) 요일(월, 화 수, ...), 계절(봄, 여름, .... )
이와 같이 한정된 값만을 갖는 데이터 타입이 열거 타입(enumeration type)이다.
열거 타입은 몇개의 열거 상수(enumeration constant) 중에서 하나의 상수를 저장하는 데이터 타입이다.
5.7.1 열거 타입 선언
관례적으로 열거 타입의 이름은 파스칼 케이스를 사용한다. (모든 자바 클래스들이 그럴껄요..?)
열거 상수들은 모두 대문자를 사용하고, 여러 단어가 사용된다면 _(밑줄)을 사용한다.

5.7.2 열거 타입 변수
Week 형식의 변수를 아래와 같이 선언하고, 또 할당할 수 있다.
Week today;
Week tmrw = Week.sunday;
Week ttmrw = null;열거 타입 변수는 null 값을 저장할 수 있는데, 열거 타입도 참조 타입이기 때문이다.
그렇다면 다음 실행 결과는 어떻게 될까?
Week today = Week.SUNDAY;
today == Week.SUNDAY //truetoday변수는 stack에 생성되고, 그리고 heap영역에 Week 객체들이 저장되기에 결과는 true가 된다.

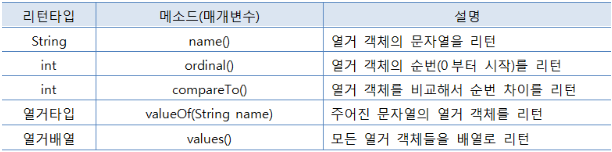
5.7.3 열거 객체의 메소드
열거 타입은 Enum 클래스를 상속받기에, 다음과 같은 메소드를 갖는다.