
🔔 학교 강의를 바탕으로 개인적인 공부를 위해 정리한 글입니다. 혹여나 틀린 부분이 있다면 지적해주시면 감사드리겠습니다.
Supplementary - Process Attributes
Process Attributes
The Process ID
#include <unistd.h>
pid_t getpid(void); /* returns PID of calling process */
pid_t getppid(void); /* returns PID of parent process */
uid_t getuid(void); /* returns real user ID of calling process */
uid_t geteuid(void); /* returns effective user ID of calling process */
gid_t getgid(void); /* returns real group ID of calling process */
gid_t getegid(void); /* returns effective group ID of calling process */위의 함수를 사용하여 PID, PPID, UID, EUID, GID, EGID를 얻을 수 있다.
Process ID 0 & 1
PID 0
- scheduler process용으로 어떤 program도 여기에 해당하지 않음
- kernel의 일부이며 system process라고도 함
PID 1
- init process용으로 부팅 절차가 끝날 때 kernel에 의해 call
- 절대 죽지 않으며 일반 사용자 process에 해당
Process Groups and Process Group ID
process도 하나의 group으로 관리되며, 동일한 작업과 관련된 하나 이상의 process 모음이다. process group은 고유한 process group ID를 가지고 있으며, 이는 process ID와 유사하다. 양의 정수로 이루어져 있으며, 각 process group에는 leader가 존재한다. 여기서 leader는 pid == pgid인 process를 의미한다.
System Call : getpgrp & getpgid
#include <unistd.h>
pid_t getpgrp(void);
pid_t getpgid(pid_t pid);
getpgrp
- 호출한 process의
pgid를 return- error 발생 시
return -1
getpgid
- 특정 pid에 대한
pgid를 return- error 발생 시
return -1
getpgrp() == getpgid(0)
System Call : setpgid
#include <unistd.h>
#include <sys/types.h>
int setpgid(pid_t pid, pid_t pgid);setpgid는 process group ID를 pgid로 설정합니다.
Arguments
pid
-pid == pgid: 새로운 group을 생성해pid를 leader로 설정
-pid == 0: 내 pgid를 변경
-pgid == 0: pid와 같은 값을 pgid로 사용 (즉 첫 번째와 동일한 역할)
process는 자신이나 자식의 pgid만 설정할 수 있으며, child process에서 exec을 call한 경우에는 변경이 불가능하다.
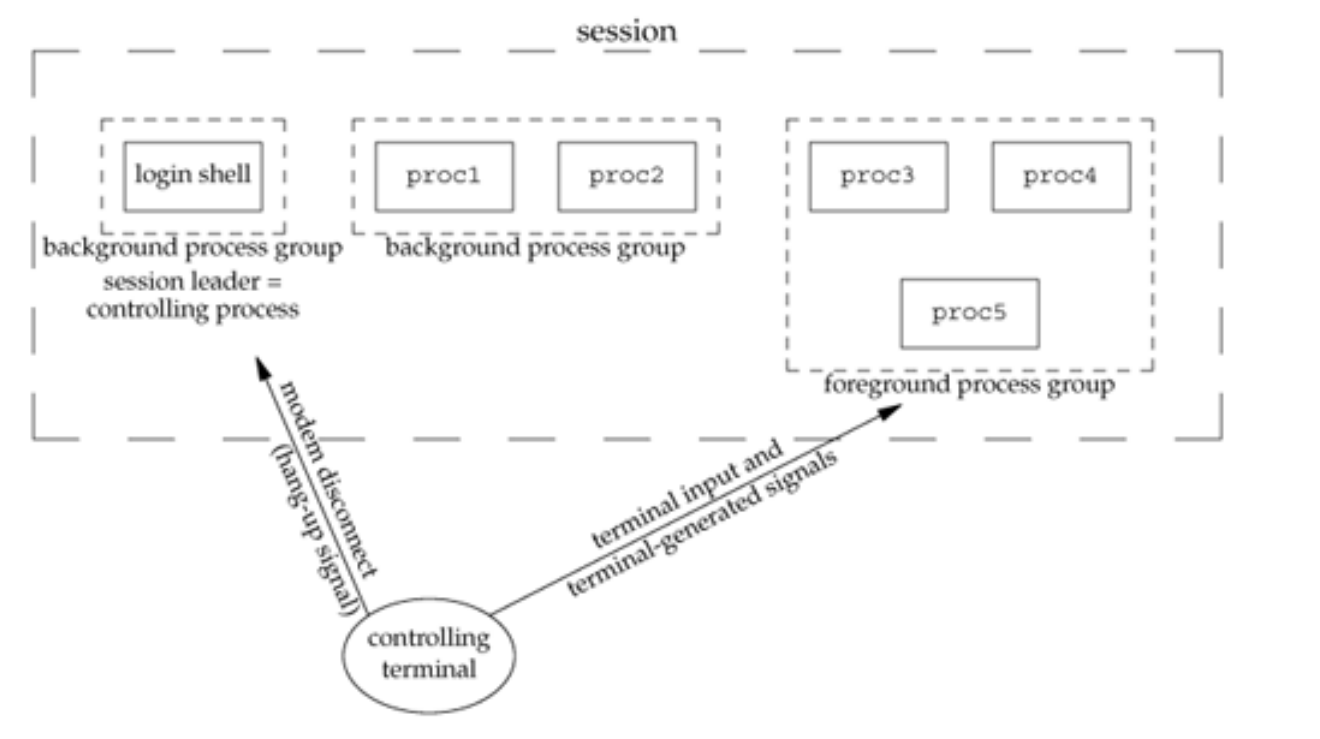
Sessions and Session ID
Session은 하나 이상의 process group의 모음으로 process의 controlling terminal과 관련되어있다. Session 내의 process group은 단일의 foreground process group과 하나 이상의 background process group으로 나눌 수 있으며, 이를 나타내면 아래와 같다.
System Call : getsid
#include <unistd.h>
pid_t getsid(pid_t pid);Return
- 성공 시
pid와 함께 process의Session leader pgid를 return- error 발생 시
return -1
System Call : setsid
#incude <unistd.h>
pid_t setsid(void);setsid는 session을 만들고 pgid를 설정한다. 호출한 process가 process group leader가 아닌 경우 새 session을 생성하며, process는 새로운 session의 leader이자 process group의 leader가 된다.
Return
- 성공 시 새 pgid를 return
- error 발생 시
return -1
Daemon process
- shell과 연결을 끊고 session을 만들어 독자적으로 돌아가는, 즉 controlling terminal이 없는 process를 의미하며,
cron이 대표적인 예이다.
The Current Working & Root Directory
Current working directory
- working directory는 process를 시작한
fork혹은exec에서 상속되며, process마다 존재한다.- 하위 process가
chdir로 위치를 변경하더라도 current working directory는 변경되지 않는다.
Current root directory
- file system의 시작 위치에 해당하며, 각 process는 절대 경로 팀색에 사용되는 root directory와 연결되어있다.
System Call : chroot
#include <unistd.h>
int chroot(const char *path);chroot는 현재 root directory를 전달받은 경로로 변경한다. 즉 root도 process마다 다르게 가져갈 수 있다.
Return
- 성공 시
return 0- error 발생 시
return -1
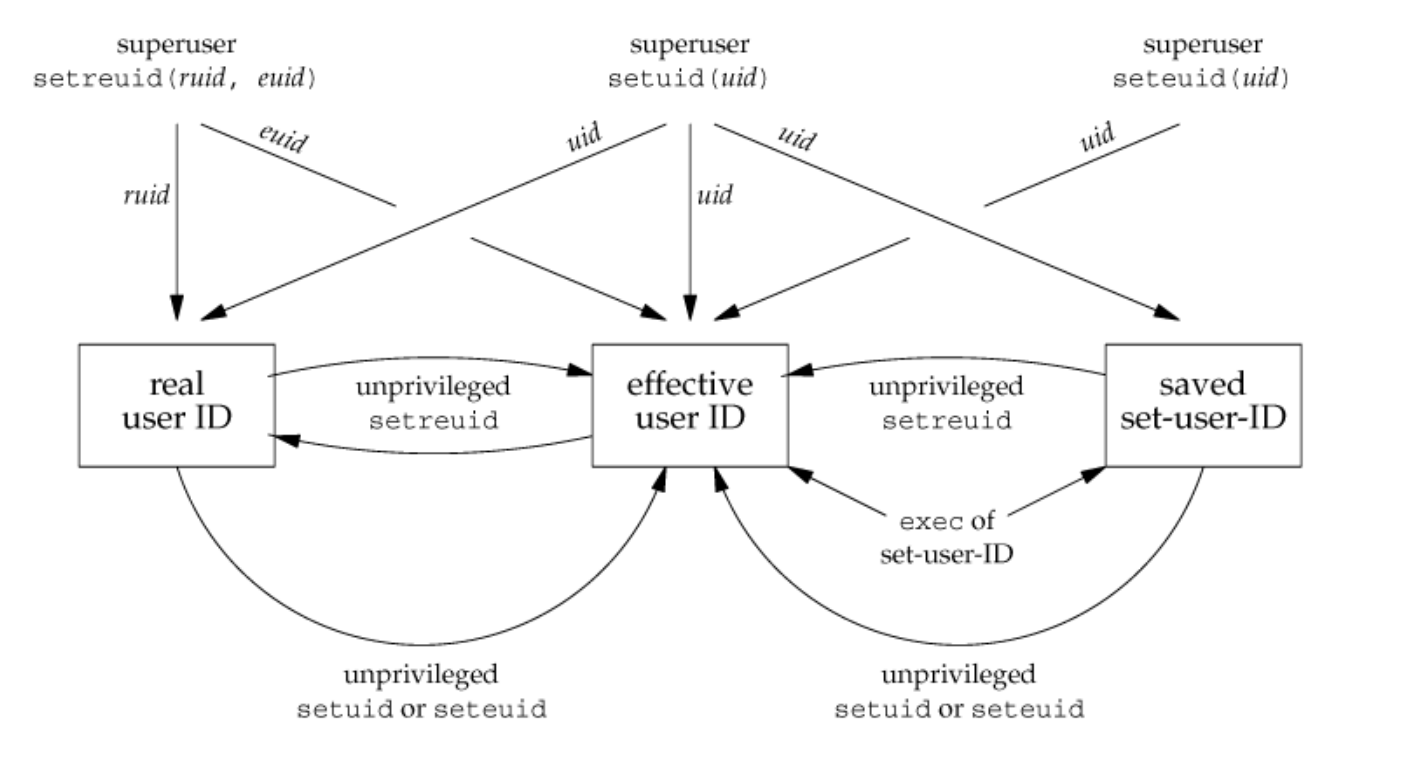
Changing User IDs and Group IDs
#include <unistd.h>
int setuid(uid_t uid);
int setgid(gid_t gid);
setuid
- effective uid를 uid로 설정
setgid
- effective uid를 gid로 설정
Return
- 둘 다 성공 시
return 0- error 발생 시
return -1
현 process에 root 권한이 있는 경우에는 setuid와 setgid는 real uid와 real gid도 설정한다. 이를 나타내면 아래와 같다.
File Size Limits : ulimit
#include <ulimit.h>
long ulimit(int cmd, [long newlimit]);write으로 생성할 수 있는 file 크기에는 process 당 제한이 있다. 현재 file 크기 제한을 얻으려면 cmd = UL_GETFSIZE로 설정되어야하며, file 크기 제한을 변경하려면 cmd = newlimit과 함께 UL_SETFSIZE로 설정되어야 한다.
Return
- 성공 시, 요청된 제한 값을 return
- error 발생 시
return -1
root 권한이 있는 경우만 이 방법으로 file 크기 제한을 늘릴 수 있다.
Process Priorities : nice
system은 nice의 값을 기반으로 특정 process에 할당되는 CPU 시간의 비율을 결정한다. scheduling시에 사용되며, 우선 순위를 지정하는 역할을 한다. 0부터 system의 max까지 값 부여가 가능하며, 작을 수록 높은 순위를 의미하게 된다.
root 권한이 있는 경우에는 음수 값을 부여할 수 있으며, 이는 보통 real time이 필요한 경우에 사용된다. 단 우선순위를 높게 둔 것은 확률을 높여주는 것이지, 무조건 먼저 실행된다는 보장은 없다는 점을 주의하자.
Inter-Process Communication Using Pipes
Inter-Process Communication
Unix(or Linux)에서는 작업을 위해 둘 이상의 process가 작동하는 경우가 많다. signal의 경우는 비정상적인 이벤트나 오류를 처리하는데는 적합하나, 다른 process로 정보를 전달하는 데는 적합하지 않다.
이때 pipe와 FIFO라는 2개의 통신 메커니즘을 통해 process가 서로 정보를 공유하고 협력할 수 있다.
Pipe
Pipe
pipe는 UNIX system 간 process간 통신의 가장 오래되고 단순한 형태로, special file로 표현된다.
$ cat test | wc -l위의 pipe command는 아래의 command와 동일하다.
$ cat test > temp
$ wc –l < temp
$ rm temp
System Call : pipe
#include <unistd.h>
int pipe(int filedes[2]);pipe는filedes[0], filedes[1]로 이루어진 pipe file descriptor를 생성하며, 각각 읽기와 쓰기에 사용된다. 단방향이므로 2개의 file descriptor로 이루어져 있으며, 일반적인 file과는 달리 lseek를 사용할 수 없다. 또한 FIFO 기반이다.
Return
- 성공 시
return 0- error 발생 시
return -1
-errno==EMFILE: 2개 이상의 file descriptor가 해당 process에서 사용중
-errno==ENFILE: system에서의 열 수 있는 파일 수를 초과
pipe read
- process가
pipe에서read를 호출하면pipe가 비어있지 않은 경우에는read는 즉시 반환되며, 비어있을 경우에는pipe에write이 될 때까지 기다린다.read용pipe가 닫히면, read하기 위해 해당 pipe를 열어도 아무 일도 일어나지 않으며,SIGPIPE가 생성된다. 기본 동작은 process 종료이며, catch하게 되면write는errno = EPIPE와 함께-1을 return한다.
pipe write
write를 호출하면pipe가 가득 차지 않았으면 바로write이후 return하며, 그렇지 않다면 기다리게 된다.pipe에서는read한 내용은 없어진다.write용pipe가 닫히면, write하기 위해 해당 pipe를 열어도 아무 일도 일어나지 않으며,read는 모든 데이터를 읽은 이후EOF를 나타내기 위해0을 return한다.
또한 PIPE는 fork시에 유전되는 요소 중 하나이다.
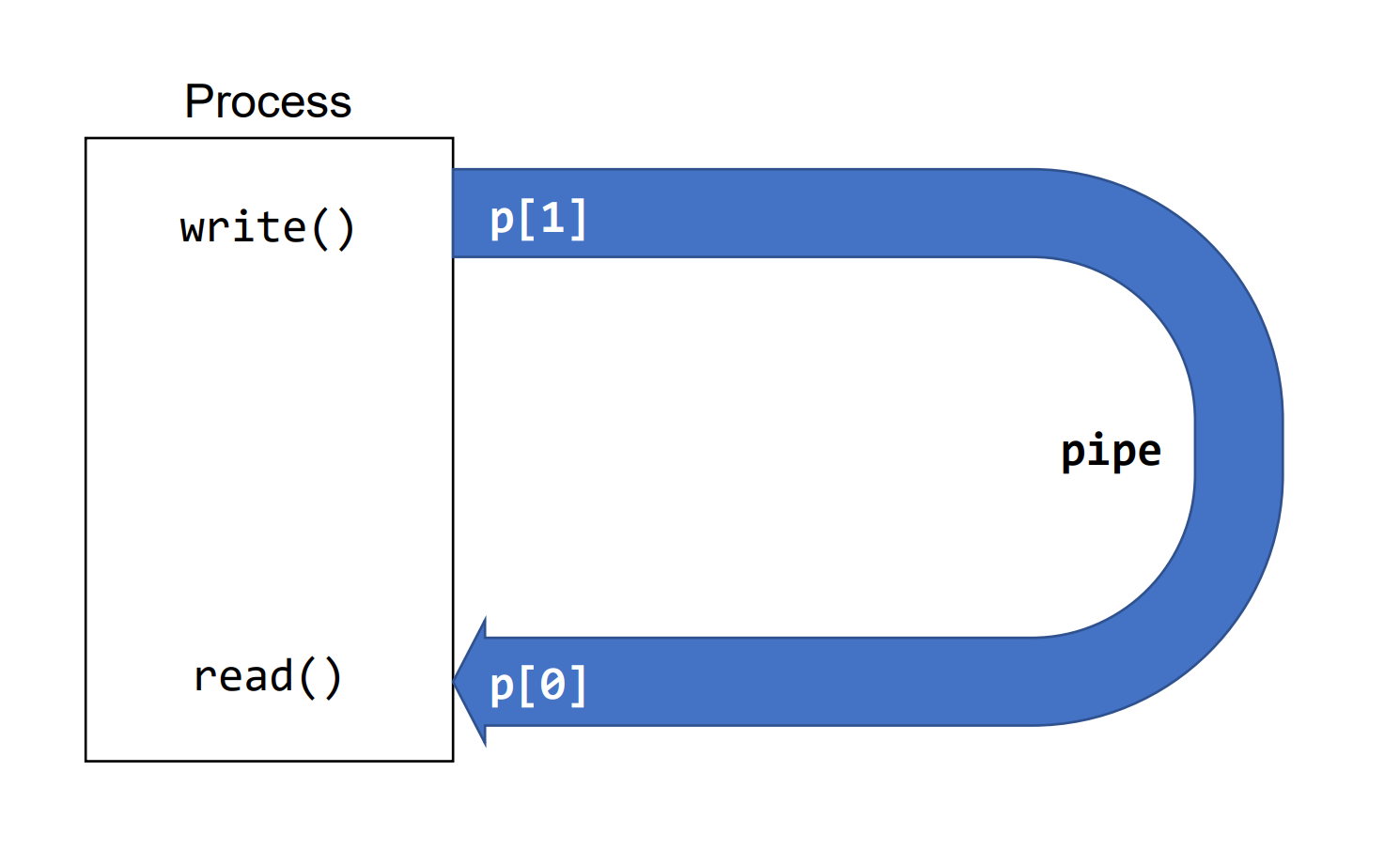
Example : pipe - 1
#include <unistd.h>
#include <stdio.h>
#define MSGSIZE 16
char *msg1 = “hello, world #1”;
char *msg2 = “hello, world #2”;
char *msg3 = “hello, world #3”;
int main() {
char inbuf[MSGSIZE];
int p[2], j;
pid_t pid;
if (pipe(p) == -1) {
perror(“pipe call”);
return 1;
}
write(p[1], msg1, MSGSIZE);
write(p[1], msg2, MSGSIZE);
write(p[1], msg3, MSGSIZE);
for(j=0; j<3; j++) {
read(p[0], inbuf, MSGSIZE);
printf(“%s\n”, inbuf);
}
return 0;
}위 코드는 하나의 process에서 pipe를 열어 스스로에게 쓰고 읽는다. 이를 그림으로 나타내면 아래와 같다.
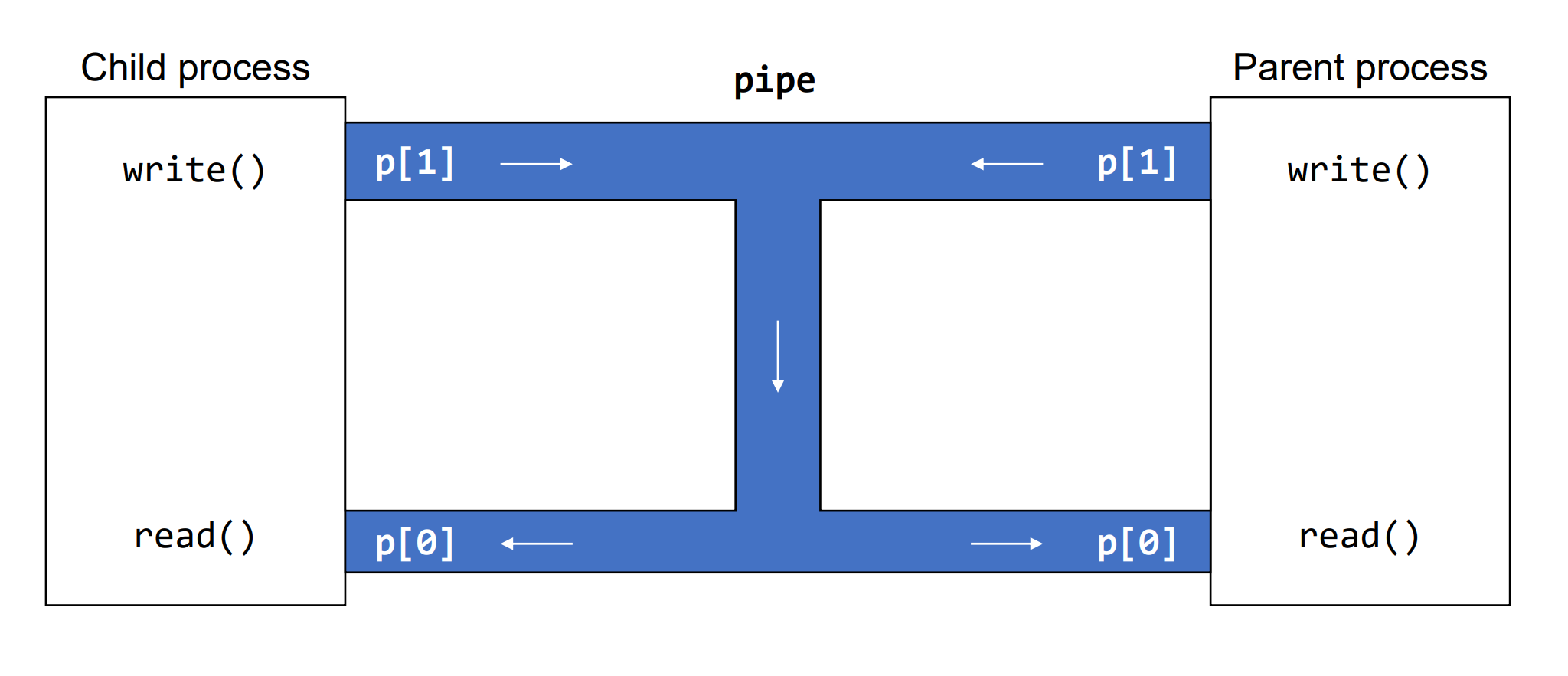
Example : pipe - 2
#include <unistd.h>
#include <stdio.h>
#define MSGSIZE 16
char *msg1 = “hello, world #1”;
char *msg2 = “hello, world #2”;
char *msg3 = “hello, world #3”;
int main() {
char inbuf[MSGSIZE];
int p[2], j;
pid_t pid;
if (pipe(p) == -1) {
perror(“pipe call”);
return 1;
}
switch (pid=fork()) {
case -1:
perror(“fork call”);
return 2;
case 0:
write(p[1], msg1, MSGSIZE);
write(p[1], msg2, MSGSIZE);
write(p[1], msg3, MSGSIZE);
break;
default:
for(j=0; j<3; j++) {
read(p[0], inbuf, MSGSIZE);
printf(“%s\n”, inbuf);
}
wait(NULL);
}
return 0;
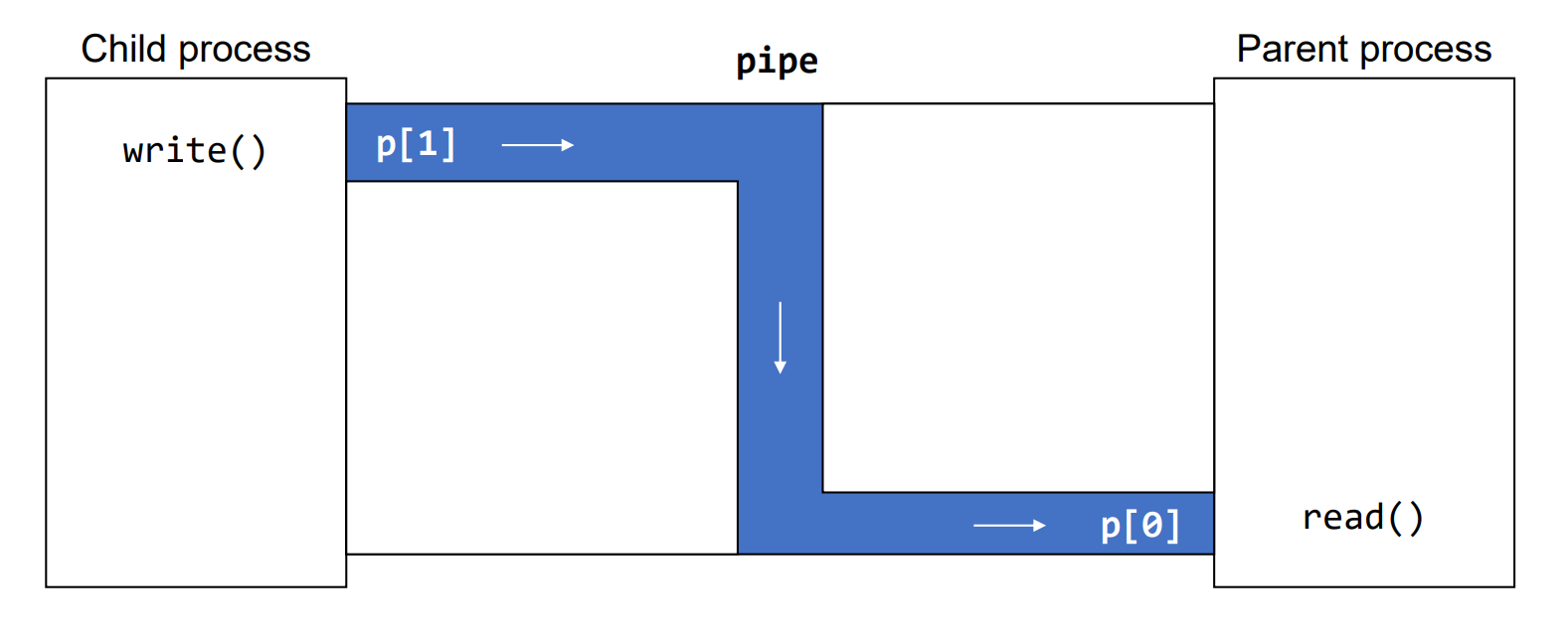
}일반적으로 pipe는 위와 같이 parent와 child 사이에 사용되기도 하며, block되므로 동기화가 어느 정도 보장된다. 이를 그림으로 나타내면 아래와 같다.
Example : pipe - 3
#include <unistd.h>
#include <stdio.h>
#define MSGSIZE 16
char *msg1 = “hello, world #1”;
char *msg2 = “hello, world #2”;
char *msg3 = “hello, world #3”;
int main() {
char inbuf[MSGSIZE];
int p[2], j;
pid_t pid;
if (pipe(p) == -1) {
perror(“pipe call”);
return 1;
}
switch (pid=fork()) {
case -1:
perror(“fork call”);
return 2;
case 0:
close(p[0]);
write(p[1], msg1, MSGSIZE);
write(p[1], msg2, MSGSIZE);
write(p[1], msg3, MSGSIZE);
break;
default:
close(p[1]);
for(j=0; j<3; j++) {
read(p[0], inbuf, MSGSIZE);
printf(“%s\n”, inbuf);
}
wait(NULL);
}
return 0;
}pipe는 단방향으로 작동하기 때문에 한 쪽에서는 read만, 다른 한 쪽에서는 write만 가능하도록 사용하지 않는 pipe는 닫아주도록 한다. 이를 그림으로 나타내면 아래와 같다.
The Size of a Pipe
Maximum pipe write size
- POSIX : 512 bytes
- Linux : 4096 bytes
Pipe max size
- Linux : 1MB (default 64KB)
일반 file보다 pipe는 size에 대한 제약이 강하며, default는 64KB, 임의로 변경시에 최대 1MB까지 증가시킬 수 있다. write의 경우에는 위보다 큰 값을 넘겼다 하더라도 쓰여지지 않는 것이 아닌, 위 단위대로 나누어 write를 진행하게 된다.
그러나 이 과정에서 다른 write에 의해 interleaved, 즉 중간에 다른 write이 개입될 수 있다. (순서가 지켜지지 않을 수 있음)
Blocking & Non-Blocking
read는 당장 읽을 data가 없을 경우에 block되며, write 역시 바로 쓸 수 없는 경우에는 block이 된다. 이에 대해 non-blocking으로 작동할 수 있도록 할 수 있으며, file descriptor를 open할 때, O_NONBLOCK을 지정하면 된다. 이미 열려있는 경우에는 fcntl을 사용하여 O_NONBLOCK flag를 설정한다.
Non-Blocking read and write on pipe
주어진 pipe에 대해 non-blocking으로 작동하도록 2가지 방법으로 설정이 가능하며, 이는 아래와 같다.
use fstat
fstat(p[1], &buf); if (buf.st_size >= PIPE_BUF) return error;
use fcntl
if (fcntl(p[1], F_SETFL, O_NONBLOCK)==-1) perror(“fcntl”);
pipe가 가득 찬 경우의 write와 pipe가 빈 경우의 read는 errno = EAGAIN과 함께 -1을 return한다.
Controlling Multiple Pipes
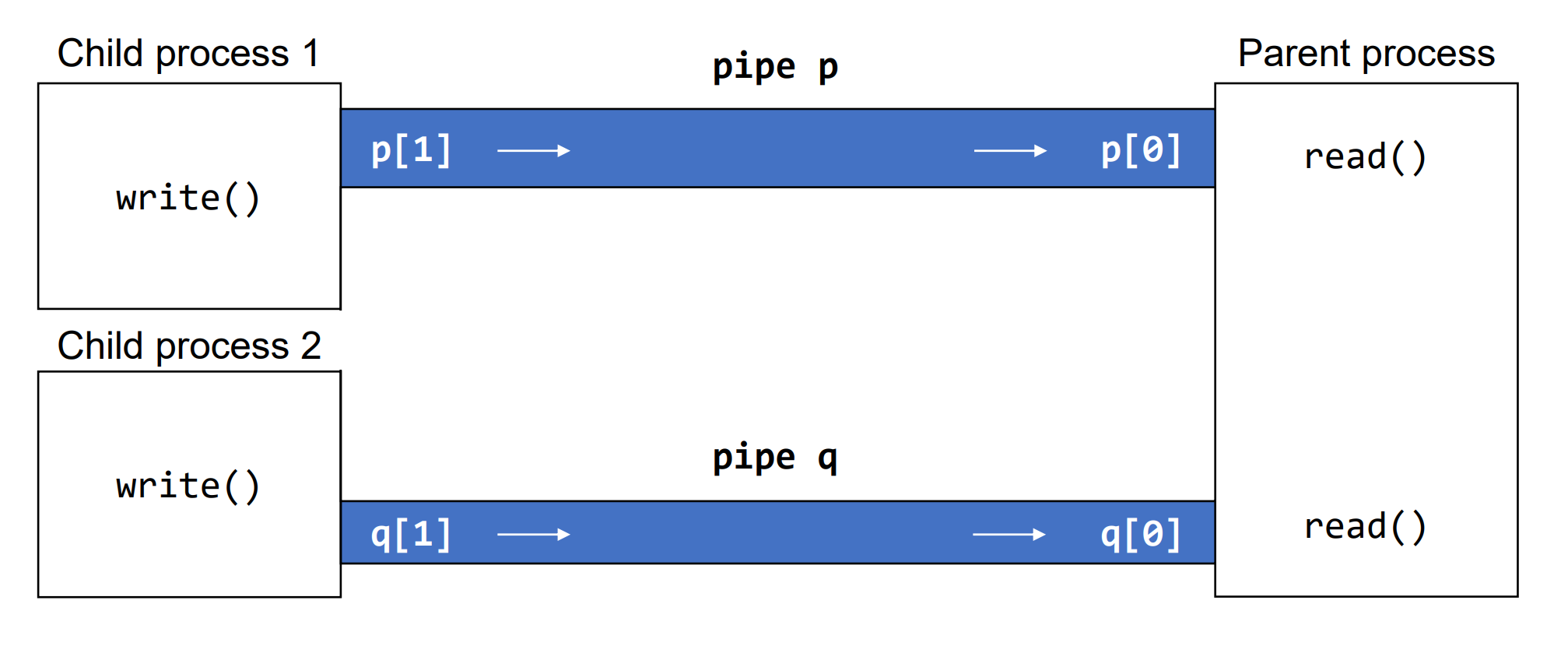
일반적으로 위와 같이 여러 process의 write를 read할 필요가 있으며, 이를 위한 것이 select이다.
✅ 실습 시간 추가 코드
ps command
ps 명령어 사용 시에 -o option을 사용하여 원하는 정보를 모아 출력해서 확인할 수 있다.
...@came01:~/ex8$ ps -o pid,ppid,pgid,sid,command
PID PPID PGID SID COMMAND
33892 33890 33892 33892 -bash
919544 33892 919544 33892 ps -o pid,ppid,pgid,sid,command