
🔔 학교 강의를 바탕으로 개인적인 공부를 위해 정리한 글입니다. 혹여나 틀린 부분이 있다면 지적해주시면 감사드리겠습니다.
4.5 Unix File Systems
Unix (Linux) File System
file system은 저장장치에 file을 저장하기 위한 논리적 구조가 존재하며, directory가 mount된 file system에 쌓여있는 것을 Mount-on이라 한다. 복수계의 device로 하나의 file system을 구축하는 것이 Linux에서는 가능하며, 이를 그림으로 나타내면 아래와 같다.
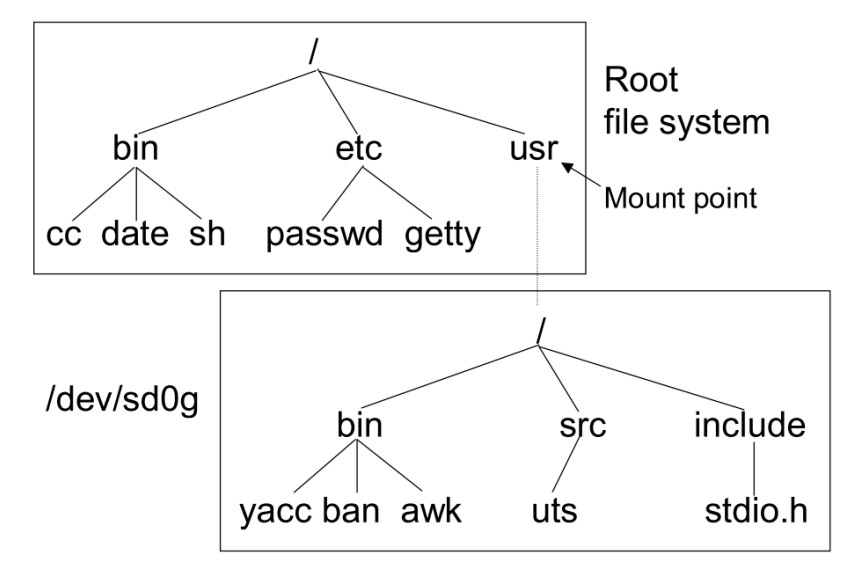
하단의 file system을 상단의 root file system의 하위 directory에 mount하여 file system을 구현한다.
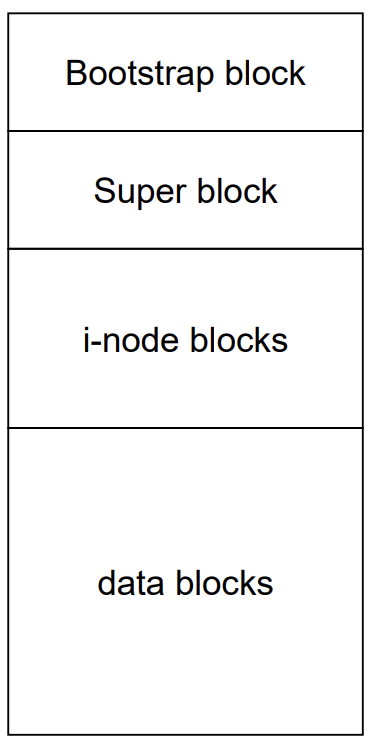
Bootstrap area
PC가 부팅되어야 할 때 실행되어야 할 코드가 들어있는 block이다.
Super block
file system에 대한 정보를 담고 있으며, 각 device마다 존재한다.
- file system 내부의 total block 개수
- i-node 개수
- block의 size
- free block과 used block의 개수
i-node blocks
디스크 file과 관련된 모든 i-node들이다.
Data blocks
file block에 해당한다.
Caching
file system에서 mount된 file system의 super block 복사본은 빠른 접근을 위해 memory상에서 관리한다. super block이 담고 있는 정보는 작기 때문에 file 변화시마다 바로 접근한다.
memory에 있는 data는 바로 disk에 쓰이는 것이 아니라, buffer에 모이게 된다. Unix(Linux)에는 buffer의 data를 disk에 write하기 위해 sync와 fsync가 존재한다.
System Call : sync and fsync
#include <unistd.h>
void sync(void);
int fsync(int filedes);argument
- int filedes : 바로 disk에 반영할 file의 file descriptor
return (
fsync)
- 성공 시에 0 return
- error 발생 시에 -1 return
sync는 모든 main memory data를 반영하며, fsync는 전달받은 file에 대해 sync를 진행한다. sync는 os와 관련되어 사용되며, unix(linux)는 주기적으로 sync를 call하는 코드를 반복한다.
중요한 차이점은 fsync의 경우는 해당 파일에 대해 sync가 처리될때까지 block되지만, sync는 바로 return이 된다는 점이다. (바로 실행은 X)
4.6 Unix (Linux) Device Files
Device of Unix (Linux)
Unix(linux)는 device를 숫자로 지정해 관리하며, 이를 device number라 한다. 이는 크게 아래와 같이 나뉘며, 사용자는 device number로 바로 device에 접근하는 것이 아닌, unix(linux)가 device number를 mapping한 device file을 통해 접근하게 된다.
- major number : device의 type을 의미 (device driver)
- minor number : type 내부의 순서, 각 device를 구분
주변 장치에 해당하는 device들은 file system의 file 이름을 통해 접근하며, 이러한 device file에 대한 read, write는 system과 해당 device간의 직접적인 데이터의 전송으로 이루어진다. 이러한 device file들은 /dev directory 안에 위치하며, 일반 file들과 같이 사용될 수 있다.
ex) $ cat fred > /dev/lp
// > : redirectionBlock and Character Device Files
device file은 아래와 같이 크게 2가지로 나뉜다.
Block device file
- block 단위로 접근
- SSD, HDD 등
random access가 가능- file system은 block device로만 구성 가능
Character device file
- char 단위 접근
- terminal, printer, network 등 바로 보내는 것이 중요한 device들
- 길이는 유동적이며, random access가 가능할 수도, 불가능할 수도 있음
추가적으로 Raw device가 존재한다. block device인데 char device로 사용하고 싶을 경우에 해당되며, file system을 걷어내므로 여러 단계를 거치지 않아도 되서 I/O 속도가 증가한다는 장점이 있다.
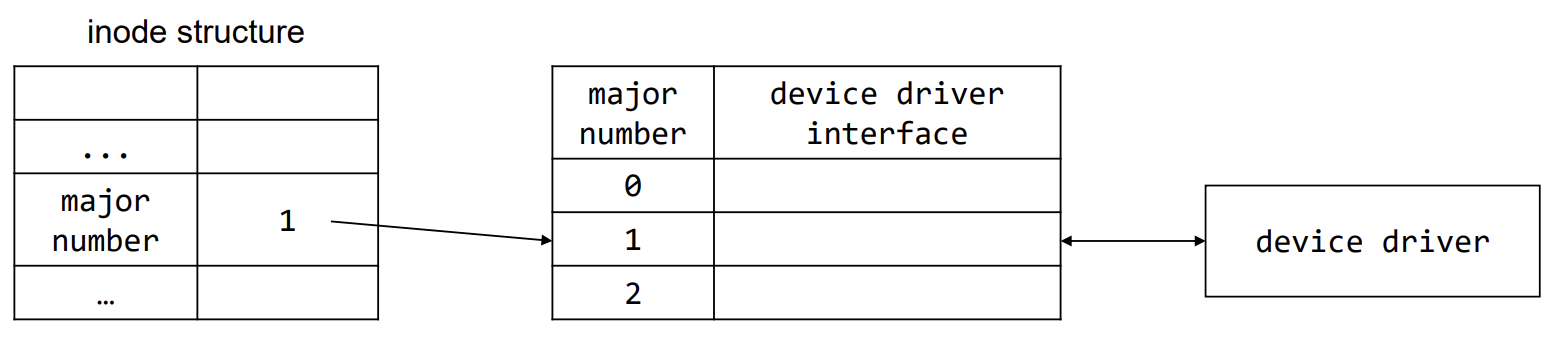
이러한 device들과 상호작용하기 위한 2가지 table이 존재하며, block device switch table과 character device switch table이다. 두 table 모두 device file의 i-node에 저장된 major number를 사용하여 인덱싱된다.
device들과 data를 주고받는 순서는 아래와 같다.
read와write를 call하여 device file의i-node에 접근i-node내의 flag를 보고block인지char인지 구분하고,major, minor number를 추출major number로 device 확인 후, driver routine 호출,minor number로 정확한 포트 식별
Revisiting stat structure
st_mode에 저장된 bit는 사실상 총 16bit이며, 권한을 나타내는 9bit와 execute 관련 3bit을 제외하고 상위 4bit이 추가로 존재한다. 이는 해당 file이 무슨 파일인지를 나타낸다. 이는 아래 그림과 같다.

st_mode에서 060000 (S_IFBLK)은 block device를 나타내며, 020000 (S_IFCHR)은 character device를 나타낸다. 또한 st_rdev는 minor number를 의미한다. 'ls -l을 통해 이를 쉽게 확인할 수 있다.

The Process
Function : main
main function의 prototype은 아래와 같으며, argc는 command line에서의 인자의 개수를 의미하며, argv는 인자가 담긴 배열의 pointer에 해당한다.
int main(int argc, char *argv[]);exec 함수 중 하나에 의해 c program이 kernel에 의해 실행되면 main이 호출되기 전에 start up routine이 실행된다. 이는 kernel에서 command line에서의 인수와 환경변수 등을 가져온다. 이는 아래와 같다.

Environment list
environment list는 char pointer의 list이며, 이 주소는 전역 변수 환경에 포함된다. 대부분의 unix(linux) 에서는 main 함수의 3번째 인자로 제공된다.
int main(int argc, char *argv[], char *envp[]);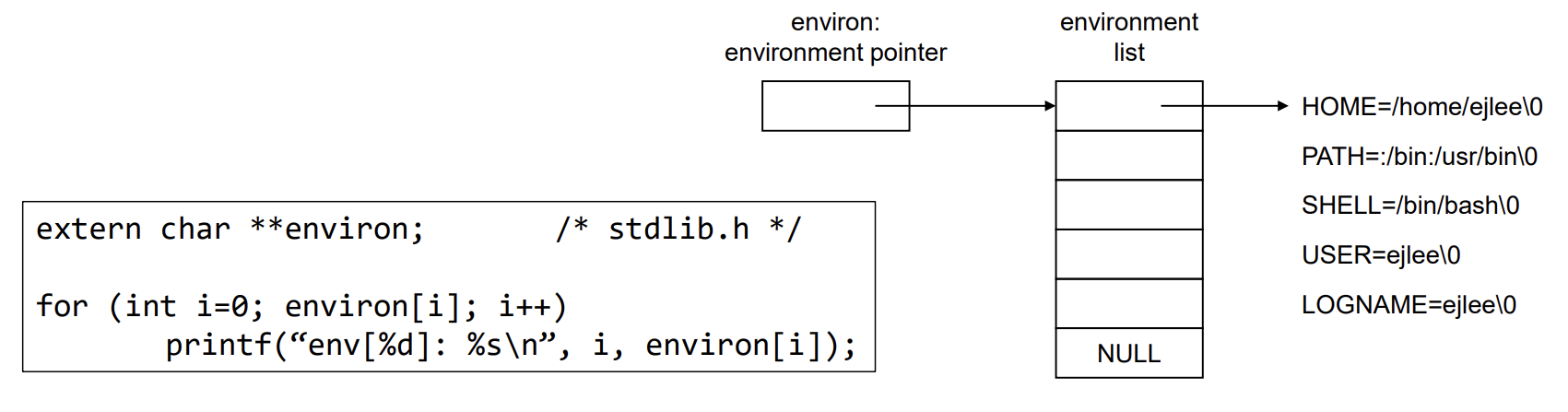
PATH의 경우는 file 이름이 주어졌을 때, 해당 file을 search할 directory들의 정보가 담겨있으며, :으로 구분하여 나열되어있다.
Memory Layout of C Program
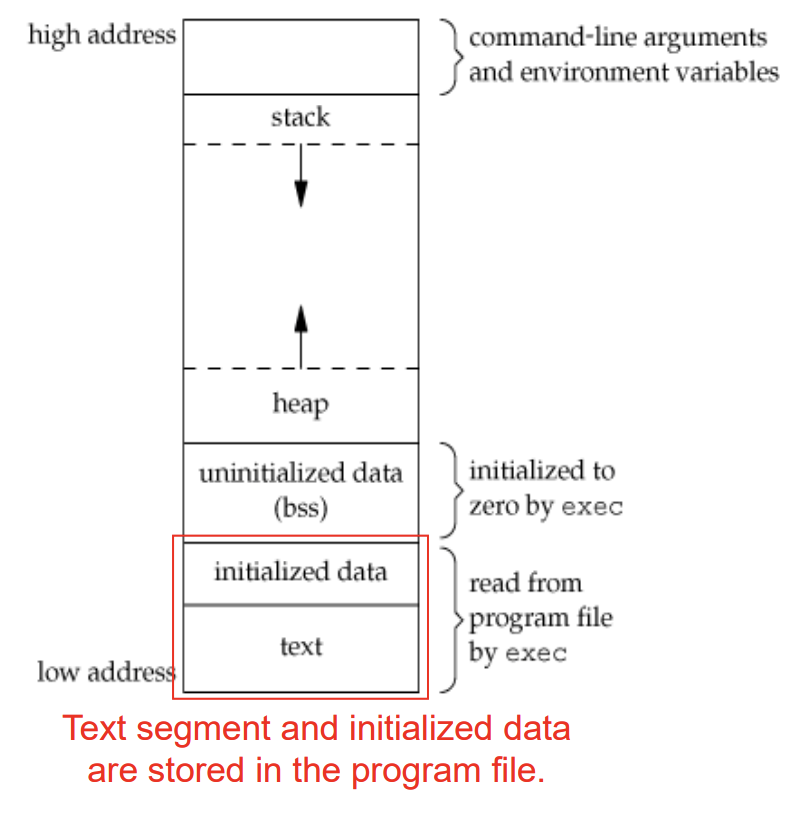
C program은 위와 같이 구성되어 있으며, 이를 정리하면 아래와 같다.
- Text segment : 실행할 프로그램 명령들
- Initialized data segment : 초기화된 전역 및 정적 변수들 (static 포함)
- Uninitialized data segment (bss) : 초기화되지 않은 전역 및 정적 변수들이며 program 시작 전에 kernel에 의해 0 혹은 null pointer로 초기화됨
- Stack : local 변수를 위한 메모리 공간
- Heap : 동적 메모리 할당 관련
Text segment와 Initialized data segment는 Program file에 저장된다.
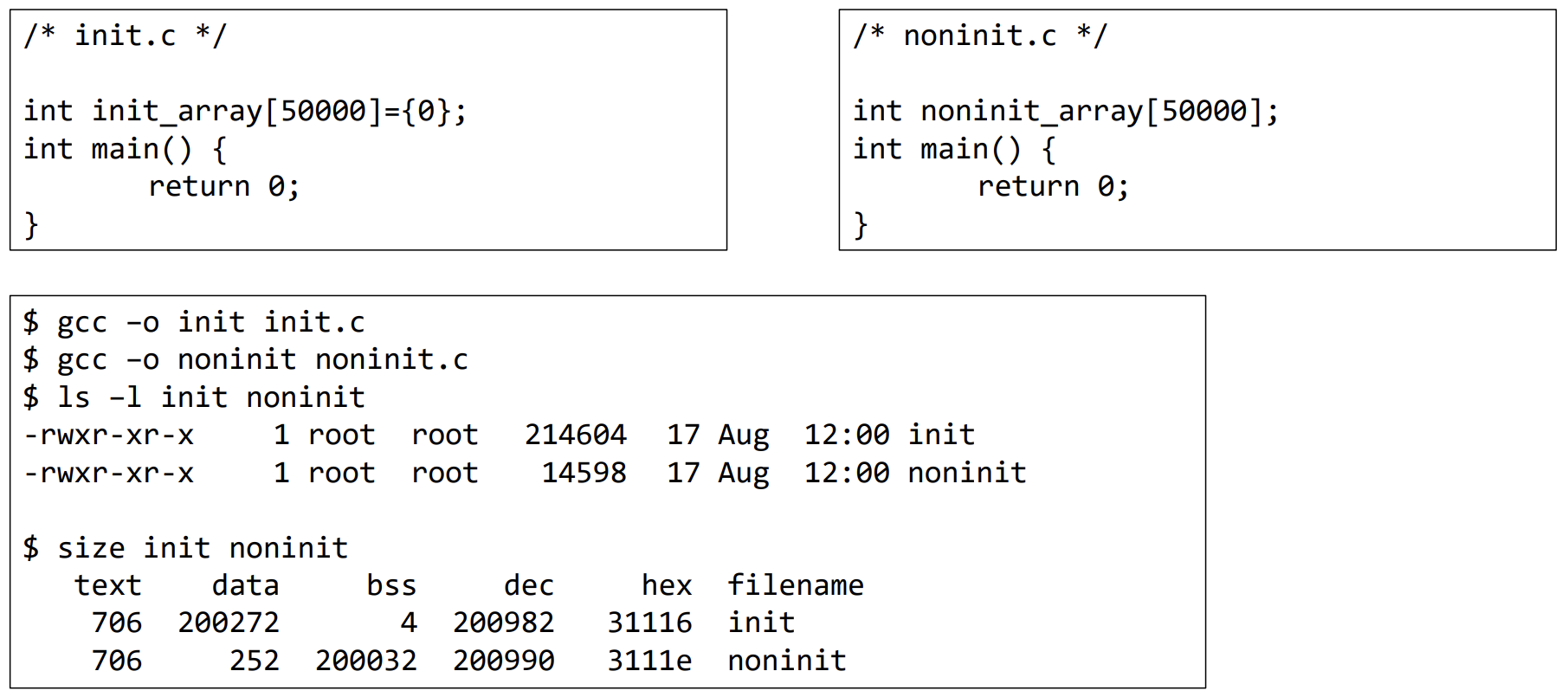
배열에서 하나만 초기화를 해준 경우와, 초기화를 해주지 않고 선언만 한 경우에 있어서 차이가 존재한다. 왼쪽의 경우는 initialized에 들어가며, 오른쪽은 uninitialized에 포함된다. 이는 size command를 이용하여 파악할 수 있다. text는 동일하나 data를 보면, bss는 file size에 포함되지 않기 때문에 init의 경우가 더 큰 것을 볼 수 있다. (program file에 포함되기 때문)
5.1 Review of the notation of a process
Process
process는 현재 실행되고 있는 program을 의미하며, program과 process는 다르다고 할 수 있다. process는 아래를 포함한다.
- program code
- program 변수 내의 data 값
- 하드웨어 register
- program stack
process는 process id(pid)가 붙어 관리되며, shell은 새로운 process를 생성한다.
Process environment
process에도 부모와 자식 관계가 존재하며, directory tree와 유사한 계층 구조로 이루어진다. 가장 상위에는 단일 제어 process인 모든 process의 조상에 해당하는 init이 존재한다. unix(linux)는 process 생성과 조작을 위해 fork, exec, wait, exit 등 system call들을 제공한다.
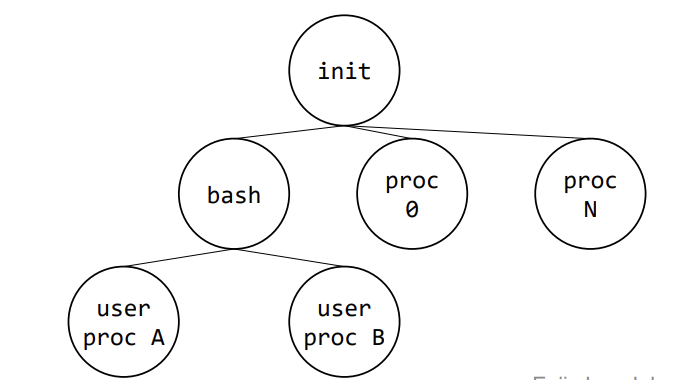
가장 상위 process인 init은 bootstrap에서 생성된다.
5.2 Creation process
System Call : getpid and getppid
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);getpid와 getppid는 process id를 return하며, process id는 유일하고 음수가 아닌 정수이다. 0, 1은 이미 존재하며, 이후의 번호를 사용하고, 유일하기 때문에 재사용될 수 없다. getpid는 현 process의 pid를 return하고, getppid는 parent process의 pid를 return한다.
System Call : fork
#include <unistd.h>
pid_t fork(void);fork는 call한 process와 동일한 새로운 process를 생성한다. child와 parent의 return값은 서로 다르다.
return
- 성공 시에는 child process는 0을, parent process는 child process의
PID를 return- error 발생 시 -1 return
system 전체에 대한 process 수 제한이나 개별 사용자에 대한 process 수 제한에 도달하면, 즉 process의 maximum 수에 도달하면 limit error로 errno = EAGAIN을 return한다.
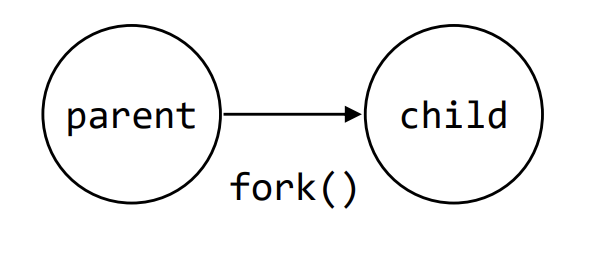
child는 parent의 data space, heap, stack의 복사본을 받지만, text segment는 공유하게 된다. 즉, 코드는 복사하지 않고 parent의 코드를 공유한다. 또한 parent와 child 둘 중 어떤 process가 먼저 실행될지 알 수 없다.
이러한 과정을 그림으로 나타내면 아래와 같다.
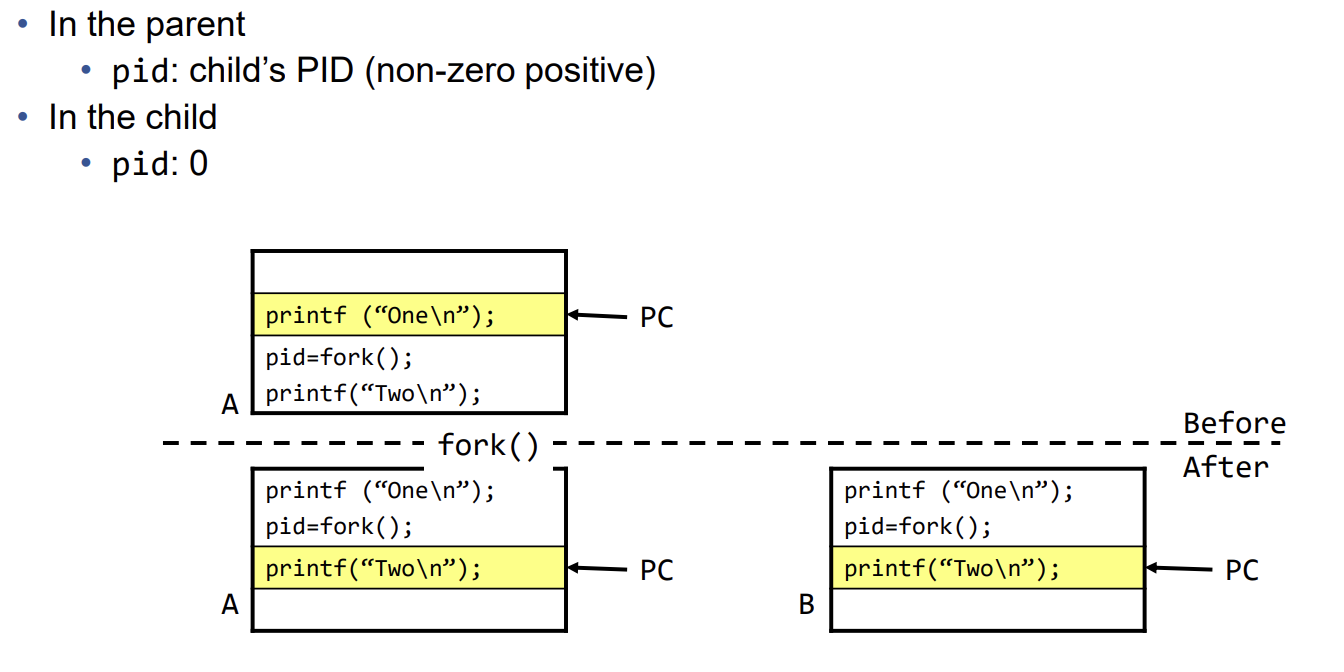
0은 이미 할당되어 있으므로 사용될 일이 없기 때문에 child를 나타낼때 사용한다. 이에 대한 예시 코드는 아래와 같다.
Example : fork
#include <unistd.h>
int main() {
pid_t pid;
printf(“Just one process so far\n”);
printf(“Calling fork …\n”);
pid = fork();
if (pid == 0)
printf(“I’m the child\n”);
else if (pid > 0)
printf(“I’m the parent, child has pid %d\n”, pid);
else
printf(“Fork returned error code, no child\n”);
return 0;
}위의 코드와 같이 fork를 사용할 경우에는 child에서 실행될 코드와 parent에서 실행될 코드가 둘 다 포함되어야 하므로 비효율적이다. 따라서 exec을 사용한다.
5.3 Running new program with exec
The exec family
exec는 새로운 program의 실행을 시작한다. execl, execv, execle, execve, execlp, execvp로 총 6가지이며, 새로운 process가 생성되지는 않기 때문에 PID는 변경되지 않는다. 단순히 현 process를 disk의 새로운 program으로 대체하는 것이며, execve가 kernel 내 systam call에 해당한다. (즉, 다른 형태는 변환을 통해 execve로 실행됨)
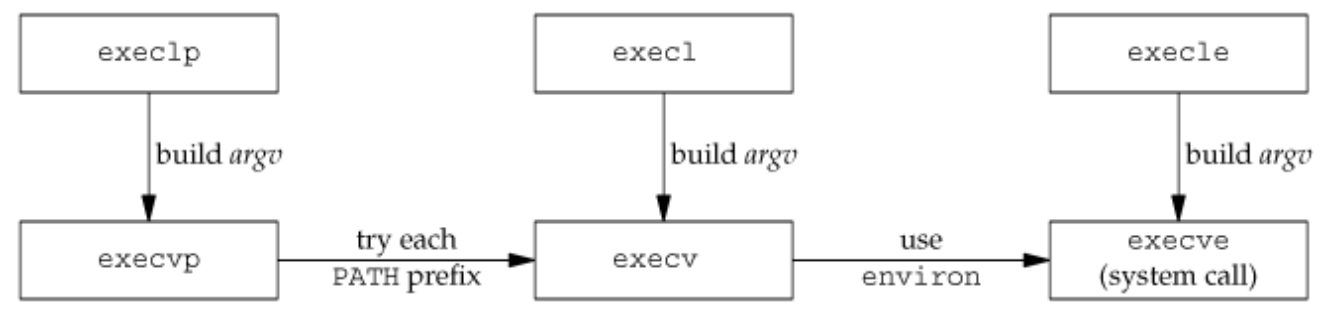
# include <unistd.h>
int execl(const char *pathname, const char *arg0, …, NULL);
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, …, NULL, char *const envp[]);
int execve(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, …, NULL);
int execvp(const char *filename, char *const argv[]);전체적인 형태는 위와 같으며, exec 뒤에 붙는 문자에 따라 의미가 달라진다.
l : 인자를 list 형태로 줌
v : 인자를 vector 형태로 줌
e : 환경변수를 포함
p : PATH 환경변수를 바탕으로
argument
- const char *pathname : 절대, 상대 경로로 표현되는 file
- char *const argv[] : vector로 전달되는 인자
- char *const envp[] : 환경변수
- const char *filename : 경로 표시 제외한 file 이름
return
- 정상 수행 시 return 없음
- error 발생 시 -1 return
exec는 새로운 하위 process를 생성하지 않으며, 실제 program이나 실행 권한이 있는 shell script를 포함해야 한다.
해당 주차에 추가로 학습한 command
stuct stat에서 st_dev는 disk drive에 대한 정보에 해당하며, 실제 장치 file 정보에 해당하는 것은 st_rdev이다.
Function : major and minor
#include <sys/sysmacros.h>
unsigned int major(dev_t dev);
unsigned int minor(dev_t dev);major과 minor은 각각 device의 major number와 minor number를 return한다.
st_mode
st_mode와 아래 bit들이 동일한지를 판별하면, 해당 file이 어떤 type인지 판별할 수 있다.
st_mode == 0010000 : FIFO (p)
st_mode == 0020000 : character dev (c)
st_mode == 0040000 : directory (d)
st_mode == 0060000 : block dev (b)
st_mode == 0100000 : regular (-)
st_mode == 0120000 : symbolic link (l)
-> `0170000`과 `&`연산을 통해 판별이 가능하다.&
program 실행 시에 뒤에 &을 붙여주면, background 수행을 하며, process 종료 전에 shell로 복귀하게 된다.
ps
현재 수행중인 process 정보를 출력하며, option은 아래와 같다.
-e: system process 전체를 전부 보여줌-f: full format으로 보여줌
위 둘에 대한 예시는 아래와 같다.

PATH environment
execlp와 execvp에서 사용하는 PATH 환경변수는 echo $PATH로 확인이 가능하며, export PATH=$PATH:추가하고싶은 경로 로 추가가 가능하다. 이에 대한 예시는 아래와 같다.

하지만 이는 해당 shell에서만 적용되므로, 종료하면 기본 PATH로 돌아간다. 따라서 모든 shell에서 PATH를 변경하고 싶다면 ~/.bashrc에 PATH=$PATH:추가하고싶은 경로를 추가하면 된다.
특정 경로를 PATH에 추가해주면, 해당 경로에서는 경로명이 아닌 file명으로 program 실행이 가능하다.
which, whereis
which 명령어로 특정 명령어의 위치(path)를 return해준다. whereis는 명령어의 바이너리(실행파일), 소스, 매뉴얼 파일의 위치를 출력한다.
