📚Linked List
컴퓨터에 데이터를 저장하는 방법에는 크게 2가지가 있다.
- 같은 타입 데이터를 연속으로 정해진 공간에 집어넣는 방법
- 필요할때마다 공간을 할당해 데이터를 집어넣는 방법
첫 번째 경우는 우리가 일반적으로 아는 배열이고, 두 번째 경우가 Linked List(연결리스트)에 해당된다.
비유를 하자면 다음과 같이 다르다.
👉예시
A라는 수업 분반에 강의실 공간이 할당됨
- 배열 : 학생 인원 예측해 책상 50개를 미리 넣어놓는다. (정확한 인원을 모르기 때문에 안쓰는 책상이 있을 수 있음)
- 연결리스트 : 학생이 직접 책상을 받아 가지고 강의실로 들어간다. 단, 바로 전 학생이 다음 학생의 위치를 기억하도록 한다. (낭비되는 책상 없음)
📝배열과 연결리스트의 장단점
👉배열의 장점
- 접근이 빠르다.
👉배열의 단점
- 메모리 사용이 효율적이지 않다.
- 배열 내의 데이터 이동이 어렵다.
👉연결리스트의 장점
- 동적 메모리를 사용하므로 메모리 관리에 효율적이다.
- 데이터 재구성이 간단한 편이다.
👉연결리스트의 단점
- 어느 특정 위치에 존재하는 데이터를 찾는데 느리다.
- 주소를 저장하는 메모리를 추가로 사용해야 한다.
📝연결리스트의 구조
연결리스트는 기본적으로 노드라고 부르는 객체로 이루어져 있다.
그럼 노드가 뭐지? 노드는 블럭 2개로 이루어진 객체라고 할 수 있다. 앞쪽에는
값이 들어가게 되고(element field), 뒤쪽 블럭에는 다음 노드의 위치를 가리키는 주소값이 들어가게 된다.(Link field)
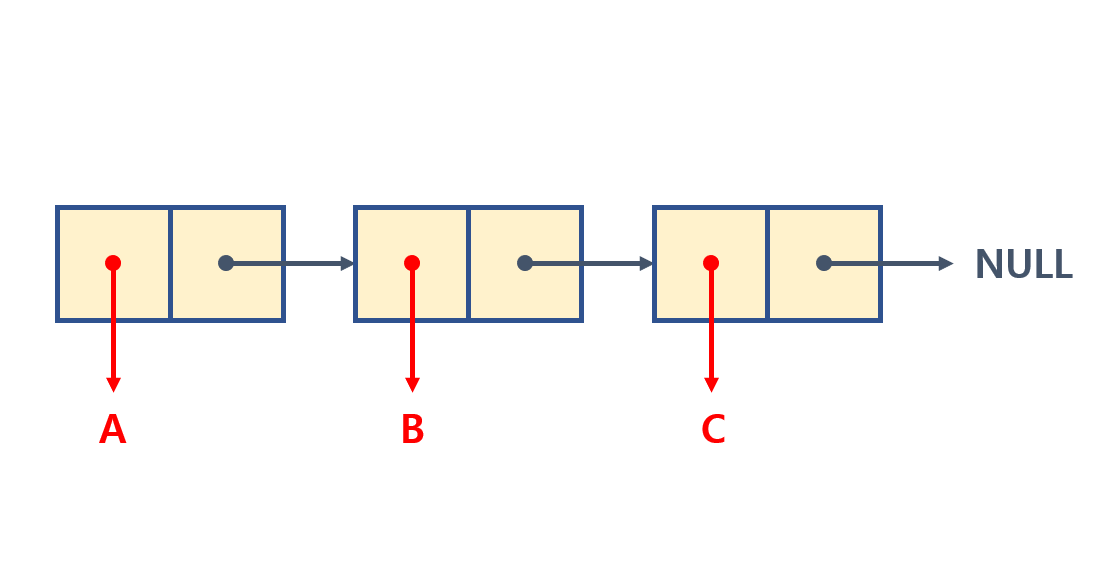
그림과 같이 연결 리스트는 노드들이 선형적으로 순서화된 형태의 집합체라 할 수 있다.
이 노드에서 링크필드가 1개만 있으면 단일 연결리스트, 2개면 이중 연결리스트라고 부른다.
📚Singly Linked List
단일 연결 리스트에서 값을 삽입(insert)하거나 삭제(delete)하는 방법은 간단히 정리하면 아래와 같다.
📝head에 값을 삽입하는 방법
- 새로운 노드를 만든다.
- 새로운 노드에 값을 집어넣는다.
- 새로운 노드의 링크 필드에 기존의 head 주소값을 넣어준다.
- head가 새로운 노드를 가리키도록 한다.
📝tail에 값을 삽입하는 방법
- 새로운 노드를 만든다.
- 새로운 노드에 값을 집어넣는다.
- 새로운 노드의 링크 필드에 NULL값을 집어넣는다.
- 기존의 마지막 노드가 새로운 노드를 가리키도록 한다.
- tail이 새로운 노드를 가리키도록 한다.
📝head의 값을 삭제하는 방법
- head가 두 번째 노드를 가리키도록 한다.
- 첫 번째 노드를 삭제한다.
📝tail의 값을 삭제하는 방법
=> 단일 연결리스트에서의 이 방법은 구현은 가능하나 효율적이지는 않다.
=> 이중 연결리스트에서는 쉽게 구현이 가능하다. (이중 연결리스트는 다음 노드의 주소뿐만 아니라 이전 노드의 주소도 가지고 있기 때문.)
📚Singly Linked List 구현
📝구현해야할 것들
우선 기본적으로 데이터 필드와 주소값 필드로 이루어져 있는 노드를 구현해야 한다. 구조체를 이용해 구현할 수도 있지만 C++을 주로 사용하기 때문에 Node class로 구현하겠다.
기본적으로 있어야 할 자료구조의 기능으로는 탐색과 삽입(저장), 삭제가 있다. 이를 위해 순차적으로 연결리스트에 값을 추가하는 기능과, 원하는 위치에 접근해 값을 넣는 기능, 원하는 위치에 접근해 값을 삭제하는 기능들이 있어야 할 것이다. 이를 위해 구현할 기본 연산은 다음과 같다.
- Empty : 연결리스트가 비어 있는지 확인하는 함수
- ListSize : 연결리스트의 크기를 확인하는 함수
- Append : 연결 리스트에 값을 추가하는 함수
- AddFront : 연결리스트의 가장 앞에 값을 추가하는 함수
- Insert : 연결리스트의 특정 인덱스에 값을 삽입하는 함수
- Delete : 연결리스트의 특정 인덱스에 해당하는 값을 삭제하는 함수
- Print : 연결리스트 안에 있는 값을 순서대로 출력하는 함수
📝예시 코드
정수 값을 담을 수 있는 Singly Linked List의 예시 구현 코드는 다음과 같다.
