
프로젝트 주제와 기획의도
1300만의 반려인을 위한 무료 반려동물 안구 질환 진단 서비스입니다.
코로나 이후로 반려동물 수와 반려인 수는 매년 가파르게 상승하고 있습니다. 현재는 대한민국의 약 25%에 해당하는 1300만명이 반려동물을 키우고 있습니다. 내 아이들이 안 아프고 쭉 건강했으면 좋겠지만 쉽지 않죠.
반려동물이 아프면 동물병원에 가야 하는데, 사람과 달리 의료보험이 적용되지 않기 때문에 비용 부담이 큽니다. 이러한 부담을 겪는 반려인을 위해, 반려동물의 안구 질환을 무료로 진단할 수 있는 서비스를 개발했습니다.
▼ GitHub
https://github.com/chickengak/walness
▼ 팀, 일정
사용 데이터
반려동물 안구질환 데이터
제공: AI 허브
서비스 및 기능
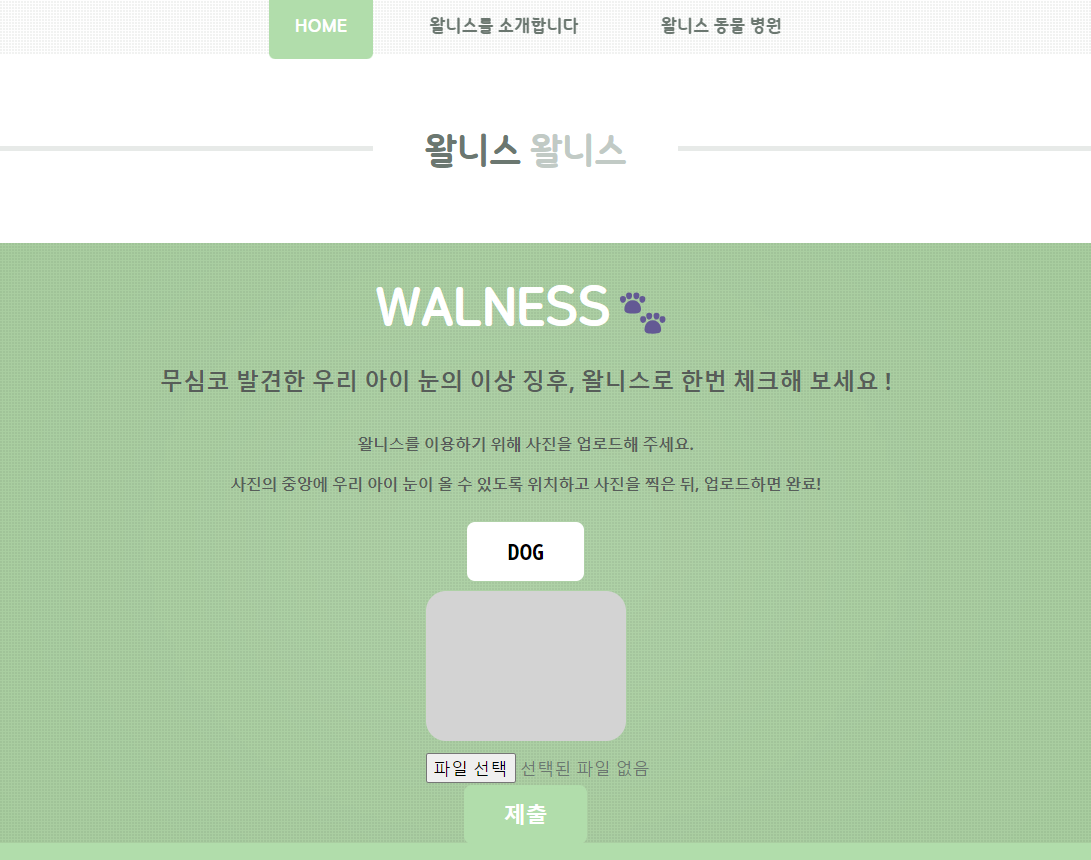
UX를 극대화하기 위해 심플하면서 편안한 디자인으로 구성함.
사용자는 개/고양이 버튼으로 반려 동물을 선택한 후, 파일 선택 버튼으로 반려 동물의 눈을 촬영해서 올리고, 제출 버튼을 누르면 결과를 확인할 수 있다.
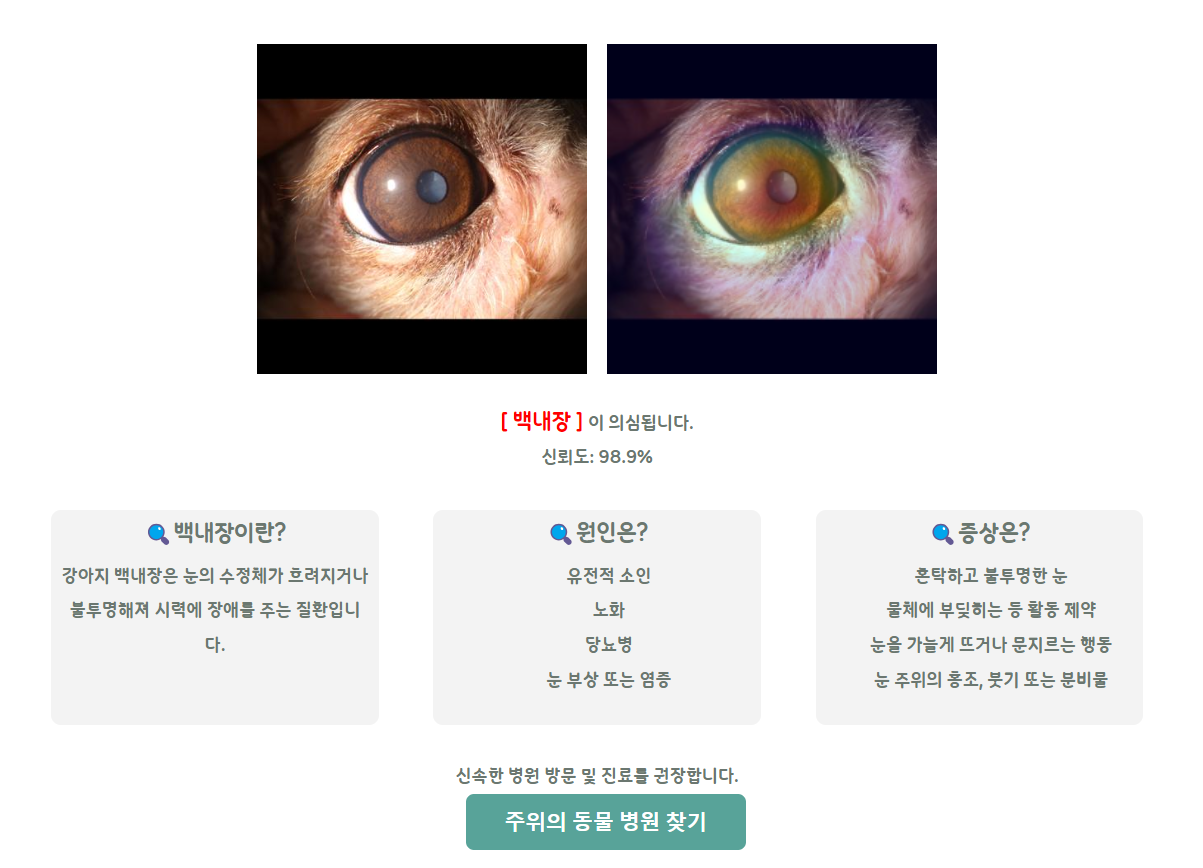
사용자가 받는 결과는 위의 사진과 같다. 사용자가 올린 이미지와 Grad CAM이 적용된 사진을 받는다. 질병 명칭과 예측 신뢰도도 확인할 수 있다. 또한, 질병에 대한 간략한 정보도 같이 제공 받을 수 있다.
질병에 따라 병원을 추천하고, 사용자는 주위의 동물 병원 찾기 버튼을 눌러서 저희가 제공하는 동물 병원 추천 페이지로 이동할 수 있습니다.
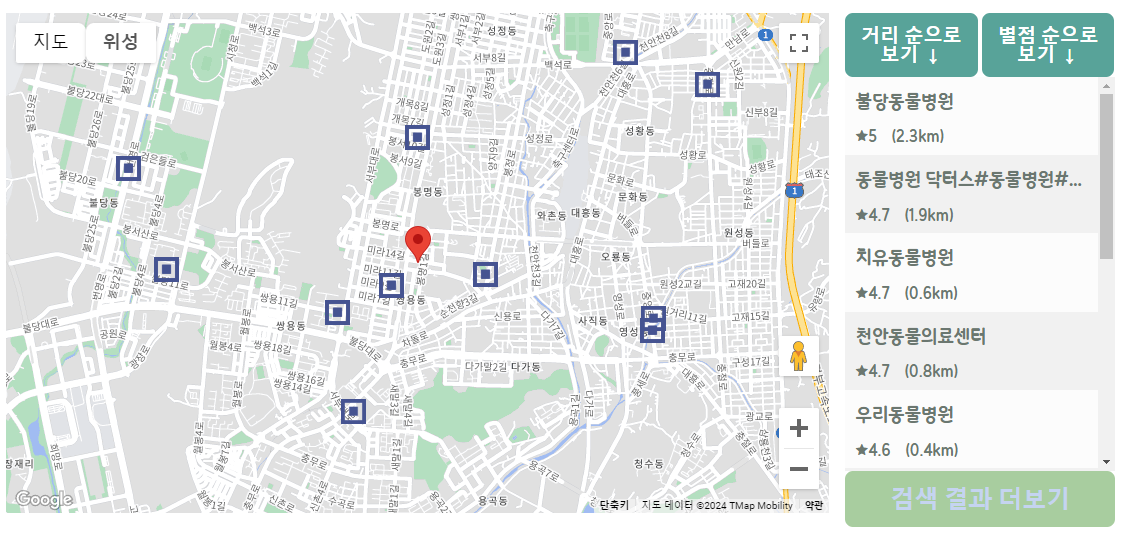
동물 병원 추천 시스템은 구글지도를 기반으로 보여 준다. 사용자가 위치 정보 사용에 동의하면, 사용자의 위치와 함께 주변의 동물 병원들을 표시 한다.
우측에는 동물병원을 거리 순 혹은 별점 순으로 정렬해서 보여주는 버튼이 있기 때문에, 사용자가 원하는 동물병원을 더 찾기 쉽게 했다.
프로젝트 후기와 배운점
1. 협업을 위한 도구들
1.1 VSCode Dev Containers
팀으로 개발할 때 라이브러리 버전을 맞추는 것이 중요한데 ML/DL에서는 특히 더 중요하다.
그래서 팀원들의 기술스택을 고려해서 최대한 간단하면서 효과적인 툴을 찾아야 했고, VSCode의 Dev Containers 익스텐션을 선택하게 됐다.
1.2 Git
어찌보면 Git을 사용한 것이 큰 성과는 아닐 수도 있지만,
Git을 처음 쓰는 팀원들도 있어서 자칫 버전관리없는 스토리지가 되어 버릴까봐 조금 우려스러웠습니다.
하지만 가르쳐 준대로 잘 따라와주고 사용한 팀원들덕분에 예쁘게 버전관리 된 Git을 얻을 수 있었습니다.
2. 커스텀 스크럼 프로세스

구글 시트를 활용해서 실시간 일정관리 프로세스를 구축했다. 전체 스케줄링은 전통적인 스크럼 스프린트를 따르지만, 스프린트를 더욱 잘게 나누어 세분화한 Task 혹은 To-Do-List 단위로 스케줄링했다. 덕분에 개발실력이 상이한 팀원들도 수월하게 스케줄링에 참여할 수 있었다.
또한 매일 스크럼 회의를 하면서 새로 알게된 내용 혹은 애로사항을 공유했다. 덕분에 팀원의 실수를 반복하는 것을 방지하고 더 나은 방향으로 프로젝트가 흘러가도록 자연스로운 브레인스토밍을 할 수 있었다.
3. 적절한 수익화 시스템의 중요성 확인
UX를 해치지 않는 선에서 광고를 게시했다. 지금까지 프로젝트를 진행할 때는 프로젝트 주제만을 위한 개발을 해왔는데, 멘토의 조언으로 다양한 수익화 방법까지 고려하는 안목을 가질 수 있게 되었다. 시스템과 서비스가 이뤄지는 중간에 발생하는 비어있는 시간 혹은 여분공간을 활용하고, 서비스와 관련된 광고를 게시하거나 상품을 판매하고 2차로 연계되는 광고들을 고려할 수 있다는 점을 알았다.
4. Servicable 모델의 중요성 확인
모델의 정확도만을 올리기 위해서 크고 무거운 모델을 사용하면 결과는 좋을 수 있으나, 서비스하기에는 부적합해질 수 있다는 사실을 알았다. 모델이 결과를 출력하기까지 너무 오래걸린다면, 아무리 정확도가 높더라도 사용자에게 서비스하기에 부적합할 수 있다.
5. 다양한 딥러닝을 시도
- 이미지 데이터에 적합한 다양한 모델을 적용해 봄.
- 사전학습 된 모델을 활용.
- ImageNet으로 학습된 weight를 활용했을 때 더 좋은 결과가 나올 수도 있다. 이 weight를 사용하려면 레이어의 trainable을 False해야 한다.
- convolution 레이어가 아닌 레이어를 동결하면 학습에 지장이 생긴다.
- 전체 convolution 레이어를 동결하기 보다는 앞쪽 레이어만 동결하고, 뒤쪽 레이어는 trainable = True로 주는게 가장 성능이 좋았다. 앞쪽은 엣지와 코너같은 낮은 수준의 특징을 추출하고 뒤로 갈 수록 추상적인 정보를 추출하기 때문에, 뒤쪽을 내 데이터에 맞춰 학습했을 때 성능이 더 좋았던 것이다.
- Pooling 방법을 바꾸는 것으로도 성능이 바뀐다.
- Max Pooling과 Avg Pooling을 적절히 바꿔보자. 모델마다 더 잘 맞는 Pooling 방법이 상이했다.
- 다양한 Optimizer를 활용.
- 일반적으로 많이 쓰이는 Adam외에도 이미지에 적합하다는 다른 Optimizer도 사용해봤다.
- AdamW는 Adam이 L2 regularization과 weight decay 관점에서 일반화 능력이 떨어지기 때문에 이를 보완하기 위해, adam에 weight decay를 적용한 모델이다. 일반화 능력 향상으로 비전에서 더욱 좋은 성능을 보여주는데, 확실히 특징을 잘 캐치해내서 금방 정확도가 올라가는 것을 확인할 수 있었다.
- Nadam은 RMSprop momentum 대신, Nesterov momentum이 적용된 Adam이다. AdamW만큼은 아니지만 adam과 비교하면 눈에 띄게 정확도가 올라가는 것을 확인했다. 이 옵티마이저는 비전에서 AdamW와 Adam 사이의 성능을 보여줬다.
- 분류 모델에서 고려해야할 점들
- 클래스별 데이터 불균형을 해소해야 한다.
- 분류할 클래스가 많아질 수록 학습을 위한 하드웨어 요구사항이 예상보다 많이 늘어난다.
- Colab과 Gdrive는 이미지 데이터에 적합하지 않다.
- 오히려 로컬PC에서 GPU로 학습하는게 낫다.
- Optuna로 하이퍼 파라미터 최적화
- 딥러닝용 하이퍼 파라미터 최적화 프레임워크인 Optuna를 사용해 봤다. 소소한 성능향상을 체감했다.
6. 데이터 엔지니어링 시도
데이터 엔지니어링을 위한 데이터 플로우도 구축해봤다. 우선, 여러 서버가 있는 상황을 만들기 위해서 3개의 가상머신을 만들었다. 그리고 하나를 메인서버로 나머지는 하위서버로 구축하기 위해 메인서버는 Namenode와 리소스매니저인 Yarn을 채택했고, 나머지는 Datanode로 만들어서 연결했다.
데이터가 잘 저장되는 것을 확인한 후에는 스파크로 분산 처리하는 구성을 만들어 봤다. 가상머신을 추가하기엔 메모리가 부족했기에 Datanode가 있는 서버를 분산처리하는 서버로 만들었다. 최종적으로 Yarn이 데이터 분산처리를 요청하면 스파크 앱 마스터가 분산 처리를 하도록 요청하고 스파크 엑시큐터들이 분산 처리하는 과정까지 확인했다.
여기에 카프카도 접목을 시도했다. 카프카에서 프로듀서로 데이터 인풋을 받아서 토픽에 저장해놓으면 컨슈머로 스파크 스트리밍이 동작해서 입력된 데이터를 스파크가 전처리한 후에 HDFS에 저장하는 것까지 구상해놨다. 하지만, 카프카에서 maven으로 빌드하는 과정에서 예상치 못한 에러가 자꾸 발생해서 차마 이 연결은 완성하지 못 했다.
향후 개선 사항
1. 모델이 분류할 수 있는 질병 클래스 수를 늘리기
현재는 물리적인 제한 상황때문에 분류 클래스 수를 줄여 놓은 상태다. 좀더 좋은 성능의 환경을 이용한다면 클래스 수를 늘릴 수 있을 것으로 기대한다.
2. 처음 계획처럼 포괄적인 진단하기
마찬가지로 하드웨어가 더 좋은 환경만 마련된다면, 피부질환, 비만도, 자세교정까지 포함되는 포괄적인 진단 서비스를 제공할 수 있을 것으로 기대한다.
3. 좀 더 servicable한 모델 만들기
모델이 결과를 반환하는데 걸리는 시간과 모델 정확도 사이에서 저울질하며 많이 고려했지만, 아직 반환 시간이 다소 걸리는 문제는 여전했다. 이 시간을 단축시키면서도 정확도를 유지할 수 있는 개선 방법을 더 찾을 수 있다면 시도해봐야겠다.
4. 데이터 엔지니어링 개선하기
아파치 에어플로우와 주키퍼를 이용한다면 더 나은 데이터 엔지니어링 환경으로 개선할 수 있을 것으로 기대한다.
마치며
크고 작은 난관들이 많았아서 계획이 다소 늘어지긴 했지만, 늘어질 것을 예상하고 초반을 타이트하게 스케줄링해서 전체 일정에는 큰 지장이 없었다. 또한, 프로젝트를 커스텀 스크럼으로 스케줄링했던 것도 매우 만족스러웠다. 이 커스텀 스크럼 프로세스도 일정을 바로 잡아주는데 많은 도움이 됐었다.
데이터 사이언스와 데이터 엔지니어링으로 많은 시도와 도전을 해봤기 때문에 다양한 경험치를 쌓을 수 있었다. 이 경험치를 잊지 않도록 가끔 다시 와서 읽어볼 필요도 있을 것 같다.
Servicable 모델과 수익화 시스템에 대해 공부하고 많은 고민을 했었는데, 그저 학업수준의 프로젝트가 아닌 실무에 더 가까운 고민을 해보고 그에 대한 해결책을 찾아 본 경험이 참 색다르고 참신한 경험이었다.
이제 Django를 이용한 간단한 웹서비스는 쉽게 할 수 있을 정도로 반복 숙달된 것 같은 것은 덤이다.
