//1강
from matplotlib import pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
plt.plot(years, gdp, color='green', marker='o', linestyle='solid') => 'r:o" 이런식으로 축약 가능
plt.title("Nominal GDP")
plt.ylabel("Billions of $")
plt.xlabel("Years")
plt.show()
plt.savefig("hello.pdf", dpi=300)
//linestyle = '--' , '-.', (0,(5,1)) 등이 있음
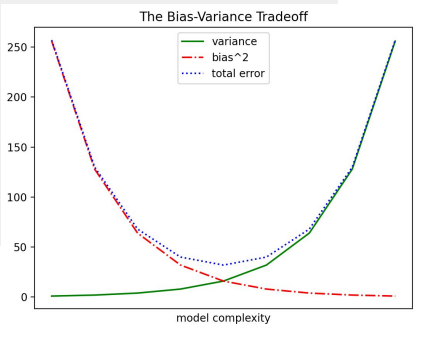
variance = [1,2,4,8,16,32,64,128,256]
bias_squared = [256, 128, 64, 32, 16, 8, 4, 2, 1]
total_error = [x + y for x, y in zip(variance, bias_squared)]
xs = range(len(variance))
plt.plot(xs, variance, 'g-', label='variance')
plt.plot(xs, bias_squared, 'r-.', label='bias^2')
plt.plot(xs, total_error, 'b:', label='total error')
plt.legend(loc="upper center")
plt.xlabel("model complexity")
plt.xticks([]) => 여기에 숫자 넣어주면 x축에 표시뎀 , ([0,8],[min,max] ) 이런식으로 하면 그 자리에 저 단어가 들어감 (y축도 동일)
plt.title("The Bias-Variance Tradeoff")
plt.show()
이런식 ?
movies = ["Annie Hall", "Ben-Hur", "Casablanca", "Gandhi",
"West Side Story"]
num_oscars = [5, 11, 3, 8, 10]
plt.bar(movies, num_oscars)
plt.title("My Favorite Movies")
plt.ylabel("# of Academy Awards")
plt.show()
// 이건 막대 그래프
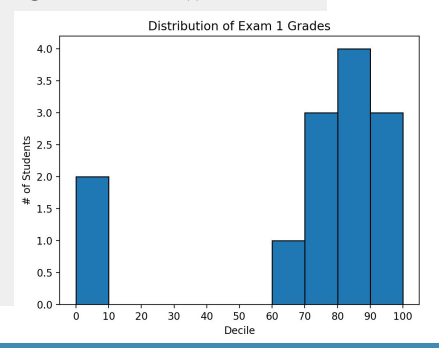
from collections import Counter
grades = [83, 95, 91, 87, 70, 0, 85, 82, 100, 67, 73, 77, 0]
histogram = Counter(min(90, grade // 10 * 10) for grade in grades)
plt.bar([x + 5 for x in histogram.keys()], histogram.values(),
width=10, edgecolor="black")
plt.xticks(range(0, 101, 10))
plt.xlabel("Decile")
plt.ylabel("# of Students")
plt.title("Distribution of Exam 1 Grades")
plt.show()
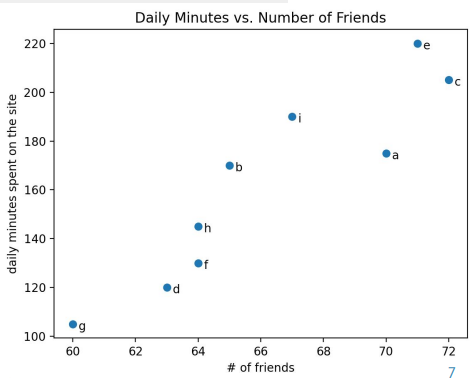
import matplotlib.pyplot as plt
friends = [ 70, 65, 72, 63, 71, 64, 60, 64, 67]
minutes = [175, 170, 205, 120, 220, 130, 105, 145, 190]
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i']
plt.scatter(friends, minutes)
for l, f, m in zip(labels, friends, minutes):
plt.annotate(l, xy=(f, m),
xytext=(5,-5), textcoords="offset points")
plt.title("Daily Minutes vs. Number of Friends")
plt.xlabel("# of friends")
plt.ylabel("daily minutes spent on the site")
plt.show()
https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.annotate.html
//산점도
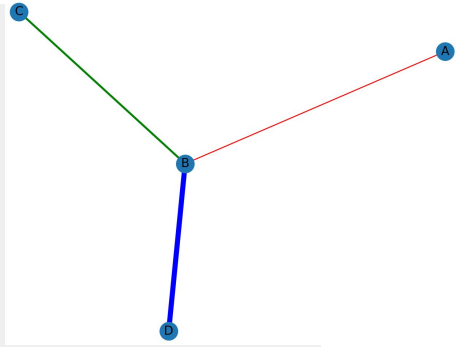
//네트워크 시각화
import networkx as nx
G = nx.Graph()
G.add_edge('A','B', color='r', weight=1)
G.add_edge('C','B', color='g', weight=2)
G.add_edge('B','D', color='b', weight=5)
pos = nx.spring_layout(G) => 믕처져있는 애들 뭉치게함
//pos = {"A": (1,10)} => 이런식으로 지정한 위치가능
colors = list(nx.get_edge_attributes(G, 'color').values())
weights = list(nx.get_edge_attributes(G, 'weight').values())
nx.draw(G, pos, edge_color=colors, width=weights, with_labels=True)
plt.show()
이런식
2강 백터
class Vector:
def init(self, *lst):
self.data = lst
def repr(self):
return f"Vector{self.data}"
a = Vector(1,2,3)
b = Vector(2,3,4)
def add(self, other):
return Vector(*(x + y for x, y in zip(self.data, other.data)))
def sub(self, other):
return Vector((x - y for x, y in zip(self.data, other.data)))
=> c= a+b 근데 add함수에 없을 경우 => a.add 이렇게 호출함 c = a.add 다른거 다 동일
def mul__(self, other):
return Vector((x * other for x in self.data))
def rmul(self, other):
return Vector((x other for x in self.data))
vector 값이 아닌 다른걸 할때는 이렇게 만들음 => a = 3*b
def mul(self, other):
if type(other) == Vector:
return sum(x y for x, y in zip(self.data, other.data))
else:
return Vector((x * other for x in self.data))
// 백터의 내적
import numpy as np
A = np.array([[1,2,3], [2,3,4]])
B = np.array([[2,3,4], [3,4,5]])
print(f"A+B = {A+B}") # 행렬 더하기
print(f"A-B = {A-B}") # 행렬 빼기
print(f"A.T = {A.T}") # 전치행렬 (Transpose)
print(f"AB = {AB}") # 행렬 요소별 곱하기
print(f"A.dot(B.T) = {A.dot(B.T)}") # 행렬 곱하기 => 내적한갑=>
print(sum(a*b)), b.T = 그 바꾸는거임 곱셉할수 있게 2x3으로
//행렬
3강
import sys
from collections import Counter
cnt_friends = sorted(Counter(int(x)
for line in sys.stdin
for x in line.split()).items())
for nid, cnt in cnt_friends:
print(nid, cnt)
from collections import Counter
import sys
num_friends = sorted(int(line.split()[1]) for line in sys.stdin)
n = len(num_friends)
//mean
mean = sum(num_friends) / len(num_friends)
print(f"mean: {mean}")
// median 중앙값
median = num_friends[n // 2]
if n % 2 == 0:
median = (median + num_friends[n // 2 - 1]) / 2
print(f"median: {median}")
// mode 최빈값
count = Counter(num_friends)
mode = [c for c in count if count[c] == max(count.values())]
print(f"mode: {mode}")
2. count = Counter(num_friends).most_common(1)[0][0] 도 뎀
// max, min
print(f"min: {min(num_friends)}")
print(f"max: {max(num_friends)}")
// quantile
q10 = num_friends[int(0.25 * n)]
q25 = num_friends[int(0.5 * n)]
q90 = num_friends[int(0.75 * n)]
print(f"quartile: {q10}, {q25}, {q90}")
// 산포도
산포도(dispersion): 데이터가 퍼져있는 정도
○ max-min: 가장 큰 값과 가장 작은 값의 차이
○ 분산 (variance): 편차 제곱의 평균
○ interquartile range: 상위 25%와 하위 25%의 차이
import sys
num_friends = sorted(int(line.split()[1]) for line in sys.stdin)
maxmin_range = max(num_friends) - min(num_friends)
mean = sum(num_friends) / len(num_friends)
var = sum((x - mean) 2 for x in num_friends) / len(num_friends)
sd = var 0.5
print(f"variance: {var}")
print(f"standard_deviation: {sd}")
//교수님 방법
import numpy as np
num_firend_np = np.array(num_firend)
//max - min
maxmin = num_firend_np.max() - "".min()
mean = n~.mean()
sum = sum((x-mean)2 for x in n~)/len(n~), ((n~)2).mean()
np.quantile(n~,0.25) 이런식으로 가능
//공분산

//상관계수
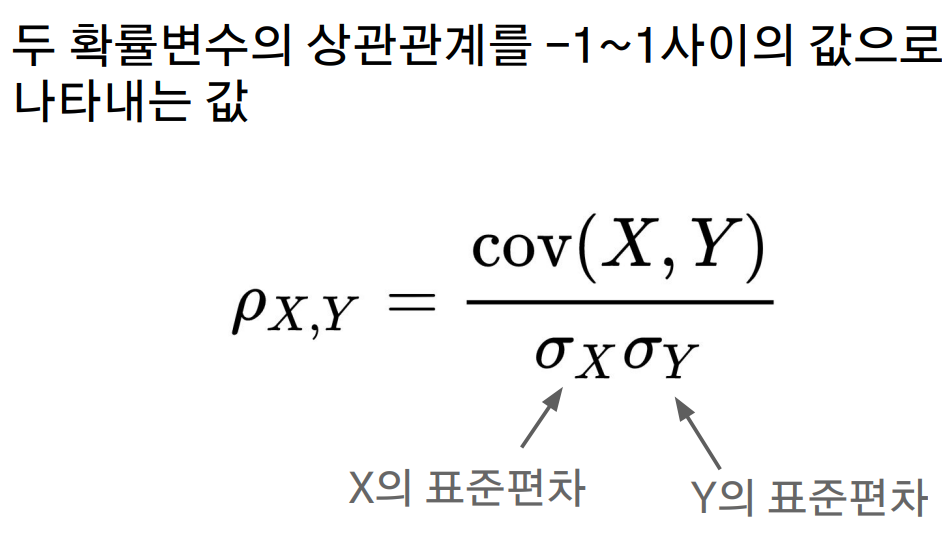
import sys
ids, X, Y = zip((tuple(int(x) for x in line.split()) for
line in sys.stdin))
mean_x = sum(X)/len(X)
mean_y = sum(Y)/len(Y)
std_x = (sum((x - mean_x) 2 for x in X)/len(X)) 0.5
std_y = (sum((y - mean_y) 2 for y in Y)/len(Y)) 0.5
cov = sum((x - mean_x) (y - mean_y) for x, y in zip(X,
Y))/len(X)
corr = cov/std_x/std_y
print(corr)
//데이터 값
0 347 127
1 17 65
2 10 25
3 17 76
4 10 61
5 13 53
6 6 33
7 20 35
8 8 47
9 57 89
...
//그리기
import matplotlib.pyplot as plt
import sys
ids, cnts, mins = zip(*(tuple(int(x) for x in line.split()) for line in sys.stdin))
plt.scatter(cnts, mins, s=0.3)
plt.xlabel("# friends")
plt.ylabel("minu'tes per day")
plt.title("Correlation")
plt.show()
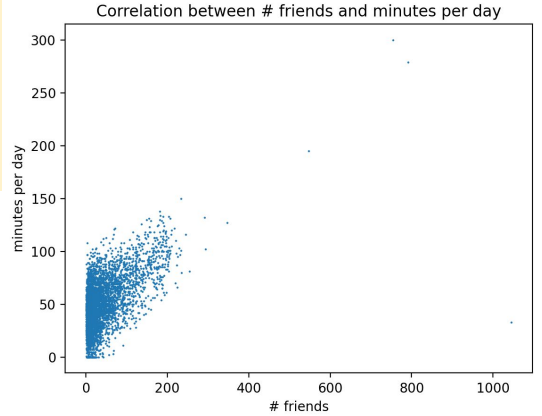
// 4강
import torch
x = torch.tensor([[1,2,3], [4,5,6], [7,8,9]])
y = torch.FloatTensor([[1,2,3], [4,5,6], [7,8,9]])
//dtype =torch.float
print("x =", x)
print("y =", y)
//x.type(), x.size() = shape, len(x.shape) = ndimension() = ndim
x0 = torch.unsqueeze(x, 0)
x1 = torch.unsqueeze(x, 1)
x2 = torch.unsqueeze(x, 2)
print("x0.shape:", x0.shape)
print("x1.shape:", x1.shape)
print("x2.shape:", x2.shape)
print("x0 =", x0)
print("x1 =", x1)
print("x2 =", x2)
x3 = torch.squeeze(torch.squeeze(x0))
print("x3 =", x3)
print("x3.shape =", x3.shape)
x4 = x.view(9)
x5 = x.view(1,3,3)
print("x4 =", x4)
print("x5 =", x5)
xw + b
x = torch.FloatTensor([[1,2], [3,4], [5,6]])
w = torch.randn(1,2, dtype=torch.float)
b = torch.randn(3,1, dtype=torch.float)
result = torch.mm(x, torch.t(w)) + b =>
mm이 곱하기임
print(result)
w = torch.tensor(1.0, requires_grad=True)
a = w*3
l = a**2
l.backward() //기울기 계산
print('l을 w로 미분한 값은', w.grad)
import torch
x_train = torch.FloatTensor([[1,2], [3,2], [3,7], [1,1], [1,0]])
y_train = torch.FloatTensor([[4], [8], [23], [1], [-2]])
y = 2x + 3x -4
W = torch.zeros(2,1)
b = torch.zeros(1,1)
lr = 0.01
for epoch in range(3001):
W.requiresgrad(True)
b.requiresgrad(True)
hypothesis = torch.mm(x_train, W) + b
cost = torch.mean((hypothesis - y_train) * 2)
cost.backward() => 미분한값이 w.grad랑 b.grad 에 들어감
with torch.no_grad() as grd:
if epoch % 100 == 0:
W = W - lr W.grad
b = b - lr * b.grad
from sklearn.linear_model import LinearRegression
x = [[1,2], [3,2], [3,7], [1,1], [1,0]]
y = [[4], [8], [23], [1], [-2]]
lr = LinearRegression() # 모델 생성
lr.fit(x, y) # 학습 (피팅)
print(lr.coef, lr.intercept)// 학습결과
print(lr.predict([[5,10]]))//y값 출력
//5강
import torch
x_train = torch.FloatTensor([[1],[2],[3],[4],[5],[2.5],[3.5],[0],[3.1],[2.7],[2.8],[2.9]])
y_train = torch.FloatTensor([[1],[1],[1],[0],[0],[0],[0],[1],[0],[1],[1],[1]])
W = torch.zeros(1,1)
b = torch.zeros(1,1)
lr = 1.0
for epoch in range(3001):
W.requiresgrad(True)
b.requiresgrad(True)
hypothesis = torch.sigmoid(torch.mm(x_train, W) + b)
cost = torch.mean(-y_train torch.log(hypothesis)
-(1 - y_train) torch.log(1 - hypothesis))
cost.backward()
with torch.no_grad() as grd:
W = W - lr W.grad
b = b - lr b.grad
//x = [4.5] 혹은 [1.1]일 때, y는 0일까 1일까?
x_test = torch.FloatTensor([[4.5],[1.1]])
test_result = torch.sigmoid(torch.mm(x_test, W) + b)
print(torch.round(test_result))
//optimizer
optimizer = torch.optim.SGD([W,b], lr=1.0)
for epoch in range(3001):
W.requiresgrad(True)
b.requiresgrad(True)
hypothesis = torch.sigmoid(torch.mm(x_train, W) + b)
cost = torch.mean(-y_train torch.log(hypothesis)
-(1 - y_train) torch.log(1 - hypothesis))
optimizer.zero_grad()
cost.backward()
optimizer.step()
with torch.no_grad() as grd:
if epoch % 100 == 0:
W = W - lr W.grad
b = b - lr b.grad
//종류
optimizer = torch.optim.SGD([W,b], lr=1.0)
optimizer = torch.optim.Adam([W,b], lr=1.0)
optimizer = torch.optim.Adadelta([W,b])
optimizer = torch.optim.Adagrad([W,b])
optimizer = torch.optim.RMSprop([W,b])
import matplotlib.pyplot as plt
with torch.nograd():
W.requires_grad(False)
b.requiresgrad(False)
plt.scatter(x_train, y_train)
X = torch.linspace(0,5,100).unsqueeze(1) // 점
Y = torch.sigmoid(torch.mm(X,W)+b) // 선
plt.plot(X,Y)
plt.show()
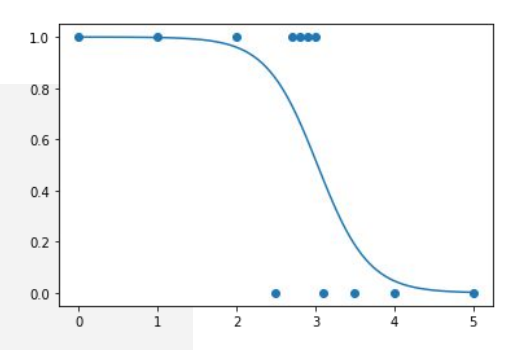
//label
plt.ylabel("Probability of 1 (Y)")
plt.xlabel("Input (X)")
/점선 색
plt.scatter(x_train, y_train, c="black")
...
plt.plot(X,Y, c="#ff0000")
//오른쪽위에 범례달기
plt.scatter(x_train, y_train, c="black", label="Training data")
...
plt.plot(X,Y, c="#ff0000", label="Fitting line")
plt.legend()
from sklearn.linear_model import LogisticRegression
xtrain = [[1],[2],[3],[4],[5],[2.5],[3.5],[0],[3.1],[2.7],[2.8],[2.9]]
y_train = [1,1,1,0,0,0,0,1,0,1,1,1] # 입력 shape이 pytorch에서와 다름에 주의!
model = LogisticRegression(penalty='none') # penalty (or regularization)은 추후 설명
model.fit(x_train, y_train)
#W와 b에 해당하는 값 출력
print(model.coef, model.intercept_)
// 새로운 x값이 주어질 때 y값 예측해보기
x_test = [[4.5],[1.1]]
test_result = model.predict(x_test)
print(test_result)
//6강
여러개의 데이타
import torch
x_train = torch.FloatTensor([ [1,2,1,1], [2,1,3,2], [3,1,3,4], [4,1,5,5], [1,7,5,5],
[1,2,5,6], [1,6,6,6], [1,7,7,7] ])
y_train = torch.FloatTensor([ [0,0,1], [0,0,1], [0,0,1], [0,1,0], [0,1,0], [0,1,0],
[1,0,0], [1,0,0] ])
W = torch.zeros(4, 3, requires_grad=True)
b = torch.zeros(1, 3, requires_grad=True)
optimizer = torch.optim.Adam([W,b], lr=0.1)
for epoch in range(3001):
hypothesis = torch.softmax(torch.mm(x_train, W)+b, dim=1)
//dim => 차원에 관한 내용. 0 , 1 가로를 합이 1, 세로를 합이 1
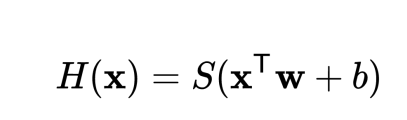
cost = -torch.mean(torch.sum(y_train * torch.log(hypothesis), dim=1))
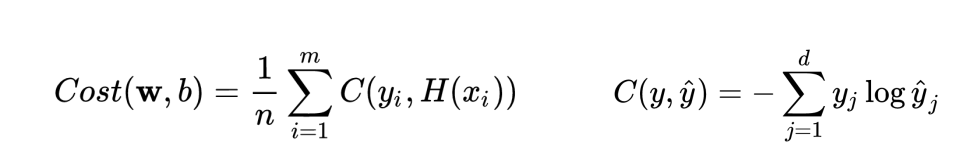
optimizer.zero_grad()
cost.backward()
optimizer.step()
with torch.no_grad():
if epoch % 300 == 0:
print("epoch: {}, cost: {:.6f}".format(epoch, cost.item()))
//x 가 [1,11,10,9], [1,3,4,3], [1,1,0,1] 일 때, y값은?
x_test = torch.FloatTensor([[1,11,10,9], [1,3,4,3], [1,1,0,1]])
test_all = torch.softmax(torch.mm(x_test, W)+b, dim=1)
print(test_all)
print(torch.argmax(test_all, dim=1))
//백터가 주어지면 백터값중 제일 큰값 위치 (index 값임)
//마음에 안드는 부분 1. [1,0,0], [0,1,0], [0,0,1] 대신 0, 1, 2를 쓰면 안되나?
y_train = torch.FloatTensor([ [0,0,1], [0,0,1], [0,0,1], [0,1,0], [0,1,0], [0,1,0],
[1,0,0], [1,0,0] ])
//마음에 안드는 부분 2. 이렇게 복잡한 함수를 항상 직접 구현해야하나? 어차피
softmax, cross entropy인데?
hypothesis = torch.softmax(torch.mm(x_train, W)+b, dim=1)
cost = -torch.mean(torch.sum(y_train * torch.log(hypothesis), dim=1))
/조금더 깔끔하게
import torch.nn.functional as F
y_train = torch.LongTensor([2,2,2,1,1,1,0,0])
z = torch.mm(x_train, W)+b
cost = F.cross_entropy(z, y_train)
//좀더 깔끔쓰
import torch.nn as nn
…
model = nn.Linear(4,3)
optimizer = torch.optim.Adam(model.parameters(),lr=1)
=>
z = torch.mm(x_train, W)+b => z = model(x_train)
import numpy as np
from sklearn.linear_model import LogisticRegression
x_train = np.array([ [1,2,1,1], [2,1,3,2], [3,1,3,4], [4,1,5,5], [1,7,5,5],
[1,2,5,6], [1,6,6,6], [1,7,7,7] ])
// y에 0, 1, 2 등 둘 이상의 class가 존재 => softmax regression
y_train = np.array([ 2, 2, 2, 1, 1, 1, 0, 0 ])
logistic = LogisticRegression() # 모델 생성
logistic.fit(x_train, y_train) # 학습
pred = logistic.predict([[1,11,10,9], [1,3,4,3], [1,1,0,1]]) # test case (값 예측)
print(pred) # 출력
//7강
import numpy as np
import pandas as pd
meta = pd.read_csv( '/kaggle/input/the-movies-dataset/movies_metadata.csv' )
//metadata에서필요한열(column)만추려내기
meta = meta[ ['id', 'original_title', 'original_language', 'genres'] ]
//rename
meta = meta.rename(columns={'id':'movieId',
'original_title': 'title',
'original_language': 'language'})
//language
meta = meta.loc[meta['language'] == 'en',:]
//movie id 변경
meta.movieId = pd.to_numeric(meta.movieId)
meta.movieId => object에서 int로 바꿈
//genre정제하기:jsonstring을pythonset으로변환하는함수구현
def str_to_set(x):
genre_set = set()
for item in eval(x):
genre_set.add(item['name'])
return genre_set
//genre정제하기:meta.genres의모든값에str_to_set적용
meta.genres = meta.genres.apply(str_to_set)
//keyward data read
keywords = pd.read_csv( '/kaggle/input/the-movies-dataset/keywords.csv' )
//keywords데이터의keywords를집합으로변환하기
keywords.keywords = keywords.keywords.apply(str_to_set)
/id열을movieId로이름변경하고데이터타입을숫자로변환하기
keywords = keywords.rename(columns={'id': 'movieId'})
keywords.movieId = pd.to_numeric(keywords.movieId)
//같은movieId를갖는데이터를합치기
meta = pd.merge(meta, keywords, on='movieId', how='inner')
//영화찾아보고합쳐서출력해보기
dk = meta.loc[meta.title == 'The Dark Knight'].iloc[0]
dkr = meta.loc[meta.title == 'The Dark Knight Rises'].iloc[0]
pd.concat([dk, dkr], axis=1).T
//Jaccard유사도함수구현및실행
def jaccard_similarity(s1, s2):
if len(s1|s2) == 0:
return 0
return len(s1&s2)/len(s1|s2)
//비슷한 영화 추천 기능
def find_similar_movies (input_title , matrix, n, alpha):
input_meta = meta.loc[ meta[ 'title'] == input_title].iloc[ 0]
input_set = input_meta.genres | input_meta.keywords
//input_meta:입력된영화의metadata
input_set:입력된영화의genres와keyword의합집합
result = []
for this_title in matrix.columns:
if this_title == input_title:
continue
//result:모든영화마다유사도를계산하여저장
//입력된영화는유사도계산을하지않고Pass~
this_meta = meta.loc[ meta[ 'title'] == this_title].iloc[ 0]
this_set = this_meta.genres | this_meta.keywords
//this_meta:유사도를계산하려는영화의metadata
// this_set:이영화의genres와keywords의합집합
pearson = pearson_similarity(matrix[this_title], matrix[input_title])
jaccard = jaccard_similarity(this_set, input_set)
//pearson:입력영화와이번영화의pearson유사도결과
jaccard:입력영화와이번영화의jaccard유사도결과
score = alpha pearson + ( 1-alpha) jaccard
result.append( (this_title, pearson, jaccard, score) )
// pearson:입력영화와이번영화의pearson유사도결과
// jaccard:입력영화와이번영화의jaccard유사도결과
result.sort(key= lambda r: r[3], reverse= True)
return result[:n]
//모든영화에대해유사도계산이끝나면result를정렬
// 상위n개를return
//TheDarkKnight와비슷한영화추천해보기
result = find_similar_movies('The Dark Knight', matrix, 10, 0.3)
pd.DataFrame(result, columns = ['ti=tle', 'pearson', 'jaccard', 'score'])
// from google.colab import files
file_upload = files.upload()
업로드 방법
//meta = pd.read_csv( "./owid-covid-data.csv", "r")
//Pearson유사도함수구현
def pearson_similarity(u1, u2):
u1_c = u1 - u1.mean()
u2_c = u2 - u2.mean()
denom = np.sqrt(np.sum(u1_c**2) np.sum(u2_c ** 2))
if denom != 0:
return np.sum(u1_c u2_c)/denom
else:
return 0
