
Apache Kafka란?
- 스트리밍 데이터를 다루기 위한 분산 메시징 시스템
- Pub-Sub 모델 지원
Pub-Sub 모델이란?
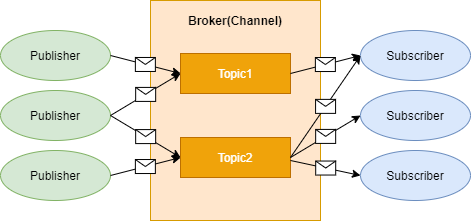
- 비동기 메시징 패러다임
- Publisher의 메세지는 특별한 수신자가 정해져 있지 않음
- Subscriber는 Publisher에 대한 지식 없이 원하는 메세지만을 수신할 수 있음
- KT 우면 연구센터 택배 보관함 시스템과 유사 - 택배 기사와 고객이 직접 택배를 주고 받는 것이 아니라, 특정 장소에 택배를 모아놓았다가 고객이 직접 가져감
Kafka Architecture
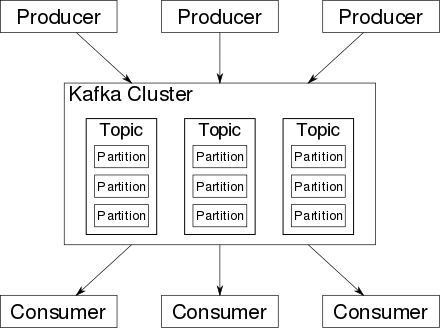
Producer
Kafka에 데이터를 입력하는 클라이언트.
Consumer
Kafka에서 데이터를 가져오는 클라이언트. 데이터를 가져올 topic을 지정한 후 해당 topic에서 데이터를 가져옴. topic에 입력된 데이터는 여러 Consumer가 서로 다른 처리를 하기 위해 여러 번 가져올 수 있음.
Topic & Partition
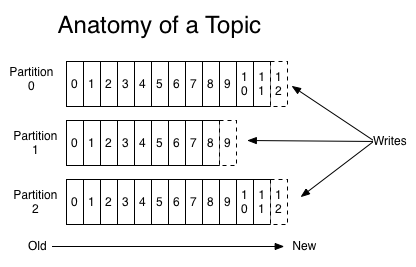
Topic은 데이터가 들어가는 장소. Topic은 여러개의 Partition으로 구성 돼 있음. Partition은 Queue와 같은 FIFO 형태로, Consumer가 데이터를 가져갈 때 가장 오래 된 순서부터 가져감. 각 Partition에는 Partition Number가 붙고 이를 통해 Consumer가 데이터를 어디까지 읽었는지를 알려주는 offset value가 생성됨.
Consumer Group
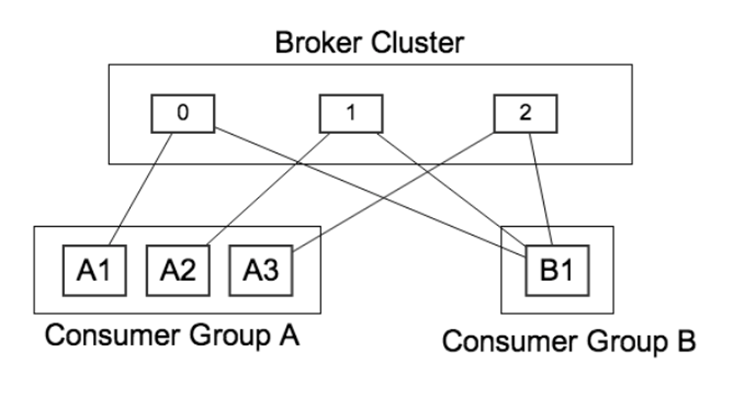
Partition은 Consumer Group당 오로지 하나의 Consumer 접근만을 허용. 해당 Consumer를 Partition Owner라고 부름.
Kafka의 장점
1. 높은 확장성
Kafka는 쉽게 클러스터(서버)를 늘리는 Scale-out이 가능함. Kafka를 통해 유통되는 데이터가 늘어나면 브로커의 부담이 증가하게 되어 클러스터의 규모를 확장할 필요가 있음. Kafka는 클러스터링을 위해 아파치 주키퍼(Apache ZooKeeper)를 사용함. 서버가 늘어나면 안정성과 성능 향상을 기대할 수 있음.
2. 고가용성
한개의 Partition에 대해 두대 이상의 브로커에 데이터를 복제(Replication)하여 분산 저장하므로 한 브로커에 장애가 나더라도 데이터 유실에 대한 걱정을 덜 수 있음.
3. 높은 성능
대용량 실시간 로그 처리에 특화됨. 불필요한 기능 제외하고 내부적으로 배치처리, 분산 처리와 같은 다양한 기법을 사용해 뛰어난 처리량(Throughput)을 갖도록 설계함.
4. 데이터의 영속성
메시지를 메모리에 저장하지 않고, 파일 시스템에 저장하여 데이터의 영속성 보장
