이전까지의 내용은 CacheMemory의 기초적인 이론에 대한 내용이었습니다. 캐시의 이론적인 구조와 캐시의 이론적 배경 등을 짚는 글이었습니다. 사실, 가장 중요한건 아래의 문장입니다.
캐시 메모리는 공간 지역성과 시간 지역성(Temporal Locality)를 기반으로 이루어진 시스템 입니다.
이번 글은 CPU 입장에서 캐시를 살펴볼겁니다.
CPU내의 실제 캐시의 모습
현대의 CPU는 코어를 1개만 가지고 있지 않습니다. CPU는 코어가 최소 8개는 되죠! 이러한 상황에서 CPU내의 cache 또한 CPU의 환경에 맞게 발전해왔습니다. 예전 글에서 CPU를 설명하면서 L1,L2,L3캐시가 있고 ~ 각각의 코어가 이런걸 갖고있다 정도만 이야기하고 슥 넘어갔지만, 이제는 그걸 자세히 볼 타이밍이 왔습니다.
저번에는 기능별로 그저 단순하게 그렸지만, 이번에는 회로 상에서 구현되는 걸 모델로 구현해봤습니다. (Intel 기준)
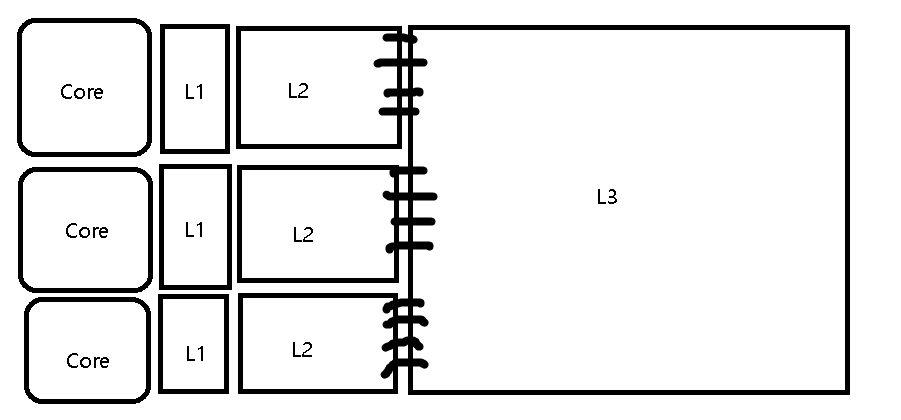
Core 1개당 L1,L2 캐시를 따로 갖고있고, L3는 모든 코어가 사용하는 공용캐시로 사용됩니다.
계층적 캐시구조의 특징
CPU내의 캐시 구조는 위 그림처럼 계층적으로 구성되어있습니다. 계층적으로 구성이 되었을 때, 장점이 뭘까요? 캐시미스 시, 메모리 엑세스 타임이 줄어듭니다.
메모리 엑세스 타임 측면
메모리에 접근하는 시간은 아래와 같이 구할 수 있습니다.
메모리 엑세스 타임 = Hit시 걸린 시간 + Miss될 확률 * Miss시 걸리는 시간
만약, 캐시가 1개밖에 없다면 어떻게 될까요?
- hit시 1초가 걸리고, 히트율은 95%라고 합시다. Miss시 5초 걸린다고 가정
- AMAT(Average Memory Access Time) = 1 + 0.05* 5 = 1.25
똑같은 캐시에 1개가 추가적으로 계층적으로 작동한다고 생각해봅시다. 그렇다면, 1계층이 실패했을 때, 2계층으로 들어가기 때문에, 메모리 접근 평균시간을 구하면 재밌는 식이 나타나게 됩니다.
- AMAT = 1 + 0.05 (L2에서의 히트시 걸리는 시간 + L2에서의 미스날 확률 L2에서 미스시 걸리는 시간) = 1 + 0.05 (1 + 0.05 5) = 1 + 0.05 * ( 1.25) = 1 + (0.0625) = 1.0625
계층적으로 설계하면 이처럼 미스 시, Miss Penalty가 줄어들게 됩니다.
캐시 메모리의 크기적인 측면
위 처럼, 계층적인 구조에서 Level이 내려갈 수록 메모리 크기를 좀 더 크게 설계할 수 있게 됩니다. 왜냐하면, CPU에 직접적으로 이용되는 것이 아니라, 캐시 - 캐시 느낌이 되버리기 때문에 L2,L3는 비교적 용량을 더 크게 설계하기가 쉽게 되고, 용량이 커지면 위에서 설명했던 L2에서 미스날 확률도 줄어들게 됩니다.
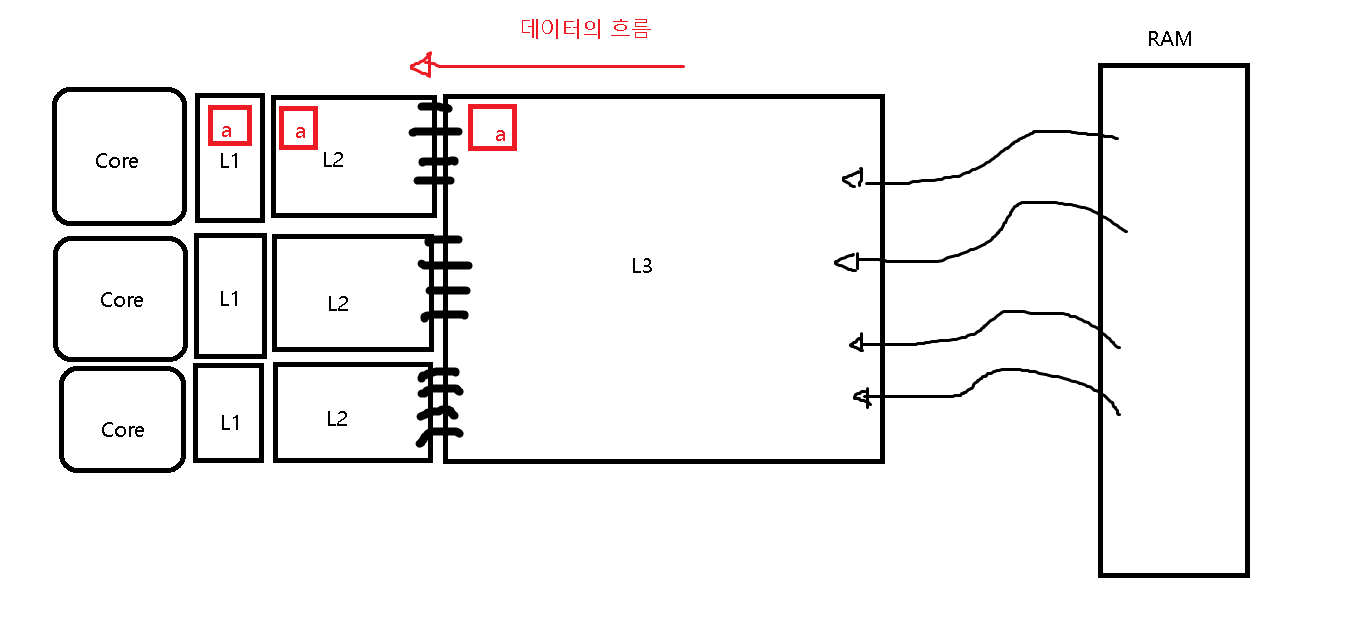
데이터의 흐름(?)적인 측면
어떻게 말을해야할지 모르겠어서 이렇게 이름을 붙였는데, 말하고 싶은 것은 "L1에 있는 데이터는 무조건 L2에 있고, L2에 있는 데이터라면 무조건 L3에 있다" 입니다.
렘에서 Cache로 데이터를 들고올 때, L3 -> L2 -> L1 순으로 모두 거쳐서 오기 때문에 L1에 있는 데이터는 무조건 L2에 있게 됩니다.
캐시라인
Cache는 공간적 지역성과 시간적 지역성을 통한 효율성을 증가시키는 장치입니다. 따라서, 데이터를 들고올 때도 1개만 달랑 들고오지 않습니다. 우리가 Page(4KB)를 렘에서 들고오는 것처럼 캐시도 캐시라인(64byte)을 기준으로 RAM에서 들고오게 됩니다.
즉, RAM이 아래 모양처럼 CacheLine으로 0부터 이쁘게 쪼개져있다고 생각하고 CPU에서는 CacheLine을 들고오게 됩니다.

예를들어, 어떤 변수가 168의 주소값을 갖고 있어서 , 127~191사이에 존재하게 된다면 아래와 같이 127~191에 해당되는 주황색 부분의 64byte를 들고오게 됩니다.
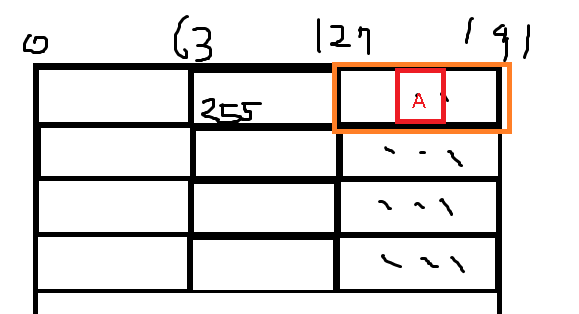
CPU는 CacheLine(64Byte)을 Cache메모리에 저장해두고, CacheHit가 되는지 안되는지 판단하게 됩니다.
그렇다면, CPU 입장에서 Instruction은 어떻게 구성이 될까요? 64Byte 중, 어느 바이트를 가져와야하는지 결정할 수 있어야하니까 Offset이 필요하게 됩니다. 64bit 프로세서라면, 마지막 6bit는 cacheLine의 Offset으로 자연스럽게 결정이 됩니다.

캐시 Set과 Index
저번 글에서 소개했다싶이, 캐시는 잦은 교체가 일어나는 것 때문에 캐시는 Set구조를 갖고있습니다. 즉, 이러한 CacheLine을 여러개 갖고있을 수 있도록 설계가 되었단 이야기 입니다. 여러 개의 CacheLine을 CPU 명세에서는 Cache Way라고 합니다. 예를들어, 12way라고 하면 캐시 1개의 세트당 12개의 Line을 저장할 수 있다는 이야기 입니다.
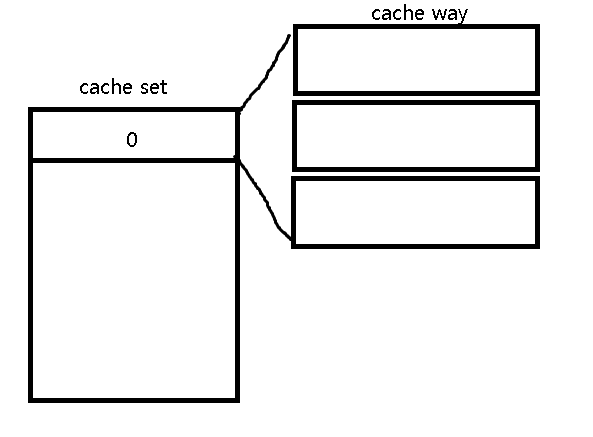
그렇다면, CacheSet는 어떤식으로 설계가 되었을까요?
- 이 부분은 가상메모리 쪽과 연계되어 있습니다. 가상 메모리 시스템에서는 메모리를 4KB단위로 다루게 됩니다.
- 즉, CPU가 바라보는 Instruction의 맨마지막 12bit는 page의 offset이고, 앞의 나머지비트는 물리주소로 변환을 위해 사용됩니다.
- 이때, 프로그래머가 캐시히트율을 최대한 생각하면서 프로그래밍을 하고싶다고 한다면, 어떻게 설계를 해주어야 할까요?
가상주소에서 물리주소로 바뀌어도 변화하지 않는 부분(예측가능한 부분)내에서 캐시히트율을 생각할 수 있도록 해줘야합니다. 즉, CacheIndex는 PageOffset을 벗어나지 않도록 6bit만 사용하도록 설계가 되었습니다.
물론, 이렇게 설계를 하지 않아도 됩니다. 이렇게 설계하지 않아도 캐시의 역할은 할 수 있습니다.
- 실제로 PageOffset을 벗어나서 cacheIndex를 더 쓰고 그걸 따로 관리하도록 만들거나 , 그냥 신경 안써도 상관은 없습니다.
- 이렇게 설계가 되었기 때문에, 사실상 캐시는 Way를 늘리는 것 이외에는 크기를 키울 방법이 딱히 없습니다. Page크기가 커지지 않았기 때문이죠.

이진수로 바라보는 캐시주소
- 같은 캐시라인이라면, 0xFFFFFFFFFFFFFFC0를 &(AND) 했을 때 같은 값이 나옵니다.
- 같은 캐시 인덱스 (세트)라면, 0x0000000000000FC00를 &(AND) 했을 때 같은 값이 나옵니다.
캐시라인 마스크, 캐시 인덱스 마스크(?)라고 저는 부르긴 하는데 어떻게 부르는지 잘 모르겠습니다.
RAM에서 데이터를 읽어오는 시나리오
- 어떤 데이터를 CPU가 가져와야할 때, 명령어를 먼저 봅니다.
- 명령어를 보고, 해당되는 cache Index로 갑니다. cacheIndex안에 있는 CacheLine들을 하나씩 체크하면서 일치하는 CacheLine이 있는지 봅니다.
if) 캐시 히트 시(CacheLine이 존재)
일치하는 CacheLine이 있다면 CacheLine Offset을 보고, 해당되는 데이터를 읽어오면 됩니다.
if) 캐시 미스 시
L2로 내려가서 뒤져보고, L3로 내려가서 뒤져보고...이런식으로 아래 캐쉬를 순차적으로 탐색한 뒤, 찾으면 L3->L2->L1 순으로 업데이트 시켜줍니다.
