포인터에 대한 것을 하다보니, 가상메모리 시스템에 대한 이야기를 정리해야겠다고 생각이 되어서 요즘 컴구조랑 C언어 정리를 왔다갔다 업로드 하고 있습니다.
사실, 제가 블로그의 글을 바로바로 쓰는게 아니라, Notion에 어느정도 한번 정리를 하고, 나름 누군가가 읽는다는 생각으로 정제해서 블로그에 업로드를 하기 때문에.. Notion에 내용들은 팍팍 쌓이는데 블로그 업로드에는 병목현상이 생겨버리네요.
(네 변명입니다..사실 C언어는 끝낸지 오래고, C++도 끝낸지 오래...)

가상 메모리 시스템의 등장배경
가상 메모리 시스템은 추상적인 개념이지만, 등장배경을 알게되면 쉽게 이해가 됩니다. 과거로 돌아가서 한 8bit 컴퓨터가 있다고 상상해봅시다. 네, 상상이 안되겠지만, 소형기기에 쓰는 간단한 CPU칩을 상상하셔도 좋을거 같습니다. (저 또한 태어날때부터 32bit였습니다.)
과거의 컴퓨터는 매우 간단한 장치였고, Ram의 크기 또한 작았습니다. 따라서, 하나의 컴퓨터가 하나의 프로그램을 실행하는 동안, 다른 프로그램을 실행하는 것은 불가능한 일이라고 여겼을겁니다.
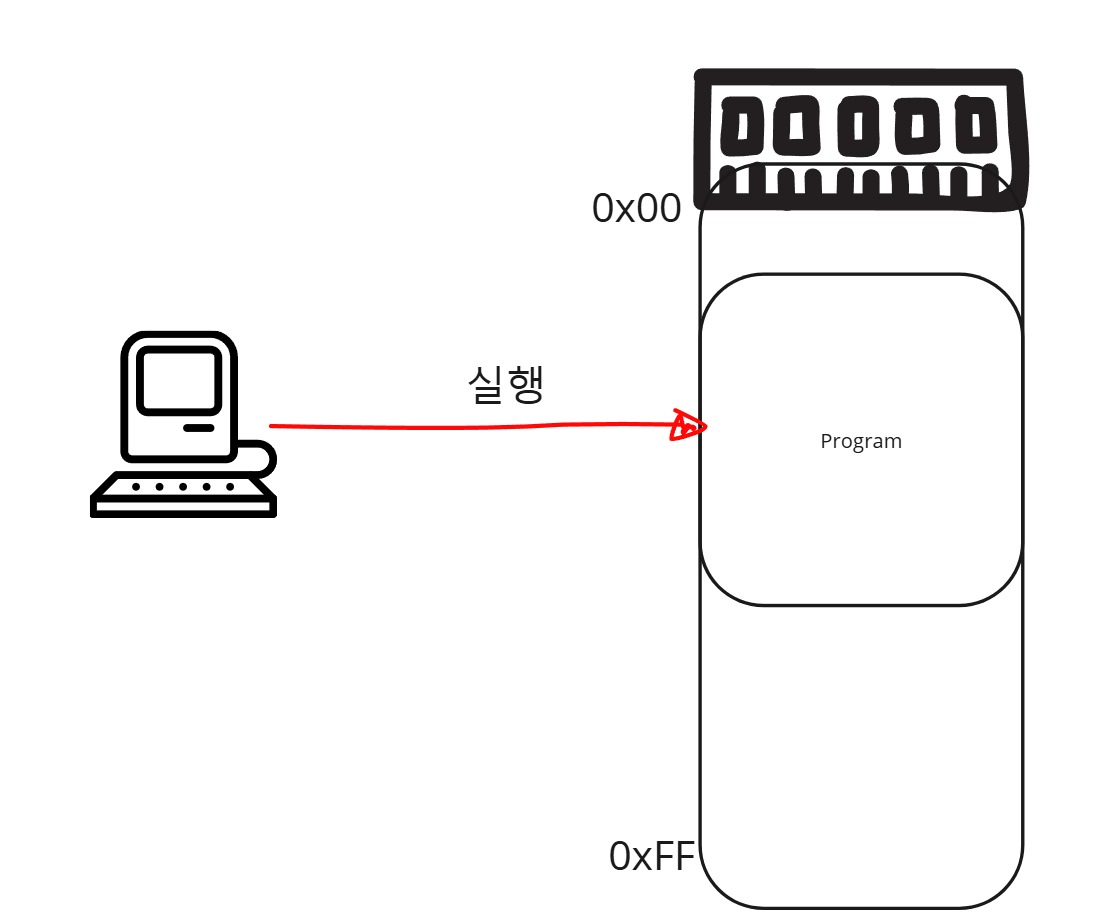
그 당시, 메모리는 굉장히 비싼 자원이었기 때문에, 메모리의 추가 없이 프로그램은 여러 개 돌릴 수 있는 방법을 이라는 욕구가 발생하고, 연구를 하기 시작했을겁니다. 여기서 부터 가상메모리 시스템의 시작점이라고 전 생각합니다. 물리 메모리를 인간기준으로 추상화시켜서, 내 멋대로 다루겠다 가 가상 메모리시스템입니다.
가상메모리 시스템
메모리의 주소를 추상화 시켜서, 내가 메모리를 직접 컨트롤 하겠다.
세그멘테이션
처음으로 제안된 방법(?)인지는 모르겠지만, 먼저 사람들은 프로그램을 일정한 영역으로 자른 뒤, 메모리에 분할해서 업로드 하는 방법을 생각했습니다. (Segmentation이 제안될 당시에 ELF Format이 있었는지, 없었는지는 모르겠지만.. 아마 있었겠죠? exe를 실행하니까.)
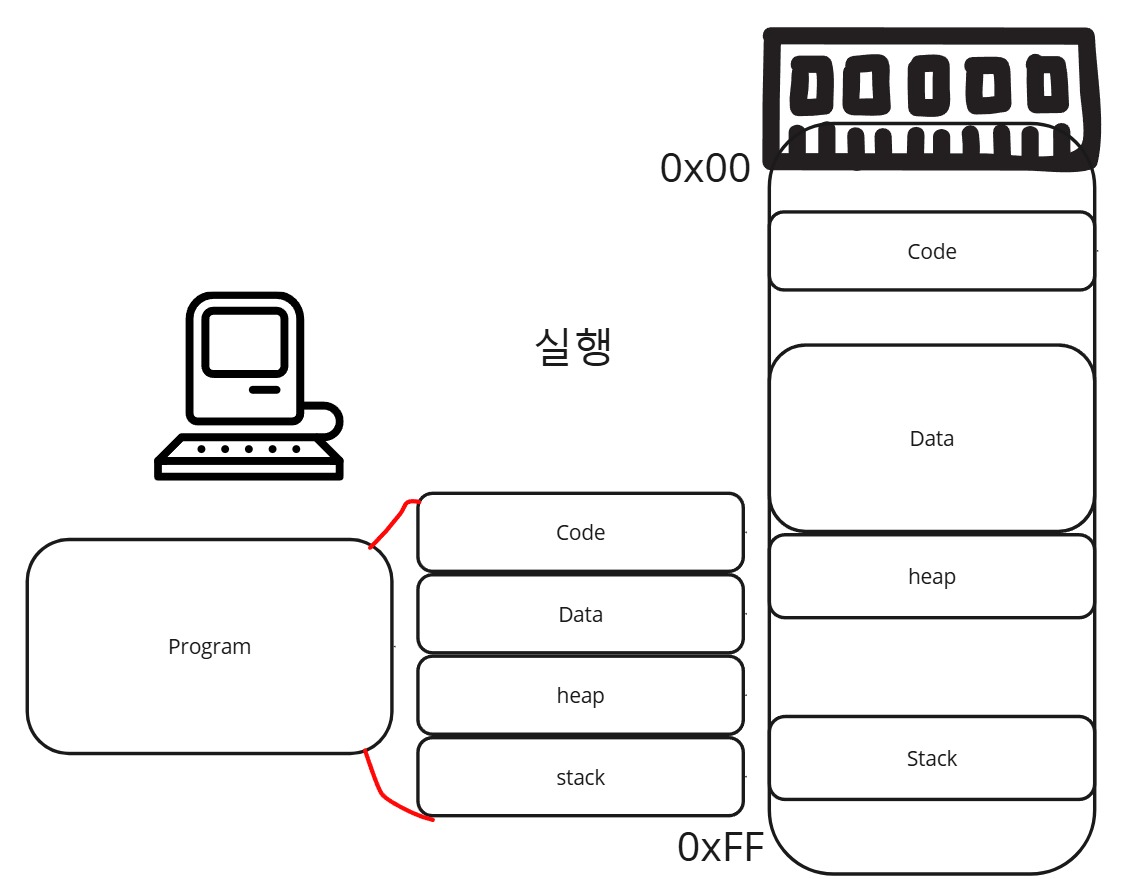
구체적으로 말하자면 구역(Segment)마다, Base와 크기정보를 저장해놓고, 해당 내용들을 메모리에 업로드하는 방식으로 구현이 된겁니다. Stack과 Heap이 동적인 크기를 가질 수 있는 이유도 여기서 부터 시작일겁니다.
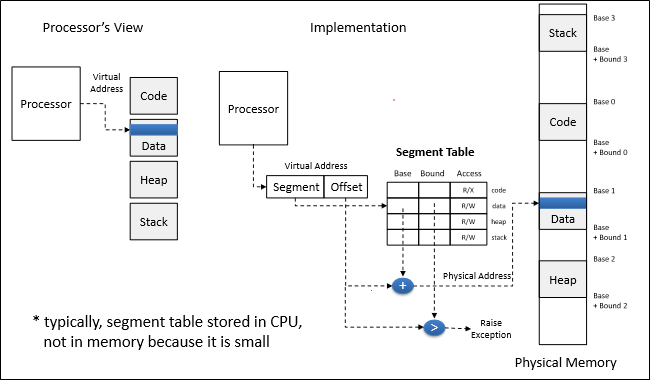
- 그림출처 : 박찬익 교수님의 CSED312 운영체제 수업
이렇게 나눠서, 메모리 공간을 활용하게 되면, 메모리를 조금 더 촘촘히 쓴다는 장점과 동적인 메모리 공간 사용이 가능하게 된다는 장점이 있습니다.
- 여기서, 오해를 하기 쉬운게, 메모리 공간을 조금 더 촘촘히 쓸 수 있다는 장점이 48KB 메모리 공간에 어떻게든 30KB,30KB 두 프로세스를 나눠서 넣을 수 있다는 개념이 아닙니다. 단순히 세그먼트는 프로세스들이 꼭 연속적인 공간을 차지할 필요가 없다는 것입니다.
여전히 문제점은 존재합니다. 각 구역별로 메모리 공간을 쪼개놨기 때문에, 각 구역마다 크기가 다양해지기 때문에 메모리 관리의 난이도가 올라갑니다. (다른 세그먼트들끼리 충돌될 가능성이 생깁니다)
또한, 각 구역별로 메모리 크기가 다양해게 되고, 메모리별로 남는 구간을 다 합쳐보면 하나의 프로세스를 실행할 수 있지만 하나의 구역이라도 프로세스가 사용할만한 충분한 연속적인 공간이 제공되지 않는다면 실행을 못하는 단점이 생기게 됩니다.
예를들어, 12KB 프로그램이 (1KB, 5KB, 1KB,5KB) 영역이 필요하다고 합시다. 메모리의 남는 공간이 19KB인데 , 코드영역에 5KB, 데이터에 4KB, 스택에 6KB, 힙에 4KB가 남았다면 19KB라는 공간이 있음에도 해당 프로세스는 실행하지 못하게 됩니다. 즉, 외부에서 볼 때는, 충분한 공간이 있음에도 남는공간이 연속적이지 않아서 생기는 외부 단편화문제를 초래하게 됩니다.
페이징
세그멘테이션과 다르게 메모리를 고정된 크기로 짤라서, 프로그램이 이용하는 방식으로 하자는게 페이징입니다. 메모리를 일정한 크기로 짜르기 때문에 메모리 관리도 편하게 되고, 메모리를 100% 다 활용할 수 있습니다. 또한, 외부 단편화는 없어집니다.
단점으로는 물리주소와 가상주소를 Mapping하기위한 방법이 세그멘테이션보다는 복잡해집니다. 세그멘테이션은 base register와 크기만 알면 됐는데, 페이징은 물리주소와 가상주소를 대응시켜줘야하는 복잡성이 생깁니다.
결론적으로, 현대 컴퓨터에서는 페이징 시스템을 사용하고 있습니다. 가상 메모리 시스템을 이야기할 때, 페이징 시스템 이야기가 쫙 나오는게 그 이유 때문입니다.
페이징 시스템의 문제점을 해결해보자
페이징 시스템의 가상 주소와 물리(프레임) 주소를 대응시키는 맵핑을 생각해봅시다.

단순하게, 가상주소와 물리주소를 1:1 대응을 시킨다고 생각을 했을 때를 가정해봅시다.
- 현재 컴퓨터는 4KB 페이지를 사용하고있고, 64bit 시스템을 사용하고 있습니다.
- 64bit 시스템은 실제로는 48bit정도를 사용하니까, 페이지는 총 몇 개가 나올 수 있을까요? 2^36개의 페이지가 나올 수 있게 됩니다.
페이지 정보는 64bit시스템이니까, 8byte라고 가정을 하고 생각한다면, 8Byte * 2^36이고, 페이징 시스템을 채택한다면 하나의 프로세스당 페이지 관리 정보를 저장하기 위해서, 512GB정보를 메모리에 상주시켜야한다는 말도 안되는 수치가 됩니다.
32bit 시스템이라고 생각해도 4byte x 2^20, 4MB라는 큰 용량을 프로세스 하나 당 4MB를 잡아먹게 됩니다.

저희가 현재 사용하는 RAM이 512GB가 넘을 수 있을리가 없고, 보통 16GB ~ 32GB정도를 사용하는데... 뭔가 이상하죠? 컴퓨터는 위와같은 문제 때문에, 페이징을 한단계로 하지 않습니다. 여러 단계를 걸쳐서 페이징을 할 수 밖에 없습니다.
따라서, 64bit인 경우에는 4단계 (몇몇자료에는 5단계라고 소개가 되기도함)에 걸쳐서, 페이징을 하고, 32bit인 경우에는 2단계에 걸쳐서 페이징을 합니다. 이렇게 하면 메모리에 상주해야하는 Page Table의 크기를 줄일 수 있다는 장점이 있습니다.
Page Table
페이징 시스템을 본격적으로 다루기전에, 용어 2개만 정리하고 가겠습니다. 물리주소와 가상주소를 매핑하는 정보를 저장하고 있는 구조체(?)를 페이지 테이블이라고 합니다.
예시를 쉽게하기 위해서, 그럴 일은 없지만 프로세스가 하나의 페이지만 할당받는다고 가정을 합시다.
페이지 테이블의 역할은 가상주소를 가지는 페이지를 실제로 물리주소(램)에 어디에 저장할지의 정보를 저장하고 있다고 보면 됩니다. 물론, 이 Page Table 또한 렘의 어딘가에 존재해야하죠.
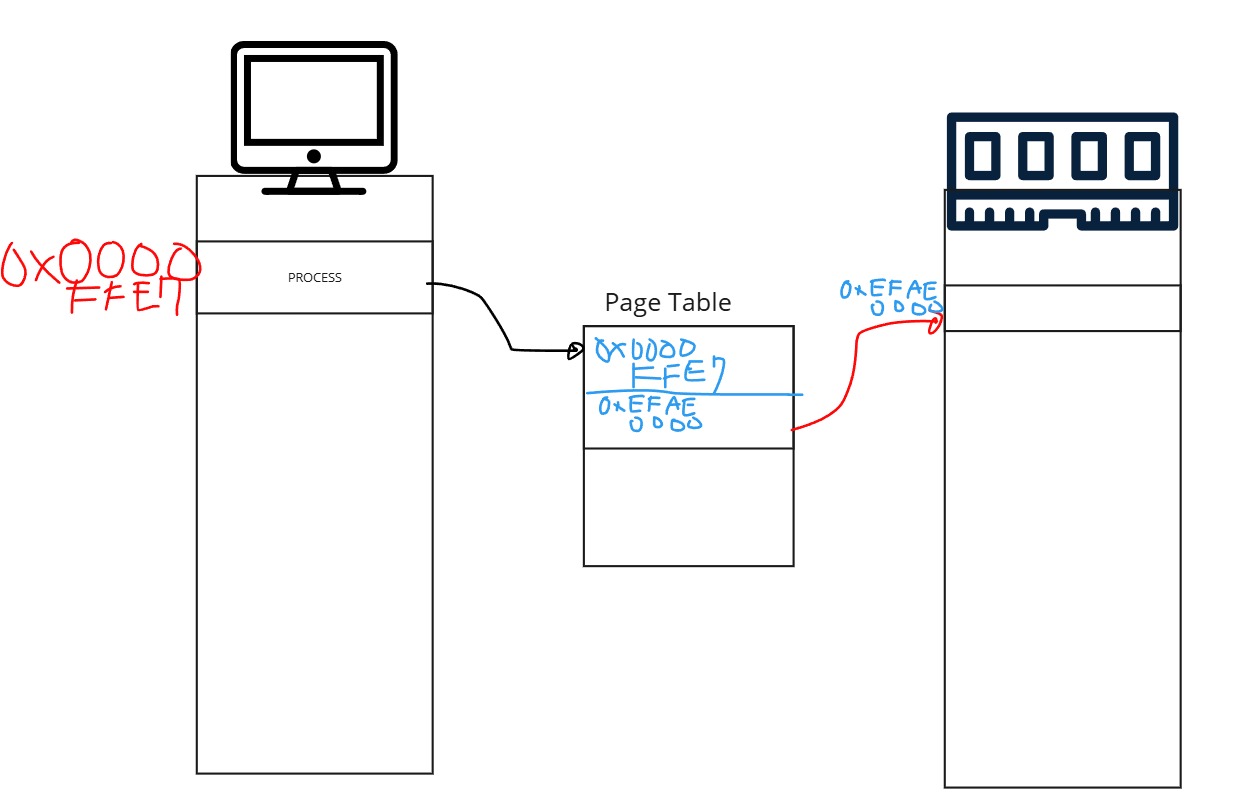
페이지 테이블
가상주소를 물리주소로 변환하기 위한 정보가 담긴 구조체. OS가 관리함.
Page Table Entry
Page Table Entry는 Page Table에 담긴 정보(32bit라면, 4byte, 64byte라면 8byte)를 가리키는 용어입니다. 그림으로 보면 더 이해하기가 쉬울겁니다.
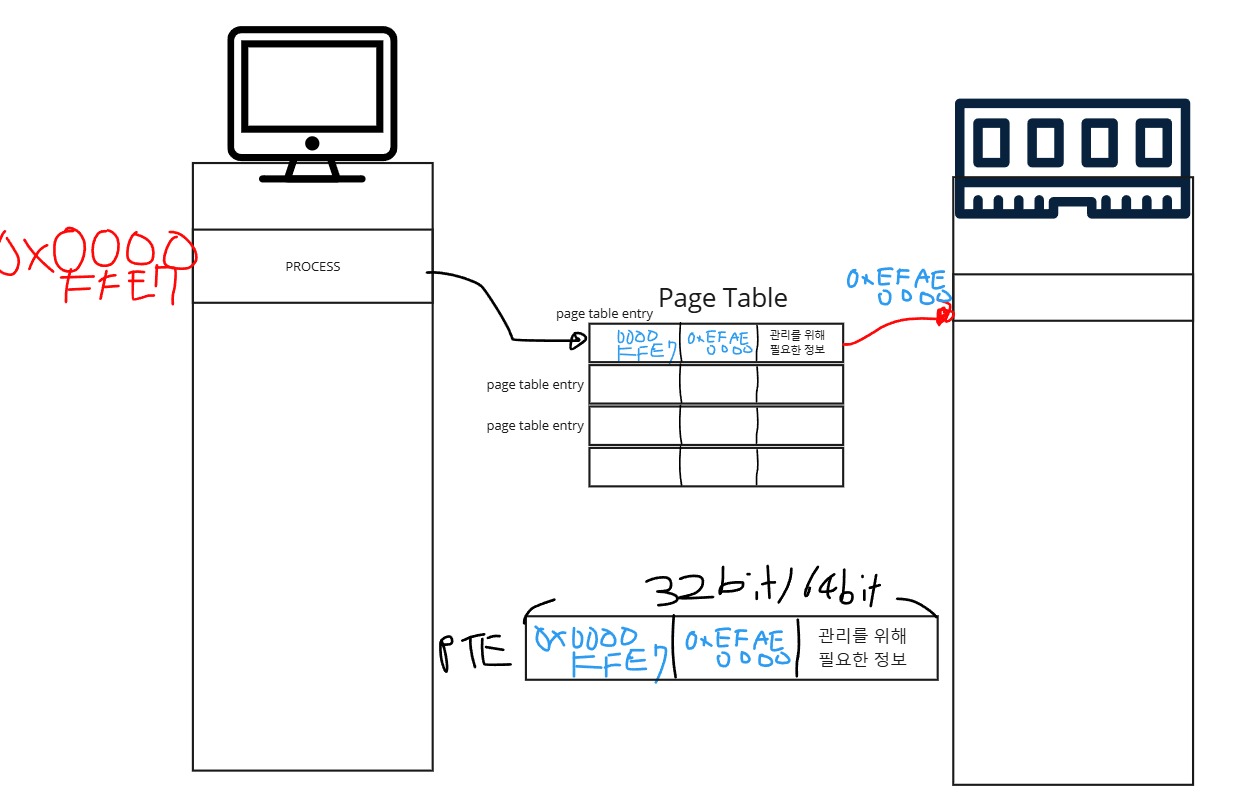
x86 PAE Page Table System(32-64bit 호환 시스템)
이때까지는 사실 이론적인 이야기였고, 실제로 32bit와 64bit에서 페이지테이블을 어떻게 사용하는지 소개해보겠습니다. 먼저 32bit에서 사용하는 Page Table System이
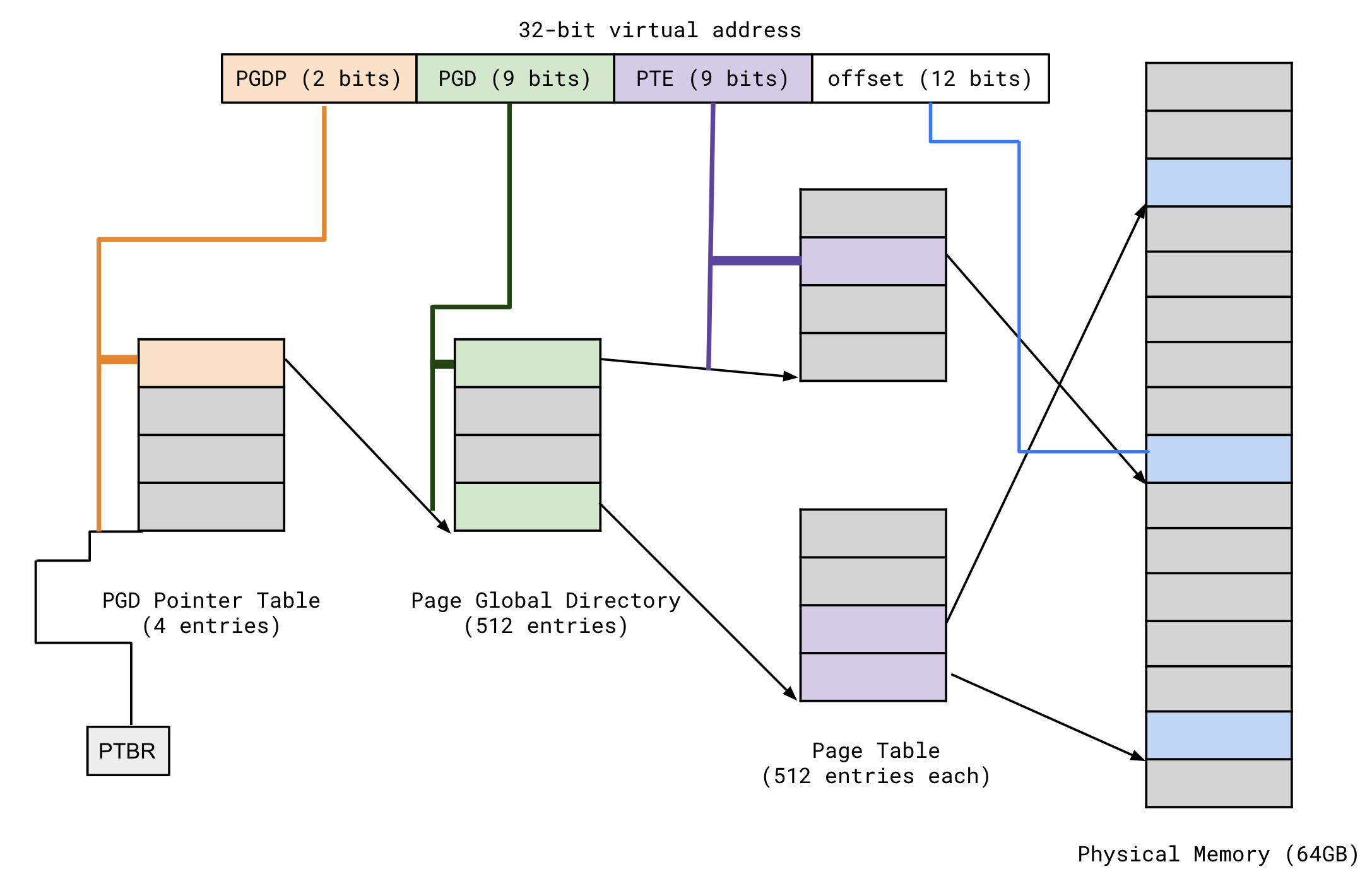
- PTBR (Page Table Base Register) : window에서는 CR3라고도 불리는 레지스터로, 최상위 Page Table(Page Directory라고도 합니다)의 주소를 갖고있습니다.
- 여기서 PGD와 PTE는 9bit(512개)의 인덱스를 갖게되는데, 이는 사실 10bit - 10bit 시스템에서, Page Entry를 8Byte로 늘려서 32bit/64bit 호환성을 맞추기 위해서 만든 시스템입니다.
- Page Directory : 페이지 테이블의 주소들을 갖고있는 페이지 테이블의 테이블(?) 상위 계층의 페이지 테이블입니다.
- Page Offset : 페이지가 4KB이기 때문에, 한 바이트를 가리키는 Offset입니다. 이건 Cache글에서 소개했듯, 프레임(물리적주소)에서도 변하지 않는 부분입니다.
기존의 10bit/10bit로 설명하는 것도 있지만,32bit에서 가장 발전된 형태는 위의 그림이고, 32bit라고 하면 위의 형태가 일반적입니다.
Multi-Level Page Table System (64bit 시스템)
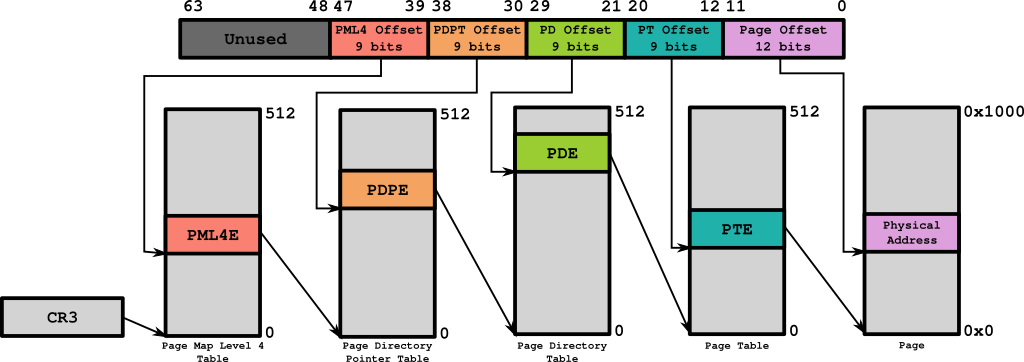
- 64bit에서는 어려울 것이 없습니다. 2단계에 걸친 작업을 4단계로 걸쳐서 하면 됩니다.
- 위에서 설명하려고 했지만, 너무 길어질 것 같아서 여기서 지연할당이라는 개념을 추가로 설명하도록 하겠습니다.
지연할당
OS에서는 굳이 지금 당장 사용하지 않는다면, 실제로 물리 메모리를 사용하진 않습니다.

말장난도 아니고 이게 뭐야 팎씨! 할수도 있지만 진짜 그렇습니다. 해당 프레임을 접근해서, Page Table까지 도달하고, Page Table의 Present가 0인걸 보고 Page Fault가 발생하는 순간 OS는 자신이 아껴놨던 RAM의 일부분을 Process에게 할당해주게 됩니다.
그 전까진, OS에서 Virtual Memory 상에서 사용할 메모리 공간을 예약 해놓고, PDPE,PDE,PTE와 같은 하위테이블 또한 존재해야한다는 것만 표시 해놓고, 실제로 프레임을 할당받지 않습니다. array[0] = 5 와 같은 코드가 실행될 때(진짜 메모리 접근이 일어났을 때), Page Fault가 발생되면서 하위테이블들도 만들고, PTE도 Frame을 할당받게 됩니다.
1GB를 할당한다면?
int* array = malloc(1 * 1024 * 1024 * 1024);
array[0] = 5;위와 같은 코드를 실행한다고 했을 때, 어떻게 OS가 여행을 떠나는지 봅시다.
우선 Top Down으로 갈수도 있지만, Bottom-UP으로 생각해봅시다. 1GB의 연속된 공간을 만들기 위해서는 몇개의 Page Table이 필요할까요?
1GB / 4KB = 2^30 / 2^12 => 2^18개 만큼의 Page Table Entry가 필요합니다.
Page Table은 512개의 Entry를 담을 수 있으므로, 2^18 / 2^9 => 512개의 Page Table이 필요하게 됩니다.
512개의 Page Table은 1개의 Page Directory Table로 관리가 가능합니다. (Page Directory Entry가 총 512개가 필요하게됨)
이러한 정보를 미리 Reserve해놓고, 프레임을 사용하진 않습니다.
하지만, array[0] = 5에서 배열의 시작주소를 접근했을 때 Page Fault가 비로소 발생하게 되고, Ram을 사용하기 시작합니다.
char* a = (char*)malloc(1 * 1024 * 1024 * 1024);
char* p = a;
for (int j = 0; j < 1024; j++)
{
for (int i = 0; i < 1024 * 4; i++)
{
*p = 'A';
++p;
}
}위의 코드를 실행했을 때, 작업표시창을 보면 아래와 같이 되있습니다. 커밋된 크기는 1GB지만,
Release모드로 디버거를 꼽고 돌려보면, 페이지 폴트를 발생시킬 때, 4K씩 주다가 가끔씩은 여러 페이지를 훅 줄 때도 있습니다.

TLB (Translate LookAside Buffer)
가상 메모리 시스템을 볼수록, 이런 생각이 드실 수 있습니다. 너무 느리지 않을까?
맞습니다. 하나의 메모리에 접근하는데 64bit의 경우 4단계의 Translation작업이 필요하게 됩니다. 그리고, Translation을 하기위한 테이블 또한 Ram에 존재하므로, CPU는 Ram에 여러번 접근을 결국 해야합니다.
CPU 내부에는 MMU에 TLB가 항상 들어가게 됩니다. 위의 과정 중, PTE에 기록되는게 곧 진짜 메모리 주소이므로, CPU는 매번 TLB를 먼저보고, 내가 지금 처리하는 워드가 TLB Hit하다면 바로 PFN으로 바꾼다음 명령어를 실행하게 됩니다.
TLB Miss가 발생했다면, 위의 내용대로 한단계씩 접근하면서, PTE까지 간 뒤, PTE의 내용을 TLB에 업데이트하게 됩니다. 어차피, 공간 지역성과 시간지역성으로 가까운 메모리에 접근할 확률이 높으므로 TLB로 인해, 주소를 Translation하는 작업은 많이 단축됩니다.

위 그림이 Cache와 TLB가 어떻게 동작하는지 i7을 기준으로 설명한 자료입니다.
Cache는 저번글에서 접근한 Ram의 Cache라인(64byte)를 적재해놓는다고 했습니다. 그 말은, 직접 물리메모리에 접근한다는 이야기 입니다. 이때, 이 PPN을 얻기 위해서 TLB를 한번 찔러본다고 짤막하게 설명하고 넘어간 적이 있습니다. 이제 이해가 되실겁니다.
다음 편에서는 DLL에 관한 짤막한 내용과 Copy on Write, Page의 속성, Window에서 메모리를 관리하는 법에 대해서 다루겠습니다. 사실 이 이론적인 내용을 바탕으로 만들어진 시스템이기 때문에, 큰 맥락은 비슷합니다.
다음편 - Window의 메모리 시스템
